Apache ShardingSphere ระบบนิเวศชั้นกลางฐานข้อมูลแบบกระจาย v5.5.0
5.5.0
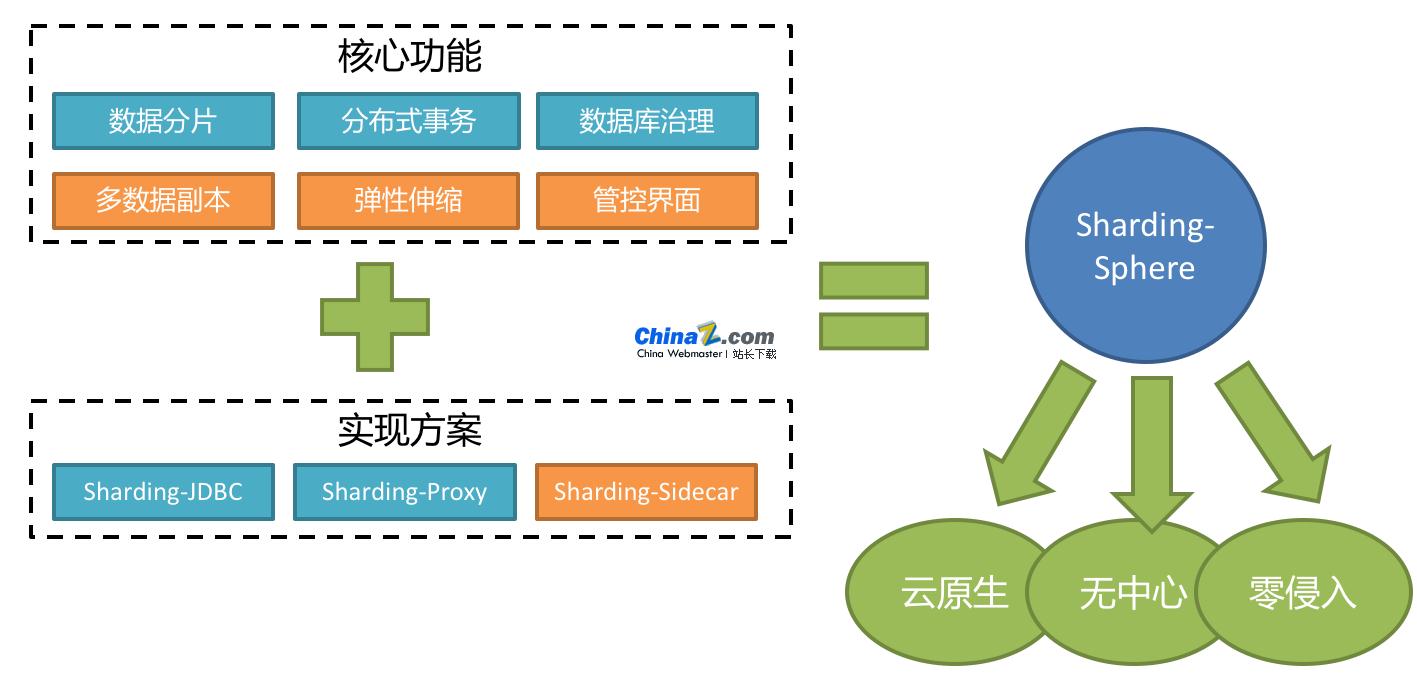
Apache ShardingSphere คือระบบนิเวศที่ประกอบด้วยชุดโซลูชันมิดเดิลแวร์ฐานข้อมูลแบบโอเพ่นซอร์สที่ประกอบด้วย JDBC, Proxy และ Sidecar (อยู่ระหว่างการวางแผน) ซึ่งเป็นผลิตภัณฑ์ 3 ชนิดที่แยกจากกัน แต่สามารถปรับใช้และใช้งานร่วมกันได้ ทั้งหมดนี้มอบการแบ่งส่วนข้อมูลที่เป็นมาตรฐาน ธุรกรรมแบบกระจาย และฟังก์ชันการจัดการฐานข้อมูล และสามารถนำไปใช้กับสถานการณ์แอปพลิเคชันที่หลากหลาย เช่น Java Isomorphism, ภาษาที่แตกต่าง, Cloud Native เป็นต้น
Apache ShardingSphere ถูกกำหนดให้เป็นมิดเดิลแวร์ฐานข้อมูลเชิงสัมพันธ์ โดยมีจุดมุ่งหมายเพื่อใช้ความสามารถในการประมวลผลและการจัดเก็บของฐานข้อมูลเชิงสัมพันธ์ในสถานการณ์แบบกระจายอย่างเต็มที่และสมเหตุสมผล แทนที่จะใช้ฐานข้อมูลเชิงสัมพันธ์ใหม่ มันรวบรวมแก่นแท้ของสิ่งต่าง ๆ โดยมุ่งเน้นไปที่ความไม่เปลี่ยนแปลง ฐานข้อมูลเชิงสัมพันธ์ยังคงอยู่ในตลาดขนาดใหญ่ในปัจจุบันและเป็นรากฐานสำคัญของธุรกิจหลักของแต่ละบริษัทในอนาคต ในขั้นตอนนี้ เราจะมุ่งเน้นไปที่การเพิ่มขึ้นตามรากฐานดั้งเดิมมากกว่าการบ่อนทำลาย
Apache ShardingSphere 5.x เริ่มมุ่งเน้นไปที่สถาปัตยกรรมที่เสียบปลั๊กได้ และส่วนประกอบการทำงานของโปรเจ็กต์สามารถขยายได้อย่างยืดหยุ่นในลักษณะที่เสียบปลั๊กได้ ในปัจจุบัน ฟังก์ชันต่างๆ เช่น การแบ่งส่วนข้อมูล การแยกอ่าน-เขียน สำเนาข้อมูลหลายชุด การเข้ารหัสข้อมูล และการทดสอบความเครียดของฐานข้อมูลเงา รวมถึงการรองรับ SQL และโปรโตคอล เช่น MySQL, PostgreSQL, SQLServer และ Oracle ล้วนรวมอยู่ใน โครงการผ่านปลั๊กอิน นักพัฒนาสามารถปรับแต่งระบบที่เป็นเอกลักษณ์ของตัวเองได้เหมือนกับการใช้แบบเอกสารสำเร็จรูป ปัจจุบัน Apache ShardingSphere มี SPI หลายสิบรายการเป็นจุดขยายของระบบ และยังมีอีกมากที่อยู่ระหว่างการเพิ่ม
