ainovelprompter
1.0.0
AI New Prepter может генерировать письменные подсказки для романов на основе характеристик, определенных пользователем.
AI Noval Precpter-это настольное приложение, предназначенное для того, чтобы помочь авторам создать последовательные и хорошо структурированные подсказки для помощников по написанию искусственного интеллекта, таких как Chatgpt и Claude. Этот инструмент помогает управлять элементами истории, детали персонажа и генерировать правильно отформатированные подсказки для продолжения вашего романа.
Исполняемый файл на исполняемом сборке/бин
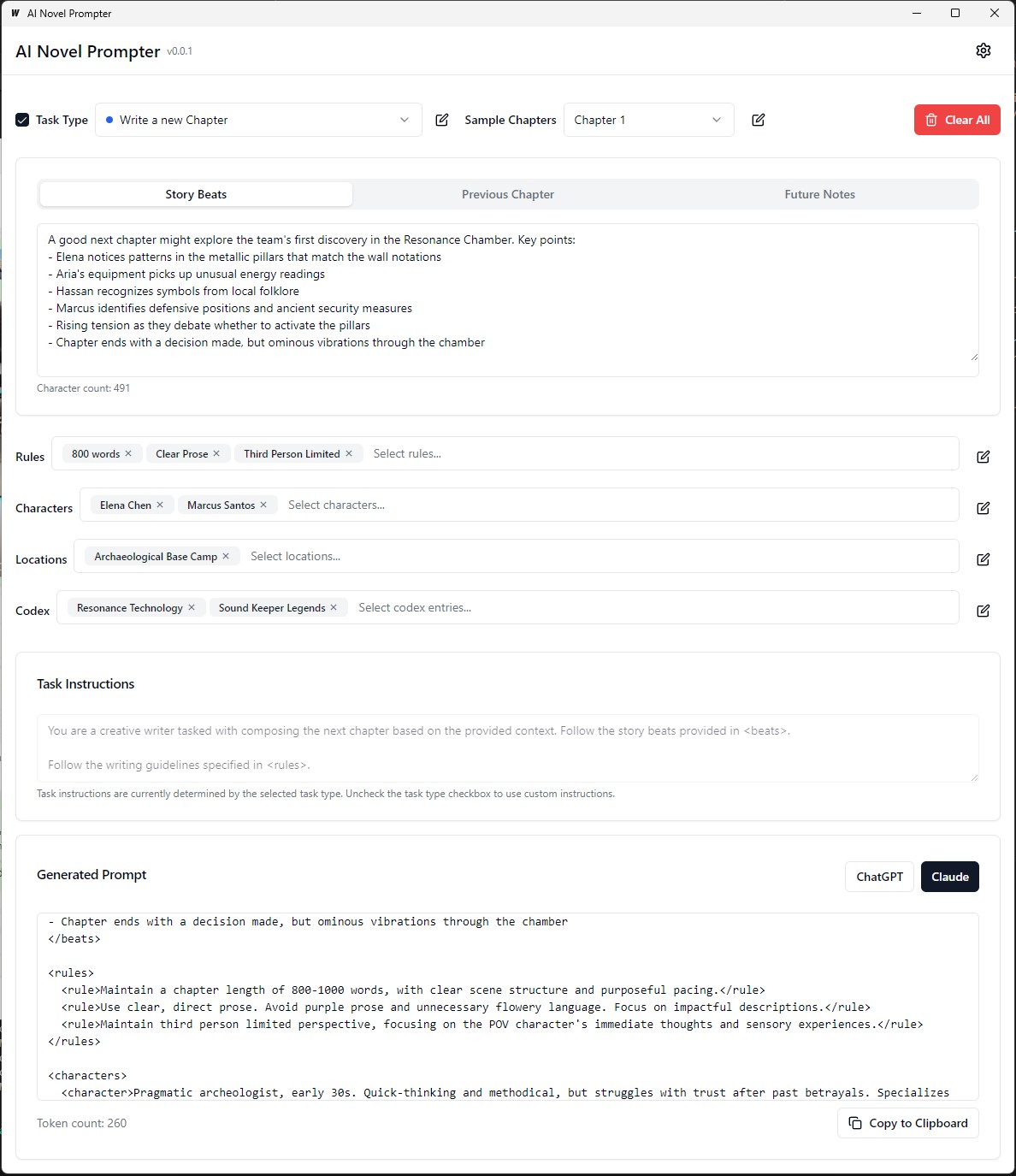
Каждая категория может быть отредактирована, сохранена и повторно используется в разных подсказках:
Внешний интерфейс :
Бэкэнд :
.ai-novel-prompter # Clone the repository
git clone [repository-url]
# Install frontend dependencies
cd frontend
npm install
# Build and run the application
cd ..
