text embeddings inference
v1.5.1
Прокачающее решение быстрого вывода для моделей встроенных текста.
Оценка для BAAI/BGE-BASE-EN-V1.5 на NVIDIA A10 с длиной последовательности 512 токенов:
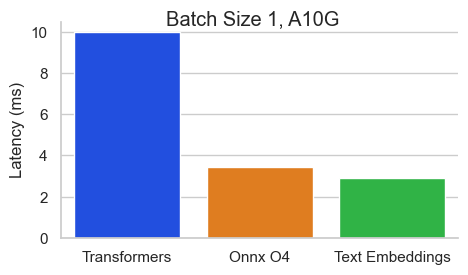
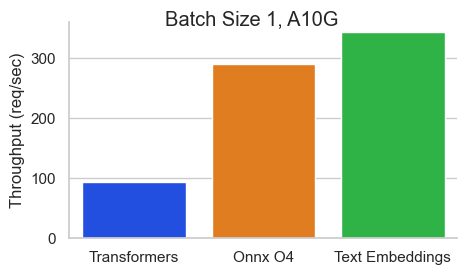
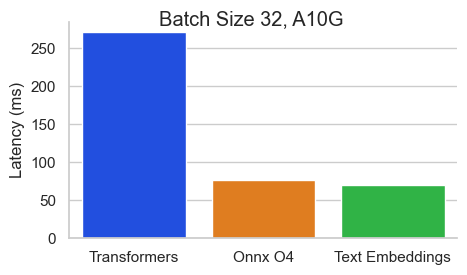
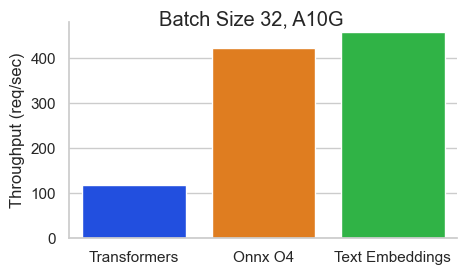
Выводы Text Enceddings (TEI) - это инструментарий для развертывания и обслуживания текстовых встроений с открытым исходным кодом и моделей классификации последовательностей. TEI обеспечивает высокоэффективную добычу для самых популярных моделей, включая флагмбеддинг, Ember, GTE и E5. TEI реализует много функций, таких как:
В настоящее время вывод текста в настоящее время поддерживает номинальные модели Bert, Camembert, XLM-Roberta с абсолютными позициями, моделью Jinabert с позициями алиби и моделями Mistral, Alibaba GTE и QWEN2 с положениями веревки.
Ниже приведены некоторые примеры поддерживаемых в настоящее время моделей:
| Mteb Rank | Размер модели | Тип модели | Идентификатор модели |
|---|---|---|---|
| 1 | 7b (очень дорого) | Мистраль | Salesforce/SFR-Embedding-2_R |
| 2 | 7b (очень дорого) | QWEN2 | Alibaba-nlp/gte-qwen2-7b-instruct |
| 9 | 1,5B (дорого) | QWEN2 | Alibaba-nlp/gte-qwen2-1.5b-instruct |
| 15 | 0,4b | Alibaba Gte | Alibaba-nlp/gte-large-en-v1.5 |
| 20 | 0,3B | Берт | Где-то/ОАЭ-Ларж-В1 |
| 24 | 0,5B | XLM-Roberta | Intfloat/Multringual-E5-Large-Instruct |
| N/a | 0,1b | Номинал | Nomic-AI/Nomic-Embed-Text-V1 |
| N/a | 0,1b | Номинал | Nomic-AI/Nomic-Embed-Text-V1.5 |
| N/a | 0,1b | Джинаберт | Jinaai/Jina-Embeddings-V2-Base-en |
| N/a | 0,1b | Джинаберт | Jinaai/Jina-Embeddings-V2-код |
Чтобы исследовать список лучших моделей текста в Entgeddings, посетите массивную таблицу лидеров встроенного эталона (MTEB).
