rag experiment accelerator
1.0.0
Эксперимент RAG Experiment - это универсальный инструмент, который помогает вам проводить эксперименты и оценки с использованием Azure AI Search и Rag Pattern. Этот документ предоставляет всеобъемлющее руководство, которое охватывает все, что вам нужно знать об этом инструменте, например, его цель, функции, установка, использование и многое другое.
Основная цель Accelerator Accelerator Experiment - облегчить и быстрее проводить эксперименты и оценки поисковых запросов и качества ответа от OpenAI. Этот инструмент полезен для исследователей, ученых данных и разработчиков, которые хотят:
18 марта 2024 года: выборка контента была добавлена. Эта функциональность позволит отображать набор данных по указанному проценту. Данные кластеризуются контентом, а затем процент выборки принимается по всему кластеру, чтобы попытаться ровное распределение отбранных данных.
Это сделано для обеспечения репрезентативных результатов в выборке, которую можно получить по всему набору данных.
Примечание . Рекомендуется восстановить окружающую среду, если вы использовали этот инструмент ранее из -за новых зависимостей.
Accelerator Experiment Accelerator управляется конфигурацией и предлагает богатый набор функций для поддержки ее цели:
Настройка эксперимента : вы можете определить и настроить эксперименты, указав диапазон параметров поисковой системы, типов поиска, наборов запросов и показателей оценки.
Интеграция : он легко интегрируется с Azure AI Search, Azure Machine Learning, Mlflow и Azure Openai.
Индекс богатого поиска : он создает несколько индексов поиска на основе конфигураций гиперпараметрических данных, доступных в файле конфигурации.
Несколько загрузчиков документов : инструмент поддерживает несколько погрузчиков документов, включая загрузку с помощью интеллекта документов Azure и основных погрузчиков Langchain. Это дает вам гибкость для экспериментов с различными методами экстракции и оценить их эффективность.
Пользовательский загрузчик интеллекта документов : при выборе модели API «Prebuilt-Layout» для интеллекта документов, инструмент использует пользовательский загрузчик интеллекта документов для загрузки данных. Этот пользовательский загрузчик поддерживает форматирование таблиц с заголовками столбцов в пары клавиш (для повышения читаемости для LLM), исключая не относящиеся к делу части файла для LLM (например, номера страниц и нижние колонтитулы), удаляет повторяющиеся шаблоны в файле с использованием REGEX и многого другого. Поскольку каждая строка таблицы преобразуется в текстовую строку, чтобы избежать разрыва ряда посередине, чункинг осуществляется рекурсивно абзацем и строкой. Пользовательский погрузчик прибегает к более простой модели «API с предварительной лайутом» в качестве запасного запасного, когда сбой в «предварительном Layout». Любая другая модель API будет использовать реализацию Langchain, которая возвращает необработанный ответ из API Document Intelligence.
Генерация запросов : инструмент может генерировать различные и настраиваемые наборы запросов, которые могут быть адаптированы для конкретных потребностей экспериментов.
Несколько типов поиска : он поддерживает несколько типов поиска, включая чистый текст, чистый вектор, кросс-вектор, мультивектор, гибрид и многое другое. Это дает вам возможность провести всесторонний анализ возможностей поиска и результатов.
Подквисение : шаблон оценивает пользовательский запрос, и если он находит его достаточно сложным, он разбивает его на более мелкие подразделы, чтобы генерировать соответствующий контекст.
Повторная оценка : ответы на запросы из Azure AI Search переоценены с использованием LLM и ранжируются в соответствии с актуальностью между запросом и контекстом.
Метрики и оценка : он поддерживает сквозные метрики, сравнивая сгенерированные ответы (фактические) с ответами на землю (ожидаемые), включая показатели на расстоянии, косинус и семантическую сходство. Он также включает в себя метрики на основе компонентов для оценки результатов поиска и генерации с использованием LLMS в качестве судьи, таких как контекст-отзыв или актуальность ответа, а также показатели поиска для оценки результатов поиска (например, Map@K).
Генерация отчета : Accelerator Accelerator Experiment автоматизирует процесс генерации отчетов, в комплекте с визуализациями, которые позволяют легко анализировать и обмениваться результатами эксперимента.
Многоязычный : инструмент поддерживает языковые анализаторы для лингвистической поддержки на отдельных языках и специализированных (языковых) анализаторах для определяемых пользователями шаблонов по индексам поиска. Для получения дополнительной информации см. Типы анализаторов.
Отбор выборки : если у вас есть большой набор данных и/или вы хотите ускорить эксперименты, доступен процесс отбора проб для создания небольшой, но репрезентативной выборки данных для указанного процента. Данные будут кластеризованы контентом, и процент каждого кластера будет выбран как часть выборки. Полученные результаты должны быть примерно свидетельствовать о полном наборе данных в пределах ~ 10%. После того, как подход был идентифицирован, работа на полном наборе данных рекомендуется для точных результатов.
На данный момент акселератор эксперимента RAG может работать локально, используя одно из следующих:
Использование контейнера для разработки будет означать, что для вас установлено все необходимое программное обеспечение. Это потребует WSL. Для получения дополнительной информации о контейнерах для разработки посетите контейнеры.dev
Установите следующее программное обеспечение на хост -машине, вы выполните развертывание из:
- Для Windows - Windows Store Ubuntu 22.04.3 LTS
- Docker Desktop
- Visual Studio Code
- VS расширение кода: удаленные контейнеры
Дополнительное руководство по настройке WSL можно найти здесь. Теперь у вас есть предпосылки, вы можете:
git clone https://github.com/microsoft/rag-experiment-accelerator.git
code .Как только проект откроется в VSCODE, он должен спросить вас, хотите ли вы «открыть это в контейнере для разработки». Скажи да.
Конечно, вы можете запустить Accelerator Experiment Experiment на машине Windows/Mac, если хотите; Вы несете ответственность за установку правильного инструмента. Следуйте этим этапам установки:
git clone https://github.com/microsoft/rag-experiment-accelerator.gitconda create -n rag-experiment python=3.11
conda init bashЗакройте свой терминал, откройте новый и запустите:
conda activate rag-experiment
pip install .az login
az account set --subscription= " <your_subscription_guid> "
az account showЕсть 3 варианта установки всех необходимых услуг Azure:
Этот проект поддерживает Azure Developer CLI.
