scratchplot story generation
1.0.0
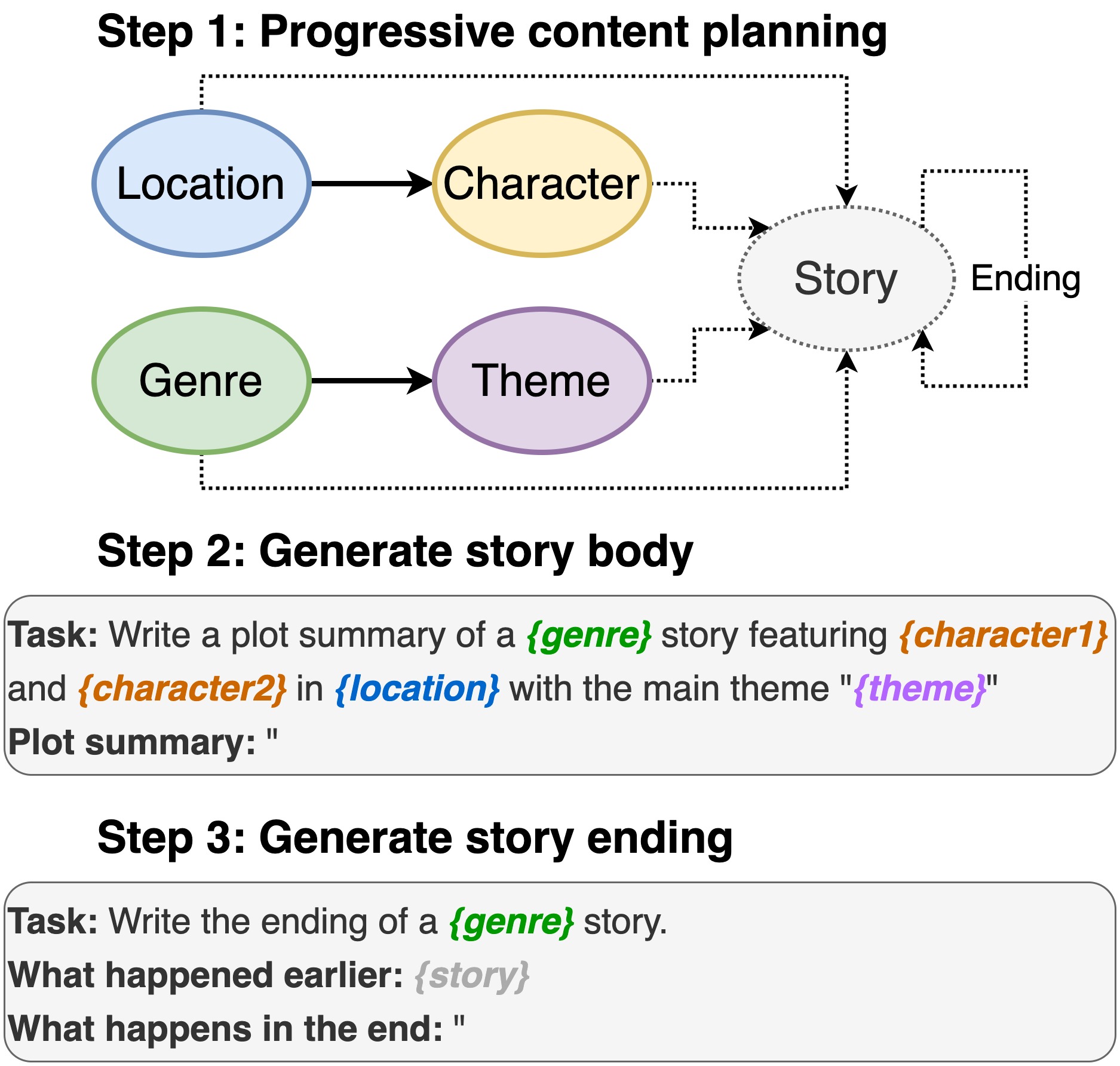
Этот репозиторий содержит код для написания сюжета из предварительно обученных языковых моделей , чтобы появиться в INLG 2022. В статье вводится метод для сначала подсказка PLM для составления плана контента. Затем мы генерируем тело истории и заканчиваем кондиционированным планом содержания. Кроме того, мы придерживаемся сгенерированного и ранга, используя дополнительные PLMS для ранжирования сгенерированных (исторических, конечных) пар.
Это репо сильно полагается на Дино. Поскольку мы внесли некоторые незначительные изменения, мы включили полный код для простоты использования.
В том числе местоположение, актерский состав, жанр и тема.
sh run_plot_static_gpu.shЭлементы плана контента генерируются один раз и хранятся. При генерации историй системные образцы из элементов сгенерированного сюжетом в автономном режиме.
sh run_plot_dynamic_gpu_single.shsh run_plot_dynamic_gpu_batch.sh--no_cuda ко всем командам, которые вызывает dino.pyТребуется Python3. Протестировано на Python 3.6 и 3.8.
pip3 install -r requirements.txt import nltk
nltk . download ( 'punkt' )
nltk . download ( 'stopwords' )Если вы используете код в этом репозитории, пожалуйста, укажите следующую статью:
@inproceedings{jin-le-2022-plot,
title = "Plot Writing From Pre-Trained Language Models",
author = "Jin, Yiping and Kadam, Vishakha and Wanvarie, Dittaya",
booktitle = "Proceedings of the 15th International Natural Language Generation conference",
year = "2022",
address = "Maine, USA",
publisher = "Association for Computational Linguistics"
}
Если вы используете Dino для других задач, также укажите следующую бумагу:
@article{schick2020generating,
title={Generating Datasets with Pretrained Language Models},
author={Timo Schick and Hinrich Schütze},
journal={Computing Research Repository},
volume={arXiv:2104.07540},
url={https://arxiv.org/abs/2104.07540},
year={2021}
}