В настоящее время вывод текста в настоящее время поддерживает модели классификации последовательностей Camembert и XLM-Roberta с абсолютными позициями.
Ниже приведены некоторые примеры поддерживаемых в настоящее время моделей:
| Задача | Тип модели | Идентификатор модели |
|---|---|---|
| Повторный рейтинг | XLM-Roberta | Baai/Bge-Reranker-Large |
| Повторный рейтинг | XLM-Roberta | BAAI/BGE-RERANCER-BASE |
| Повторный рейтинг | Глин | Alibaba-nlp/gte-multingual-reranker-base |
| Анализ настроений | Роберта | SAMLOWE/ROBERTA-BASE-GO_EMOTIONS |
model=BAAI/bge-large-en-v1.5
volume= $PWD /data # share a volume with the Docker container to avoid downloading weights every run
docker run --gpus all -p 8080:80 -v $volume :/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5 --model-id $modelИ тогда вы можете сделать такие запросы, как
curl 127.0.0.1:8080/embed
-X POST
-d ' {"inputs":"What is Deep Learning?"} '
-H ' Content-Type: application/json 'Примечание. Чтобы использовать графические процессоры, вам необходимо установить инструментарий контейнера nvidia. Драйверы NVIDIA на вашей машине должны быть совместимы с версией CUDA 12.2 или выше.
Чтобы увидеть все варианты для обслуживания ваших моделей:
text-embeddings-router --help Usage: text-embeddings-router [OPTIONS]
Options:
--model-id <MODEL_ID>
The name of the model to load. Can be a MODEL_ID as listed on <https://hf.co/models> like `thenlper/gte-base`.
Or it can be a local directory containing the necessary files as saved by `save_pretrained(...)` methods of
transformers
[env: MODEL_ID=]
[default: thenlper/gte-base]
--revision <REVISION>
The actual revision of the model if you're referring to a model on the hub. You can use a specific commit id
or a branch like `refs/pr/2`
[env: REVISION=]
--tokenization-workers <TOKENIZATION_WORKERS>
Optionally control the number of tokenizer workers used for payload tokenization, validation and truncation.
Default to the number of CPU cores on the machine
[env: TOKENIZATION_WORKERS=]
--dtype <DTYPE>
The dtype to be forced upon the model
[env: DTYPE=]
[possible values: float16, float32]
--pooling <POOLING>
Optionally control the pooling method for embedding models.
If `pooling` is not set, the pooling configuration will be parsed from the model `1_Pooling/config.json` configuration.
If `pooling` is set, it will override the model pooling configuration
[env: POOLING=]
Possible values:
- cls: Select the CLS token as embedding
- mean: Apply Mean pooling to the model embeddings
- splade: Apply SPLADE (Sparse Lexical and Expansion) to the model embeddings. This option is only
available if the loaded model is a `ForMaskedLM` Transformer model
- last-token: Select the last token as embedding
--max-concurrent-requests <MAX_CONCURRENT_REQUESTS>
The maximum amount of concurrent requests for this particular deployment.
Having a low limit will refuse clients requests instead of having them wait for too long and is usually good
to handle backpressure correctly
[env: MAX_CONCURRENT_REQUESTS=]
[default: 512]
--max-batch-tokens <MAX_BATCH_TOKENS>
**IMPORTANT** This is one critical control to allow maximum usage of the available hardware.
This represents the total amount of potential tokens within a batch.
For `max_batch_tokens=1000`, you could fit `10` queries of `total_tokens=100` or a single query of `1000` tokens.
Overall this number should be the largest possible until the model is compute bound. Since the actual memory
overhead depends on the model implementation, text-embeddings-inference cannot infer this number automatically.
