awesome RLHF
1.0.0
Это набор исследовательских работ для обучения подкреплению с обратной связью с человека (RLHF). И репозиторий будет постоянно обновляться для отслеживания границы RLHF.
Добро пожаловать, чтобы следовать и звезда!
Потрясающий RLHF (RL с человеческой обратной связью)
2024
2023
2022
2021
2020 и до
Подробное объяснение
Оглавление
Обзор RLHF
Документы
Кодовые базы
Набор данных
Блоги
Другая языковая поддержка
Внося
Лицензия
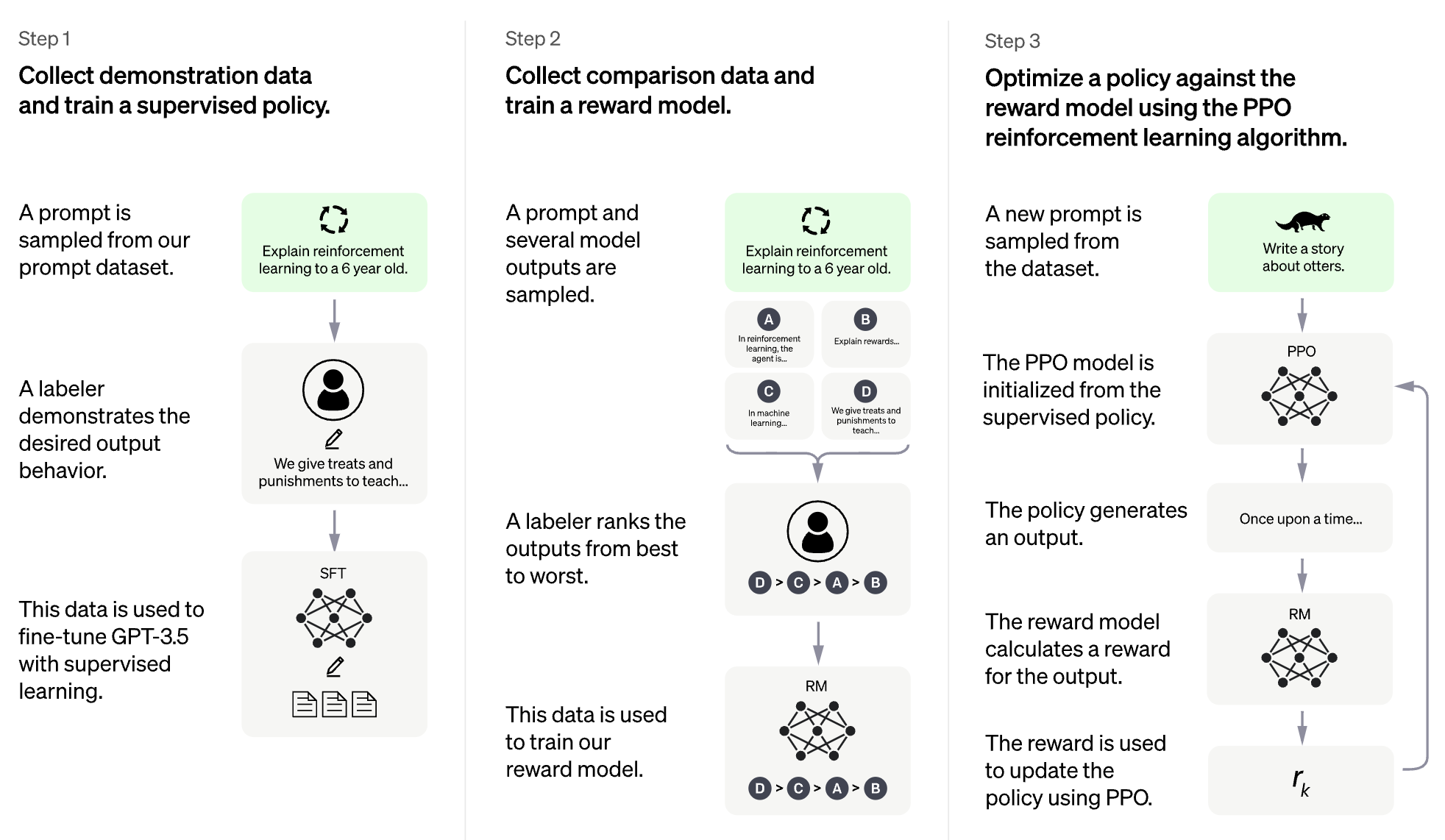
Идея RLHF состоит в том, чтобы использовать методы обучения подкрепления для непосредственной оптимизации языковой модели с обратной связью с человека. RLHF позволил языковым моделям начать выравнивать модель, обученную общему корпусу текстовых данных, к сложным человеческим ценностям.
RLHF для модели на большой языке (LLM)
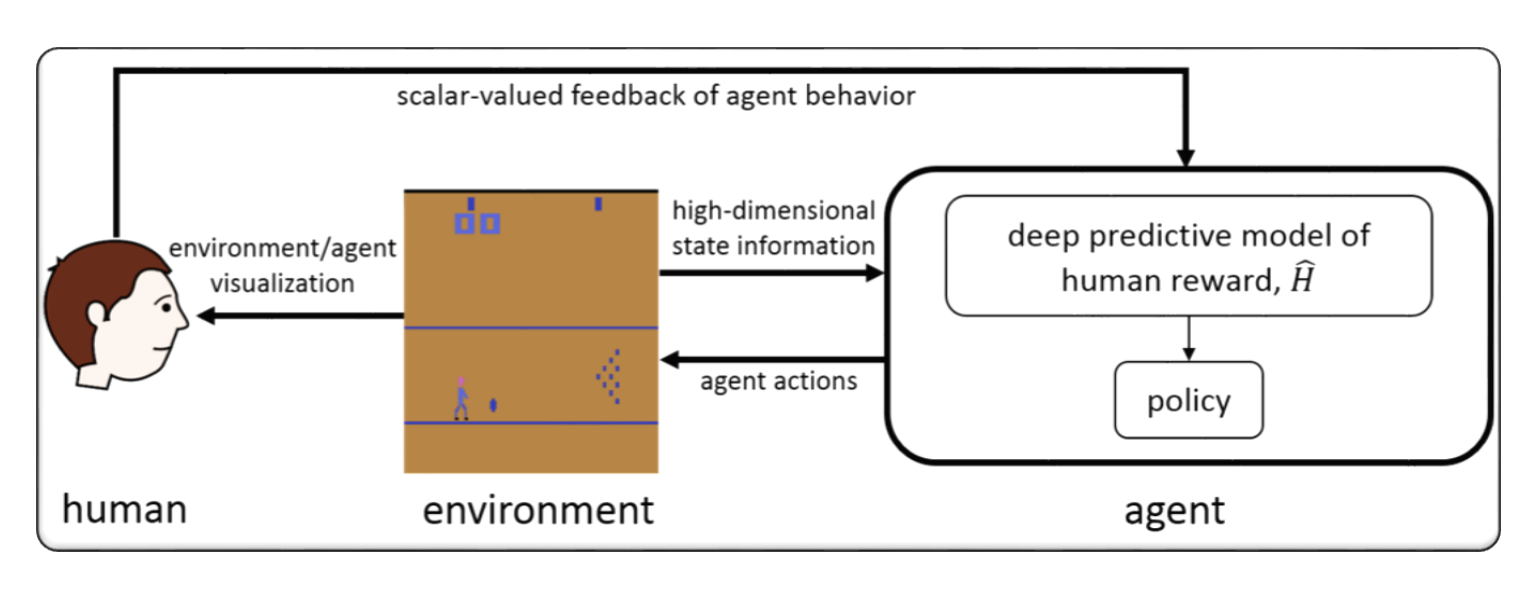
RLHF для видеоигры (например, atari)
(Следующий раздел был автоматически сгенерирован CHATGPT)
RLHF обычно относится к «подкреплению обучения с обратной связью с человека». Подкрепление обучения (RL) - это тип машинного обучения, которое включает в себя обучение агента для принятия решений на основе обратной связи из окружающей среды. В RLHF агент также получает отзывы от людей в виде рейтингов или оценок его действий, которые могут помочь ему учиться быстрее и точно.