azd provisionazd up если вы предпочитаете, так как это вызывает azd provision в любом случае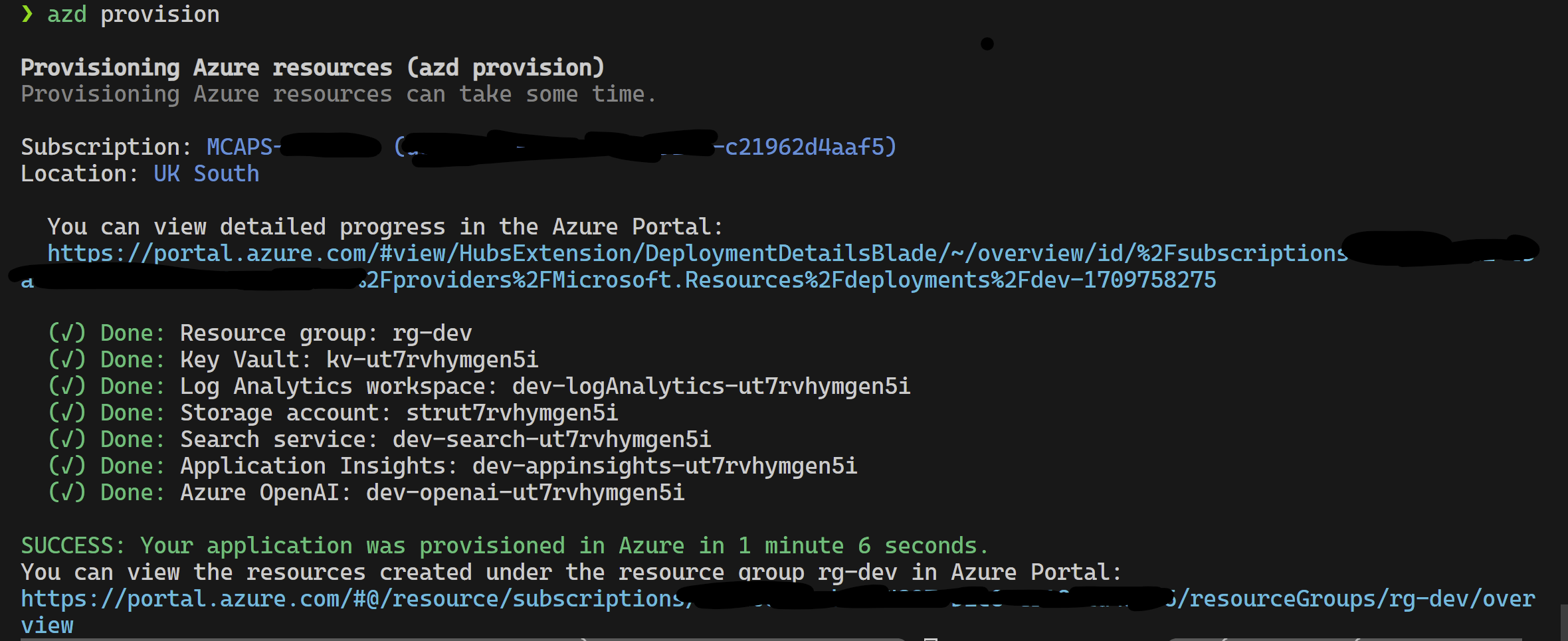
После того, как это будет завершено, вы можете использовать конфигурацию запуска для запуска или отлаживать 4 шага, и текущая среда, предоставленная azd , будет загружена с правильными значениями.
Если вы хотите развернуть инфраструктуру самостоятельно из шаблона, вы также можете нажать здесь:
Если вы не хотите использовать azd вы также можете использовать обычный az CLI.
Используйте следующую команду для развертывания.
az login
az deployment sub create --subscription < subscription-id > --location < location > --template-file infra/main.bicepИли
Развернуть с помощью изолированного использования сети следующей командой. Замените значения параметров на специфику вашей изолированной сети. Вы должны предоставить все три параметра (то есть vnetAddressSpace , proxySubnetAddressSpace и subnetAddressSpace ), если вы хотите развернуть в изолированной сети.
az login
az deployment sub create --location < location > --template-file infra/main.bicep
--parameters vnetAddressSpace= < vnet-address-space >
--parameters proxySubnetAddressSpace= < proxy-subnet-address-space >
--parameters subnetAddressSpace= < azure-subnet-address-space >Вот пример со значениями параметров:
az deployment sub create --location uksouth --template-file infra/main.bicep
--parameters vnetAddressSpace= ' 10.0.0.0/16 '
--parameters proxySubnetAddressSpace= ' 10.0.1.0/24 '
--parameters subnetAddressSpace= ' 10.0.2.0/24 ' Чтобы использовать акселератор RAG Experiment локально, выполните следующие действия:
Скопируйте предоставленный файл .env.template в файл с именем .env и обновите все необходимые значения. Многие из необходимых значений для файла .env будут поступать из ресурсов, которые ранее были настроены и/или могут быть собраны из ресурсов, предоставленных в разделе инфраструктуры положения. Также обратите внимание, по умолчанию LOGGING_LEVEL установлен на INFO , но может быть изменена на любой из следующих уровней: NOTSET , DEBUG , INFO , WARN , ERROR , CRITICAL .
cp .env.template .env
# change parameters manually Скопируйте предоставленный файл config.sample.json в файл с именем config.json и измените все гиперпараметры, чтобы адаптировать к вашему эксперименту.
cp config.sample.json config.json
# change parameters manually Скопируйте любые файлы для проглатывания (PDF, HTML, Markdown, Text, JSON или DOCX Format) в папку data .
Запустите 01_index.py (Python 01_index.py), чтобы создать индексы поиска Azure AI и загрузить в них данные.
python 01_index.py
-d " The directory holding the configuration files and data. Defaults to current working directory "
-dd " The directory holding the data. Defaults to data "
-cf " JSON config filename. Defaults to config.json " Запустите 02_qa_generation.py (Python 02_QA_Generation.py), чтобы генерировать пары вопросов-ответов с использованием Azure OpenAI.
python 02_qa_generation.py
-d " The directory holding the configuration files and data. Defaults to current working directory "
-dd " The directory holding the data. Defaults to data "
-cf " JSON config filename. Defaults to config.json " Запустите 03_querying.py (Python 03_QUERYING.PY), чтобы запросить AZURE AI SEARK для генерации контекста, повторных элементов в контексте и получить ответ от Azure Open, используя новый контекст.
python 03_querying.py
-d " The directory holding the configuration files and data. Defaults to current working directory "
-cf " JSON config filename. Defaults to config.json " Запустите 04_evaluation.py (python 04_evaluation.py) для расчета метрик с использованием различных методов и генерирования диаграмм и отчетов в машинном обучении Azure с использованием интеграции Mlflow.
python 04_evaluation.py
-d " The directory holding the configuration files and data. Defaults to current working directory "
-cf " JSON config filename. Defaults to config.json " В качестве альтернативы, вы можете запустить вышеуказанные шаги (кроме 02_qa_generation.py ), используя трубопровод Azure ML. Для этого следуйте руководству здесь.
Отбор проб будет выполняться локально для создания небольшого, но репрезентативного среза данных. Это помогает с быстрыми экспериментами и снижает расходы. Полученные результаты должны быть примерно свидетельствовать о полном наборе данных в пределах ~ 10%. После того, как подход был идентифицирован, работа на полном наборе данных рекомендуется для точных результатов.
ПРИМЕЧАНИЕ . Выборка может быть запущена только локально, на этом этапе она не поддерживается на распределенном Compute Cluster. Таким образом, процесс будет запускать выборку локально, а затем использовать сгенерированный набор данных образцов для запуска на AML.
Если у вас есть очень большой набор данных и вы хотите запустить аналогичный подход, чтобы попробовать данные, вы можете использовать дистрибьюторную реализацию Pyspark в памяти в инструментарии для обнаружения данных для Microsoft Fabric или Azure Synapse Analytics.