[env: MAX_BATCH_TOKENS=]
[default: 16384]
--max-batch-requests <MAX_BATCH_REQUESTS>
Optionally control the maximum number of individual requests in a batch
[env: MAX_BATCH_REQUESTS=]
--max-client-batch-size <MAX_CLIENT_BATCH_SIZE>
Control the maximum number of inputs that a client can send in a single request
[env: MAX_CLIENT_BATCH_SIZE=]
[default: 32]
--auto-truncate
Automatically truncate inputs that are longer than the maximum supported size
Unused for gRPC servers
[env: AUTO_TRUNCATE=]
--default-prompt-name <DEFAULT_PROMPT_NAME>
The name of the prompt that should be used by default for encoding. If not set, no prompt will be applied.
Must be a key in the `sentence-transformers` configuration `prompts` dictionary.
For example if ``default_prompt_name`` is "query" and the ``prompts`` is {"query": "query: ", ...}, then the
sentence "What is the capital of France?" will be encoded as "query: What is the capital of France?" because
the prompt text will be prepended before any text to encode.
The argument '--default-prompt-name <DEFAULT_PROMPT_NAME>' cannot be used with '--default-prompt <DEFAULT_PROMPT>`
[env: DEFAULT_PROMPT_NAME=]
--default-prompt <DEFAULT_PROMPT>
The prompt that should be used by default for encoding. If not set, no prompt will be applied.
For example if ``default_prompt`` is "query: " then the sentence "What is the capital of France?" will be
encoded as "query: What is the capital of France?" because the prompt text will be prepended before any text
to encode.
The argument '--default-prompt <DEFAULT_PROMPT>' cannot be used with '--default-prompt-name <DEFAULT_PROMPT_NAME>`
[env: DEFAULT_PROMPT=]
--hf-api-token <HF_API_TOKEN>
Your HuggingFace hub token
[env: HF_API_TOKEN=]
--hostname <HOSTNAME>
The IP address to listen on
[env: HOSTNAME=]
[default: 0.0.0.0]
-p, --port <PORT>
The port to listen on
[env: PORT=]
[default: 3000]
--uds-path <UDS_PATH>
The name of the unix socket some text-embeddings-inference backends will use as they communicate internally
with gRPC
[env: UDS_PATH=]
[default: /tmp/text-embeddings-inference-server]
--huggingface-hub-cache <HUGGINGFACE_HUB_CACHE>
The location of the huggingface hub cache. Used to override the location if you want to provide a mounted disk
for instance
[env: HUGGINGFACE_HUB_CACHE=]
--payload-limit <PAYLOAD_LIMIT>
Payload size limit in bytes
Default is 2MB
[env: PAYLOAD_LIMIT=]
[default: 2000000]
--api-key <API_KEY>
Set an api key for request authorization.
By default the server responds to every request. With an api key set, the requests must have the Authorization
header set with the api key as Bearer token.
[env: API_KEY=]
--json-output
Outputs the logs in JSON format (useful for telemetry)
[env: JSON_OUTPUT=]
--otlp-endpoint <OTLP_ENDPOINT>
The grpc endpoint for opentelemetry. Telemetry is sent to this endpoint as OTLP over gRPC. e.g. `http://localhost:4317`
[env: OTLP_ENDPOINT=]
--otlp-service-name <OTLP_SERVICE_NAME>
The service name for opentelemetry. e.g. `text-embeddings-inference.server`
[env: OTLP_SERVICE_NAME=]
[default: text-embeddings-inference.server]
--cors-allow-origin <CORS_ALLOW_ORIGIN>
Unused for gRPC servers
[env: CORS_ALLOW_ORIGIN=]
Текстовые встраиваемые суда с несколькими изображениями Docker, которые вы можете использовать для нацеливания на конкретный бэкэнд:
| Архитектура | Изображение |
|---|---|
| Процессор | ghcr.io/huggingface/text-embeddings inference:cpu-1.5 |
| Вольта | Не поддерживается |
| Тьюринг (T4, RTX 2000 Series, ...) | ghcr.io/huggingface/text-embeddings-inference:turing-1.5 (экспериментальный) |
| Ampere 80 (A100, A30) | ghcr.io/huggingface/text-embeddings inference:1.5 |
| Ampere 86 (A10, A40, ...) | ghcr.io/huggingface/text-embeddings inference:86-1.5 |
| Ada Lovelace (серия RTX 4000, ...) | ghcr.io/huggingface/text-embeddings inference:89-1.5 |
| Бункер (H100) | ghcr.io/huggingface/text-embeddings inference:hopper-1.5 (экспериментальный) |
ПРЕДУПРЕЖДЕНИЕ : Внимание вспышки отключается по умолчанию для изображения Тьюринга, поскольку оно страдает от точности. Вы можете включить Flash Hatter v1, используя переменную USE_FLASH_ATTENTION=True .
