คลังข้อมูลเชิงวิเคราะห์ Apache Kylin v4.0.3 เวอร์ชันอย่างเป็นทางการ
4.0.3
Apache Kylin: เครื่องมือสืบค้นเสี้ยววินาทีสำหรับข้อมูลขนาดใหญ่มาก
ตัวแก้ไขดาวน์โค้ด
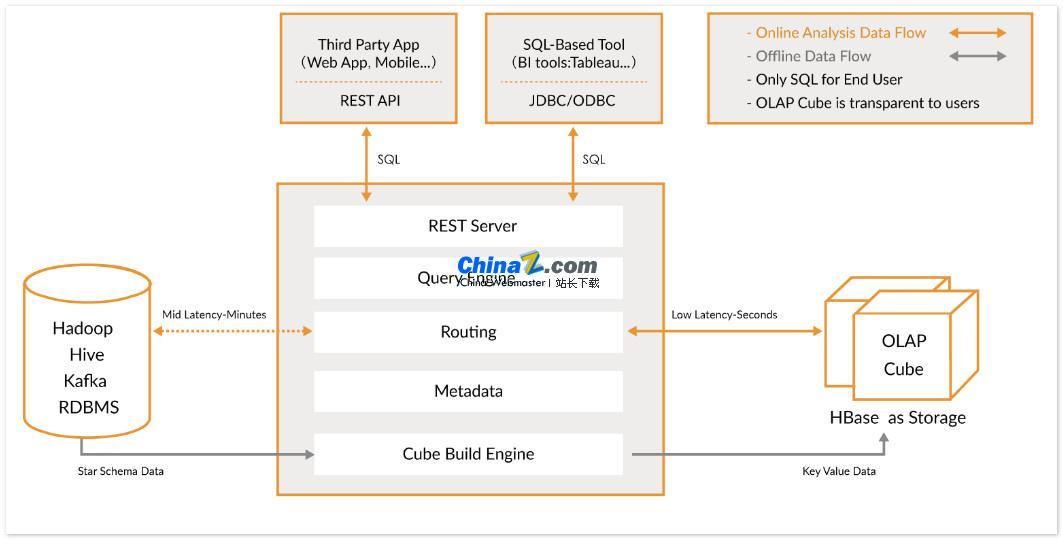
Apache Kylin เป็นคลังข้อมูลการวิเคราะห์แบบโอเพ่นซอร์สแบบกระจายที่มีความสามารถอินเทอร์เฟซการสืบค้น SQL และการวิเคราะห์หลายมิติ (OLAP) นอกเหนือจาก Hadoop/Spark และสามารถประมวลผลข้อมูลขนาดใหญ่มากได้อย่างมีประสิทธิภาพ เดิมพัฒนาโดย eBay และมีส่วนร่วมในชุมชนโอเพ่นซอร์ส โดยจะตอบคำถามเกี่ยวกับข้อมูลขนาดใหญ่ได้ภายในเสี้ยววินาที
สามขั้นตอนสำคัญของ Kylin
Kylin อนุญาตให้ผู้ใช้ดำเนินการค้นหาย่อยวินาทีกับชุดข้อมูลขนาดใหญ่มากในเวลาเพียงสามขั้นตอน:
1. กำหนดแบบจำลองดาวหรือเกล็ดหิมะบนชุดข้อมูลของคุณ: ขั้นแรก คุณต้องกำหนดแบบจำลองดาวหรือเกล็ดหิมะเพื่ออธิบายชุดข้อมูลของคุณ สิ่งนี้จะช่วยให้ Kylin เข้าใจความสัมพันธ์ระหว่างข้อมูลและเพิ่มประสิทธิภาพการสืบค้น
2. สร้าง Cube: สร้าง Cube บนตารางข้อมูลที่กำหนด Cube เป็นหน่วยสำหรับ Kylin ในการคำนวณล่วงหน้าและจัดเก็บข้อมูล ซึ่งสามารถปรับปรุงความเร็วการสืบค้นได้อย่างมาก
3. ใช้การสืบค้น SQL มาตรฐาน: ใช้ไวยากรณ์ SQL มาตรฐานเพื่อสืบค้น Cube ผ่าน ODBC, JDBC หรือ RESTFUL API Kylin สามารถส่งคืนผลลัพธ์การสืบค้นในหน่วยวินาทีย่อย
ความสามารถในการบูรณาการของ Kylin
Kylin ทำงานร่วมกับเครื่องมือสร้างภาพข้อมูลที่หลากหลาย เช่น Tableau, Power BI เป็นต้น ผู้ใช้สามารถใช้เครื่องมือ BI เหล่านี้เพื่อวิเคราะห์ข้อมูล Hadoop และแสดงข้อมูลเชิงลึกด้วยภาพ
สรุป
Apache Kylin เป็นเครื่องมืออันทรงพลังที่สามารถช่วยให้ผู้ใช้กรอกแบบสอบถามข้อมูลขนาดใหญ่มากได้ภายในเสี้ยววินาที ใช้งานง่าย ความสามารถในการปรับขนาด และประสิทธิภาพทำให้เหมาะสำหรับการจัดการการวิเคราะห์ข้อมูลขนาดใหญ่