wails dev Чтобы построить перераспределяемый пакет производственных режимов, используйте wails build .
wails buildИсполняемый файл на исполняемом сборке/бин
Или генерируйте его с:
wails build -nsisЭто можно сделать для Mac, а также увидеть последнюю часть этого руководства
Застроенное приложение будет доступно в каталоге build .
Первоначальная настройка :
Создание подсказки :
Генерирование вывода :
Перед запуском приложения убедитесь, что у вас установлено следующее:
git clone https://github.com/danielsobrado/ainovelprompter.git
cd ainovelprompter
Перейдите к server каталогу:
cd server
Установите зависимости GO:
go mod download
Обновите файл config.yaml с помощью конфигурации базы данных.
Запустите миграции базы данных:
go run cmd/main.go migrate
Запустите бэкэнд -сервер:
go run cmd/main.go
Перейдите к client каталогу:
cd ../client
Установите зависимости от фронта:
npm install
Запустите сервер разработки Frontend:
npm start
http://localhost:3000 чтобы получить доступ к приложению. git clone https://github.com/danielsobrado/ainovelprompter.git
cd ainovelprompter
Обновите файл docker-compose.yml с помощью конфигурации базы данных.
Запустите приложение с помощью Docker Compose:
docker-compose up -d
http://localhost:3000 чтобы получить доступ к приложению. server/config.yaml .client/src/config.ts . Чтобы построить фронт для производства, запустите следующую команду в client каталоге:
npm run build
Подготовленные к производству файлы будут генерироваться в каталоге client/build .
В этом небольшом руководстве представлены инструкции о том, как установить PostgreSQL в подсистеме Windows для Linux (WSL), а также шаги по управлению разрешениями пользователей и устранением распространенных проблем.
Открыть терминал WSL : запустите дистрибуцию WSL (рекомендуется Ubuntu).
Обновление пакетов :
sudo apt updateУстановите PostgreSQL :
sudo apt install postgresql postgresql-contribПроверьте установку :
psql --versionУстановить пароль пользователя Postgresql :
sudo passwd postgresСоздать базу данных :
createdb mydbДоступ к базе данных :
psql mydbТаблицы импорта из файла SQL :
psql -U postgres -q mydb < /path/to/file.sqlСписок баз данных и таблиц :
l # List databases
dt # List tables in the current databaseПереключить базу данных :
c dbnameСоздайте нового пользователя :
CREATE USER your_db_user WITH PASSWORD ' your_db_password ' ;Привилегии гранта :
ALTER USER your_db_user CREATEDB;Роль не существует ошибки : переключитесь на пользователя «Postgres»:
sudo -i -u postgres
createdb your_db_nameРазрешение отказано в создании расширения : войти в систему как «Postgres» и выполнить:
CREATE EXTENSION IF NOT EXISTS pg_trgm; Неизвестная ошибка пользователя : убедитесь, что вы используете признанного пользователя системы или правильно обратитесь к пользователю PostgreSQL в среде SQL, а не через sudo .
Чтобы создать пользовательские данные обучения для точной настройки языковой модели для подражания стилю письма Джорджа Макдональда, процесс начинается с получения полного текста одного из его романов «Принцесса и гоблина» от проекта Гутенберг. Затем текст разбивается на индивидуальные истории истории или ключевые моменты, используя подсказку, которая инструктирует ИИ создать объект JSON для каждого удара, захватывая автора, эмоциональный тон, тип письма и фактический текстовый отрывок.
