อ่านเรื่องนี้เป็นภาษาอังกฤษ
GLM-4-Voice คือโมเดลคำพูดจากต้นทางถึงปลายทางที่ Zhipu AI เปิดตัว GLM-4-Voice สามารถเข้าใจและสร้างเสียงภาษาจีนและอังกฤษได้โดยตรง สนทนาด้วยเสียงแบบเรียลไทม์ และสามารถเปลี่ยนอารมณ์ น้ำเสียง ความเร็ว ภาษาถิ่น และคุณลักษณะอื่น ๆ ของเสียงตามคำแนะนำของผู้ใช้

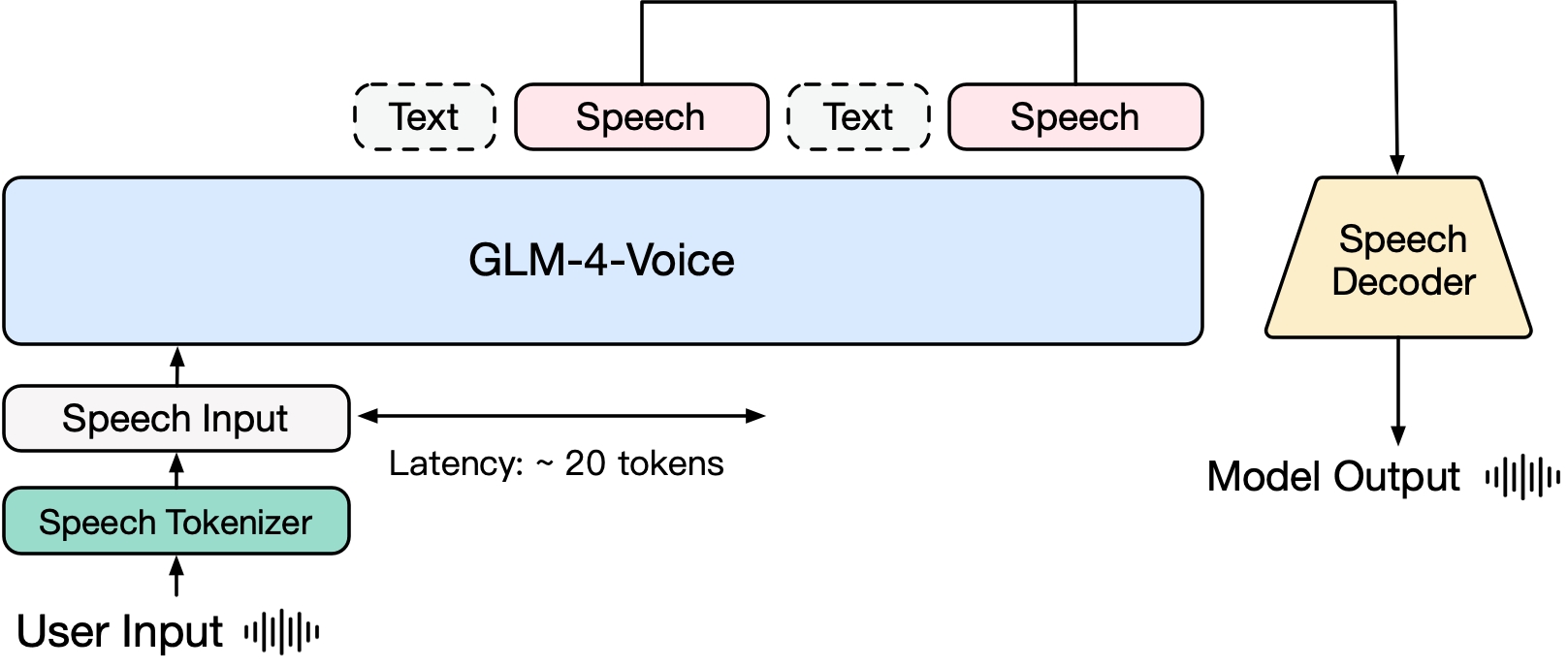
GLM-4-Voice ประกอบด้วยสามส่วน:
GLM-4-Voice-Tokenizer: ด้วยการเพิ่ม Vector Quantization ไปยังส่วนตัวเข้ารหัสของ Whisper และการฝึกอบรมภายใต้การดูแลเกี่ยวกับข้อมูล ASR การป้อนข้อมูลด้วยเสียงอย่างต่อเนื่องจะถูกแปลงเป็นโทเค็นแบบแยก โดยเฉลี่ยแล้ว เสียงจะต้องแสดงด้วยโทเค็นแยก 12.5 โทเค็นต่อวินาทีเท่านั้น
GLM-4-Voice-Decoder: เครื่องถอดรหัสเสียงพูดที่รองรับการใช้เหตุผลแบบสตรีม และได้รับการฝึกอบรมตามโครงสร้างโมเดล Flow Matching ของ CosyVoice เพื่อแปลงโทเค็นเสียงพูดแบบแยกเป็นเสียงพูดแบบต่อเนื่อง จำเป็นต้องมีโทเค็นเสียงอย่างน้อย 10 รายการเพื่อเริ่มสร้าง ช่วยลดความล่าช้าในการสนทนาจากต้นทางถึงปลายทาง
GLM-4-Voice-9B: อิงจาก GLM-4-9B มีการดำเนินการฝึกอบรมล่วงหน้าและการจัดตำแหน่งรูปแบบเสียงเพื่อทำความเข้าใจและสร้างโทเค็นเสียงที่แยกออกมา
ในแง่ของการฝึกอบรมล่วงหน้า เพื่อเอาชนะความยากลำบากสองประการของ IQ ของโมเดลและการแสดงออกสังเคราะห์ในโหมดคำพูด เราได้แยกงาน Speech2Speech ออกเป็น "การตอบกลับข้อความตามเสียงของผู้ใช้" และ "การสังเคราะห์คำพูดตาม การตอบกลับข้อความและคำพูดของผู้ใช้" สองงานและวัตถุประสงค์ก่อนการฝึกอบรมสองประการ ได้รับการออกแบบมาเพื่อสังเคราะห์ข้อมูลที่แทรกระหว่างข้อความคำพูดและข้อความโดยอิงตามข้อมูลข้อความก่อนการฝึกอบรมและข้อมูลเสียงที่ไม่ได้รับการดูแลเพื่อปรับให้เข้ากับรูปแบบงานทั้งสองนี้ จากโมเดลพื้นฐานของ GLM-4-9B นั้น GLM-4-Voice-9B ได้รับการฝึกอบรมล่วงหน้าด้วยเสียงหลายล้านชั่วโมงและโทเค็นข้อมูลแทรกข้อความเสียงหลายแสนล้านโทเค็น และมีความเข้าใจและสร้างโมเดลเสียงที่แข็งแกร่ง . ความสามารถ.