"sampling" : {
"sample_data" : " Set to true to enable sampling " ,
"only_run_sampling" : " If set to true, this will only run the sampling step and will not create an index or any subsequent steps, use this if you want to build a small sampled dataset to run in AML " ,
"sample_percentage" : " Percentage of the document corpus to sample " ,
"optimum_k" : " Set to 'auto' to automatically determine the optimum cluster number or set to a specific value e.g. 15 " ,
"min_cluster" : " Used by the automated optimum cluster process, this is the minimum number of clusters e.g. 2 " ,
"max_cluster" : " Used by the automated optimum cluster process, this is the maximum number of clusters e.g. 30 " ,
},Процесс отбора проб приведет следующие артефакты в каталоге выборки:
job_name содержащего подмножество файлов, отобранных, они могут быть указаны как аргумент --data_dir при запуске всего процесса на AML.
"optimum_k": auto конфигурация установлена на Auto, процесс выборки попытается автоматически установить оптимальное количество кластеров. Это может быть переопределено, если вы примерно знаете, сколько широких ведер контента существует в ваших данных. График локтя будет генерироваться в папке отбора проб. 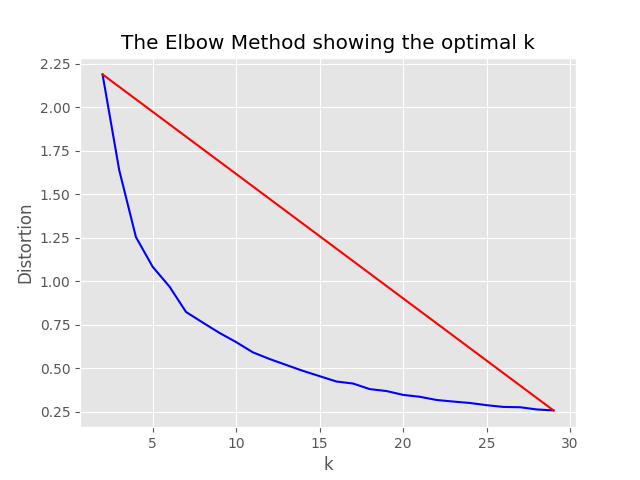
Существуют два варианта запуска отбора проб, а именно:
Установите следующие значения для запуска процесса индексации локально:
"sampling" : {
"sample_data" : true ,
"only_run_sampling" : false ,
"sample_percentage" : 10 ,
"optimum_k" : auto,
"min_cluster" : 2 ,
"max_cluster" : 30
}, Если значение конфигурации only_run_sampling установлено на TRUE, это только выполнит шаг выборки, индекс не будет создан, и любые другие последующие шаги не будут выполнены. Установите аргумент --data_dir в каталог, созданный процессом отбора проб, который будет:
artifacts/sampling/config.[job_name] и выполнить шаг трубопровода AML.
Все значения могут быть списками элементов. Включая вложенные конфигурации. Каждый массив будет создавать комбинации плоских конфигураций, когда метод flatten() вызывается в конкретном узле, чтобы выбрать 1 случайную комбинацию - вызовите sample() .
{
"experiment_name" : " If provided, this will be the experiment name in Azure ML and it will group all job run under the same experiment, otherwise (if left empty) index_name_prefix will be used and there may be more than one experiment " ,
"job_name" : " If provided, all jobs runs in Azure ML will be named with this property value plus timestamp, otherwise (if left empty) each job with be named only with timestamp " ,
"job_description" : " You may provide a description for the current job run which describes in words what you are about to experiment with " ,
"data_formats" : " Specifies the supported data formats for the application. You can choose from a variety of formats such as JSON, CSV, PDF, and more. [*] - means all formats included " ,
"main_instruction" : " Defines the main instruction prompt coming with queries to LLM " ,
"use_checkpoints" : " A boolean. If true, enables use of checkpoints to load data and skip processing that was already done in previous executions. " ,
"index" : {
"index_name_prefix" : " Search index name prefix " ,
"ef_construction" : " ef_construction value determines the value of Azure AI Search vector configuration. " ,
"ef_search" : " ef_search value determines the value of Azure AI Search vector configuration. " ,
"chunking" : {
"preprocess" : " A boolean. If true, preprocess documents, split into smaller chunks, embed and enrich them, and finally upload documents chunks for retrieval into Azure Search Index. " ,
"chunk_size" : " Size of each chunk e.g. [500, 1000, 2000] " ,
"overlap_size" : " Overlap Size for each chunk e.g. [100, 200, 300] " ,
"generate_title" : " A boolean. If true, a title is generated for the chunk of content and an embedding is created for it " ,
"generate_summary" : " A boolean. If true, a summary is generated for the chunk of content and an embedding is created for it " ,
"override_content_with_summary" : " A boolean. If true, The chunk content is replaced with its summary " ,
"chunking_strategy" : " determines the chunking strategy. Valid values are 'azure-document-intelligence' or 'basic' " ,
"azure_document_intelligence_model" : " represents the Azure Document Intelligence Model. Used when chunking strategy is 'azure-document-intelligence'. When set to 'prebuilt-layout', provides additional features (see above) "
},
"embedding_model" : " see 'Description of embedding models config' below " ,
"sampling" : {
"sample_data" : " Set to true to enable sampling " ,
"percentage" : " Percentage of the document corpus to sample " ,
"optimum_k" : " Set to 'auto' to automatically determine the optimum cluster number or set to a specific value e.g. 15 " ,
"min_cluster" : " Used by the automated optimum cluster process, this is the minimum number of clusters e.g. 2 " ,
"max_cluster" : " Used by the automated optimum cluster process, this is the maximum number of clusters e.g. 30 "
}
},
"language" : {
"analyzer" : {
"analyzer_name" : " name of the analyzer to use for the field. This option can be used only with searchable fields and it can't be set together with either searchAnalyzer or indexAnalyzer. " ,
"index_analyzer_name" : " name of the analyzer used at indexing time for the field. This option can be used only with searchable fields. It must be set together with searchAnalyzer and it cannot be set together with the analyzer option. " ,
"search_analyzer_name" : " name of the analyzer used at search time for the field. This option can be used only with searchable fields. It must be set together with indexAnalyzer and it cannot be set together with the analyzer option. This property cannot be set to the name of a language analyzer; use the analyzer property instead if you need a language analyzer. " ,
"char_filters" : " The character filters for the index " ,
"tokenizers" : " The tokenizers for the index " ,
"token_filters" : " The token filters for the index "