RLHF - это активная область исследований в области искусственного интеллекта, с приложениями в таких областях, как робототехника, игры и индивидуальные системы рекомендаций. Он стремится решить проблемы RL в сценариях, где агент имеет ограниченный доступ к обратной связи из окружающей среды и требует ввода человека для повышения его эффективности.
Подкрепление обучения с обратной связью с человека (RLHF) - это быстро развивающаяся область исследований в области искусственного интеллекта, и существует несколько передовых методов, которые были разработаны для улучшения эффективности систем RLHF. Вот несколько примеров:
Inverse Reinforcement Learning (IRL) : IRL-это метод, который позволяет агенту изучать функцию вознаграждения от обратной связи человека, а не полагаться на предварительно определенные функции вознаграждения. Это позволяет агенту учиться на более сложных сигналах обратной связи, таких как демонстрации желаемого поведения.
Apprenticeship Learning : Обучение ученичества - это метод, который сочетает в себе IRL с контролируемым обучением, чтобы позволить агенту учиться как на обратной связи с человеком, так и на демонстрациях экспертов. Это может помочь агенту учиться быстрее и эффективно, так как он может учиться как на положительной, так и на отрицательной обратной связи.
Interactive Machine Learning (IML) : IML-это метод, который включает в себя активное взаимодействие между агентом и человеком-экспертом, позволяя эксперту предоставлять отзывы о действиях агента в режиме реального времени. Это может помочь агенту учиться быстрее и эффективно, так как он может получать отзывы о своих действиях на каждом этапе учебного процесса.
Human-in-the-Loop Reinforcement Learning (HITLRL) : Hitlrl-это метод, который включает в себя интеграцию обратной связи человека в процесс RL на нескольких уровнях, таких как формирование вознаграждения, выбор действий и оптимизация политики. Это может помочь повысить эффективность и эффективность системы RLHF, используя преимущества сильных сторон как людей, так и машин.
Вот несколько примеров обучения подкрепления с отзывами человека (RLHF):
Game Playing : в игре отзывы человека могут помочь агенту изучить стратегии и тактики, которые эффективны в разных сценариях игры. Например, в популярной игре в Go эксперты-человеческие эксперты могут предоставить агенту отзывы о его движениях, помогая ему улучшить свой игровой процесс и принятие решений.
Personalized Recommendation Systems : в системах рекомендаций обратная связь с человеком может помочь агенту изучить предпочтения отдельных пользователей, что позволяет предоставить персонализированные рекомендации. Например, агент может использовать отзывы пользователей на рекомендуемых продуктах, чтобы узнать, какие функции наиболее важны для них.
Robotics : в робототехнике обратная связь с человеком может помочь агенту научиться взаимодействовать с физической средой безопасным и эффективным образом. Например, робот может научиться быстрее ориентироваться в новой среде с обратной связью от оператора человека по лучшему пути, который нужно идти или какие объекты следует избегать.
Education : в образовании обратная связь с людьми может помочь агенту научиться более эффективно обучать студентов. Например, преподаватель на основе искусственного интеллекта может использовать отзывы от учителей, на которые лучше всего работают стратегии обучения, помогая персонализировать опыт обучения.
format: - [title](paper link) [links] - author1, author2, and author3... - publisher - keyword - code - experiment environments and datasets
Гибридный цвет: гибкая и эффективная структура RLHF
Гуанминг Шэн, Чи Чжан, Зилингфенг Ю, Сибин Ву, Ван Чжан, Ру Чжан, Янхуа Пэн, Хайбин Лин, Чуан Ву
Ключевое слово: гибкое, эффективное, RLHF Framework
Код: официальный
Аварийный сигнал: выравнивать языковые модели с помощью иерархического моделирования вознаграждений
Юханг Лай, Сиюань Ван, Шудзюн Лю, Сюандзинг Хуан, Чжунгу Вэй
Ключевое слово: иерархическое вознаграждение, задачи генерации открытого текста
Код: официальный
TLCR: Непрерывное вознаграждение уровня токена за мелкозернистое обучение подкреплению на человеческих отзывах
Eunseop Yoon, Hee Suk Yoon, Soohwan Eom, Gunsoo Han, Daniel Wontae Nam, Daejin Jo, Kyoung-Woon On, Марк А. Хасегава-Джонсон, Sungwoong Kim, Chang D. Yoo.