ShardingSphere-JDBC
วางตำแหน่งเป็นเฟรมเวิร์ก Java แบบน้ำหนักเบา โดยให้บริการเพิ่มเติมในเลเยอร์ JDBC ของ Java ใช้ไคลเอนต์เพื่อเชื่อมต่อกับฐานข้อมูลโดยตรงและให้บริการในรูปแบบของแพ็คเกจ jar โดยไม่ต้องปรับใช้และการขึ้นต่อกันเพิ่มเติม สามารถเข้าใจได้ว่าเป็นไดรเวอร์ JDBC เวอร์ชันปรับปรุงและเข้ากันได้กับ JDBC และเฟรมเวิร์ก ORM ต่างๆ
ใช้ได้กับเฟรมเวิร์ก ORM ที่ใช้ JDBC เช่น: JPA, Hibernate, Mybatis, Spring JDBC Template หรือใช้ JDBC โดยตรง
รองรับพูลการเชื่อมต่อฐานข้อมูลบุคคลที่สาม เช่น DBCP, C3P0, BoneCP, Druid, HikariCP เป็นต้น
รองรับฐานข้อมูลใด ๆ ที่ใช้ข้อกำหนด JDBC ในปัจจุบัน รองรับ MySQL, Oracle, SQLServer, PostgreSQL และฐานข้อมูลใด ๆ ที่เป็นไปตามมาตรฐาน SQL92
ShardingSphere-พร็อกซี
โดยวางตำแหน่งเป็นตัวแทนฐานข้อมูลแบบโปร่งใส โดยจัดเตรียมเซิร์ฟเวอร์ที่ห่อหุ้มโปรโตคอลไบนารี่ของฐานข้อมูลเพื่อรองรับภาษาที่ต่างกัน ปัจจุบัน MySQL และ PostgreSQL มีให้บริการ โดยสามารถใช้ไคลเอ็นต์การเข้าถึงใดๆ ที่เข้ากันได้กับโปรโตคอล MySQL/PostgreSQL (เช่น MySQL Command Client, MySQL Workbench, Navicat ฯลฯ) เพื่อดำเนินการข้อมูล ทำให้เป็นมิตรกับ DBA มากขึ้น
มีความโปร่งใสอย่างสมบูรณ์สำหรับแอปพลิเคชัน และสามารถใช้เป็นเซิร์ฟเวอร์ MySQL/PostgreSQL ได้โดยตรง
ใช้ได้กับไคลเอนต์ที่รองรับโปรโตคอล MySQL/PostgreSQL
ShardingSphere-รถเทียมข้างรถจักรยานยนต์ (TODO)
วางตำแหน่งเป็นพร็อกซีฐานข้อมูลบนคลาวด์สำหรับ Kubernetes โดยมอบพร็อกซีการเข้าถึงฐานข้อมูลทั้งหมดในรูปแบบของ Sidecar โซลูชันแบบไร้ศูนย์กลางและการบุกรุกเป็นศูนย์มอบเลเยอร์การมีส่วนร่วมที่โต้ตอบกับฐานข้อมูล ซึ่งก็คือ Database Mesh หรือที่เรียกว่าตารางฐานข้อมูล
