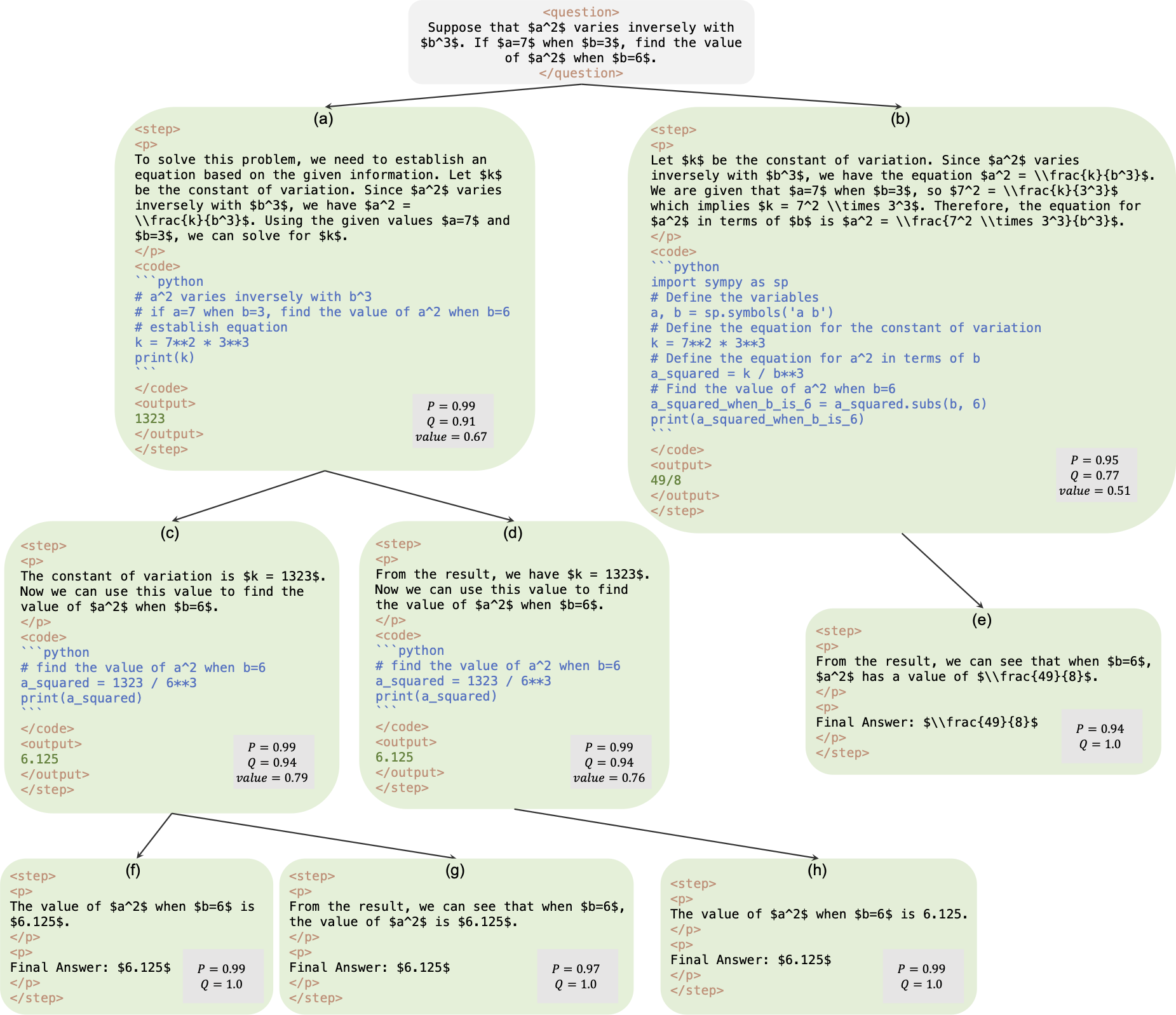
นี่คือพื้นที่เก็บข้อมูลอย่างเป็นทางการสำหรับกระดาษ AlphaMath Near Zero: การควบคุมกระบวนการโดยไม่มีกระบวนการ รหัสนี้ดึงมาจากฐานรหัสภายในองค์กรของเรา ด้วยเหตุนี้ อาจมีความแตกต่างเล็กน้อยเมื่อทำซ้ำตัวเลขที่รายงานในรายงานของเรา แต่ตัวเลขเหล่านี้ควรจะใกล้เคียงกันมาก แนวทางของเราเกี่ยวข้องกับการฝึกอบรมโมเดลนโยบายและคุณค่าโดยใช้เพียงการให้เหตุผลทางคณิตศาสตร์ที่ได้รับจากกรอบงาน Monte Carlo Tree Search (MCTS) โดยไม่จำเป็นต้องใช้ GPT-4 หรือคำอธิบายประกอบของมนุษย์ นี่คือตัวอย่างการฝึกอบรมที่สร้างโดย MCTS ในรอบที่ 3
ด่าน : AlphaMath-7B รอบ 3 ? / AlphaMath-7B รอบ 3 ?