},
"query_language" : " The language of the query. Possible values: en-us, en-gb, fr-fr etc. "
},
"rerank" : {
"enabled" : " determines if search results should be re-ranked. Value values are TRUE or FALSE " ,
"type" : " determines the type of re-ranking. Value values are llm or cross_encoder " ,
"llm_rerank_threshold" : " determines the threshold when using llm re-ranking. Chunks with rank above this number are selected in range from 1 - 10. " ,
"cross_encoder_at_k" : " determines the threshold when using cross-encoding re-ranking. Chunks with given rank value are selected. " ,
"cross_encoder_model" : " determines the model used for cross-encoding re-ranking step. Valid value is cross-encoder/stsb-roberta-base "
},
"search" : {
"retrieve_num_of_documents" : " determines the number of chunks to retrieve from the search index " ,
"search_type" : " determines the search types used for experimentation. Valid value are search_for_match_semantic, search_for_match_Hybrid_multi, search_for_match_Hybrid_cross, search_for_match_text, search_for_match_pure_vector, search_for_match_pure_vector_multi, search_for_match_pure_vector_cross, search_for_manual_hybrid. e.g. ['search_for_manual_hybrid', 'search_for_match_Hybrid_multi','search_for_match_semantic'] " ,
"search_relevancy_threshold" : " the similarity threshold to determine if a doc is relevant. Valid ranges are from 0.0 to 1.0 "
},
"query_expansion" : {
"expand_to_multiple_questions" : " whether the system should expand a single question into multiple related questions. By enabling this feature, you can generate a set of alternative related questions that may improve the retrieval process and provide more accurate results " .,
"query_expansion" : " determines if query expansion feature is on. Value values are TRUE or FALSE " ,
"hyde" : " this feature allows you to experiment with various query expansion approaches which may improve the retrieval metrics. The possible values are 'disabled' (default), 'generated_hypothetical_answer', 'generated_hypothetical_document_to_answer' reference article - Precise Zero-Shot Dense Retrieval without Relevance Labels (HyDE - Hypothetical Document Embeddings) - https://arxiv.org/abs/2212.10496 " ,
"min_query_expansion_related_question_similarity_score" : " minimum similarity score in percentage between LLM generated related queries to the original query using cosine similarly score. default 90% "
},
"openai" : {
"azure_oai_chat_deployment_name" : " determines the Azure OpenAI deployment name " ,
"azure_oai_eval_deployment_name" : " determines the Azure OpenAI deployment name used for evaluation " ,
"temperature" : " determines the OpenAI temperature. Valid value ranges from 0 to 1. "
},
"eval" : {
"metric_types" : " determines the metrics used for evaluation (end-to-end or component-wise metrics using LLMs). Valid values for end-to-end metrics are lcsstr, lcsseq, cosine, jaro_winkler, hamming, jaccard, levenshtein, fuzzy_score, cosine_ochiai, bert_all_MiniLM_L6_v2, bert_base_nli_mean_tokens, bert_large_nli_mean_tokens, bert_large_nli_stsb_mean_tokens, bert_distilbert_base_nli_stsb_mean_tokens, bert_paraphrase_multilingual_MiniLM_L12_v2. Valid values for component-wise LLM-based metrics are llm_answer_relevance, llm_context_precision and llm_context_recall. e.g ['fuzzy_score','bert_all_MiniLM_L6_v2','cosine_ochiai','bert_distilbert_base_nli_stsb_mean_tokens', 'llm_answer_relevance'] " ,
}
}Примечание. При изменении конфигурации не забудьте изменить:
config.sample.json (пример конфигурации, который будет скопирован другими) embedding_model - это массив, содержащий конфигурацию для использования моделей Encedding. Встроенный type модели должен быть azure для моделей Azure OpenAI и sentence-transformer для моделей трансформаторов предложений HuggingFace.
{
"type" : " azure " ,
"model_name" : " the name of the Azure OpenAI model " ,
"dimension" : " the dimension of the embedding model. For example, 1536 which is the dimension of text-embedding-ada-002 "
} Если вы используете модель, отличную от text-embedding-ada-002 , вы должны указать соответствующее измерение для модели в поле dimension ; например:
{
"type" : " azure " ,
"model_name" : " text-embedding-3-large " ,
"dimension" : 3072
}Размеры для различных моделей Azure Openai Entricdings можно найти в документации Azure Openai Models.
При использовании более новых моделей Enterdings (V3) вы также можете использовать их поддержку для сокращения внедрения. В этом случае укажите количество необходимых вам измерений, и добавьте флаг shorten_dimensions , чтобы указать, что вы хотите сократить вторжения. Например:
{
"type" : " azure " ,
"model_name" : " text-embedding-3-large " ,
"dimension" : 256 ,
"shorten_dimensions" : true
}{
"type" : " sentence-transformer " ,
"model_name" : " the name of the sentence transformer model " ,
"dimension" : " the dimension of the model. This field is not required if model name is one of ['all-MiniLM-L6-v2', 'all-mpnet-base-v2', 'bert-large-nli-mean-tokens] "
}Приводящий пример гипотетического ответа на вопрос в запросе, гипотетический отрывок, который придерживается ответа на запрос или генерирует мало альтернативных связанных с этим вопросом, может улучшить поиск и, таким образом, получить более точные куски документов для перехода в контекст LLM. Основано на справочной статье - точный плотный поиск с нулевым выстрелом без меток релевантности (гипотетические документы).
Следующие параметры конфигурации включают эти подходы к экспериментам:
{
"hyde" : " generated_hypothetical_answer "
}{
"hyde" : " generated_hypothetical_document_to_answer "
} Эта функция будет генерировать тонкие вопросы, связанные с точными, отфильтровать те, которые меньше, чем min_query_expansion_related_question_similarity_score Процент из исходного запроса (используя оценку сходства косинуса), и поиск документов для каждого из них вместе с исходным запросом, дедупликации результатов и возврата их к реранкуркеру и лучшим K.