จุดเน้นของ Database Mesh คือวิธีเชื่อมต่อแอปพลิเคชันการเข้าถึงข้อมูลแบบกระจายและฐานข้อมูล โดยเน้นที่การโต้ตอบและการเรียงลำดับการโต้ตอบระหว่างแอปพลิเคชันและฐานข้อมูลที่ยุ่งเหยิงอย่างมีประสิทธิภาพ การใช้ Database Mesh แอปพลิเคชันและฐานข้อมูลที่เข้าถึงฐานข้อมูลจะสร้างระบบกริดขนาดใหญ่ในที่สุด แอปพลิเคชันและฐานข้อมูลจะต้องลงทะเบียนในระบบกริดเท่านั้น แอปพลิเคชันและฐานข้อมูลทั้งหมดจะถูกจัดการโดยเลเยอร์แบบตาข่าย
สถาปัตยกรรมไฮบริด
ShardingSphere-JDBC ใช้สถาปัตยกรรมแบบกระจายอำนาจและเหมาะสำหรับแอปพลิเคชัน OLTP น้ำหนักเบาประสิทธิภาพสูงที่พัฒนาใน Java ShardingSphere-Proxy ให้การสนับสนุนรายการแบบคงที่และภาษาที่แตกต่างกัน และเหมาะสำหรับแอปพลิเคชัน OLAP และการจัดการและการทำงานของฐานข้อมูลที่แบ่งส่วน
Apache ShardingSphere เป็นระบบนิเวศที่ประกอบด้วยเทอร์มินัลการเข้าถึงหลายเครื่อง ด้วยการผสมผสาน ShardingSphere-JDBC และ ShardingSphere-Proxy และใช้ศูนย์การลงทะเบียนเดียวกันเพื่อกำหนดค่ากลยุทธ์การแบ่งส่วนอย่างเท่าเทียมกัน ระบบแอปพลิเคชันที่เหมาะสมสำหรับสถานการณ์ต่างๆ จึงสามารถสร้างได้อย่างยืดหยุ่น ช่วยให้สถาปนิกสามารถปรับระบบที่ดีที่สุดสำหรับสถาปัตยกรรมปัจจุบันได้อย่างอิสระมากขึ้น
1. การกระจายตัวของข้อมูล
ไลบรารีย่อยและตารางย่อย
แยกการอ่านและการเขียน
การปรับแต่งกลยุทธ์การแบ่งส่วน
คีย์หลักแบบกระจายแบบไม่รวมศูนย์
2. ธุรกรรมแบบกระจาย
อินเทอร์เฟซการทำธุรกรรมที่ได้มาตรฐาน
XA การทำธุรกรรมที่สอดคล้องกันอย่างยิ่ง
กิจการที่ยืดหยุ่น
3. การจัดการฐานข้อมูล
การปกครองแบบกระจาย
การปรับขนาดแบบยืดหยุ่น
ความสามารถในการสังเกต (การติดตามแบบกระจาย ตัวชี้วัด)
การเข้ารหัสและถอดรหัสข้อมูล
การทดสอบแรงดันเกจเงา