bitnet.cpp เป็นเฟรมเวิร์กการอนุมานอย่างเป็นทางการสำหรับ 1-bit LLM (เช่น BitNet b1.58) มีชุดเคอร์เนลที่ได้รับการปรับปรุง ซึ่งรองรับการอนุมาน ที่รวดเร็ว และ ไม่สูญเสียข้อมูล ของโมเดล 1.58 บิตบน CPU (พร้อมรองรับ NPU และ GPU ในเร็วๆ นี้)
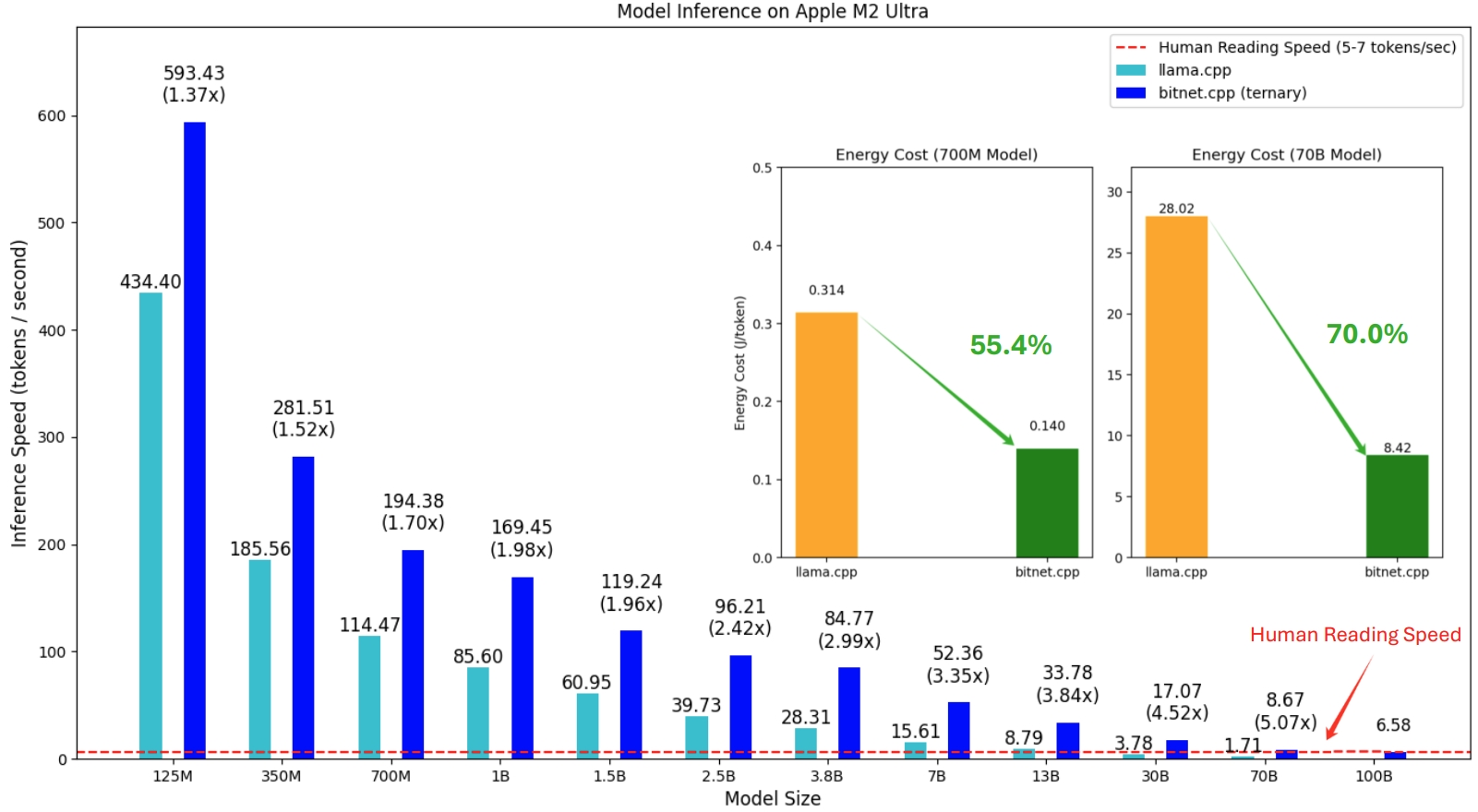
bitnet.cpp เปิดตัวครั้งแรกเพื่อรองรับการอนุมานบน CPU bitnet.cpp เพิ่มความเร็วได้ 1.37x ถึง 5.07x บน CPU ARM โดยที่โมเดลขนาดใหญ่จะมีประสิทธิภาพเพิ่มขึ้นมากขึ้น นอกจากนี้ยังลดการใช้พลังงานลง 55.4% เหลือ 70.0% ช่วยเพิ่มประสิทธิภาพโดยรวมอีกด้วย บนซีพียู x86 การเร่งความเร็วจะอยู่ในช่วงตั้งแต่ 2.37x ถึง 6.17x โดยมีการลดพลังงานระหว่าง 71.9% ถึง 82.2% นอกจากนี้ bitnet.cpp ยังสามารถรันรุ่น BitNet b1.58 ขนาด 100B บน CPU ตัวเดียว ซึ่งมีความเร็วเทียบเท่ากับการอ่านของมนุษย์ (5-7 โทเค็นต่อวินาที) ซึ่งช่วยเพิ่มศักยภาพในการรัน LLM บนอุปกรณ์ภายในเครื่องได้อย่างมาก โปรดดูรายงานทางเทคนิคสำหรับรายละเอียดเพิ่มเติม


แบบจำลองที่ทดสอบคือการตั้งค่าจำลองที่ใช้ในบริบทการวิจัยเพื่อสาธิตประสิทธิภาพการอนุมานของ bitnet.cpp
การสาธิต bitnet.cpp ที่ใช้งาน BitNet b1.58 3B รุ่นบน Apple M2:
21/10/2024 1-บิต AI Infra: ตอนที่ 1.1, BitNet ที่รวดเร็วและไม่สูญเสีย b1.58 การอนุมานบน CPU
17/10/2024 bitnet.cpp 1.0 เปิดตัว
21/03/2024 ยุคแห่ง 1 บิต LLMs__Training_Tips_Code_FAQ
27/02/2024 ยุคของ LLM 1 บิต: โมเดลภาษาขนาดใหญ่ทั้งหมดมีขนาด 1.58 บิต
10/10/2023 BitNet: การปรับขนาด Transformers 1 บิตสำหรับโมเดลภาษาขนาดใหญ่
โปรเจ็กต์นี้อิงตามเฟรมเวิร์ก llama.cpp เราขอขอบคุณผู้เขียนทุกท่านที่มีส่วนร่วมในชุมชนโอเพ่นซอร์ส นอกจากนี้ เคอร์เนลของ bitnet.cpp ยังสร้างขึ้นจากวิธีการ Lookup Table ที่บุกเบิกใน T-MAC สำหรับการอนุมาน LLM บิตต่ำทั่วไปนอกเหนือจากแบบจำลองที่ประกอบด้วยสาม เราขอแนะนำให้ใช้ T-MAC
❗️ เราใช้ LLM 1 บิตที่มีอยู่ใน Hugging Face เพื่อสาธิตความสามารถในการอนุมานของ bitnet.cpp โมเดลเหล่านี้ไม่ได้รับการฝึกอบรมหรือเผยแพร่โดย Microsoft เราหวังว่าการเปิดตัว bitnet.cpp จะเป็นแรงบันดาลใจในการพัฒนา LLM ขนาด 1 บิตในการตั้งค่าขนาดใหญ่ในแง่ของขนาดโมเดลและโทเค็นการฝึกอบรม
