conversational agent langchain
Basic Updates
Это увольнение для отдыха для разговорного агента, который позволяет встраивать документы, искать их с помощью семантического поиска, для QA на основе документов и выполнять обработку документов с помощью больших языковых моделей.
На данный момент я перерабатываю Langgraph, поэтому не все версии в основном будут работать со всеми поставщиками. Я буду обновлять поставщиков в ближайшие недели. Пожалуйста, используйте релизы, чтобы получить рабочую версию.
Если вы хотите использовать только бэкэнд Aleph Alpha, я бы порекомендовал свой другой бэкэнд: https://github.com/mfmezger/aleph-alpha-rag.
Чтобы запустить полную систему с Docker, используйте эту команду:
git clone https://github.com/mfmezger/conversational-agent-langchain.git
cd conversational-agent-langchainСоздайте файл .env из .env-template и установите ключ Qdrant API. Для тестов просто установите его на тестирование. Qdrant_api_key = "test"
Затем запустите систему с
docker compose up -dЗатем перейдите по адресу http://127.0.0.1:8001/docs или http://127.0.0.1:8001/redoc, чтобы увидеть документацию API.
Frontend: Localhost: 8501 Qdrant Dashboard: Localhost: 6333/Dashboard
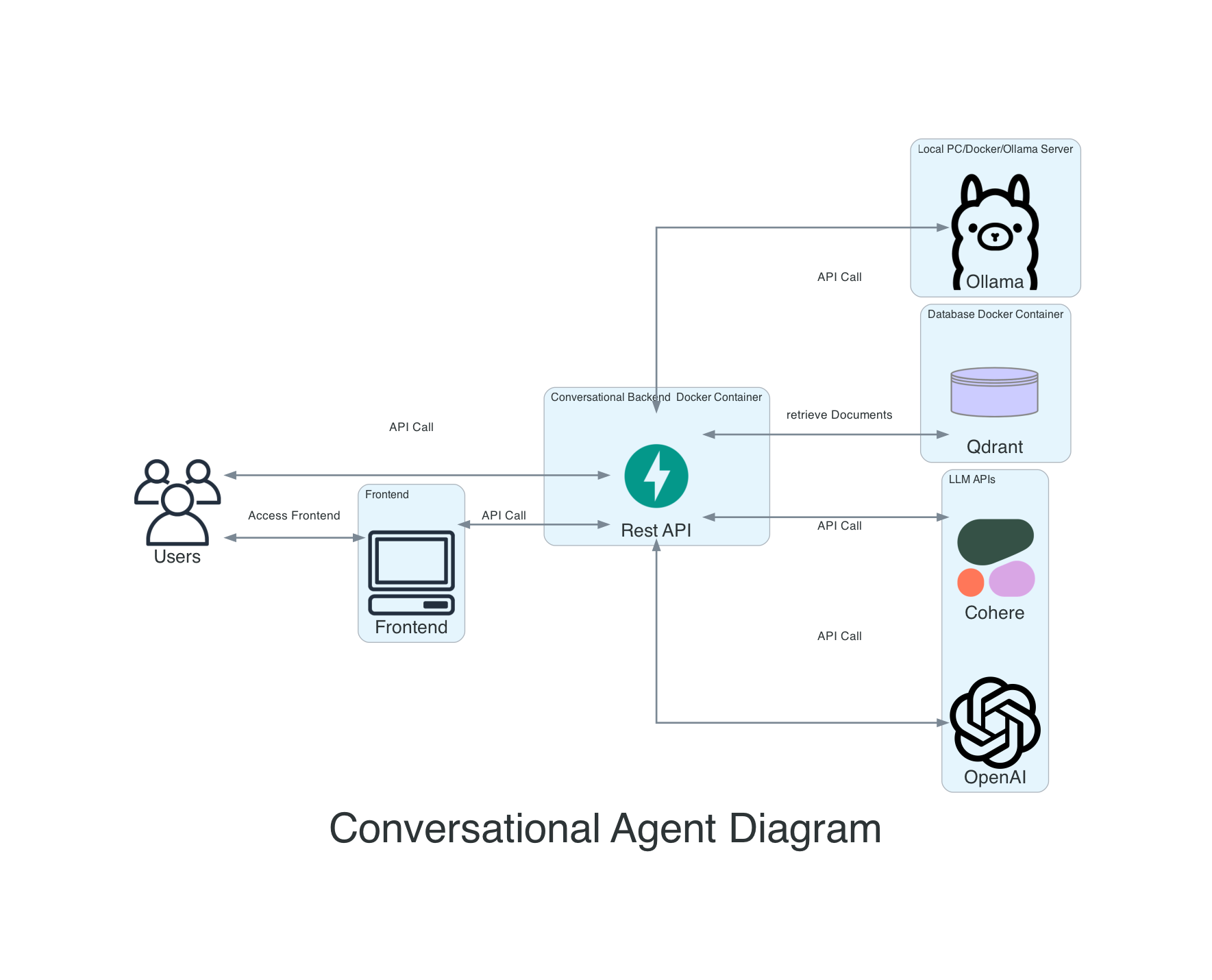
Этот проект является разговорным агентом, который использует модели Aleph Alpha и Openai на больших языках для создания ответов на запросы пользователей. Агент также включает в себя векторную базу данных и API REST, построенный с FASTAPI.
