OneForAll
1.0.0
Бумага: https://arxiv.org/abs/2310.00149
Авторы: Хао Лю, Джируй Фенг, Леченг Конг, Нинью Лян, Дахенг Тао, Йисин Чен, Мухан Чжан
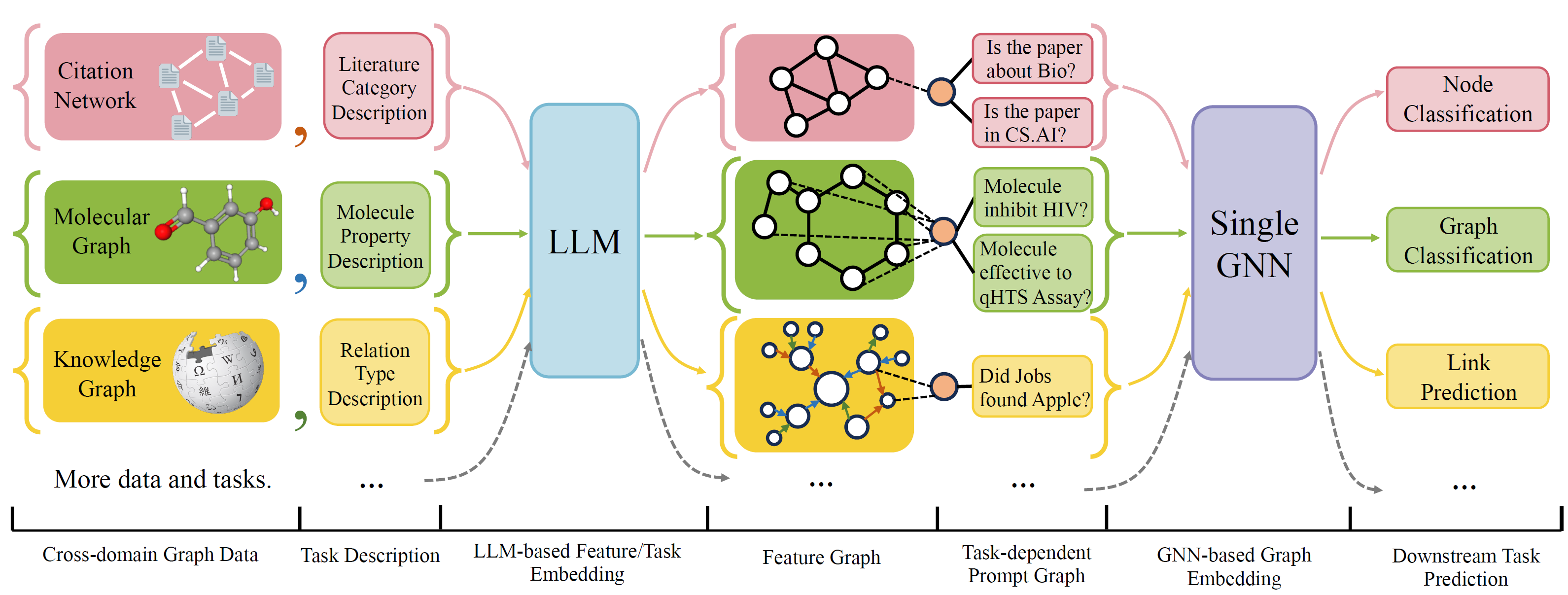
OFA - это общая структура классификации графиков, которая может решать широкий диапазон задач классификации графиков с помощью одной модели и одного набора параметров. Задачи-это междомен (например, сеть цитирования, молекулярный график, ...) и перекрестные задачи (например, несколько выстрелов, с нулевым выстрелом, уровнем графа, узел, ...)
OFA используют естественные языки для описания всех графиков и используйте LLM для встроенного встроенного в одном и том же пространстве встраивания, что позволяет тренировку между доменом с использованием одной модели.
OFA предлагает Paradiagm, что все задачи преобразуются в запрос на график. Таким образом, модель последующей способности может считывать информацию о задачах и соответствующим образом прогнозировать целевую цель, без необходимости регулировать параметры модели и архитектуру. Следовательно, одна модель может быть перекрестной задачей.