| แบบอย่าง | พารามิเตอร์ | ซีพียู | เคอร์เนล | ||
|---|---|---|---|---|---|
| I2_S | ทีแอล1 | ทีแอล2 | |||
| bitnet_b1_58-ขนาดใหญ่ | 0.7B | x86 | |||
| แขน | |||||
| bitnet_b1_58-3B | 3.3B | x86 | |||
| แขน | |||||
| Llama3-8B-1.58-100B-โทเค็น | 8.0B | x86 | |||
| แขน | |||||
หลาม>=3.9
ซีเมค>=3.22
เสียงดังกราว>=18
การพัฒนาเดสก์ท็อปด้วย C++
C++-เครื่องมือ CMake สำหรับ Windows
คอมไพล์สำหรับ Windows
C++-Clang Compiler สำหรับ Windows
การสนับสนุน MS-Build สำหรับ LLVM-Toolset (เสียงดังกราว)
สำหรับผู้ใช้ Windows ให้ติดตั้ง Visual Studio 2022 ในตัวติดตั้ง ให้สลับตัวเลือกต่อไปนี้เป็นอย่างน้อย (ซึ่งจะติดตั้งเครื่องมือเพิ่มเติมที่จำเป็นเช่น CMake โดยอัตโนมัติด้วย):
สำหรับผู้ใช้ Debian/Ubuntu คุณสามารถดาวน์โหลดด้วยสคริปต์การติดตั้งอัตโนมัติ
bash -c "$(wget -O - https://apt.llvm.org/llvm.sh)"
คอนดา (ขอแนะนำอย่างยิ่ง)
สำคัญ
หากคุณใช้ Windows โปรดอย่าลืมใช้ Developer Command Prompt / PowerShell สำหรับ VS2022 เสมอสำหรับคำสั่งต่อไปนี้
โคลน repo
git clone --recursive https://github.com/microsoft/BitNet.gitcd BitNet
ติดตั้งการพึ่งพา
# (แนะนำ) สร้างสภาพแวดล้อม conda ใหม่สร้าง -n bitnet-cpp python=3.9 conda เปิดใช้งาน bitnet-cpp pip ติดตั้ง -r ข้อกำหนด.txt
สร้างโครงการ
# ดาวน์โหลดโมเดลจาก Hugging Face แปลงเป็นรูปแบบ gguf เชิงปริมาณ และสร้าง projectpython setup_env.py --hf-repo HF1BitLLM/Llama3-8B-1.58-100B-tokens -q i2_s# หรือคุณสามารถดาวน์โหลดโมเดลด้วยตนเองและ รันด้วยการดาวน์โหลด pathhuggingface-cli ในเครื่อง HF1BitLLM/Llama3-8B-1.58-100B-tokens --local-dir models/Llama3-8B-1.58-100B-tokens python setup_env.py -md รุ่น/Llama3-8B-1.58-100B-tokens -q i2_s
การใช้งาน: setup_env.py [-h] [--hf-repo {1bitLLM/bitnet_b1_58-large,1bitLLM/bitnet_b1_58-3B,HF1BitLLM/Llama3-8B-1.58-100B-tokens}] [--model-dir MODEL_DIR] [ --log-dir LOG_DIR] [--ประเภทปริมาณ {i2_s,tl1}] [--ปริมาณ-ฝัง]