Ключевое слово: непрерывное награду на уровне токена, RLHF
Код: официальный
Выравнивание больших мультимодальных моделей с фактически дополненным RLHF
Zhiqing Sun, Sheng Shen, Shengcao Cao, Haotian Liu, Chunyuan Li, Yikang Shen, Chuang Gan, Liang-Yan Gui, Yu-Xiong Wang, Yiming Yang, Kurt Keutzer, Trevor Darrell
Ключевое слово: фактически дополняется RLHF, Vision & Language, набор данных человеческих предпочтений
Код: официальный
Прямое выравнивание модели с большим языком посредством самообслуживания контрастной оперативной дистилляции
Aiwei Liu, Haoping Bai, Zhiyun Lu, Xiang Kong, Simon Wang, Jiulong Shan, Meng Cao, Lijie Wen
Ключевое слово: без данных о человеческих предпочтениях, самоуправляемость, DPO
Код: официальный
Арифметическое управление LLMS для разнообразных пользовательских предпочтений: выравнивание направленных предпочтений с многоцелевыми вознаграждениями
Haoxiang Wang, Yong Lin, Wei Xiong, Rui Yang, Shizhe Dio, Shuang Qiu, Han Zhao, Tong Zhang
Ключевое слово: предпочтения пользователя, многоцелевая модель вознаграждения, отбор отбора проб.
Код: официальный
Вернуться к основам: повторное повторное усиление оптимизации стиля для обучения на обратной связи с людьми в LLMS
Араш Ахмадиан, Крис Кремер, Матиас Галле, Марзи Фадеи, Джулия Кройцер, Оливье Пиеткин, Ахмет üstün, Сара Хукер
Ключевое слово: онлайн -оптимизация RL, низкая вычислительная стоимость
Код: официальный
Улучшение крупных языковых моделей с помощью мелкозернистого обучения подкреплению с минимальным ограничением редактирования
Zhipeng Chen, Kun Zhou, Wayne Xin Zhao, Junchen Wan, Fuzheng Zhang, Di Zhang, Ji-Rong Wen
Ключевое слово: награда на уровне токена, LLM
Код: официальный
Rlaif vs. RLHF: масштабирование подкрепления, обучение от обратной связи с человеком с обратной связью с ИИ
Харрисон Ли, Самрат Пхатале, Хасан Мансур, Томас Меснард, Йохан Феррет, Келли Рен Лу, Колтон Бишоп, Этан Холл, Виктор Карбун, Абхинав Растоги, Сушант Пракаш
Ключевое слово: rl из обратной связи с искусственным интеллектом
Код: официальный
Принципиальные штрафные методы для обучения Bilevel Atrumborment и RLHF
Хан Шен, Чжуоран Ян, Тиани Чен
Ключевое слово: билевеловая оптимизация
Код: официальный
Плотное вознаграждение бесплатно в подкреплении, обучение от человеческой обратной связи
Алекс Джеймс Чан, Хао Сан, Сэмюэль Холт, Михаэла ван дер Шаар
Ключевое слово: формирование вознаграждений, RLHF
Код: официальный
Минимаксималистский подход к укреплению обучения на человеческой обратной связи
Гокул Свами, Кристоф Данн, Рахул Кирамби, Стивен Ву, Алех Агарвал
Ключевое слово: минимакс-победитель, оптимизация предпочтений самостоятельно
Код: официальный
RLHF-V: На пути к надежным MLLM за счет выравнивания поведения из мелкозернистой исправительной обратной связи с человеком.
Tianyu Yu, Yuan Yao, Haoye Zhang, Taiwen He, Yifeng Han, Ganqu Cui, Jinyi Hu, Zhiyuan Liu, Hai-Tao Zheng, Maosong Sun, Tat-Seng Chua
Ключевое слово: мультимодальные крупные языковые модели, проблема галлюцинации, обучение подкреплению на человеческих отзывах
Код: официальный
Рабочий процесс RLHF: от моделирования вознаграждения до онлайн RLHF
Hanze Dong, Wei Xiong, Bo Pang, Haoxiang Wang, Han Zhao, Yingbo Zhou, Nan Jiang, Doyen Sahoo, Caiming Xiong, Тонг Чжан
Ключевое слово: онлайн -итеративный RLHF, моделирование предпочтений, модели с большими языками
Код: официальный
MAXMIN-RLHF: На пути к справедливому выравниванию крупных языковых моделей с разнообразными человеческими предпочтениями
Souradip Chakraborty, Jiahao Qiu, Hui Yuan, Alec Koppel, Furong Huang, Dinesh Manocha, Amrit Singh Bedi, Mengdi Wang
Ключевое слово: смесь распределений предпочтений, цель выравнивания максмин
Код: официальный
Оптимизация политики сброса набора данных для RLHF
Джонатан Д. Чанг, Венхао Чжан, Оуэн Ортелл, Кианте Брантли, Дипендра Мисра, Джейсон Д. Ли, Вэнь Сан
Ключевое слово: оптимизация политики сброса набора данных
Код: официальный
Плотное представление о награде о выравнивании диффузии текста до изображения с предпочтениями
Shentao Yang, Tianqi Chen, Mingyuan Zhou
Ключевое слово: RLHF для генерации текста до изображения, плотное улучшение вознаграждения DPO, эффективное выравнивание
Код: официальный
Самостоятельная настройка преобразует слабые языковые модели в сильные языковые модели
Zixiang Chen, Yihe Deng, Huishuo Yuan, Kaixuan Ji, Quanquan gu
Ключевое слово: самостоятельная настройка
Код: официальный
Расшифровал RLHF: критический анализ обучения подкреплению от обратной связи с людьми для LLMS
Шреяс Чаудхари, Пранджал Аггарвал, Вишвак Мурахари, Танмей Раджпурохит, Эшвин Калян, Картик Нарасимхан, Амит Дешпанде, Бруно Кастро да Силва
Ключевое слово: rlhf, оракулярное вознаграждение, анализ модели вознаграждения, опрос
Столкновение вознаграждения за чрезмерную оптимизацию для диффузионных моделей: перспектива индуктивных и первенцев предвзятости
Ziyi Zhang, Sen Zhang, Yibing Zhan, Yong Luo, Yonggang Wen, Dacheng Tao
Ключевое слово: диффузионные модели, выравнивание, обучение подкреплению, RLHF, вознаграждение, переооооооооооооптиза, предвзятость первенства
Код: официальный
О диверсифицированных предпочтениях крупного языкового выравнивания модели
Dun Zeng, Yong Dai, Pengyu Cheng, Tianhao Hu, Wanshun Chen, Nan Du, Zenglin Xu
Ключевое слово: выравнивание общих предпочтений, метрики моделирования вознаграждений, LLM
Код: официальный
Выравнивание обратной связи толпы с помощью моделирования вознаграждения о распределении
Dexun Li, Cong Zhang, Kuicai Dong, Derrick Goh Sxin Deik, Ruiming Tang, Yong Liu
Ключевое слово: RLHF, распределение предпочтений, выравнивание, LLM
Помимо выравнивания с одним из однопометров: многоцелевая оптимизация прямых предпочтений
Чжанхуи Чжоу, Цзе Лю, Чао Ян, Цзин Шао, Юй Лю, Сянгю Юэ, Ванли Уян, Ю Цяо
Ключевое слово: многообъясняющий RLHF без вознаграждения, DPO
Код: официальный
Эмулированное рассуждение: выравнивание безопасности для крупных языковых моделей может иметь неприятные последствия!
