คำพูดที่เป็นธรรมชาติ2
v1.0
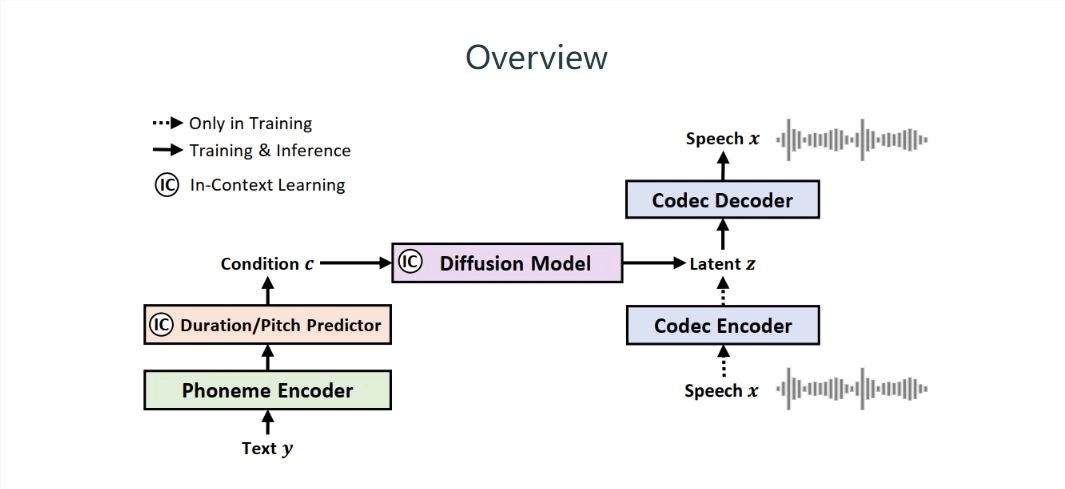
naturalspeech2 github เมื่อเร็ว ๆ นี้ Microsoft ประกาศว่าจะเปิดตัวโมเดลขนาดใหญ่ใหม่: NaturalSpeech2 เมื่อเปรียบเทียบกับรุ่นขนาดใหญ่ก่อนหน้านี้ การสร้างเสียงพูดของ NaturalSpeech2 ใหม่นั้น "แม่นยำยิ่งขึ้น" จะไม่ "ติดการอ่าน" และสามารถนำผู้ใช้ได้รับประสบการณ์ที่ดีขึ้นและให้บริการ .
Microsoft เพิ่งเปิดตัวโมเดลคำพูดที่เรียกว่า NaturalSpeech2 โมเดลนี้ใช้การออกแบบ "การกระจายที่เป็นไปได้" และมีผลลัพธ์ที่โดดเด่นในระดับการสังเคราะห์คำพูดแบบไม่มีตัวอย่าง Microsoft อ้างว่าโมเดลดังกล่าวมอบโซลูชันการพูด/ร้องเพลง "ระดับเชิงพาณิชย์" ที่สามารถให้ได้ ผู้ใช้จะได้รับประสบการณ์การสังเคราะห์เสียงคุณภาพสูงและหลากหลาย
Microsoft ดำเนินการชุดสาธิต NaturalSpeech2 ซึ่งแสดงให้เห็นถึงความสามารถในการสร้างคำพูดที่มีตัวตนของผู้พูด ฉันทลักษณ์ และสไตล์ที่แตกต่างกัน (เช่น การร้องเพลง) ในสถานการณ์ที่ไม่มีตัวอย่าง
มีรายงานว่า NaturalSpeech2 ของ Microsoft ต่างจากระบบคำพูดเป็นข้อความ (TTS) แบบดั้งเดิมตรงที่ใช้ "เวกเตอร์ต่อเนื่อง" แทน "เครื่องหมายแยก" เพื่อแสดงคำพูด ดังนั้นจึงสร้างส่วนของคำพูดที่สมบูรณ์มากขึ้น และไม่สร้าง "การอ่านแบบแท่ง" นั่นคือ " ไร้ซึ่งอารมณ์" (พูดทีละคำ)" ปรากฏการณ์
ผลการทดลองแสดงให้เห็นว่าคำพูดที่สร้างโดย NaturalSpeech2 ภายใต้เงื่อนไขตัวอย่างเป็นศูนย์เกือบจะสอดคล้องกับฉันทลักษณ์ของคำพูดและคำพูดจริง และความเป็นธรรมชาติ (วัดโดย CMOS) ในชุดทดสอบ LibriTTS และ VCTK นั้นแยกไม่ออกจากคำพูดจริง
บทความสำหรับโครงการนี้ปัจจุบันเผยแพร่บน GitHub
1. รุ่นใหญ่ที่ Microsoft เปิดตัวอย่างเป็นทางการ
2. จะนำปฏิสัมพันธ์ใหม่ๆ มากมายมาสู่ผู้เล่น
3. ขณะนี้อยู่ระหว่างการพัฒนาอย่างเข้มข้น โปรดติดตามต่อไป