ชุดข้อมูล : AlphaMath-Round3-Trainset ? กระบวนการแก้ไขปัญหาของข้อมูลการฝึกอบรมจะถูกสร้างขึ้นโดยอัตโนมัติตาม MCTS และจุดตรวจสอบในรอบที่ 2 ทั้งตัวอย่างเชิงบวกและเชิงลบรวมอยู่ในการฝึกอบรมโมเดลนโยบายและคุณค่า
รหัสการฝึกอบรม : ตามนโยบาย เราสามารถเปิดเผยรายละเอียดการใช้งานของฟังก์ชันหลักบางอย่างเท่านั้น ซึ่งโดยพื้นฐานแล้วควรได้รับการแก้ไขในรหัสการฝึกอบรมของคุณเอง
| วิธีการอนุมาน | ความแม่นยำ | เฉลี่ย เวลา (s) ต่อ q | เฉลี่ย ขั้นตอน | #โซล |
|---|---|---|---|---|
| โลภ | 53.62 | 1.6 | 3.1 | 1 |
| พ.ต.5 | 61.84 | 2.9 | 2.9 | 5 |
| ลำแสงระดับขั้น (1,5) | 62.32 | 3.1 | 3.0 | ด้านบน-1 |
| 5 รอบ + พ.ค.@5 | 67.04 | x5 | x1 | 5 อันดับแรก-1 |
| ลำแสงระดับขั้น (2,5) | 64.66 | 2.4 | 2.4 | ด้านบน-1 |
| ลำแสงระดับขั้น (3,5) | 65.74 | 2.3 | 2.2 | ด้านบน-1 |
| ลำแสงระดับขั้น (5,5) | 65.98 | 4.7 | 2.3 | ด้านบน-1 |
| 1 รอบ + พ.ค.@5 | 66.54 | x1 | x1 | 5 อันดับแรก |
| 5 รอบ + พ.ค.@5 | 69.94 | x5 | x1 | 5 อันดับแรก-1 |
| เอ็มซีทีเอส (N=40) | 64.02 | 10.1 | 3.8 | ด้านบน-1 |
+ Maj@5 ต้องวิ่ง 5 ครั้ง ซึ่งส่งเสริมความหลากหลาย+ Maj@5 จึงใช้ผู้สมัครทั้ง 5 คนโดยตรง ซึ่งขาดความหลากหลาย| อุณหภูมิ | 0.6 | 1.0 |
|---|---|---|
| ลำแสงระดับขั้น (1,5) | 62.32 | 62.76 |
| ลำแสงระดับขั้น (2,5) | 64.66 | 65.60 |
| ลำแสงระดับขั้น (3,5) | 65.74 | 66.28 |
| ลำแสงระดับขั้น (5,5) | 65.98 | 66.38 |
สำหรับการค้นหาลำแสงระดับขั้น การตั้งค่า temperature=1.0 อาจให้ผลลัพธ์ที่ดีขึ้นเล็กน้อย
requirements.txt pip install -r requirements.txt
หรือเพียงทำตาม cmds
> git clone https://github.com/MARIO-Math-Reasoning/Super_MARIO.git
> git clone https://github.com/MARIO-Math-Reasoning/MARIO_EVAL.git
> git clone https://github.com/MARIO-Math-Reasoning/vllm.git
> cd Super_MARIO && pip install -r requirements.txt && cd ..