Чжанхуи Чжоу, Цзе Лю, Жичен Донг, Цзяхенг Лю, Чао Ян, Ванли Уян, Ю Цяо
Ключевое слово: атака времени вывода LLM, DPO, создание вредных LLM без обучения
Код: официальный
Теоретический анализ обучения Нэш на обратной связи с человеком под общим KL-регулярным предпочтением
Chenlu Ye, Wei Xiong, Yuheng Zhang, Nan Jiang, Tong Zhang
Ключевое слово: RLHF на основе игры, Nash Learning, выравнивание под наградным моделью без модели Oracle
Смягчение налога на выравнивание RLHF
Yong Lin, Hangyu Lin, Wei Xiong, Shizhe Diao, Jianmeng Liu, Jipeng Zhang, Rui Pan, Haoxiang Wang, Wenbin Hu, Hanning Zhang, Hanze Dong, Renjie Pi, Han Zhao, Nan Jiang, Heng Ji, Yuan Yao, Longao
Ключевое слово: rlhf, налог на выравнивание, катастрофическое забывание
Обучение диффузионных моделей с обучением подкрепления
Кевин Блэк, Майкл Джаннер, Йилун Дю, Илья Костроков, Сергей Левин
Ключевое слово: обучение подкреплению, RLHF, диффузионные модели
Код: официальный
Aligndiff: выравнивание разнообразных человеческих предпочтений посредством модели диффузии, подлежащей поведению, диффузионной модели
Зибин Донг, Ифу Юань, Цзяньи Хао, Фей Ни, Яо Му, Ян Чжэн, Юдзин Ху, Танджи Л.В., Чанджи Фан, Зиниг Ху
Ключевое слово: подкрепление обучения; Диффузионные модели; Rlhf; Предпочтения выравнивание
Код: официальный
Плотное вознаграждение бесплатно в подкреплении, обучение от человеческой обратной связи
Алекс Дж. Чан, Хао Сан, Сэмюэль Холт, Михаэла ван дер Шаар
Ключевое слово: rlhf
Код: официальный
Преобразование и объединение вознаграждений за выравнивание крупных языковых моделей
Зихао Ван, Чираг Нагпал, Джонатан Берант, Джейкоб Эйзенштейн, Алекс Д'Амур, Санми Койехо, Виктор Вейч
Ключевое слово: rlhf, aligning, llm
Параметр эффективное подкрепление обучение от обратной связи с человеком
Hakim Sidahmed, Samrat Phatale, Алекс Хатчесон, Чжуонан Лин, Чжан Чен, Зак Ю, Джарвис Джин, Симала Чаудхари, Романа Комарица, Кристиан Альхейм, Йонгао Чжу, Боуэн Ли, Сараван Ганш, Билл Бирн, Джессика Хффмана, Хассан Манс, Ианс -Манс. , Абхинад Растоги, Лукас Диксон
Ключевые слова: RLHF, эффективный метод параметров, низкие вычислительные затраты, LLM, VLM
Улучшение обучения подкреплению от обратной связи человека с помощью эффективного ансамбля модели вознаграждения
Шун Чжан, Чженфанг Чен, Санли Чен, Йиканг Шен, Чжицинг Солнца, Чуан Ган
Ключевые слова: rlhf, ансамбль вознаграждения, эффективный метод ансамбля
Общая теоретическая парадигма для понимания обучения на человеческих предпочтениях
Мохаммад Гешлагхи Азар, Марк Роуленд, Билал Пиот, Даниэль Го, Даниэле Каланриелло, Михал Валько, Реми Мунос
Ключевые слова: RLHF, парные предпочтения
Мелкозернистая обратная связь с человеком дает лучшие награды за обучение на языковой модели
Zeqiu Wu, Yushi Hu, Weijia Shi, Nouha Dziri, Alane Suhr, Prithviraj Ammanabrolu, Noah A. Smith, Mari Ostendorf, Hannaneh Hajishirzi
Ключевое слово: rlhf, вознаграждение на уровне предложения, LLM
Код: официальный
Предпочтение отдавливаемое
Шентао Ян, Шудзиан Чжан, Congying Xia, Yihao Feng, Caiming Xiong, Mingyuan Zhou
Ключевое слово: RLHF, руководство по обучению на уровне токена, альтернативная/онлайн-структура обучения, минималистские цели обучения
Код: официальный
Фантастические награды и как их приручить: тематическое исследование по обучению вознаграждениям для систем диалога, ориентированных на задание, ориентированные на задачи
Yihao Feng*, Shentao Yang*, Shujian Zhang, Jianguo Zhang, Caiming Xiong, Mingyuan Zhou, Huan Wang
Ключевое слово: rlhf, генрализованное обучение функции вознаграждения, использование функций вознаграждения, ориентированная на задача система диалога, обучение к ранке
Код: официальный
Обучение обратному предпочтению: RL на основе предпочтений без вознаграждения
Джои Хейна, Дорса Садиг
Ключевое слово: обратное обучение предпочтения, без модели вознаграждения
Код: официальный
Alpacafarm: структура моделирования для методов, которые учатся на обратной связи с человеком
Янн Дюбуа, Чен Сюэхен Ли, Рохан Таори, Тиани Чжан, Ишаан Гулраджани, Джимми Ба, Карлос Гестрин, Перси С. Лян, Татсунори Б. Хасимото
Ключевое слово: rlhf, структура симуляции
Код: официальный
Оптимизация ранжирования предпочтений для выравнивания человека
Фейфан Сонг, Боуэн Ю, Мингхао Ли, Хайян Ю, Фей Хуанг, Юнбин Ли, Хуфенг Ван
Ключевое слово: оптимизация ранжирования предпочтения
Код: официальный
Оптимизация состязательных предпочтений
Пенгью Ченг, Ифан Ян, Цзянь Ли, Юн Дай, Нэн Ду
Ключевое слово: RLHF, GAN, Adversarial Games
Код: официальный
Итеративное предпочтение обучению от обратной связи человека: теория и практика для RLHF в рамках KL-ограничений
Вэй Сионг, Ханзе Донг, Ченлу Ю, Зики Ван, Хан Чжун, Хенг Цзи, Нан Цзян, Тонг Чжан
Ключевое слово: rlhf, итеративный DPO, математическая основа
Образец эффективного обучения подкреплению от обратной связи человека через активное исследование
Viraj Mehta, Vikramjeet Das, Ojash Neopane, Yijia Dai, Ilija Bogunovic, Джефф Шнайдер, Вилли Нейсвангер
Ключевое слово: rlhf, эффективность образца, исследования