[--ใช้-pretuned]
ตั้งค่าสภาพแวดล้อมสำหรับการรันการอนุมาน
อาร์กิวเมนต์ทางเลือก:
-h, --help แสดงข้อความช่วยเหลือนี้และออก
--hf-repo {1bitLLM/bitnet_b1_58-large,1bitLLM/bitnet_b1_58-3B,HF1BitLLM/Llama3-8B-1.58-100B-โทเค็น}, -ชม {1bitLLM/bitnet_b1_58-large,1bitLLM/bitnet_b1_58-3B,HF1BitLLM/Llama3- 8B-1.58-100B-โทเค็น}
โมเดลที่ใช้ในการอนุมาน
--model-dir MODEL_DIR, -md MODEL_DIR
ไดเร็กทอรีสำหรับบันทึก/โหลดโมเดล
--log-dir LOG_DIR, -ld LOG_DIR
ไดเร็กทอรีสำหรับบันทึกข้อมูลการบันทึก
--quant-type {i2_s,tl1}, -q {i2_s,tl1}
ประเภทการหาปริมาณ
--quant-embd ปริมาณการฝังเป็น f16
--use-pretuned, -p ใช้พารามิเตอร์เคอร์เนลที่ปรับแต่งล่วงหน้า# เรียกใช้การอนุมานด้วย modelpython run_inference.py -m models/Llama3-8B-1.58-100B-tokens/ggml-model-i2_s.gguf -p "Daniel กลับไปที่สวน แมรี่เดินทางไปที่ห้องครัว แซนดร้า เดินทางไปที่ห้องครัว แซนดร้าไปที่ห้องโถง จอห์นไปที่ห้องนอน แมรี่กลับไปที่สวน แมรี่อยู่ไหน? nAnswer:" -n 6 -temp 0# Output:# Daniel กลับไปที่สวน แมรี่เดินทางไปที่ห้องครัว แซนดร้าเดินทางไปที่ห้องครัว แซนดราไปที่โถงทางเดิน จอห์นไปที่ห้องนอน แมรี่กลับเข้าไปในสวน แมรี่อยู่ที่ไหน?# คำตอบ: แมรี่อยู่ในสวน
การใช้งาน: run_inference.py [-h] [-m MODEL] [-n N_PREDICT] -p PROMPT [-t THREADS] [-c CTX_SIZE] [-temp TEMPERATURE]
เรียกใช้การอนุมาน
อาร์กิวเมนต์ทางเลือก:
-h, --help แสดงข้อความช่วยเหลือนี้และออก
-m รุ่น --รุ่น รุ่น
เส้นทางไปยังไฟล์โมเดล
-n N_PREDICT, --n-ทำนาย N_PREDICT
จำนวนโทเค็นที่ต้องทำนายเมื่อสร้างข้อความ
-p พร้อมท์, --พร้อมท์พร้อมท์
แจ้งให้สร้างข้อความจาก
-t THREADS, --threads เธรด
จำนวนเธรดที่จะใช้
-c CTX_SIZE, --ctx ขนาด CTX_SIZE
ขนาดของบริบทพร้อมท์
-อุณหภูมิ อุณหภูมิ, --อุณหภูมิ อุณหภูมิ
