super json mode
1.0.0
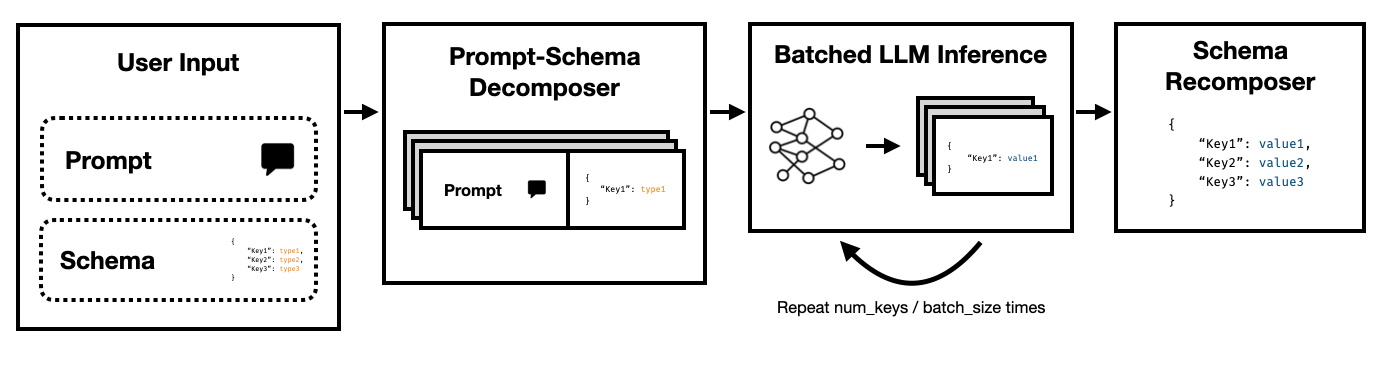
Super JSON Mode - это структура Python, которая обеспечивает эффективное создание структурированного вывода из LLM путем разбивания целевой схемы на атомные компоненты, а затем выполняя поколения параллельно.
Он поддерживает оба состояния Art LLM с помощью API завершения Openai API и LLMS с открытым исходным кодом, таких как The Hearging Face Transformers и VLLM . В ближайшее время будет поддержано больше LLMS!
По сравнению с наивным трубопроводом генерации JSON, полагающимся на подсказки и трансформаторы HF, мы обнаруживаем, что режим Super JSON может генерировать выходы на 10 раз быстрее . Это также более детерминированно и менее склонна сталкиваться с проблемами разбора по сравнению с наивным поколением.
Установка проста: pip install super-json-mode
Структурированные выходные форматы, такие как JSON или YAML, имеют присущую параллельную или иерархическую структуру.
Рассмотрим следующий неструктурированный проход (сгенерированный GPT-4):
Добро пожаловать на 123 Azure Lane, потрясающую резиденцию Сан -Франциско, обладающая фантастическим современным дизайном, теперь на рынке за 2 500 000 долларов. Эта собственность, разбросанная на роскошные 3000 квадратных футов, сочетает в себе изысканность и комфорт, чтобы создать действительно уникальный опыт жизни.
Идиллический дом для семей или профессионалов, наша эксклюзивная резиденция оснащена пятью просторными спальнями, каждая из которых сочилась тепло и современной элегантностью. Спальни тщательно спланированы, чтобы обеспечить достаточный естественный свет и щедрое место для хранения. С тремя элегантно разработанными полными ванными комнатами резиденция гарантирует удобство и конфиденциальность для своих жителей.
Большой вход приводит вас к просторной жилой зоне, обеспечивая отличную атмосферу для встреч или тихого вечера у пожара. Кухня шеф-повара включает в себя современные приборы, нестандартные шкафы и красивые гранитные столешницы, что делает его мечтой для всех, кто любит готовить.
Если мы хотим извлечь address , square footage , number of bedrooms , number of bathrooms и price используя LLM, мы могли бы попросить модель заполнить схему в соответствии с описанием.
Потенциальная схема (такая как одна, сгенерированная из пидантического объекта) может выглядеть так:
{
"address": {
"type": "string"
},
"price": {
"type": "number"
},
"square_feet": {
"type": "integer"
},
"num_beds": {
"type": "integer"
},
"num_baths": {
"type": "integer"
}
}
И действительный вывод может выглядеть примерно так:
{
"address": "123 Azure Lane",
"price": 2500000,
"square_feet": 3000,
"num_beds": 5,
"num_baths": 3
}
Очевидный подход состоит в том, чтобы гнездовать схему в приглашении и попросить модель заполнить ее. В настоящее время большинство команд в настоящее время извлекают структурированный выход из неструктурированного текста с использованием LLMS.
Однако это неэффективно по трем причинам.
Обратите внимание, как каждый из этих ключей не зависит друг от друга. Super Json Mode использует преимущества быстрого параллелизма , рассматривая каждую пару ключевых значений в схеме как отдельное расследование. Например, мы можем извлечь num_baths , не сгенерировав address !
Запрашивая модель для генерации JSON с нуля без необходимости потреблять токены (и, следовательно, время) на предсказуемом синтаксисе, таких как брекеты и имена клавиш, которые уже ожидаются в результате вывода. Это сильный ранее поколение, которое мы должны иметь возможность использовать для улучшения задержек.