Подкрепление обучения на статистической обратной связи: путешествие от тестирования AB до тестирования муравья
Фейян Хан, Йимин Вэй, Чжаофенг Лю, Янсинг Ци
Ключевое слово: rlhf, ab testing, rlsf
Базовый анализ способности моделей вознаграждений точно анализировать модели фундамента при смене распределения
Бен Пикус, Уилл Левин, Тони Чен, Шон Хендрикс
Ключевое слово: rlhf, ood, сдвиг дистрибуции
Данное по сравнению с выравниванием больших языковых моделей с отзывом человека через естественный язык
Ди Джин, Шикиб Мехри, Деваманю Хазарика, Айшвария Падмакумар, Сунгжин Ли, Ян Лю, Махди Намазифар
Ключевое слово: rlhf, эффективность данных, выравнивание
Давайте подкрепляем шаг за шагом
Сара Пан, Владислав Лиалин, Шерин Мукатира, Анна Рамшиски
Ключевое слово: rlhf, рассуждение
Прямая оптимизация политики на основе прямых предпочтений без моделирования вознаграждения
Гаон Ан, Джунхьок Ли, Синдонг Зуо, Норио Косака, Кёнг-Мин Ким, Хён Ох Песня
Ключевое слово: RLHF без моделирования вознаграждений, контрастное обучение, офлайновое обучение рефринформированию
Aligndiff: выравнивание разнообразных человеческих предпочтений посредством модели диффузии, подлежащей поведению, диффузионной модели
Зибин Донг, Ифу Юань, Цзяньи Хао, Фей Ни, Яо Му, Ян Чжэн, Юдзин Ху, Танджи Л.В., Чанджи Фан, Зиниг Ху
Ключевое слово: RLHF, выравнивание, диффузионная модель
Eureka: дизайн вознаграждения на уровне человека через кодирование больших языковых моделей
Yecheng Jason Ma, William Liang, Guanzhi Wang, De-An Huang, Osbert Bastani, Dinesh Jayaraman, Yuke Zhu, Fan Linxi, Anima Anandkumar
Ключевое слово: LLM на основе проектирования функций вознаграждения
Безопасный RLHF: безопасное подкрепление, обучение от человеческой обратной связи
Josef Dai, Xuehai Pan, Ruiyang Sun, Jiaming Ji, Xinbo Xu, Mickel Liu, Yizhou Wang, Yaodong Yang
Ключевое слово: продажа RL, LLM Fine-Ture
Качественное разнообразие через отзывы человека
Ли Дин, Дженни Чжан, Джефф Клюне, Ли Спектор, Джоэл Леман
Ключевое слово: качественное разнообразие, диффузионная модель
Remax: простой, эффективный и эффективный метод обучения подкреплению для выравнивания больших языковых моделей
Ziniu Li, Tian Xu, Yushun Zhang, Yang Yu, Ruoyu Sun, Zhhi-Quan Luo
Ключевое слово: вычислительная эффективность, метод снижения дисперсии
Настройка моделей компьютерного зрения с вознаграждением за задание
Андре Сюзано Пинто, Александр Колесников, Юг Ши, Лукас Бейер, Сяуа Чжая
Ключевое слово: настройка вознаграждения в компьютерном видении
Мудрость задним числом делает языковые модели лучшими последователями обучения
Тяньджун Чжан, Фанхен Лю, Джастин Вонг, Питер Аббейл, Джозеф Э. Гонсалес
Ключевое слово: задним числом инструкции по переходу, система RLHF, сеть не требуется.
Код: официальный
Язык инструкции по подкреплению обучения для координации человека-аи
Хенгьюан Ху, Дорса Садиг
Ключевое слово: координация человека-аи, выравнивание предпочтений человека, обусловленное обучение RL
Выравнивание языковых моделей с офлайновым подкреплением обучения на человеческом образовании
Цзянь Ху, Ли Тао, Джун Ян, Чендлер Чжоу
Ключевое слово: выравнивание на основе решений, офлайновое обучение подкреплению, система RLHF
Оптимизация ранжирования предпочтений для выравнивания человека
Фейфан Сонг, Боуэн Ю, Мингхао Ли, Хайян Ю, Фей Хуанг, Юнбин Ли и Хуфенг Ванг
Ключевое слово: контролируемое выравнивание предпочтений человека, расширение ранжирования предпочтений
Код: официальный
Соединение пробела: опрос об интеграции (человеческой) обратной связи для генерации естественного языка
Патрик Фернандес, Аман Мадаан, Эмми Лю, Антонио Фаринхас, Педро Энрике Мартинс, Аманда Берш, Хосе Г.К. де Соуза, Шюян Чжоу, Тонгшуанг Ву, Грахэм Нойбиг, Андре Форт Мартинс
Ключевое слово: генерация естественного языка, интеграция обратной связи с человеком, формализация обратной связи и таксономия, обратная связь ИИ и принципы, основанные на
GPT-4 Технический отчет
Openai
Ключевое слово: крупномасштабная, мультимодальная модель, модель с трансформаторами, тонко настроенная использованная RLHF
Код: официальный
Набор данных: Drop, Winogrande, Hellaswag, Arc, Humaneval, GSM8K, MMLU, правдифка
Плот: вознаграждение ранжируется на финал для выравнивания модели генеративного фундамента
Ханзе Донг, Вэй Сионг, Дипаншу Гоял, Руи Пан, Шицхе Диао, Джипенг Чжан, Кашун Шум, Тонг Чжан
Ключевое слово: отбор отбора проб, альтернатива PPO, диффузионная модель
Код: официальный
RRHF: Ранные реакции на выравнивание языковых моделей с человеческой обратной связью без слез
Zheng Yuan, Hongyi Yuan, Chuanqi Tan, Wei Wang, Songfang Huang, Fei Huang
Ключевое слово: новая парадигма для RLHF
Код: официальный
Несколько выстрелов в обучении для RL человека в петле
Джои Хейна, Дорса Садиг
Ключевое слово: предпочтение обучению, интерактивное обучение, многозадачное обучение, расширение пула доступных данных путем просмотра RL человека в петле
Код: официальный
Лучше выровнять модели текста до изображения с человеческими предпочтениями