Вы можете проконсультироваться с документацией OpenAPI API REST text-embeddings-inference используя маршрут /docs . UI Swagger также доступен по адресу: https://huggingface.github.io/text-embeddings-inference.
У вас есть возможность использовать переменную среды HF_API_TOKEN для настройки токена, используемого text-embeddings-inference . Это позволяет вам получить доступ к защищенным ресурсам.
Например:
HF_API_TOKEN=<your cli READ token>или с докером:
model= < your private model >
volume= $PWD /data # share a volume with the Docker container to avoid downloading weights every run
token= < your cli READ token >
docker run --gpus all -e HF_API_TOKEN= $token -p 8080:80 -v $volume :/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5 --model-id $modelЧтобы развернуть вывод текстовых встроенных встроенных в воздушную среду, сначала загрузите веса, а затем установите их внутри контейнера, используя громкость.
Например:
# (Optional) create a `models` directory
mkdir models
cd models
# Make sure you have git-lfs installed (https://git-lfs.com)
git lfs install
git clone https://huggingface.co/Alibaba-NLP/gte-base-en-v1.5
# Set the models directory as the volume path
volume= $PWD
# Mount the models directory inside the container with a volume and set the model ID
docker run --gpus all -p 8080:80 -v $volume :/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5 --model-id /data/gte-base-en-v1.5 text-embeddings-inference v0.4.0 добавлена поддержка моделей Camembert, Roberta, XLM-Roberta и GTE классификации последовательностей. Модели повторных оранжеров представляют собой модели сети-кодеров классификации последовательностей с одним классом, который оценивает сходство между запросом и текстом.
Посмотрите на этот пост команды LmamainDex, чтобы понять, как вы можете использовать модели повторных оранжеров в своем Rag Pipeline, чтобы повысить производительность вниз по течению.
model=BAAI/bge-reranker-large
volume= $PWD /data # share a volume with the Docker container to avoid downloading weights every run
docker run --gpus all -p 8080:80 -v $volume :/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5 --model-id $modelИ тогда вы можете оценить сходство между запросом и списком текстов с:
curl 127.0.0.1:8080/rerank
-X POST
-d ' {"query": "What is Deep Learning?", "texts": ["Deep Learning is not...", "Deep learning is..."]} '
-H ' Content-Type: application/json ' Вы также можете использовать классификационные модели классификации классификации последовательностей, такие как SamLowe/roberta-base-go_emotions :
model=SamLowe/roberta-base-go_emotions
volume= $PWD /data # share a volume with the Docker container to avoid downloading weights every run
docker run --gpus all -p 8080:80 -v $volume :/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5 --model-id $model После того, как вы развернули модель, вы можете использовать конечную точку predict , чтобы получить эмоции, наиболее связанные с входом:
curl 127.0.0.1:8080/predict
-X POST
-d ' {"inputs":"I like you."} '
-H ' Content-Type: application/json 'Вы можете активировать объединение Splade для архитектуры Bert и Distilbert Maskedlm:
model=naver/efficient-splade-VI-BT-large-query
volume= $PWD /data # share a volume with the Docker container to avoid downloading weights every run
docker run --gpus all -p 8080:80 -v $volume :/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5 --model-id $model --pooling splade После того, как вы развернули модель, вы можете использовать конечную точку /embed_sparse , чтобы получить разреженное внедрение:
curl 127.0.0.1:8080/embed_sparse
-X POST
-d ' {"inputs":"I like you."} '
-H ' Content-Type: application/json ' text-embeddings-inference приспособлен с распределенной трассировкой с использованием Opentelemetry. Вы можете использовать эту функцию, установив адрес для коллекционера OTLP с аргументом --otlp-endpoint .
