pytorch openai transformer lm
1.0.0
Это реализация Pytorch кода Tensorflow, предоставленного бумагой Openai «Улучшение языкового понимания путем генеративного предварительного обучения» Алеком Рэдфордом, Картиком Нарасимханом, Тимом Салимансом и Ильей Сатскевером.
Эта реализация включает в себя сценарий для загрузки в модели Pytorch, предварительно обученные авторами с реализацией TensorFlow.
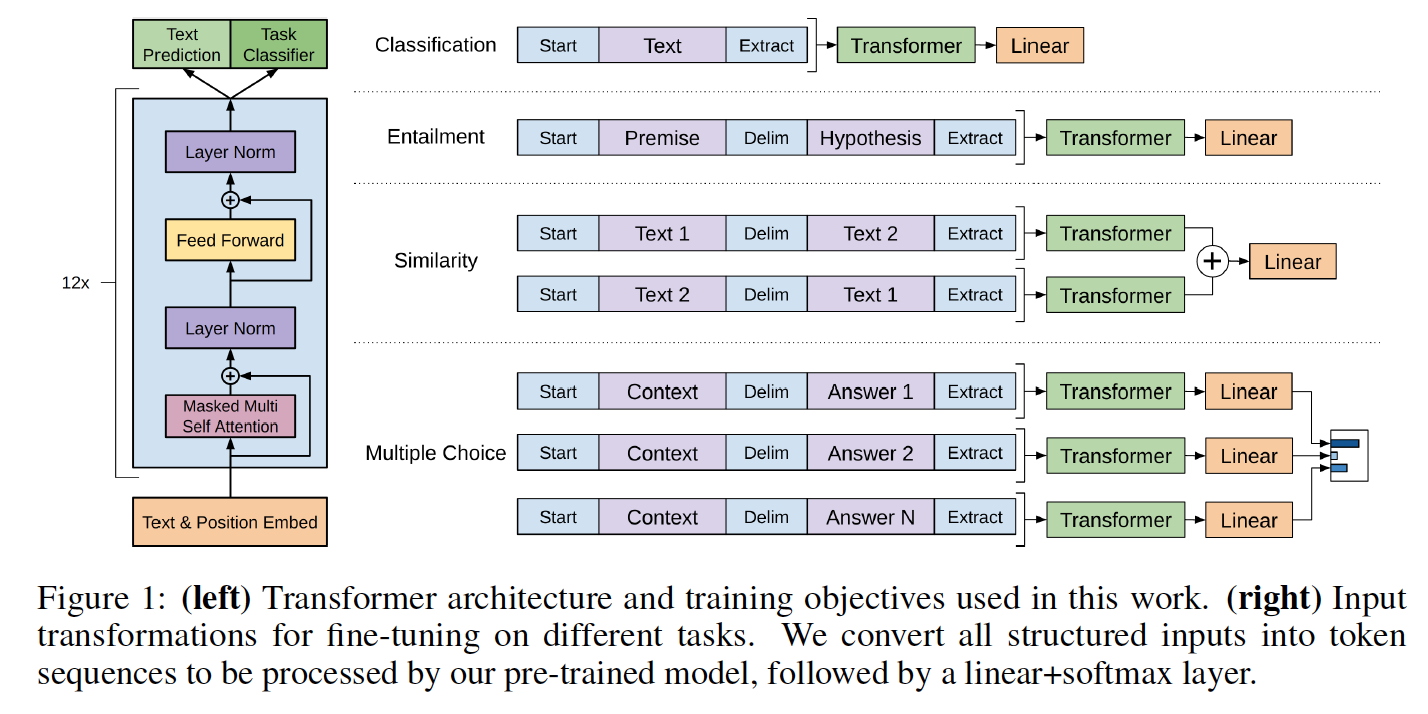
Модельные классы и сценарий загрузки расположены в Model_pytorch.py.
Имена модулей в модели Pytorch следуют именам переменной в реализации TensorFlow. Эта реализация пытается следовать исходному коду как можно ближе, чтобы минимизировать расхождения.
Таким образом, эта реализация также включает в себя модифицированный алгоритм оптимизации ADAM, используемый в бумаге Openai с:
Чтобы использовать модель IT-Self, импортируя model_pytorch.py, вам просто нужно:
Чтобы запустить сценарий обучения классификатора в Train.py, вам понадобится дополнительно:
Вы можете скачать веса предварительно обученной версии OpenAI, клонируя репо Алека Рэдфорда и поместив папку model , содержащую предварительно обученные веса в настоящем репо.
Модель может использоваться в качестве модели языка трансформатора с предварительно обученными весами OpenAI следующим образом:
from model_pytorch import TransformerModel , load_openai_pretrained_model , DEFAULT_CONFIG
args = DEFAULT_CONFIG
model = TransformerModel ( args )
load_openai_pretrained_model ( model ) Эта модель генерирует скрытые состояния трансформатора. Вы можете использовать класс LMHead в model_pytorch.py, чтобы добавить декодер, связанный с весами энкодера, и получить полную языковую модель. Вы также можете использовать класс ClfHead в Model_pytorch.py, чтобы добавить классификатор поверх трансформатора и получить классификатор, как описано в публикации Openai. (См. Пример обоих в функции __main__ train.py)
Чтобы использовать позиционный энкодер трансформатора, вы должны кодировать ваш набор данных, используя функцию encode_dataset() utils.py. Пожалуйста, обратитесь к началу функции __main__ в Train.py, чтобы увидеть, как правильно определить словарный запас и кодировать ваш набор данных.
Эта модель также может быть интегрирована в классификатор, как подробно описано в статье Openai. Пример точной настройки на задачу Rocstories Cloze включено в код обучения в Train.py
Набор данных Rocstories можно загрузить с соответствующего веб -сайта.
Как и в случае с кодом TensorFlow, этот код реализует результаты теста Rocstories Cloze, представленные в статье, которые можно воспроизвести путем запуска:
python -m spacy download en
python train.py --dataset rocstories --desc rocstories --submit --analysis --data_dir [path to data here]Создание модели Pytorch для 3 эпох на Rocstories занимает 10 минут на одну NVIDIA K-80.
Точность теста на одну пробку этой версии Pytorch составляет 85,84%, в то время как авторы сообщают о медианной точности с кодом TensorFlow 85,8%, а в статье наилучшую точность одного запуска составляет 86,5%.
Реализации авторов используют 8 графических процессоров и, таким образом, могут приспособиться к партии из 64 образцов, в то время как настоящая реализация представляет собой отдельный графический процессор и, как следствие, ограничена 20 экземплярами на K80 по причинам памяти. В нашем тесте увеличение размера партии с 8 до 20 выборок повысило точность теста на 2,5 балла. Лучшая точность может быть получена с помощью настройки с несколькими GPU (еще не пробова).
Предыдущая SOTA на наборе данных Rocstories составляет 77,6% («скрытая модель когерентности» Chaturvedi et al.