Значение по умолчанию для min_query_expansion_related_question_similarity_score установлено на 90%, вы можете изменить это в config.json
{
"query_expansion" : true ,
"min_query_expansion_related_question_similarity_score" : 90
}Решение интегрируется с Azure Machine Learning и использует Mlflow для управления экспериментами, рабочими и артефактами. Вы можете просмотреть следующие отчеты как часть процесса оценки:
all_metrics_current_run.html показывает средние оценки по вопросам и типам поиска для каждой выбранной метрики:
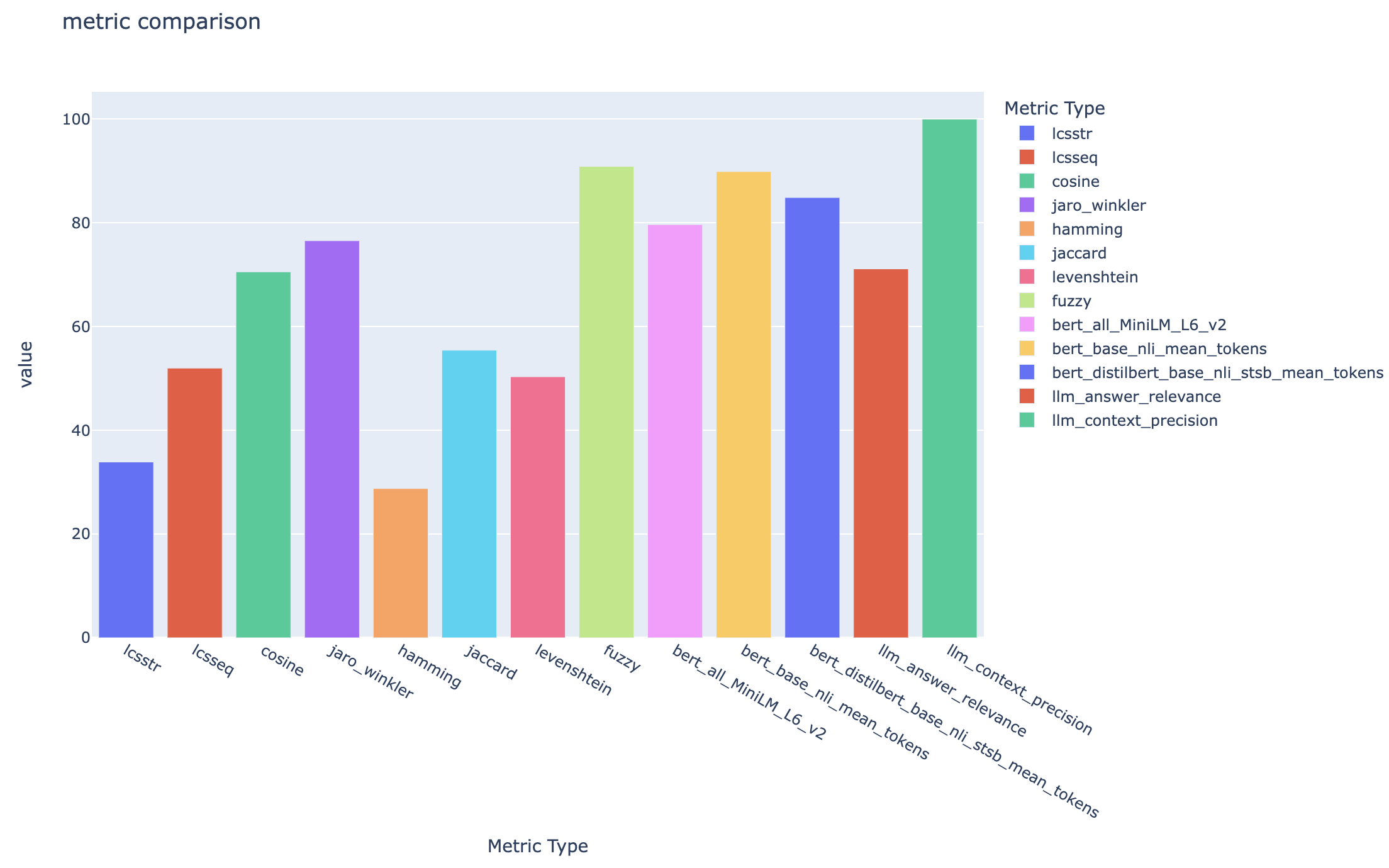
Вычисление каждой метрики и поля, используемых для оценки, отслеживаются для каждого вопроса и типа поиска в выходном файле CSV:
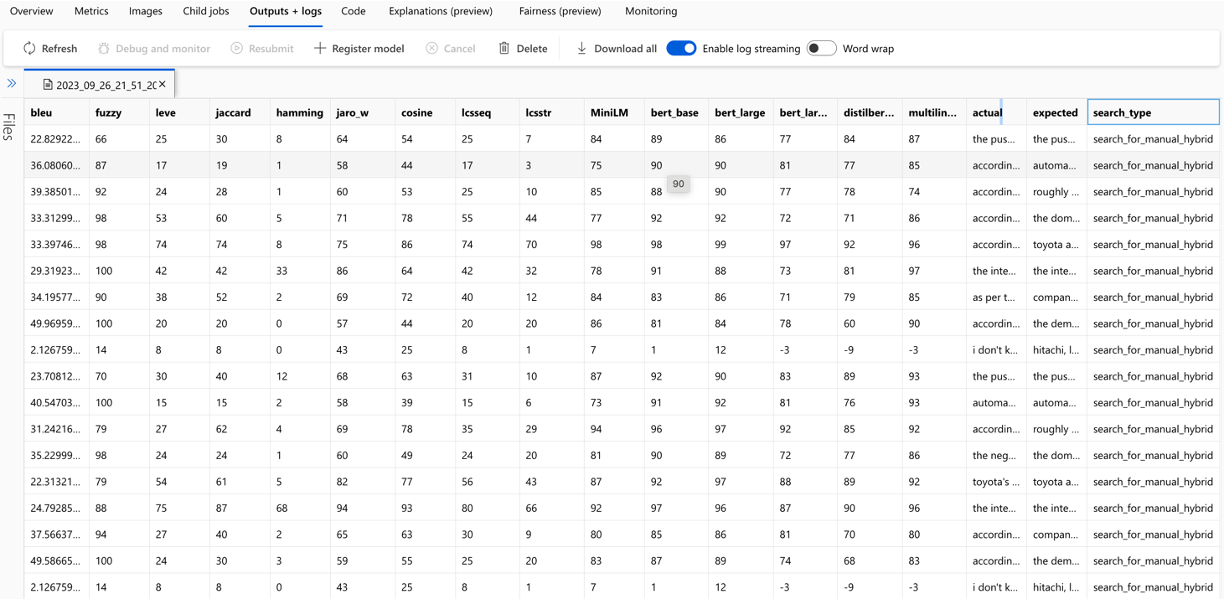
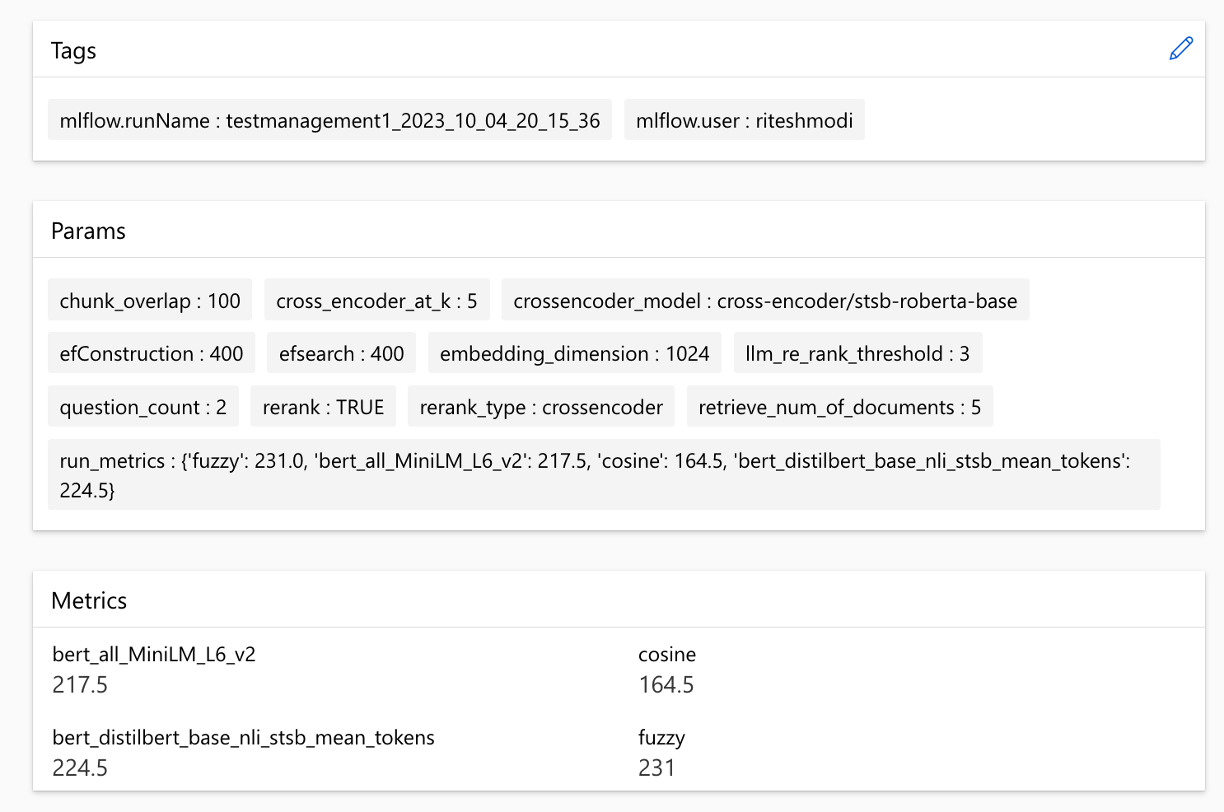
Метрики можно сравнить по пробегам:
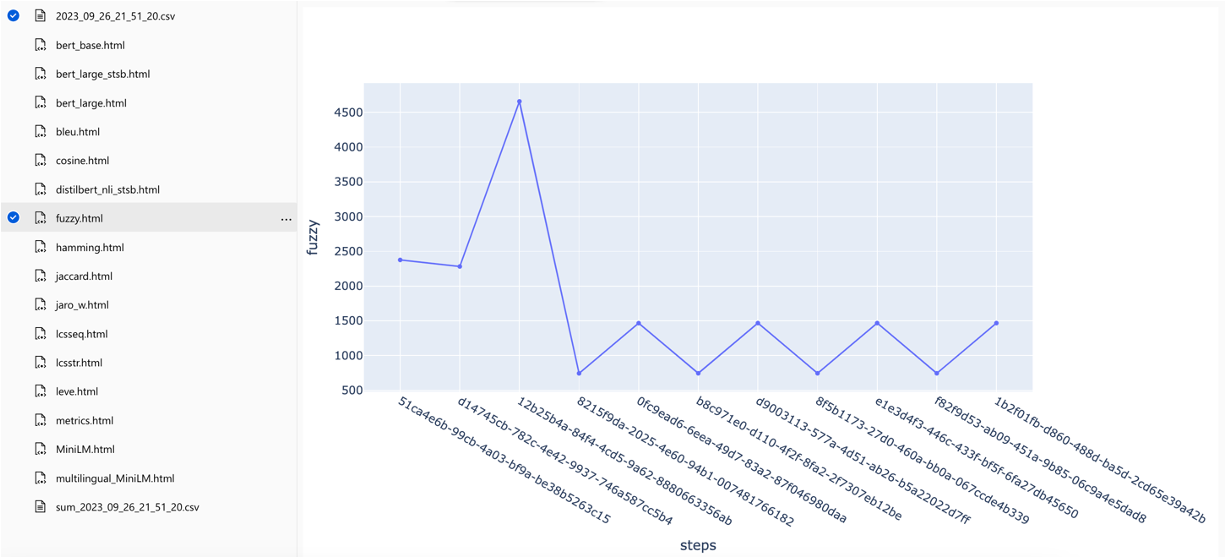