OFA курировал список наборов данных графиков из разных источников и доменов и описывает узлы/ребра на графиках с помощью систематического протокола описания. Мы благодарим предыдущие работы, в том числе, OGB, Gimlet, Moleculenet, Graphllm и Villmow за предоставление прекрасных необработанных графических данных/текстовых данных, которые делают нашу работу возможной.
OneForall прошла серьезный пересмотр, где мы очистили код и исправили несколько сообщенных ошибок. Основными обновлениями являются:
Если вы ранее использовали наш репозиторий, пожалуйста, вытяните и удалите старые сгенерированные функции/текстовые файлы и регенерацию. Приносим извинения за неудобства.
Чтобы установить требования для проекта с использованием Conda:
conda env create -f environment.yml
Для совместных сквозных экспериментов на всех собранных наборах данных запустите
python run_cdm.py --override e2e_all_config.yaml
Все аргументы могут быть изменены по пространству, разделенными значениями, такими как
python run_cdm.py --override e2e_all_config.yaml num_layers 7 batch_size 512 dropout 0.15 JK none
Пользователи могут изменить переменную task_names в ./e2e_all_config.yaml для управления тем, какие наборы данных включены во время обучения. Длина task_names , d_multiple и d_min_ratio должна быть одинаковой. Они также могут быть указаны в аргументах командной строки с помощью запятых разделенных значений.
например
python run_cdm.py task_names cora_link,arxiv d_multiple 1,1 d_min_ratio 1,1
Ofa-ind может быть указан
python run_cdm.py task_names cora_link d_multiple 1 d_min_ratio 1
Чтобы запустить эксперименты с несколькими выстрелами и с нулевым выстрелом
python run_cdm.py --override lr_all_config.yaml
Мы определяем конфигурации для каждой задачи, каждая конфигурация задачи содержит несколько конфигураций наборов данных.
Конфигурации задачи хранятся в ./configs/task_config.yaml . Задача обычно состоит из нескольких наборов данных (не обязательно одинаковых наборов данных). Например, регулярная задача классификации узлов CORA будет иметь разделение набора данных CORA в качестве набора данных поезда, и действительное разделение набора данных CORA в качестве одного из допустимого набора данных, а также для тестового разделения. Вы также можете провести больше проверки/теста, указав разделение поезда CORA в качестве одного из наборов данных проверки/тестирования. В частности, конфигурация задачи выглядит как
arxiv :
eval_pool_mode : mean
dataset : arxiv # dataset name
eval_set_constructs :
- stage : train # a task should have one and only one train stage dataset
split_name : train
- stage : valid
split_name : valid
dataset : cora # replace the default dataset for zero-shot tasks
- stage : valid
split_name : valid
- stage : test
split_name : test
- stage : test
split_name : train # test the train split Конфигурации набора данных хранятся в ./configs/task_config.yaml . Конфигурация набора данных определяет, как построен набор данных. Конкретно,
arxiv :
task_level : e2e_node
preprocess : null # name of the preprocess function defined in task_constructor.py
construct : ConstructNodeCls # name of the dataset construction function defined in task_constructor.py
args : # additional arguments to construct function
walk_length : null
single_prompt_edge : True
eval_metric : acc # evaluation metric
eval_func : classification_func # evaluation function that process model output and batch to input to evaluator
eval_mode : max # evaluation mode (min/max)
dataset_name : arxiv # name of the OFAPygDataset
dataset_splitter : ArxivSplitter # splitting function defined in task_constructor.py
process_label_func : process_pth_label # name of process label function that transform original label to the binary labels
num_classes : 40 Если вы реализуете набор данных, такой как CORA/PubMed/ARXIV, мы рекомендуем добавить каталог ваших данных $ ablectized_data $ в разделе Data/Single_graph/$ CANDITIC_DATA $ и реализовать GEN_DATA.PY в каталоге вы можете использовать DATA/CORA/GEN_DATA. py в качестве примера.