Сяси Ву, Кецян Сан, Фэн Чжу, Руи Чжао, Хоншенг Ли
Ключевое слово: диффузионная модель, текст к изображению, эстетика
Код: официальный
ImagereWard: изучение и оценка человеческих предпочтений для генерации текста до изображения
Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, Yuxiao Dong
Ключевое слово: общее назначение для людей с человеческими предпочтениями RM, оценка генеративных моделей текста к изображению
Код: официальный
Набор данных: Coco, DiffusionDB
Выравнивание моделей текста до изображения с использованием обратной связи с человеком
Кимин Ли, Хао Лю, Муньюнг Рю, Оливия Уоткинс, Юцин Дю, Крейг Бутилье, Питер Аббейл, Мохаммад Гавамзаде, Шиксиан Шейн Гу
Ключевое слово: модель текста к изображению, стабильная диффузионная модель, функция вознаграждения, которая прогнозирует обратную связь человека
Visual Chatgpt: разговор, рисование и редактирование с моделями Visual Foundation
Chenfei Wu, Shengming Yin, Weizhen Qi, Xiaodong Wang, Zecheng Tang, Nan Duan
Ключевое слово: модели Visual Foundation, Visual Chatgpt
Код: официальный
Предварительные языковые модели с человеческими предпочтениями (PHF)
Томаш Корбак, Кеджян Ши, Анжелика Чен, Расика Бхалерао, Кристофер Л. Бакли, Джейсон Пханг, Сэмюэль Р. Боуман, Итан Перес
Ключевое слово: предварительная подготовка, автономный RL, Transformer Решения
Код: официальный
Выравнивание языковых моделей с предпочтениями посредством минимизации F-дивергенции (F-DPG)
Dongyoung Go, Tomasz Korbak, Germán Kruszewski, Jos Rozen, Nahyeon Ryu, Marc Dymetman
Ключевое слово: F-Divergence, RL с штрафами KL
Принципиальное обучение подкреплению с отзывами человека из парных или k-vise сравнений
Banghua Zhu, Jiantao Jiao, Michael I. Jordan
Ключевое слово: пессимистичный MLE, Max-Entropy IRL
Способность к моральной самокоррекции в моделях крупных языков
Антроп
Ключевое слово: улучшить моральные возможности самокорректировки за счет увеличения обучения RLHF
Набор данных; БАРБЕКЮ
Является ли подкрепление обучения (не) для обработки естественного языка?
Раджкумар Рамамурти, Притхвирадж Амманабролу, Кианте, Брантли, Джек Хессель, Рафет Сифа, Кристиан Баукхейдж, Ханнане Хаджисирзи, Йецзин Чой
Ключевое слово: оптимизация языковых генераторов с помощью RL, Benchmark, Performant RL -алгоритм
Код: официальный
Набор данных: IMDB, Commongen, CNN Daily Mail, Totto, WMT-16 (EN-DE), NorgativeQA, DailyDialog
Законы масштабирования за чрезмерную оптимизацию модели вознаграждения
Лео Гао, Джон Шульман, Джейкоб Хилтон
Ключевое слово: модель Gold Ward Model Train Proxy Model, размер набора данных, размер параметров политики, BON, PPO
Улучшение выравнивания диалоговых агентов с помощью целевых человеческих суждений (воробей)
Amelia Glaese, Nat McAleese, Maja Trębacz, et al.
Ключевое слово: агент по поиску информации, поиск информации, разбил хороший диалог на правила естественного языка, DPC, взаимодействует с моделью, чтобы вызвать нарушение конкретного правила (состязательное зондирование)
Набор данных: натуральные вопросы, ELI5, качество, витриака, Winobias, BBQ
Красные языковые модели для уменьшения вреда: методы, масштабирование поведения и извлеченные уроки
Deep Ganguli, Liane Lovitt, Jackson Kernion, et al.
Ключевое слово: модель языка красной команды, исследуйте поведение масштабирования, прочитайте набор данных команды
Код: официальный
Динамическое планирование в открытом диалоге с использованием обучения подкреплению
Дебора Коэн, Лункунг Рю, Йинлам Чоу, Оргад Келлер, Идо Гринберг, Авинатан Хассидим, Майкл Финк, Йосси Матиас, Иган Шпекер, Крейг Бутилье, Гал Элидан
Ключевое слово: в реальном времени, открытая система диалога, соединяет краткое внедрение состояния разговора с помощью языковых моделей, CAQL, CQL, BERT
Quark: управляемое генерацию текста с усиленным отучением
Ximing Lu, Sean Welleck, Jack Hessel, Liwei Jiang, Lianhui Qin, Peter West, Prithviraj Ammanabrolu, Yejin Choi
Ключевое слово: тонкая настройка языковой модели по сигналам того, что не следует делать, Transformer, LLM настройка с PPO
Код: официальный
Набор данных: Написание Propmpts, SST-2, Wikitext-103
Обучение полезного и безвредного помощника по подкреплению обучения на отзыве человека
Yuntao Bai, Andy Jones, Kamal Ndousse, et al.
Ключевое слово: безвредные помощники, онлайн -режим, надежность обучения RLHF, обнаружение OOD.
Код: официальный
Набор данных: Viriviaqa, Hellaswag, Arc, OpenBookqa, Lambada, Humaneval, Mmlu, Trildufulqa
Учебные языковые модели для поддержки ответов с проверенными цитатами (Gophercite)
Джейкоб Меник, Майя Требач, Владимир Микулик, Джон Асланидес, Фрэнсис Сонг, Мартин Чедвик, Миа Глаз, Сюзанна Янг, Люси Кэмпбелл-Гиллингем, Джеффри Ирвинг, Нат Макализ
Ключевое слово: генерируйте ответы, которые ссылаются на конкретные доказательства, воздерживаются от ответа, когда не уверены
Набор данных: естественные вопросы, eli5, качество, правдиворка
Модели языка обучения, чтобы следовать инструкциям с обратной связью с человека (Instructgpt)
Long Ouyang, Jeff Wu, Xu Jiang, et al.