Далее, GPT-4 используется для переписывания каждой из этих историй о своих собственных словах, генерируя параллельный набор данных JSON с уникальными идентификаторами, связывающими каждый переписанный ритм с его первоначальным аналогом. Чтобы упростить данные и сделать их более полезным для обучения, широкий спектр эмоциональных тонов отображается с меньшим набором основных тонов, используя функцию Python. Затем два файла JSON (оригинальные и переписываемые ритмы) используются для создания подсказок обучения, где модель просят перефразировать текст, сгенерированный GPT-4 в стиле оригинального автора. Наконец, эти подсказки и их целевые выходы отформатированы в файлы JSONL и JSON, готовые к использованию для точной настройки языковой модели для захвата отличительного стиля написания MacDonald's.
В предыдущем примере процесс генерации перефразированного текста с использованием языковой модели включал некоторые ручные задачи. Пользователь должен был вручную предоставить входной текст, запустить сценарий, а затем просмотреть сгенерированный вывод, чтобы обеспечить его качество. Если вывод не соответствовал желаемым критериям, пользователю необходимо будет вручную повторно повторить процесс генерации с различными параметрами или внести коррективы к входному тексту.
Однако с обновленной версией функции process_text_file весь процесс был полностью автоматизирован. Функция заботится о чтении файла ввода текста, разделении его на абзацы и автоматической отправке каждого абзаца в языковую модель для перефразирования. Он включает в себя различные проверки и механизмы повторения для обработки случаев, когда сгенерированный выход не соответствует указанным критериям, таким как содержание нежелательных фраз, слишком короткие или слишком длительные или слишком длинные, или состоящий из нескольких абзацев.
Процесс автоматизации включает в себя несколько ключевых функций:
Возобновление из последнего обработанного абзаца: если сценарий прерывается или должен запускать несколько раз, он автоматически проверяет выходной файл и резюме обработки из последнего успешно перефразируемого абзаца. Это гарантирует, что прогресс не потерян, и сценарий может поднять, где он остановился.
Механизм повторения со случайными семенами и температурой: если сгенерированная перефраза не соответствует указанным критериям, скрипт автоматически возвращает процесс генерации до определенного количества раз. При каждой попытке он случайным образом изменяет значения семян и температуры, чтобы ввести вариации в генерируемых ответах, увеличивая шансы на получение удовлетворительного выхода.
Сохранение прогресса: скрипт сохраняет прогресс в выходном файле каждое указанное количество параграфов (например, каждые 500 абзацев). Эта гарантия против потери данных в случае любых перерывов или ошибок при обработке большого текстового файла.
Подробная регистрация и резюме: сценарий предоставляет подробную информацию о журнале, включая входной абзац, сгенерированный вывод, попытки повторения и причины отказа. В конце он также генерирует резюме, отображая общее количество абзацев, успешно перефразируемых абзацев, пропущенных абзацев и общего количества повторных изданий.
Чтобы создать пользовательские данные ORPO на заказ для точной настройки языковой модели, чтобы подражать стилю письма Джорджа Макдональда.
Входные данные должны быть в формате JSONL, причем каждая строка содержит объект JSON, который включает в себя подсказку и выбранную ответ. (Из предыдущей тонкой настройки) Для использования скрипта необходимо настроить клиент OpenAI с помощью клавиши API и указать пути ввода и выходных файлов. Запуск сценария обработает файл JSONL и генерирует файл CSV с столбцами для приглашения, выбранного ответа и сгенерированного отклоненного ответа. Сценарий сохраняет прогресс каждые 100 строк и может возобновить от того места, где он остановился, если прерван. По завершении он предоставляет сводку общих линий, обработанных, написанных линий, пропущенных линий и деталей повторения.
Качество набора данных имеет значение: 95% результатов зависят от качества наборов данных. Чистый набор данных очень важен, поскольку даже немного плохих данных могут повредить модели.
Ручной обзор данных: очистка и оценка набора данных может значительно улучшить модель. Это трудоемкий, но необходимый шаг, потому что никакое количество регулировки параметров не может исправить дефектный набор данных.
Параметры обучения не должны улучшаться, но предотвращать деградацию модели. В надежных наборах данных цель должна заключаться в том, чтобы избежать негативных последствий при руководстве моделью. Там нет оптимального уровня обучения.