После того, как данные построены, вам нужно зарегистрировать имя набора данных здесь и реализовать сплиттер , как здесь. Если вы выполняете задачи с нулевым выстрелом/несколькими выстрелами, вы можете создать здесь тоже конструировать с ноль-выстрелом/несколько выстрелов.
Наконец, зарегистрируйте запись конфигурации в configs/data_config.yaml. Например, для классификации сквозных узлов
$data_name$ :
<< : *E2E-node
dataset_name : $data_name$
dataset_splitter : $splitter$
process_label_func : ... # usually processs_pth_label should work
num_classes : $number of classes$Process_label_func преобразует целевую метку в двоичную метку и преобразование класса внедрения, если задача составляет нулевой выстрел/несколько выстрелов, где количество узла класса не установлено. Список Avalailable Process_label_func здесь. Он принимает все классы, встраивающие и правильную метку. Выход-это кортеж: (метка, class_node_embedding, двоичный/однокайчатый метку).
Если вы хотите большую гибкость, то добавление настраиваемых наборов данных требует реализации настроенного подкласса OfapyGdataset. Шаблон здесь:
class CustomizedOFADataset ( OFAPygDataset ):
def gen_data ( self ):
"""
Returns a tuple of the following format
(data, text, extra)
data: a list of Pyg Data, if you only have a one large graph, you should still wrap it with the list.
text: a list of list of texts. e.g. [node_text, edge_text, label_text] this is will be converted to pooled vector representation.
extra: any extra data (e.g. split information) you want to save.
"""
def add_text_emb ( self , data_list , text_emb ):
"""
This function assigns generated embedding to member variables of the graph
data_list: data list returned in self.gen_data.
text_emb: list of torch text tensor corresponding to the returned text in self.gen_data. text_emb[0] = llm_encode(text[0])
"""
data_list [ 0 ]. node_text_feat = ... # corresponding node features
data_list [ 0 ]. edge_text_feat = ... # corresponding edge features
data_list [ 0 ]. class_node_text_feat = ... # class node features
data_list [ 0 ]. prompt_edge_text_feat = ... # edge features used in prompt node
data_list [ 0 ]. noi_node_text_feat = ... # noi node features, refer to the paper for the definition
return self . collate ( data_list )
def get_idx_split ( self ):
"""
Return the split information required to split the dataset, this optional, you can further split the dataset in task_constructor.py
"""
def get_task_map ( self ):
"""
Because a dataset can have multiple different tasks that requires different prompt/class text embedding. This function returns a task map that maps a task name to the desired text embedding. Specifically, a task map is of the following format.
prompt_text_map = {task_name1: {"noi_node_text_feat": ["noi_node_text_feat", [$Index in data[0].noi_node_text_feat$]],
"class_node_text_feat": ["class_node_text_feat",
[$Index in data[0].class_node_text_feat$]],
"prompt_edge_text_feat": ["prompt_edge_text_feat", [$Index in data[0].prompt_edge_text_feat$]]},
task_name2: similar to task_name 1}
Please refer to examples in data/ for details.
"""
return self . side_data [ - 1 ]
def get_edge_list ( self , mode = "e2e" ):
"""
Defines how to construct prompt graph
f2n: noi nodes to noi prompt node
n2f: noi prompt node to noi nodes
n2c: noi prompt node to class nodes
c2n: class nodes to noi prompt node
For different task/mode you might want to use different prompt graph construction, you can do so by returning a dictionary. For example
{"f2n":[1,0], "n2c":[2,0]} means you only want f2n and n2c edges, f2n edges have edge type 1, and its text embedding feature is data[0].prompt_edge_text_feat[0]
"""
if mode == "e2e_link" :
return { "f2n" : [ 1 , 0 ], "n2f" : [ 3 , 0 ], "n2c" : [ 2 , 0 ], "c2n" : [ 4 , 0 ]}
elif mode == "lr_link" :
return { "f2n" : [ 1 , 0 ], "n2f" : [ 3 , 0 ]}