> cd MARIO_EVAL/latex2sympy && pip install . && cd ..
> pip install -e .
> cd ../vllm
> pip install -e . scripts/save_value_head.py เพื่อเพิ่ม value head ให้กับ LLM คุณสามารถเรียกใช้ cmds สองตัวต่อไปนี้ได้ อาจมีความแตกต่างเล็กน้อยของความแม่นยำระหว่างทั้งสอง ในเครื่องของเรา อันแรกได้ 53.4% และอันที่สองได้ 53.62%
python react_batch_demo.py
--custom_cfg configs/react_sft.yaml
--qaf ../MARIO_EVAL/data/math_testset_annotation.json
หรือ
# use step_beam (1, 1) without value func
python solver_demo.py
--custom_cfg configs/sbs_greedy.yaml
--qaf ../MARIO_EVAL/data/math_testset_annotation.json
ในเครื่องของเรา บนชุดทดสอบ MATH cmd ต่อไปนี้ที่มีการกำหนดค่า B1=1, B2=5 สามารถบรรลุ ~62% และอันที่มีการกำหนดค่า B1=3, B2=5 สามารถเข้าถึงได้ ~65%
python solver_demo.py
--custom_cfg configs/sbs_sft.yaml
--qaf ../MARIO_EVAL/data/math_testset_annotation.json
คำนวณความแม่นยำ
python eval_output_jsonl.py