Масштаб модели и оборудования: более крупные модели (параметры 33B) могут обеспечить лучшую настройку, но требуют не менее 48 ГБ VRAM, что делает их непрактичными для большинства домашних настройки.
Накопление градиента и размер партии: накопление градиента помогает уменьшить переосмысление за счет улучшения обобщения в разных наборах данных, но оно может снизить качество после нескольких партий.
Размер набора данных более важен для точной настройки базовой модели, чем хорошо настроенная модель. Перегрузка хорошо настроенной модели с чрезмерными данными может ухудшить его предыдущую точную настройку.
Идеальный график обучения начинается с фазы разминки, сохраняется устойчиво для эпохи, а затем постепенно уменьшается, используя график косинуса.
Ранг и обобщение модели: количество обучаемых параметров влияет на детали и обобщение модели. Модели с более низким уровнем обобщаются лучше, но теряют детали.
Применимость Лоры: эффективная точная настройка параметров (PEFT) применима к моделям крупных языков (LLMS) и таких системам, как стабильная диффузия (SD), демонстрируя ее универсальность.
Сообщество USLOTH помогло решить несколько проблем с Manetuning Llama3. Вот несколько ключевых моментов, которые следует иметь в виду:
Двойные токены BOS : двойные токены BOS во время создания могут сломать вещи. USLOTH автоматически решает эту проблему.
Преобразование GGUF : преобразование GGUF нарушено. Будьте осторожны с двойным BOS и используйте процессор вместо графического процессора для преобразования. USLOTH имеет встроенные автоматические преобразования GGUF.
Бэгги-базовые веса : некоторые из базовых весов Llama 3 (не инструктирование) являются «Buggy» (не подготовленным): <|reserved_special_token_{0->250}|> <|eot_id|> <|start_header_id|> <|end_header_id|> . Это может привести к НАНС и Блиной результатам. Унлот автоматически исправляет это.
Системная подсказка : Согласно сообществу USLOTH, добавление системной подсказки делает создание версии «Инструкт» (и, возможно, базовой версии) гораздо лучше.
Проблемы квантования : проблемы квантования являются обычными. Посмотрите на это сравнение, которое показывает, что вы можете получить хорошую производительность с Llama3, но использование неправильного квантования может повредить производительности. Для создания, используйте BitsAndbytes NF4, чтобы повысить точность. Для GGUF используйте как можно больше версий I.
Длинные контекстные модели : длинные контекстные модели плохо обучены. Они просто расширяют веревку тета, иногда без какого -либо обучения, а затем тренируются на странном наборе данных, чтобы сделать его длинным набором данных. Этот подход не работает хорошо. Плавное, непрерывное длинное масштабирование контекста было бы намного лучше, если бы масштабировать от длины контекста 8K до 1 м.
Чтобы решить некоторые из этих проблем, используйте Unloth для Manetuning Llama3.
При тонкой настройке языковой модели для перефразирования в стиле автора важно оценить качество и эффективность сгенерированных перефразов.
Следующие показатели оценки могут быть использованы для оценки эффективности модели:
Bleu (двуязычная оценка занзания):
sacrebleu в Python.from sacrebleu import corpus_bleu; bleu_score = corpus_bleu(generated_paraphrases, [original_paragraphs])Rouge (отзыв, ориентированная на повторную занзание для расстояния оценки):
rouge в Python.from rouge import Rouge; rouge = Rouge(); scores = rouge.get_scores(generated_paraphrases, original_paragraphs)Недоумение:
perplexity = model.perplexity(generated_paraphrases)Стилометрические меры:
stylometry в Python.from stylometry import extract_features; features = extract_features(generated_paraphrases)Чтобы интегрировать эти показатели оценки в ваш Axolotl Tipeline, выполните следующие действия:
Подготовьте данные обучения, создав набор данных параграфов из работ целевого автора и разделив их на наборы обучения и проверки.
Настраивайте свою языковую модель, используя учебный набор, после подхода, обсуждаемого ранее.
Создайте перефразы для абзацев в наборе проверки с использованием тонкой настройки модели.