Ключевое слово: большая языковая модель, выравнивание языковой модели с человеческими намерениями
Код: официальный
Набор данных: правдифка, RealtoxicityPrompts
Конституционный ИИ: безвредность от обратной связи ИИ
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, et al.
Ключевое слово: RL от AI обратной связи (RLAIF), обучение безвредного помощника ИИ с помощью SelfiMmovement, цепочка стиля, контроля AI более точно
Код: официальный
Обнаружение языкового поведения с помощью модельных оценок
Этан Перес, Сэм Рингер, Камил Лукошют, Карина Нгуен, Эдвин Чен и др.
Ключевое слово: автоматически генерировать оценки с LMS, больше RLHF усугубляет LMS, оценочные оценки LM являются высококачественными
Код: официальный
Набор данных: барбекю, схемы сногендера
Моделирование вознаграждений не Марковийского вознаграждения из метков
Джозеф рано, Том Бьюли, Кристина Эверс, Сарвапали Рамчурн
Ключевое слово: моделирование вознаграждений (RLHF), не-марковианское, многочисленное обучение, интерпретируемость
Код: официальный
WebGPT: вопросы вопроса о браузере с обратной связью (WebGPT)
Рейтихиро Накано, Джейкоб Хилтон, Сучир Баладжи и др.
Ключевое слово: Поиск модели в Интернете и предоставьте ссылку , Имитационное обучение , BC, Вопрос о длинной форме
Набор данных: eli5, triviaqa, rightfulqa
Рекурсивно суммирование книг с человеческой обратной связью
Джефф Ву, Лонг Уян, Даниэль М. Циглер, Нисан Стинон, Райан Лоу, Ян Лейк, Пол Кристиан
Ключевое слово: модель, обученная небольшой задаче, чтобы помочь человеку оценить более широкую задачу, до н.э.
Набор данных: книги, повествование
Пересмотр слабых мест обучения подкреплению для перевода нейронной машины
Сэмюэль Кигеленд, Джулия Кройцер
Ключевое слово: успех градиента политики связан с вознаграждением, а не с формой распределения вывода, машинного перевода, NMT, адаптации домена
Код: официальный
Набор данных: WMT15, IWSLT14
Научиться суммировать от обратной связи с человеком
Нисан Стинон, Лонг Ояанг, Джефф Ву, Даниэль М. Циглер, Райан Лоу, Челси Восс, Алек Рэдфорд, Дарио Амодеэй, Пол Кристиан
Ключевое слово: забота о качестве краткого, потери обучения влияют на поведение модели, модель вознаграждения обобщает новые наборы данных
Код: официальный
Набор данных: TL; DR, CNN/DM
Чико настраивающие языковые модели от человеческих предпочтений
Даниэль М. Циглер, Нисан Стейнон, Джеффри Ву, Том Б. Браун, Алек Рэдфорд, Дарио Амодеей, Пол Кристиан, Джеффри Ирвинг
Ключевое слово: вознаграждение за изучение языка, продолжение текста с позитивным настроением, краткое задание, физическое описательное
Код: официальный
Набор данных: TL; DR, CNN/DM
Масштабируемое выравнивание агента через моделирование вознаграждения: направление исследования
Ян Лейк, Дэвид Крюгер, Том Эверитт, Милжан Мартик, Вишал Майни, Шейн Легг
Ключевое слово: проблема выравнивания агента, изучить вознаграждение от взаимодействия, оптимизировать вознаграждение с помощью RL, рекурсивное моделирование вознаграждения
Код: официальный
Энг: Атари
Награда за обучение от человеческих предпочтений и демонстраций в Атари
Борха Ибарз, Ян Лейк, Тобиас Полен, Джеффри Ирвинг, Шейн Легг, Дарио Амодеей
Ключевое слово: экспертная демонстрационная траектория Проблема взлома, шум в человеческой метке
Код: официальный
Энг: Атари
Глубокий урон: формирование интерактивного агента в высокомерных государственных пространствах
Гаррет Уорнелл, Николас Уэйтович, Вернон Лоухерн, Питер Стоун
Ключевое слово: состояние высокого размера, используйте ввод человеческого тренера
Код: третья сторона
Энг: Атари
Глубокое подкрепление обучения от человеческих предпочтений
Пол Кристиан, Ян Лейк, Том Б. Браун, Милжан Мартик, Шейн Легг, Дарио Амодеэй
Ключевое слово: исследуйте цель, определенную в предпочтениях человека между парами сегментации траекторий, узнайте более сложную вещь, чем обратная связь с людьми
Код: официальный
Энг: Атари, Моджоко
Интерактивное обучение от обратной связи с политикой, зависимых от политики, человека
Джеймс МакГлашан, Марк К. Хо, Роберт Лофтин, Бей Пенг, Гуан Ван, Дэвид Робертс, Мэтью Э. Тейлор, Майкл Л. Литтман
Ключевое слово: решение зависит от текущей политики, а не отзывы человека, учиться на обратной связи, зависимой от политики, которая сходится к локальному оптимальному
format: - [title](codebase link) [links] - author1, author2, and author3... - keyword - experiment environments, datasets or tasks
Verl: обучение армированию двигателя вулкана для LLM
Seedance Seed Mlsys Team & Hku: Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, Chuan Wu
Ключевое слово: гибкое, эффективное, RLHF Framework
Задачи: RLHF, рассуждения, включая математику и код.
Openrlhf
Openrlhf
Ключевое слово: 70b, rlhf, deepspeed, ray, vllm
Задача: простой в использовании, масштабируемой и высокопроизводительной структуре RLHF (поддержка 70B+ полная настройка и Lora & Mixtral & KTO).
Palm + rlhf - pytorch
Фил Ван, Яхин Захиди, Икко Эльтоцир Ашимин, Эрик Алькаид
Ключевое слово: трансформаторы, пальмовая архитектура
Набор данных: enwik8
LM-Human-Preferences
Даниэль М. Циглер, Нисан Стейнон, Джеффри Ву, Том Б. Браун, Алек Рэдфорд, Дарио Амодеей, Пол Кристиан, Джеффри Ирвинг
Ключевое слово: вознаграждение за изучение языка, продолжение текста с позитивным настроением, краткое задание, физическое описательное
Набор данных: TL; DR, CNN/DM
Следуют инструментации, обрабатывают обратную связь
Long Ouyang, Jeff Wu, Xu Jiang, et al.
Ключевое слово: большая языковая модель, выравнивание языковой модели с человеческими намерениями
Набор данных: Pelightfulqa RealtoxicityPrompts
Обучение усиленной трансформаторе (TRL)
Leandro von Werra, Younes Belkada, Lewis Tunstall, et al.