--res_file <the saved tree jsonl file by solver_demo.py>
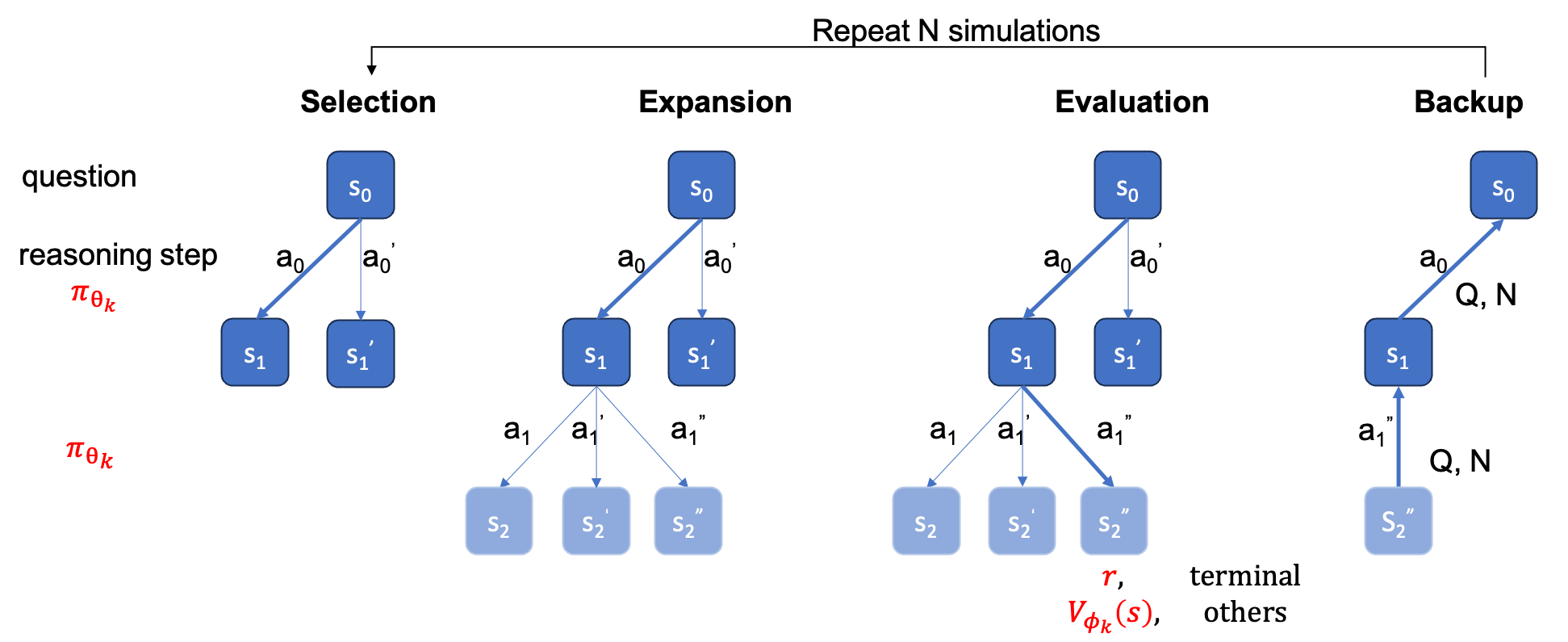
ต้องระบุ ground_truth (คำตอบสุดท้าย ไม่ใช่กระบวนการแก้ปัญหา) ในไฟล์ qaf json หรือ jsonl (รูปแบบตัวอย่างสามารถอ้างถึง ../MARIO_EVAL/data/math_testset_annotation.json )
รอบที่ 1
# Checkpoint Initialization is required by adding value head
python solver_demo.py
--custom_cfg configs/mcts_round1.yaml
--qaf /path/to/training/data
รอบ > 1 หลัง SFT
python solver_demo.py
--custom_cfg configs/mcts_sft_round.yaml
--qaf /path/to/training/data
question เดียวที่จะใช้ในการสร้างโซลูชัน แต่จะใช้ ground_truth ในการคำนวณความแม่นยำ
python solver_demo.py
--custom_cfg configs/mcts_sft.yaml
--qaf ../MARIO_EVAL/data/math_testset_annotation.json
แตกต่างจากการค้นหาลำแสงระดับขั้น คุณต้องสร้างแผนผังที่สมบูรณ์ก่อน จากนั้นคุณควรรัน MCTS ออฟไลน์ จากนั้นจึงคำนวณความแม่นยำ
python offline_inference.py
--custom_cfg configs/offline_inference.yaml