ในแง่ของการจัดตำแหน่ง เพื่อรองรับบทสนทนาด้วยเสียงคุณภาพสูง เราได้ออกแบบสถาปัตยกรรมการคิดแบบสตรีมมิ่ง: ตามเสียงของผู้ใช้ GLM-4-Voice สามารถส่งออกเนื้อหาในสองโหมด: ข้อความและเสียงในรูปแบบสตรีมมิ่ง โหมดเสียงแสดงโดย ข้อความถูกใช้เป็นข้อมูลอ้างอิงเพื่อให้แน่ใจว่าเนื้อหาตอบกลับมีคุณภาพสูง และการเปลี่ยนแปลงเสียงที่เกี่ยวข้องนั้นเกิดขึ้นตามความต้องการคำสั่งเสียงของผู้ใช้ โดยยังคงมีความสามารถในการจำลองแบบตั้งแต่ต้นทางถึงปลายทางในขณะที่ยังคงไว้ IQ ของโมเดลภาษาในระดับสูงสุด และในขณะเดียวกันก็มีความหน่วงต่ำ โดยจะต้องส่งออกโทเค็นอย่างน้อย 20 อันเพื่อสังเคราะห์เสียงพูด
รายงานทางเทคนิคที่มีรายละเอียดเพิ่มเติมจะเผยแพร่ในภายหลัง
| แบบอย่าง | พิมพ์ | ดาวน์โหลด |
|---|---|---|
| GLM-4-เสียง-Tokenizer | Tokenizer คำพูด | ? กอดใบหน้า ? |
| GLM-4-วอยซ์-9B | รูปแบบการแชท | ? กอดใบหน้า ? |
| GLM-4-เครื่องถอดรหัสเสียง | ตัวถอดรหัสคำพูด | ? กอดใบหน้า ? |
เรามี Web Demo ที่สามารถเริ่มต้นได้โดยตรง ผู้ใช้สามารถป้อนเสียงหรือข้อความได้ และโมเดลจะให้การตอบกลับทั้งเสียงและข้อความ

ขั้นแรกให้ดาวน์โหลดที่เก็บ
git clone --recurse-submodules https://github.com/THUDM/GLM-4-Voicecd GLM-4-Voice
จากนั้นติดตั้งการพึ่งพา คุณยังสามารถใช้รูปภาพ zhipuai/glm-4-voice:0.1 ที่เรามีให้เพื่อข้ามขั้นตอนนี้
pip ติดตั้ง -r ข้อกำหนด.txt
เนื่องจากโมเดลตัวถอดรหัสไม่รองรับการเริ่มต้นผ่าน transformers จึงจำเป็นต้องดาวน์โหลดจุดตรวจสอบแยกต่างหาก
# ดาวน์โหลดโมเดล git โปรดตรวจสอบให้แน่ใจว่าคุณได้ติดตั้ง git-lfsgit lfs install แล้ว โคลนคอมไพล์ https://huggingface.co/THUDM/glm-4-voice-decoder
เริ่มบริการโมเดล