อุณหภูมิ ไฮเปอร์พารามิเตอร์ที่ควบคุมการสุ่มของข้อความที่สร้างขึ้นเราจัดทำสคริปต์เพื่อรันเกณฑ์มาตรฐานการอนุมานโดยจัดทำโมเดล
usage: e2e_benchmark.py -m MODEL [-n N_TOKEN] [-p N_PROMPT] [-t THREADS] Setup the environment for running the inference required arguments: -m MODEL, --model MODEL Path to the model file. optional arguments: -h, --help Show this help message and exit. -n N_TOKEN, --n-token N_TOKEN Number of generated tokens. -p N_PROMPT, --n-prompt N_PROMPT Prompt to generate text from. -t THREADS, --threads THREADS Number of threads to use.
ต่อไปนี้เป็นคำอธิบายโดยย่อของแต่ละข้อโต้แย้ง:
-m , --model : เส้นทางไปยังไฟล์โมเดล นี่เป็นอาร์กิวเมนต์ที่จำเป็นซึ่งจะต้องระบุเมื่อเรียกใช้สคริปต์
-n , --n-token : จำนวนโทเค็นที่จะสร้างระหว่างการอนุมาน เป็นอาร์กิวเมนต์เผื่อเลือกซึ่งมีค่าเริ่มต้นเป็น 128
-p , --n-prompt : จำนวนโทเค็นพร้อมท์ที่จะใช้ในการสร้างข้อความ นี่เป็นอาร์กิวเมนต์ทางเลือกที่มีค่าเริ่มต้นเป็น 512
-t , --threads : จำนวนเธรดที่จะใช้สำหรับการรันการอนุมาน เป็นอาร์กิวเมนต์ทางเลือกที่มีค่าเริ่มต้นเป็น 2
-h , --help : แสดงข้อความช่วยเหลือและออก ใช้อาร์กิวเมนต์นี้เพื่อแสดงข้อมูลการใช้งาน
ตัวอย่างเช่น:
หลาม utils/e2e_benchmark.py -m /path/to/model -n 200 -p 256 -t 4
คำสั่งนี้จะรันเกณฑ์มาตรฐานการอนุมานโดยใช้โมเดลที่อยู่ที่ /path/to/model สร้าง 200 โทเค็นจากพรอมต์โทเค็น 256 รายการ โดยใช้ 4 เธรด
สำหรับเค้าโครงโมเดลที่ไม่รองรับโดยโมเดลสาธารณะใดๆ เราจะจัดเตรียมสคริปต์เพื่อสร้างโมเดลจำลองด้วยเค้าโครงโมเดลที่กำหนด และรันการวัดประสิทธิภาพบนเครื่องของคุณ:
python utils/generate-dummy-bitnet-model.py models/bitnet_b1_58-large --outfile models/dummy-bitnet-125m.tl1.gguf --outtype tl1 --model-size 125M# รันการวัดประสิทธิภาพด้วยโมเดลที่สร้างขึ้น ใช้ -m เพื่อระบุพาธของโมเดล -p เพื่อระบุพรอมต์ที่ประมวลผล -n เพื่อระบุจำนวนโทเค็นเพื่อสร้าง python utils/e2e_benchmark.py -m models/dummy-bitnet-125m.tl1.gguf -p 512 -n 128