--tree_jsonl <the saved tree jsonl file by solver_demo.py>
หมายเหตุ: สคริปต์การประเมินผลนี้สามารถรันด้วยแผนผังที่บันทึกไว้โดยการค้นหาลำแสงระดับขั้นตอน และความถูกต้องควรยังคงเหมือนเดิม
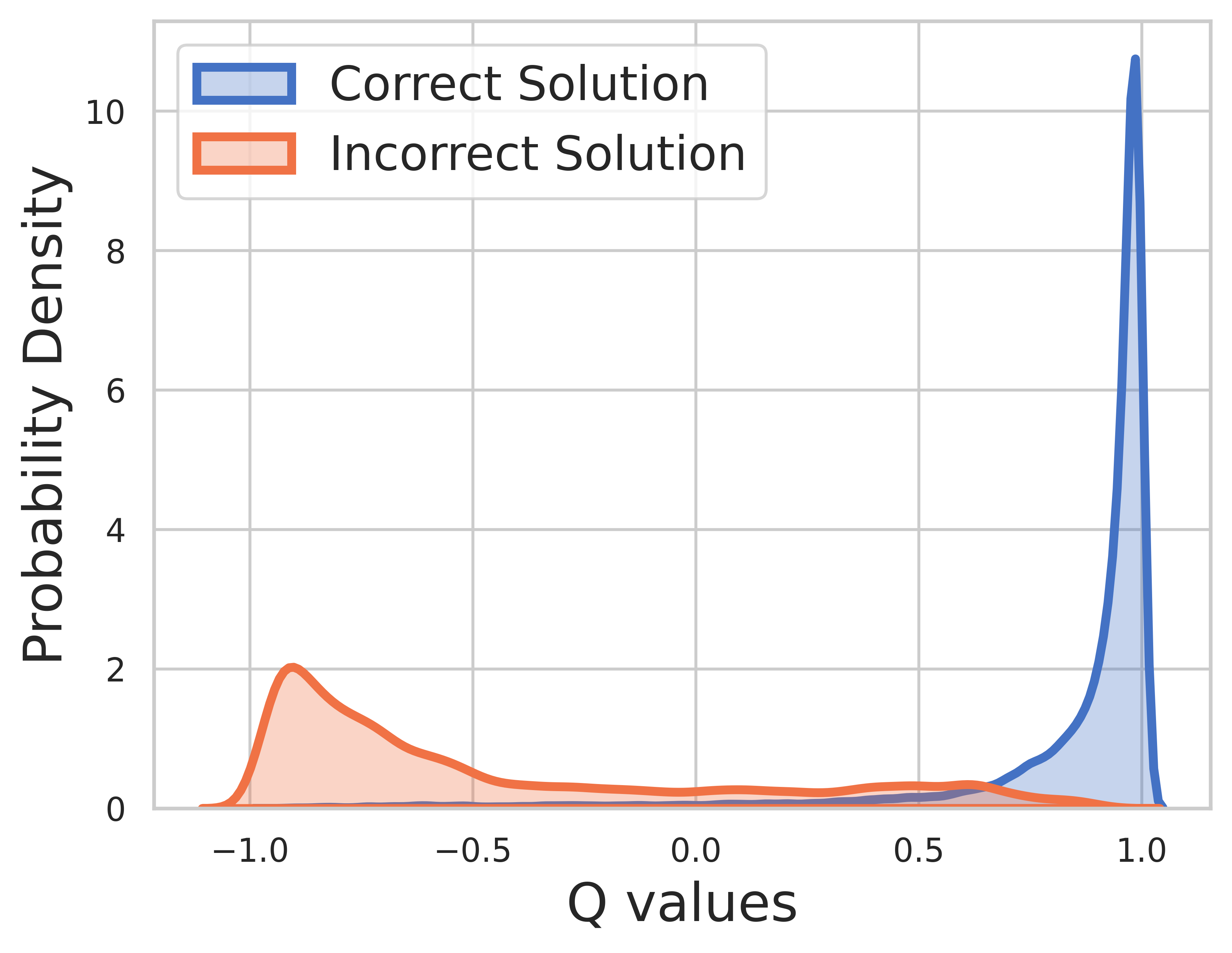
เนื่องจากความจริงภาคพื้นดินเป็นที่รู้จักสำหรับข้อมูลการฝึกอบรม คุณค่าของขั้นตอนสุดท้ายคือรางวัล และค่า Q สามารถมาบรรจบกันได้เป็นอย่างดี
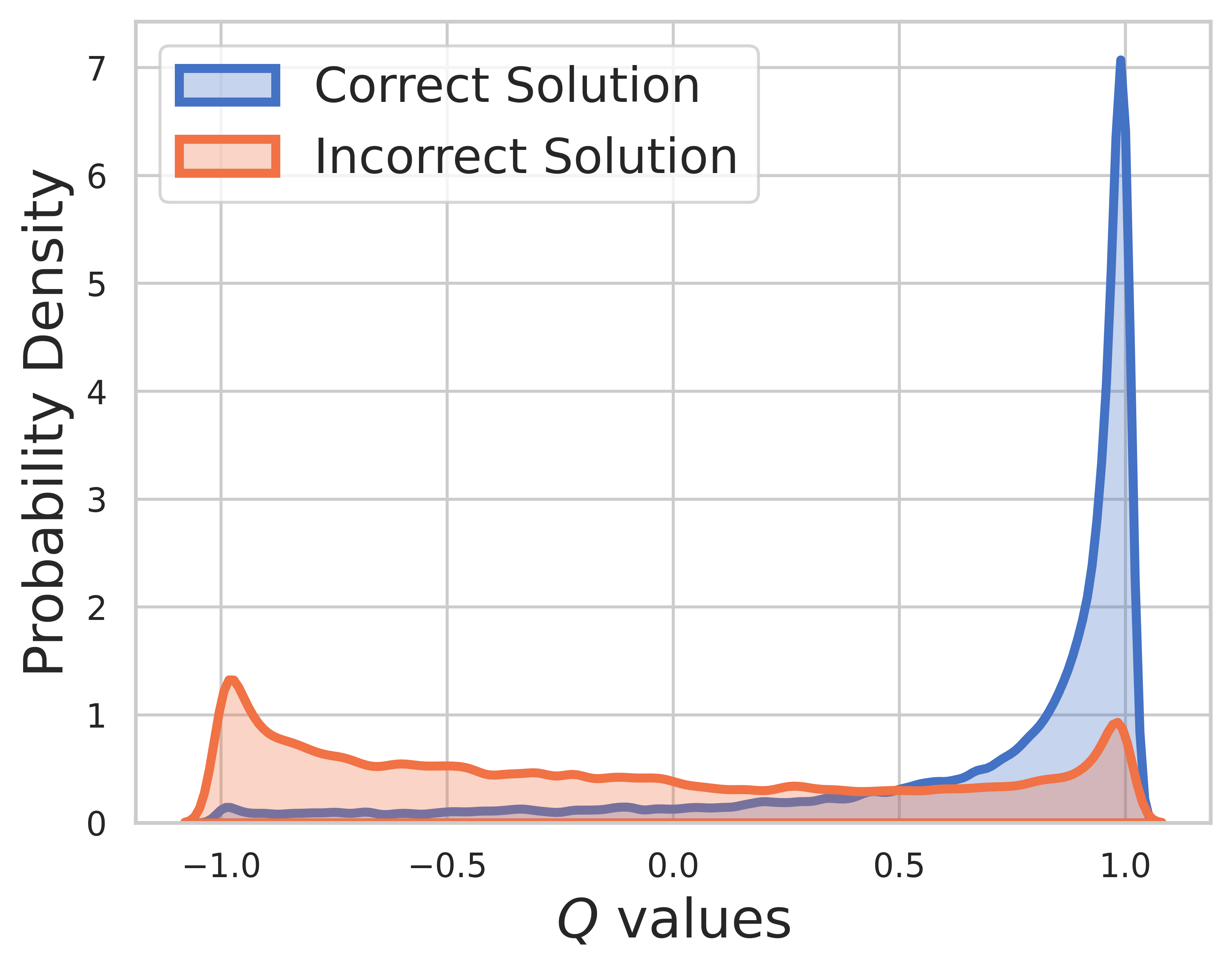
ในชุดทดสอบ ไม่ทราบความจริงภาคพื้นดิน ดังนั้นการแจกแจงค่า Q จึงมีทั้งขั้นตอนกลางและขั้นตอนสุดท้าย จากรูปนี้เราจะพบว่า
SVPO โดย MCTS
@misc{chen2024steplevelvaluepreferenceoptimization,
title={Step-level Value Preference Optimization for Mathematical Reasoning},
author={Guoxin Chen and Minpeng Liao and Chengxi Li and Kai Fan},
year={2024},
eprint={2406.10858},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2406.10858},
}
เวอร์ชัน MCTS
@misc{chen2024alphamathzeroprocesssupervision,
title={AlphaMath Almost Zero: process Supervision without process},
author={Guoxin Chen and Minpeng Liao and Chengxi Li and Kai Fan},
year={2024},
eprint={2405.03553},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2405.03553},
}
ชุดเครื่องมือประเมินผล
@misc{zhang2024marioevalevaluatemath,
title={MARIO Eval: Evaluate Your Math LLM with your Math LLM--A mathematical dataset evaluation toolkit},
author={Boning Zhang and Chengxi Li and Kai Fan},
year={2024},
eprint={2404.13925},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2404.13925},
}
เวอร์ชัน OVM (แบบจำลองมูลค่าผลลัพธ์)
@misc{liao2024mariomathreasoningcode,
title={MARIO: MAth Reasoning with code Interpreter Output -- A Reproducible Pipeline},
author={Minpeng Liao and Wei Luo and Chengxi Li and Jing Wu and Kai Fan},
year={2024},
eprint={2401.08190},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2401.08190},
}