python model_server.py --host localhost --model-path THUDM/glm-4-voice-9b --port 10,000 --dtype bfloat16 -- อุปกรณ์ cuda: 0
หากคุณต้องการบูตด้วยความแม่นยำ Int4 ให้รัน
python model_server.py --host localhost --model-path THUDM/glm-4-voice-9b --port 10000 --dtype int4 --อุปกรณ์ cuda: 0
คำสั่งนี้จะดาวน์โหลด glm-4-voice-9b โดยอัตโนมัติ หากสภาพเครือข่ายไม่ดี คุณสามารถดาวน์โหลดและระบุเส้นทางภายในเครื่องด้วยตนเองผ่าน --model-path
เริ่มบริการเว็บ
หลาม web_demo.py --tokenizer-path THUDM/glm-4-voice-tokenizer --model-path THUDM/glm-4-voice-9b --flow-path ./glm-4-voice-decoder
คุณสามารถเข้าถึงการสาธิตเว็บได้ที่ http://127.0.0.1:8888
คำสั่งนี้จะดาวน์โหลด glm-4-voice-tokenizer และ glm-4-voice-9b โดยอัตโนมัติ โปรดทราบว่าจำเป็นต้องดาวน์โหลด glm-4-voice-decoder ด้วยตนเอง
หากสภาพเครือข่ายไม่ดี คุณสามารถดาวน์โหลดโมเดลทั้งสามนี้ด้วยตนเอง จากนั้นระบุพาธในเครื่องผ่าน --tokenizer-path , --flow-path และ --model-path
การเล่นเสียงแบบสตรีมมิ่งของ Gradio ไม่เสถียร คุณภาพเสียงจะสูงขึ้นเมื่อคลิกในกล่องโต้ตอบหลังจากการสร้างเสร็จสมบูรณ์
เรามีตัวอย่างการสนทนาของ GLM-4-Voice รวมถึงการควบคุมอารมณ์ การเปลี่ยนความเร็วในการพูด การสร้างภาษาถิ่น ฯลฯ
นำทางฉันให้ผ่อนคลายด้วยเสียงแผ่วเบา
บรรยายการแข่งขันฟุตบอลด้วยเสียงที่ตื่นเต้น
เล่าเรื่องผีด้วยน้ำเสียงคร่ำครวญ
แนะนำว่าหน้าหนาวในภาษาถิ่นอีสานจะหนาวขนาดไหน
พูดว่า "กินองุ่นโดยไม่คายเปลือกองุ่น" ในภาษาถิ่นฉงชิ่ง
พูดลิ้นพันกันในภาษาปักกิ่ง
พูดเร็วขึ้น
เร็วขึ้น
ส่วนหนึ่งของรหัสสำหรับโครงการนี้มาจาก:
โคซี่วอยซ์
หม้อแปลงไฟฟ้า
GLM-4
การใช้ตุ้มน้ำหนักโมเดล GLM-4 จะต้องเป็นไปตามระเบียบวิธีของโมเดล
รหัสของที่เก็บโอเพ่นซอร์สนี้เป็นไปตามโปรโตคอล Apache 2.0