Метрики можно сравнить по разным стратегиям поиска:
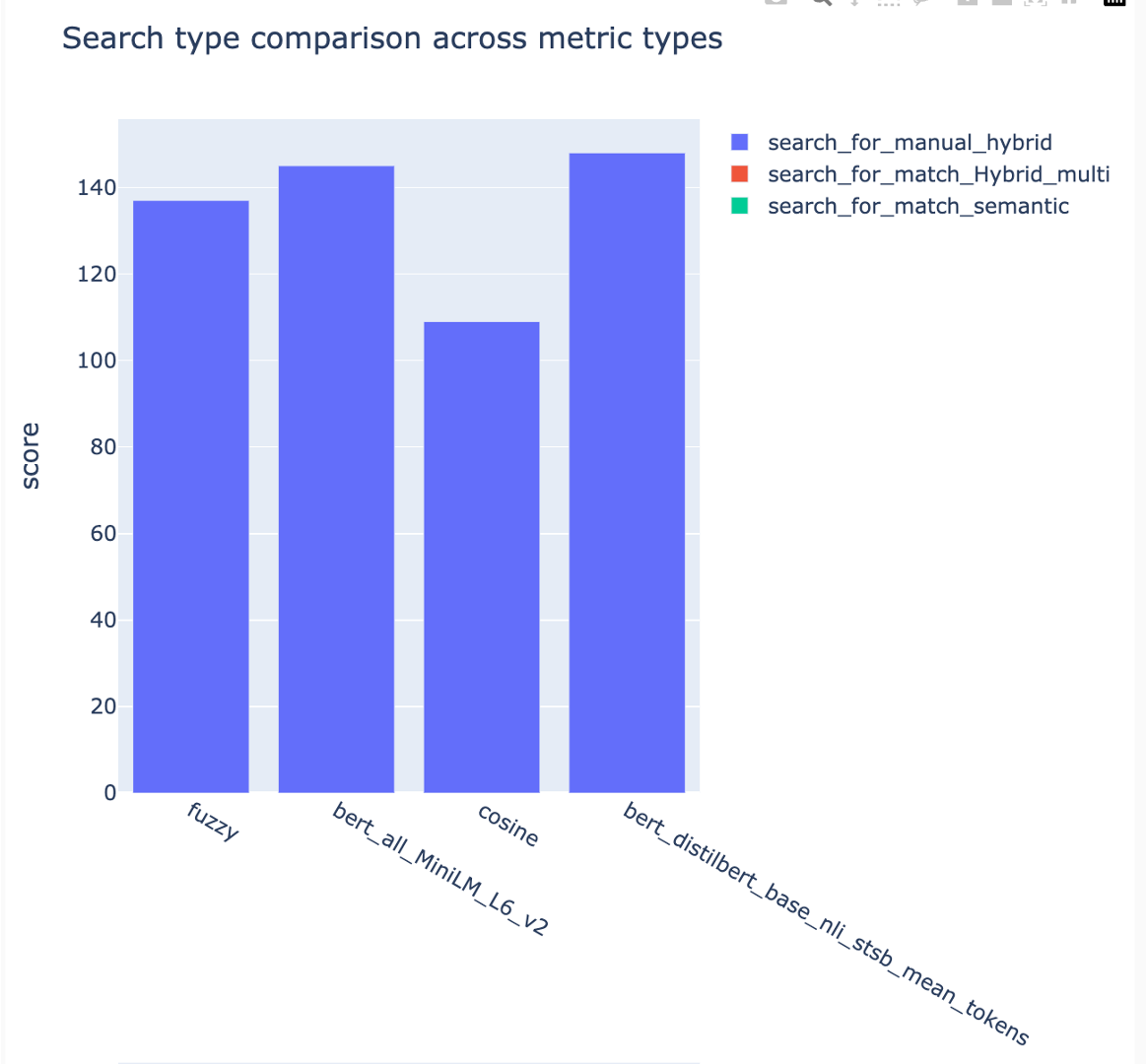
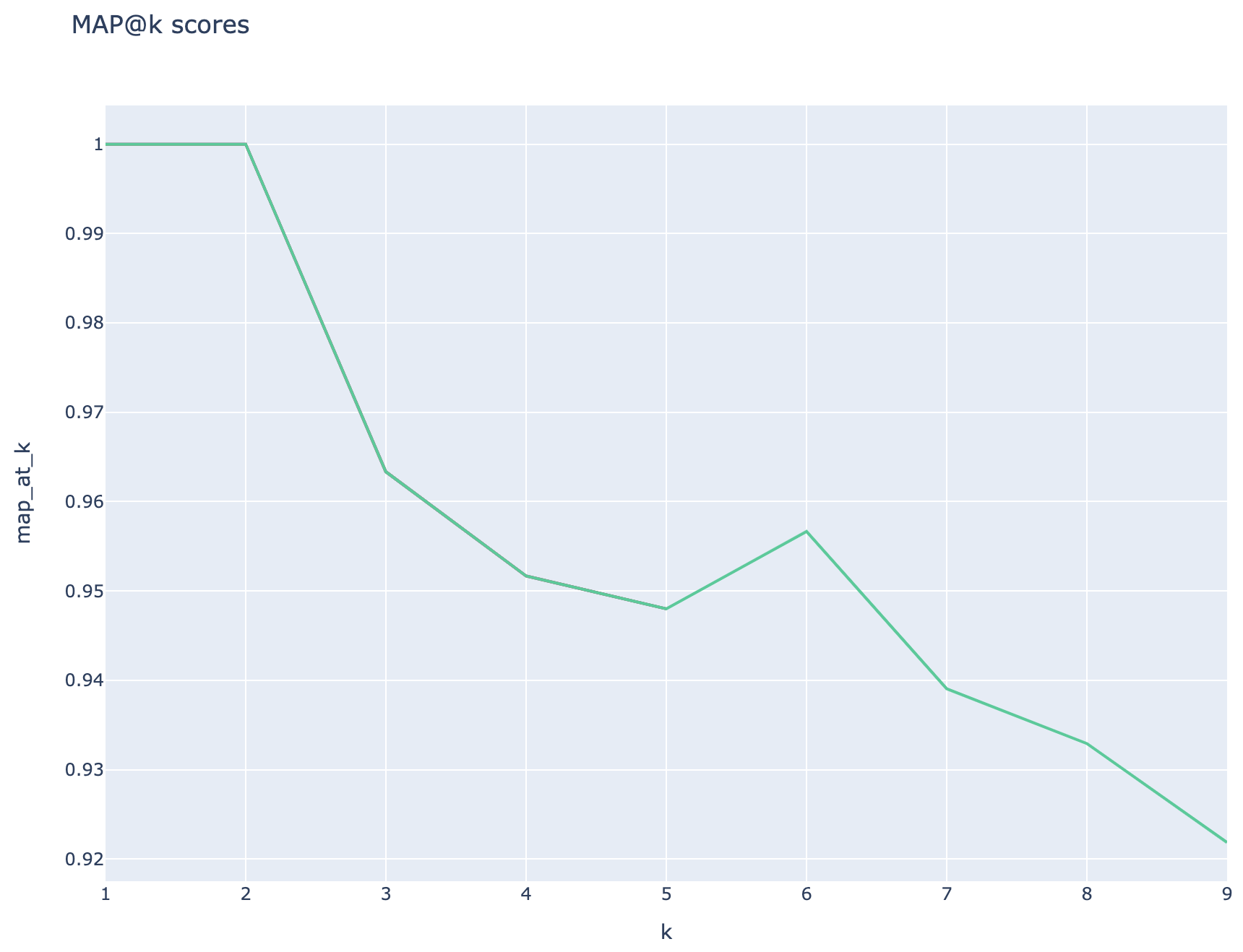
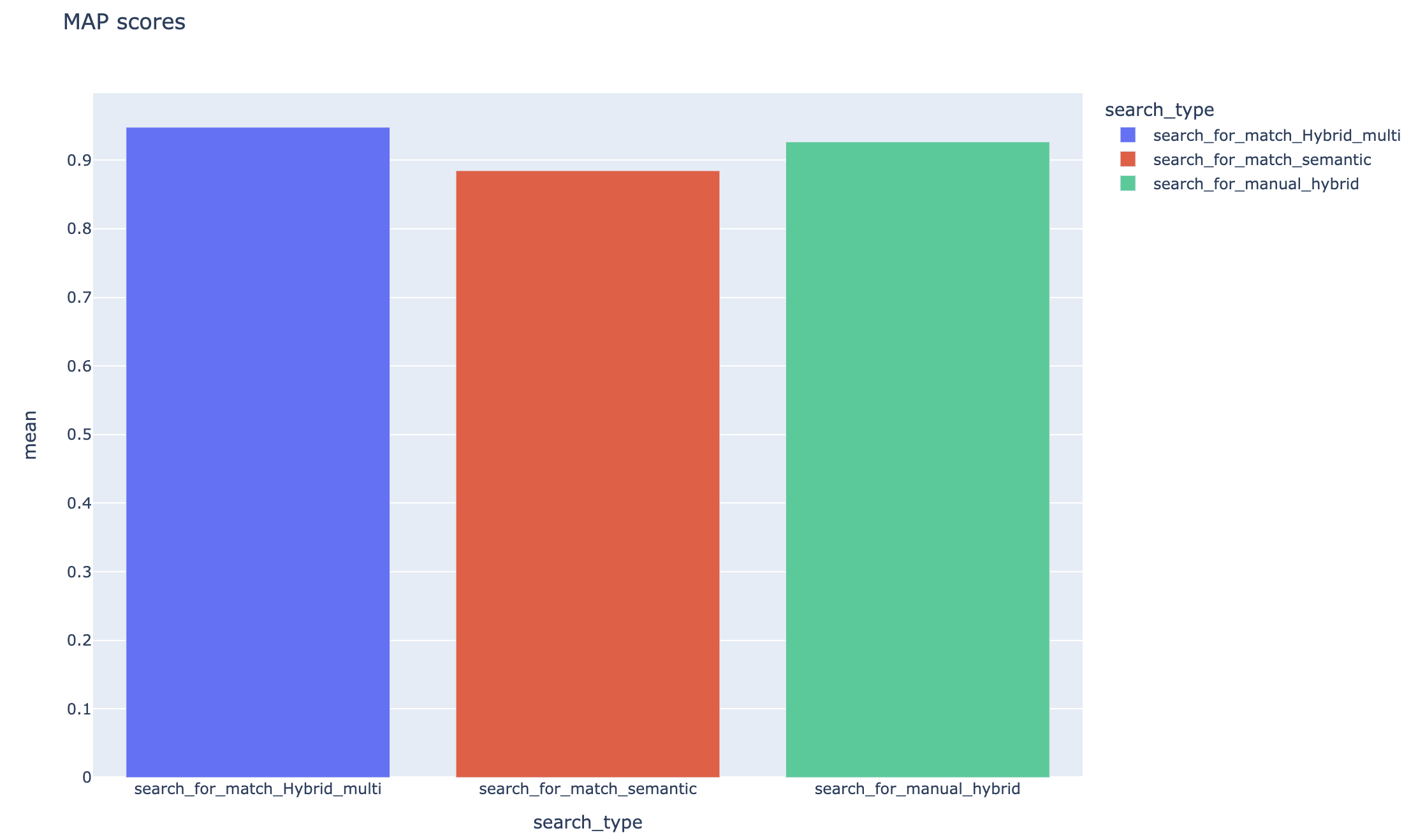
Средние средние показатели точности отслеживаются, а средние показатели карты можно сравнить по типу поиска:
В этом разделе описываются общие GotChas или подводные камни, с которыми могут столкнуться инженеры/разработчики/ученые, работающие с учеными, работая с RAG Experiment Accelerator.