Ключевое слово: Train LLM с RL, PPO, Transformer
Задача: IMDB настроение
Трансформирование подкрепление обучение x (TRLX)
Джонатан Тау, Леандро фон Верра и др.
Ключевое слово: распределенная учебная структура, языковые модели на основе T5, Train LLM с RL, PPO, ILQL
Задача: Fine Tuning LLM с RL с использованием предоставленной функции вознаграждения или меченного вознаграждением набора данных
RL4LMS (модульная библиотека RL для точной настройки языковых моделей к человеческим предпочтениям)
Раджкумар Рамамурти, Притхвирадж Амманабролу, Кианте, Брантли, Джек Хессель, Рафет Сифа, Кристиан Баукхейдж, Ханнане Хаджисирзи, Йецзин Чой
Ключевое слово: оптимизация языковых генераторов с помощью RL, Benchmark, Performant RL -алгоритм
Набор данных: IMDB, Commongen, CNN Daily Mail, Totto, WMT-16 (EN-DE), NorgativeQA, DailyDialog
Lamda-rlhf-pytorch
Фил Ван
Ключевое слово: Ламда, Механизм внимания
Задача: Предварительное обучение с открытым исходным кодом.
Textrl
Эрик Лам
Ключевое слово: трансформатор Huggingface
Задача: генерация текста
Env: Pfrl, тренажерный зал
minrlhf
Томфостер
Ключевое слово: PPO, минимальная библиотека
Задача: образовательные цели
Темно-скорость-чат
Microsoft
Ключевое слово: доступное обучение RLHF
Дромедарь
IBM
Ключевое слово: минимальный человеческий надзор, самоотверженное
Задача: модель самосовершенствованного языка, обученная минимальным человеческим надзором
Fg-rlhf
Zeqiu Wu, Yushi Hu, Weijia Shi, et al.
Ключевое слово: мелкозернистый RLHF, обеспечивающий вознаграждение после каждого сегмента, включая несколько среднеквадратичных средств, связанных с различными типами обратной связи
Задача: структура, которая позволяет обучение и обучение на вознаграждении, которые мелкозернистые по плотности и множеству среднеквадратичных средств -SAFE-RLHF
Xuehai Pan, Ruiyang Sun, Jiaming Ji, et al.
Ключевое слово: поддерживать популярные предварительно обученные модели, большой набор данных, меченный человеком, многомасштабные метрики для проверки ограничений безопасности, настраиваемые параметры
Задача: LLM с ограниченной стоимостью через Safe RLHF
format: - [title](dataset link) [links] - author1, author2, and author3... - keyword - experiment environments or tasks
HH-RLHF
Бен Манн, глубокий гангули
Ключевое слово: набор данных по предпочтениям человека, красные данные команды, созданные машины
Задача: набор данных с открытым исходным кодом для данных о предпочтениях человека о полезности и безвредности
Стэнфордский набор данных человеческих предпочтений (SHP)
Ethayarajh, Kawin и Zhang, Heidi и Wang, Yizhong и Jurafsky, Dan
Ключевое слово: естественный набор данных и написанный человеком, 18 различных предметных областей
Задача: предназначено для обучения моделей вознаграждения RLHF
ReptSource
Стивен Х. Бах, Виктор Санх, Чжэн-Син Йонг и соавт.
Ключевое слово: поощренные наборы данных английского языка, отображение примера данных на естественный язык
Задача: инструментарий для создания, обмена и использования подсказок естественного языка
Структурированные коллекции ресурсов заземления знаний (SKG)
Tianbao Xie, Chen Henry Wu, Peng Shi et al.
Ключевое слово: структурированное заземление знаний
Задача: Сбор наборов данных связан со структурированным заземлением знаний
Коллекция FLAN
Longpre Shayne, Hou Le, Vu Tu et al.
Задача: сборы компилируют наборы данных от Flan 2021, P3, супер-натуральные инструкции
RLHF-Reward-Datasets
Yiting xie
Ключевое слово: автоматический набор данных
webgpt_comparisons
Openai
Ключевое слово: написанный человеком набор данных, ответ на вопрос о длинных формах формы
Задача: тренировать модель ответа на вопросы с длинной формой, чтобы соответствовать предпочтениям человека
Summarize_from_feedback
Openai
Ключевое слово: написанный человеком набор данных, суммирование
Задача: обучить модель суммирования, чтобы соответствовать человеческим предпочтениям
Дахоа/Синтетическая-Инстакция-GPTJ-PAIRWISE
Дахоа
Ключевое слово: написанный человеком набор данных, синтетический набор данных
Стабильное выравнивание - обучение выравнивания в социальных играх
Рурибо Лю, Руисин (Рэй) Ян, Цян Пенг
Ключевое слово: данные взаимодействия, используемые для обучения выравниванию, запустите в песочнице
Задача: тренируйтесь на записанных данных взаимодействия в моделируемых социальных играх
Лима
Meta ai
Ключевое слово: без какого -либо RLHF, мало тщательно кураторских подсказок и ответов
Задача: набор данных, используемый для обучения модели LIMA
[OpenAI] CHATGPT: оптимизация языковых моделей для диалога
[Объятие лица] иллюстрируя подкрепление обучения на человеческой обратной связи (RLHF)
[Zhihu] 通向 agi 之路 : 大型语言模型 (llm) 技术精要
[Zhihu] 大语言模型的涌现能力 : 现象与解释
[Zhihu] 中文 Hh-rlhf 数据集上的 ppo 实践
[W & B Полностью связан] Понимание подкрепления, обучение на отзывах человека (RLHF)
[DeepMind] Обучение через отзыв человека
[Понятие] 深入理解语言模型的突现能力
[Понятие] 拆解追溯 GPT-3.5 各项能力的起源
[GIST] УЧЕБНО
[YouTube] Джон Шульман - Увеличение подкрепления от отзывов человека: прогресс и проблемы
[Openai / arize] openai по обучению подкреплению с обратной связью с человека
[Encord] Руководство по подкреплению обучения от обратной связи с человеком (RLHF) для компьютерного зрения
[Weixun Wang] Обзор RL (HF)+LLM
турецкий
Наша цель - сделать это репо еще лучше. Если вы заинтересованы в соревнованиях, пожалуйста, обратитесь к инструкциям в вкладе.
Awesome RLHF выпускается по лицензии Apache 2.0.