Реализуйте метрики оценки, используя соответствующие библиотеки ( sacrebleu , rouge , stylometry ) и вычислите оценки для каждого сгенерированного парафразы.
Выполните оценку человека, собирая рейтинги и обратную связь от оценщиков человека.
Проанализируйте результаты оценки, чтобы оценить качество и стиль сгенерированных перефразов и принять обоснованные решения для улучшения процесса точной настройки.
Вот пример того, как вы можете интегрировать эти метрики в свой трубопровод:
from sacrebleu import corpus_bleu
from rouge import Rouge
from stylometry import extract_features
# Fine-tune the model using the training set
fine_tuned_model = train_model ( training_data )
# Generate paraphrases for the validation set
generated_paraphrases = generate_paraphrases ( fine_tuned_model , validation_data )
# Calculate evaluation metrics
bleu_score = corpus_bleu ( generated_paraphrases , [ original_paragraphs ])
rouge = Rouge ()
rouge_scores = rouge . get_scores ( generated_paraphrases , original_paragraphs )
perplexity = fine_tuned_model . perplexity ( generated_paraphrases )
stylometric_features = extract_features ( generated_paraphrases )
# Perform human evaluation
human_scores = collect_human_evaluations ( generated_paraphrases )
# Analyze and interpret the results
analyze_results ( bleu_score , rouge_scores , perplexity , stylometric_features , human_scores )Не забудьте установить необходимые библиотеки (Sacrebleu, Rouge, Stylometry) и адаптировать код в соответствии с вашей реализацией в Axolotl или аналогичном.
В этом эксперименте я исследовал возможности и различия между различными моделями искусственного интеллекта в создании текста из 1500 слов на основе подробной подсказки. Я проверил модели с https://chat.lmsys.org/, Chatgpt4, Claude 3 Opus и некоторые локальные модели в LM Studio. Каждая модель генерировала текст три раза, чтобы наблюдать изменчивость в своих выходах. Я также создал отдельную подсказку для оценки написания первой итерации из каждой модели и попросил CHATGPT 4 и Claude Opus 3 предоставить обратную связь.
Благодаря этому процессу я заметил, что некоторые модели демонстрируют более высокую изменчивость между выполнениями, в то время как другие, как правило, используют аналогичную формулировку. Были также существенные различия в количестве сгенерированных слов и объеме диалога, описаний и абзацев, созданных каждой моделью. Оценка обратная связь показала, что CHATGPT предлагает более «утонченную» прозу, в то время как Клод рекомендует меньше фиолетовой прозы. Основываясь на этих выводах, я составил список выводов, чтобы включить в следующую подсказку, сосредоточившись на точности, разнообразных структурах предложений, сильных глаголах, уникальных поворотах на фантазийных мотивах, последовательном тоне, отдельном голосе рассказчика и привлекательном стимуляции. Еще одна техника, которую следует рассмотреть, - это запрашивать обратную связь, а затем переписать текст на основе этой обратной связи.
Я открыт для сотрудничества с другими для дальнейших подсказок для каждой модели и изучения их возможностей в задачах творческого письма.
Модели имеют неотъемлемые предубеждения форматирования. Некоторые модели предпочитают дефисы для списков, других звездочек. При использовании этих моделей полезно отражать их предпочтения для последовательных результатов.
Форматирование тенденций:
Llama 3 предпочитает списки с жирными жирниками и звездочками.
Пример :
Перечислите элементы со звездочкой после двух новейсов
Список элементов, разделенных одним новым линином
Следующий список
Больше элементов списка
И т. д...
Несколько примеров:
Системная приверженность приверженности:
Контекст окна:
Цензура:
Интеллект:
Последовательность:
Списки и форматирование:
Настройки чата:
Настройки трубопровода:
Llama 3 гибкая и умная, но имеет контекст и цитирование ограничений. Соответственно настроить методы подсказки.
Все комментарии приветствуются. Откройте проблему или отправьте запрос на привлечение, если вы найдете какие -либо ошибки или имеете рекомендации для улучшения.
Этот проект лицензирован по лицензии: Attribution-noncommercial-noderivatives (по-N