Функции
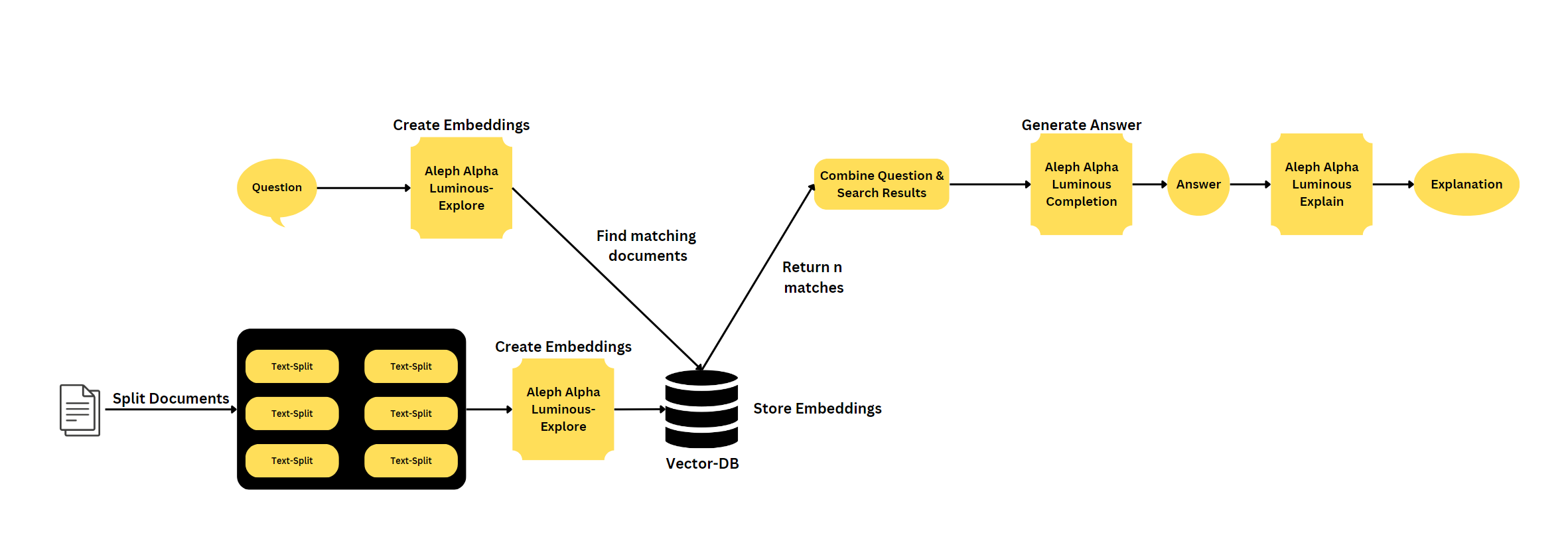
Семантический поиск - это расширенный метод поиска, целью которого является понимание значения и контекста запроса пользователя, а не сопоставление ключевых слов. Он включает в себя обработку естественного языка (NLP) и алгоритмы машинного обучения для анализа и интерпретации намерений пользователя, синонимов, отношений между словами и структуры содержания. Рассматривая эти факторы, семантический поиск повышает точность и актуальность результатов поиска, обеспечивая более интуитивно понятный и персонализированный пользовательский опыт.
Langchain - это библиотека для обработки естественного языка и машинного обучения. FOSTAPI-это современная, быстрая (высокопроизводительная) веб-структура для построения API с Python 3.7+ на основе стандартных подсказок типа Python. Vectordatabase - это база данных, которая хранит векторы, которые можно использовать для поиска сходства и других задач машинного обучения.
Доступны два способа управления вашим API -ключами, самый простой подход - отправить токен API в запрос в качестве токена. Другая возможность - создать файл .env и добавить токен API там. Если вы используете OpenAI из Azure или OpenAI напрямую, вам нужно установить правильные параметры в файле .env.
На Linux или Mac вам необходимо настроить файл /etc /hosts, чтобы включить следующую строку:
127.0.0.1 qdrantСначала установить зависимости от питона:
Вам нужно установить рожь, если вы хотите использовать его для синхронизации файла Telects.lock. Рай установка.
rye sync
# or if you do not want to use rye
pip install -r requirements.lockНачните полную систему с:
docker compose up -dЧтобы запустить базу данных Qdrant Local Just Run:
docker compose up qdrantДля запуска бэкэнд используйте эту команду в корневом каталоге:
poetry run uvicorn agent.api:app --reloadЧтобы запустить тесты, вы можете использовать эту команду:
poetry run coverage run -m pytest -o log_cli=true -vvv testsЧтобы запустить фронт. Используйте эту команду в корневом каталоге:
poetry run streamlit run gui.py --theme.base= " dark "Mypy Rag-Explicite-Package-Bases
Приборная панель Qdrant доступна по адресу http://127.0.0.1:6333/dashboard. Там вам нужно ввести клавишу API.
Чтобы использовать Qdrant API, вам необходимо установить правильные параметры в файле .env. Qdrant_api_key - это ключ API для Qdrant API. И вам нужно изменить его в файле qdrant.yaml в папке конфигурации.
Если вы хотите пригласить большое количество данных, я бы порекомендовал использовать сценарии, расположенные в агенте/проглатывании.
Чтобы проверить API, я бы порекомендовал Бруно. Запросы API хранятся в папке ConvagentBruno.