text-embeddings-inference предлагает API GRPC в качестве альтернативы HTTP API по умолчанию для высокопроизводительных развертываний. Определение Protobuf API можно найти здесь.
Вы можете использовать API GRPC, добавив тег -grpc в любое изображение TEI Docker. Например:
model=BAAI/bge-large-en-v1.5
volume= $PWD /data # share a volume with the Docker container to avoid downloading weights every run
docker run --gpus all -p 8080:80 -v $volume :/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5-grpc --model-id $model grpcurl -d ' {"inputs": "What is Deep Learning"} ' -plaintext 0.0.0.0:8080 tei.v1.Embed/Embed Вы также можете установить установку text-embeddings-inference на местном уровне.
Сначала установить ржавчину:
curl --proto ' =https ' --tlsv1.2 -sSf https://sh.rustup.rs | shЗатем беги:
# On x86
cargo install --path router -F mkl
# On M1 or M2
cargo install --path router -F metalТеперь вы можете запустить вывод Text Enceddings на процессоре с:
model=BAAI/bge-large-en-v1.5
text-embeddings-router --model-id $model --port 8080Примечание. На некоторых машинах вам также могут понадобиться библиотеки OpenSSL и GCC. На машинах Linux, запустите:
sudo apt-get install libssl-dev gcc -yGPU с возможностями CUDA Compute <7,5 не поддерживаются (V100, Titan V, GTX 1000 Series, ...).
Убедитесь, что у вас установлены драйверы Nvidia. Драйверы NVIDIA на вашем устройстве должны быть совместимы с версией CUDA 12.2 или выше. Вам также нужно добавить в свой путь двоичные файлы nvidia:
export PATH= $PATH :/usr/local/cuda/binЗатем беги:
# This can take a while as we need to compile a lot of cuda kernels
# On Turing GPUs (T4, RTX 2000 series ... )
cargo install --path router -F candle-cuda-turing -F http --no-default-features
# On Ampere and Hopper
cargo install --path router -F candle-cuda -F http --no-default-featuresТеперь вы можете запустить вывод Text Enceddings на графическом процессоре с помощью:
model=BAAI/bge-large-en-v1.5
text-embeddings-router --model-id $model --port 8080Вы можете построить контейнер процессора с помощью:
docker build .Чтобы построить контейнеры CUDA, вам необходимо знать расчетчик графического процессора, который вы будете использовать во время выполнения.
Затем вы можете построить контейнер с:
# Example for Turing (T4, RTX 2000 series, ...)
runtime_compute_cap=75
# Example for A100
runtime_compute_cap=80
# Example for A10
runtime_compute_cap=86
# Example for Ada Lovelace (RTX 4000 series, ...)
runtime_compute_cap=89
# Example for H100
runtime_compute_cap=90
docker build . -f Dockerfile-cuda --build-arg CUDA_COMPUTE_CAP= $runtime_compute_capКак объяснено здесь, готово MPS, ARM64 Docker Image, Metal / MPS не поддерживается через Docker. Таким образом, вывод будет связан с процессором и, скорее всего, довольно медленным при использовании этого изображения Docker на процессоре M1/M2 ARM.
docker build . -f Dockerfile --platform=linux/arm64