LLMS смущающе параллельны, а заводящие запросы в партиях намного быстрее, чем в серийном порядке. Таким образом, мы можем разделить схему на несколько запросов. Затем LLM заполнит схему для каждого независимого ключа параллельно и излучает гораздо меньше токенов за один проход, что позволяет гораздо более быстрое время вывода.
Запустите следующую команду:
pip install super-json-mode
conda create --name superjsonmode python=3.10 -y
conda activate superjsonmode
git clone https://github.com/varunshenoy/super-json-mode
cd superjsonmode
pip install -r requirements.txt
Мы попытались сделать Super Json Mode Super Easy в использовании. Смотрите папку examples для получения дополнительных примеров и использования vLLM .
Используя OpenAI и gpt-3-instruct-turbo :
from superjsonmode . integrations . openai import StructuredOpenAIModel
from pydantic import BaseModel
import time
model = StructuredOpenAIModel ()
class Character ( BaseModel ):
name : str
genre : str
age : int
race : str
occupation : str
best_friend : str
home_planet : str
prompt_template = """{prompt}
Please fill in the following information about this character for this key. Keep it succinct. It should be a {type}.
{key}: """
prompt = """Luke Skywalker is a famous character."""
start = time . time ()
output = model . generate (
prompt ,
extraction_prompt_template = prompt_template ,
schema = Character ,
batch_size = 7 ,
stop = [ " n n " ],
temperature = 0 ,
)
print ( f"Total time: { time . time () - start } " )
# Total Time: 0.409s
print ( output )
# {
# "name": "Luke Skywalker",
# "genre": "Science fiction",
# "age": "23",
# "race": "Human",
# "occupation": "Jedi Knight",
# "best_friend": "Han Solo",
# "home_planet": "Tatooine",
# }Использование MiStral 7B с трансформаторами HuggingChingface:
from transformers import AutoTokenizer , AutoModelForCausalLM
from superjsonmode . integrations . transformers import StructuredOutputForModel
from pydantic import BaseModel
device = "cuda"
model = AutoModelForCausalLM . from_pretrained ( "mistralai/Mistral-7B-Instruct-v0.2" ). to ( device )
tokenizer = AutoTokenizer . from_pretrained ( "mistralai/Mistral-7B-Instruct-v0.2" )
# Create a structured output object
structured_model = StructuredOutputForModel ( model , tokenizer )
passage = """..."""
class QuarterlyReport ( BaseModel ):
company : str
stock_ticker : str
date : str
reported_revenue : str
dividend : str
prompt_template = """[INST]{prompt}
Based on this excerpt, extract the correct value for "{key}". Keep it succinct. It should have a type of `{type}`.[/INST]
{key}: """
output = structured_model . generate ( passage ,
extraction_prompt_template = prompt_template ,
schema = QuarterlyReport ,
batch_size = 6 )
print ( json . dumps ( output , indent = 2 ))
# {
# "company": "NVIDIA",
# "stock_ticker": "NVDA",
# "date": "2023-10",
# "reported_revenue": "18.12 billion dollars",
# "dividend": "0.04"
# } Есть много функций, которые могут сделать Super JSON режим лучше. Вот некоторые идеи.
Качественный анализ вывода : мы запустили контрольные показатели производительности, но мы должны придумать более строгий подход к оценке качественных результатов режима Super JSON.
Структурированная выборка : в идеале мы должны замаскировать логиты LLM для обеспечения ограничений типа, аналогично JSONFORMER. Есть несколько пакетов, которые уже делают это, и либо они должны интегрировать наш параллелизированный конвейер генерации JSON, либо мы должны построить его в режим Super JSON.
Поддержка графика зависимости : режим Super JSON имеет очень очевидный случай сбоя: когда ключ имеет зависимость от другого ключа. Рассмотрим каплю JSON с двумя ключами, thought и response . Этот вид желаемого вывода является обычным явлением для цепочки мыслей с большими языковыми моделями, и очень ясно, что response зависит от thought . Мы должны быть в состоянии передать график зависимостей и партийных подсказок таким образом, чтобы родительские результаты были завершены и переданы на элементы детской схемы.
Поддержка локальной модели : режим Super JSON лучше всего работает в локальных ситуациях, когда размер партии обычно является 1. Вы можете использовать партии, чтобы уменьшить задержку, аналогично спекулятивному декодированию. Llama.cpp - это главная структура для локальных моделей + вывод процессора. Я хотел бы реализовать это с помощью Ollama, если это возможно.
Поддержка TRT-LLM : VLLM отличная и проста в использовании, но в идеале мы интегрируемся с гораздо более эффективной структурой, такой как TRT-LLM.
Мы ценим это, если вы, пожалуйста, процитируйте этот репо, если вы нашли библиотеку полезной для вашей работы:
@misc{ShenoyDerhacobian2024,
author = {Shenoy, Varun and Derhacobian, Alex},
title = {Super JSON Mode: A Framework for Accelerated Structured Output Generation},
year = {2024},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/varunshenoy/super-json-mode}}
}
Этот проект был построен для CS 229: Системы для машинного обучения. Огромное спасибо учебной команде и TAS за их руководство на протяжении всего этого проекта.