Чтобы успешно использовать это решение, вы должны сначала аутентифицировать себя, вошли в свою учетную запись Azure. Этот важный шаг гарантирует, что у вас есть необходимые разрешения для доступа и управления ресурсами Azure, используемых им. Вы можете ошибки, связанные с хранением данных QNA в активах данных машинного обучения Azure, выполнением этапа запроса и оценки в результате ненадлежащей авторизации и аутентификации Azure. Обратитесь к пункту 4 в этом документе для аутентификации и авторизации.
Могут быть ситуации, в которых решение все еще будет генерировать ошибки, несмотря на действительную аутентификацию и авторизацию. В таких случаях запустите новый сеанс с совершенно новым экземпляром терминала, входите в Azure, используя шаги, упомянутые на шаге 4, а также проверьте, имеет ли пользователь доступ к ресурсам Azure, связанным с решением.
Это решение использует несколько параметров конфигурации в config.json , которые напрямую влияют на его функциональность и производительность. Пожалуйста, обратите пристальное внимание на эти настройки:
reture_num_of_documents: эта конфигурация управляет начальным количеством документов, полученных для анализа. Чрезмерно высокие или низкие значения могут привести к ошибкам «индексировать вне диапазона» из -за ранжирования результатов поискового ИИ.
cross_encoder_at_k: эта конфигурация влияет на процесс ранжирования. Высокая стоимость может привести к тому, что неактуальные документы включены в окончательные результаты.
LLM_RERANK_THRESHOLD: Эта конфигурация определяет, какие документы передаются в языковую модель (LLM) для дальнейшей обработки. Установка этого значения слишком высока может создать чрезмерно большой контекст для обработки LLM, что может привести к ошибкам обработки или ухудшению результатов. Это также может привести к исключению из конечной точки Azure Openai.
Прежде чем запустить это решение, убедитесь, что вы правильно настроили как свое имя развертывания Azure Openai в файле config.json, так и добавите соответствующие секреты в переменные среды (.env file). Эта информация имеет решающее значение для приложения, чтобы подключиться к соответствующим ресурсам Azure Openai и функционированию, как и разработано. Если вы не уверены в данных конфигурации, пожалуйста, см. Решение было протестировано с помощью модели GPT 3.5 Turbo и требует дальнейших тестов для любой другой модели.
На шаге генерации QNA вы можете иногда сталкиваться с ошибками, связанными с выходом JSON, полученным от Azure OpenAI. Эти ошибки могут предотвратить успешное поколение нескольких вопросов и ответов. Вот что вам нужно знать:
Неправильное форматирование: вывод JSON из Azure OpenAI может не придерживаться ожидаемого формата, вызывая проблемы с процессом генерации QNA. Фильтрация контента: Azure Openai имеет на месте контент. Если входной текст или сгенерированные ответы считаются неуместными, это может привести к ошибкам. Ограничения API: Услуга Azure OpenAI имеет ограничения токена и скорости, которые влияют на выход.
Средние показатели оценки: не все метрики, сравнивающие сгенерированные и грунтовые ответы, способны отражать различия в семантике. Например, такие метрики, как levenshtein или jaro_winkler измеряют только расстояния редактирования. Метрика cosine также не позволяет сравнивать семантику: она использует реализацию на основе токков TextDistance на основе термин-частотных векторов. Чтобы рассчитать семантическое сходство между сгенерированными ответами и ожидаемыми ответами, рассмотрите возможность использования метрик на основе встраивания, таких как баллы BERT ( bert_ ).
Метрики оценки компонентов: метрики оценки с использованием LLM-as Judges не детерминированные. Метрики llm_ , включенные в акселератор, используют модель, указанную в поле конфигурации azure_oai_eval_deployment_name . Подсказки, используемые для инструкции по оценке, могут быть скорректированы и включены в файл prompts.py ( llm_answer_relevance_instruction , llm_context_recall_instruction , llm_context_precision_instruction ).
Метрики на основе поиска: показатели карт рассчитываются путем сравнения каждого извлеченного куски с вопросом и кусочком, используемым для генерации пары QNA. Чтобы оценить, является ли извлеченный кусок или нет, сходство между извлеченным кусочком и объединением вопроса конечного пользователя и чанком, используемым на шаге QNA ( 02_qa_generation.py ), вычисляется с использованием SpacyEvaluator. Сходство SPACY по умолчанию со средним значением векторов токенов, что означает, что вычисление нечувствительно к порядку слов. По умолчанию порог сходства устанавливается на 80% ( spacy_evaluator.py ).
Мы приветствуем ваш вклад и предложения. Чтобы внести свой вклад, вам необходимо согласиться с лицензионным соглашением о участнике (CLA), которое подтверждает, что вы имеете право и фактически предоставить нам права на использование вашего вклада. Для получения подробной информации, посетите [https://cla.opensource.microsoft.com].
Когда вы отправляете запрос на привлечение, бот CLA автоматически проверит, нужно ли вам предоставить CLA и дать вам инструкции (например, проверка состояния, комментарий). Следуйте инструкциям от бота. Вам нужно сделать это только один раз для всех репо, которые используют наш CLA.
Прежде чем внести свой вклад, обязательно бегите
pip install -e .
pre-commit install
Этот проект следует за Microsoft Open Source Code поведения. Для получения дополнительной информации см. Code of Perving FAQ или свяжитесь с [email protected] с любыми вопросами или комментариями.
bug/11-short-descriptionfeature/22-short-descriptionexample_snake_case .git config --global user.name "First Last"Этот проект может содержать товарные знаки или логотипы для проектов, продуктов или услуг. Вы должны следовать руководящим принципам Microsoft по торговле и бренду, чтобы правильно использовать товарные знаки или логотипы Microsoft. Не используйте товарные знаки Microsoft или логотипы в модифицированных версиях этого проекта таким образом, чтобы это приводит к путанице или подразумевает спонсорство Microsoft. Следуйте политикам любых сторонних товарных знаков или логотипов, которые содержит этот проект.


