
ซวน จู 1* , อี้หมิง เกา 1* , จ้าวหยาง จาง 1*# , ซีหยาง หยวน 1 , ซินเทา หวาง 1 , อ้ายหลิง เจิง, หยูซีออง, เฉียง ซู, หยิงซาน 1
1 ARC Lab, Tencent PCG 2 มหาวิทยาลัยจีนแห่งฮ่องกง * ผลงานที่เท่าเทียมกัน # หัวหน้าโครงการ
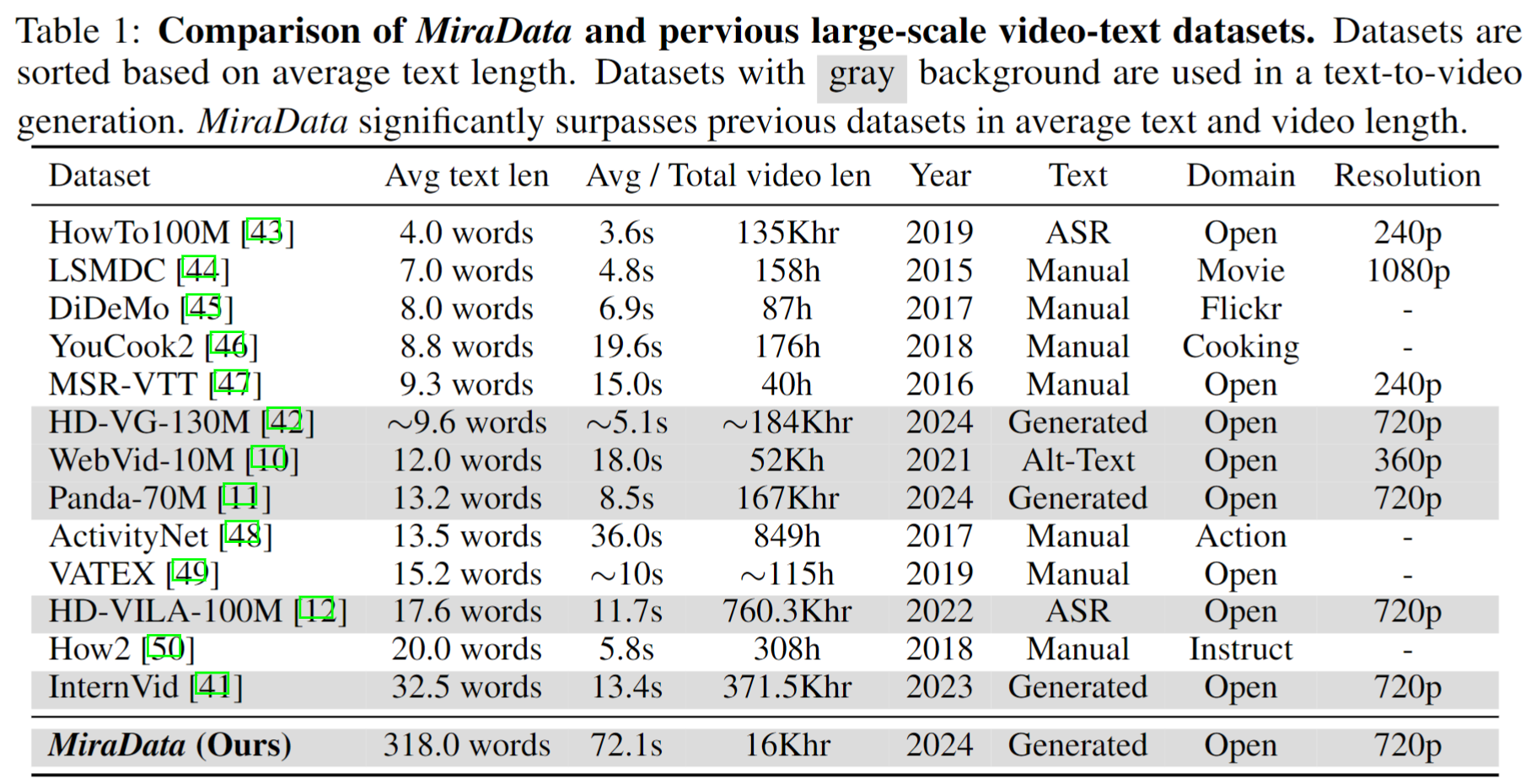
ชุดข้อมูลวิดีโอมีบทบาทสำคัญในการสร้างวิดีโอ เช่น Sora อย่างไรก็ตาม ชุดข้อมูลข้อความ-วิดีโอที่มีอยู่มักจะขาดเมื่อต้อง จัดการกับลำดับวิดีโอขนาดยาว และ การบันทึกการเปลี่ยนภาพ เพื่อแก้ไขข้อจำกัดเหล่านี้ เราขอแนะนำ MiraData ซึ่งเป็นชุดข้อมูลวิดีโอที่ออกแบบมาโดยเฉพาะสำหรับงานสร้างวิดีโอที่มีระยะเวลายาวนาน นอกจากนี้ เพื่อประเมินความสอดคล้องชั่วคราวและความเข้มข้นของการเคลื่อนไหวในการสร้างวิดีโอได้ดีขึ้น เราขอแนะนำ MiraBench ซึ่งปรับปรุงเกณฑ์มาตรฐานที่มีอยู่โดยการเพิ่มความสม่ำเสมอของ 3D และตัวชี้วัดความแข็งแกร่งของการเคลื่อนไหวตามการติดตาม คุณสามารถหารายละเอียดเพิ่มเติมได้ในเอกสารวิจัยของเรา
เราเปิดตัว MiraData สี่เวอร์ชัน ซึ่งมีข้อมูล 330K, 93K, 42K, 9K
ไฟล์เมตาสำหรับ MiraData เวอร์ชันนี้มีอยู่ในชุดข้อมูล Google Drive และ HuggingFace นอกจากนี้ เพื่อความเข้าใจที่ดีขึ้นและรวดเร็วยิ่งขึ้นเกี่ยวกับองค์ประกอบเมตาไฟล์ของเรา เราจะสุ่มตัวอย่างชุดคลิปวิดีโอ 100 คลิป ซึ่งสามารถเข้าถึงได้ที่นี่ ไฟล์เมตาประกอบด้วยข้อมูลดัชนีต่อไปนี้:
{download_id}.{clip_id}หากต้องการดาวน์โหลดวิดีโอและแยกออกเป็นคลิป ให้เริ่มด้วยการดาวน์โหลดไฟล์เมตาจาก Google Drive หรือชุดข้อมูล HuggingFace เมื่อคุณมีไฟล์เมตาแล้ว คุณสามารถใช้สคริปต์ต่อไปนี้เพื่อดาวน์โหลดตัวอย่างวิดีโอ:
python download_data.py --meta_csv {meta file} --download_start_id {the start of download id} --download_end_id {the end of download id} --raw_video_save_dir {the path of saving raw videos} --clip_video_save_dir {the path of saving cutted video}
เราจะลบตัวอย่างวิดีโอออกจากชุดข้อมูล / Github / หน้าเว็บโครงการของเราตราบเท่าที่คุณต้องการ โปรดติดต่อเราเพื่อขอคำร้องขอ
ในการรวบรวมข้อมูล MiraData ก่อนอื่นเราจะเลือกช่อง YouTube ในสถานการณ์ที่แตกต่างกันด้วยตนเอง และรวมวิดีโอจาก HD-VILA-100M, Videovo, Pixabay และ Pexels จากนั้น วิดีโอทั้งหมดในช่องที่เกี่ยวข้องจะถูกดาวน์โหลดและแยกโดยใช้ PySceneDetect จากนั้นเราใช้โมเดลหลายแบบเพื่อต่อคลิปสั้นเข้าด้วยกันและกรองวิดีโอคุณภาพต่ำออก ต่อไปนี้เราเลือกคลิปวิดีโอที่มีระยะเวลายาว สุดท้ายเราบรรยายคลิปวิดีโอทั้งหมดโดยใช้ GPT-4V

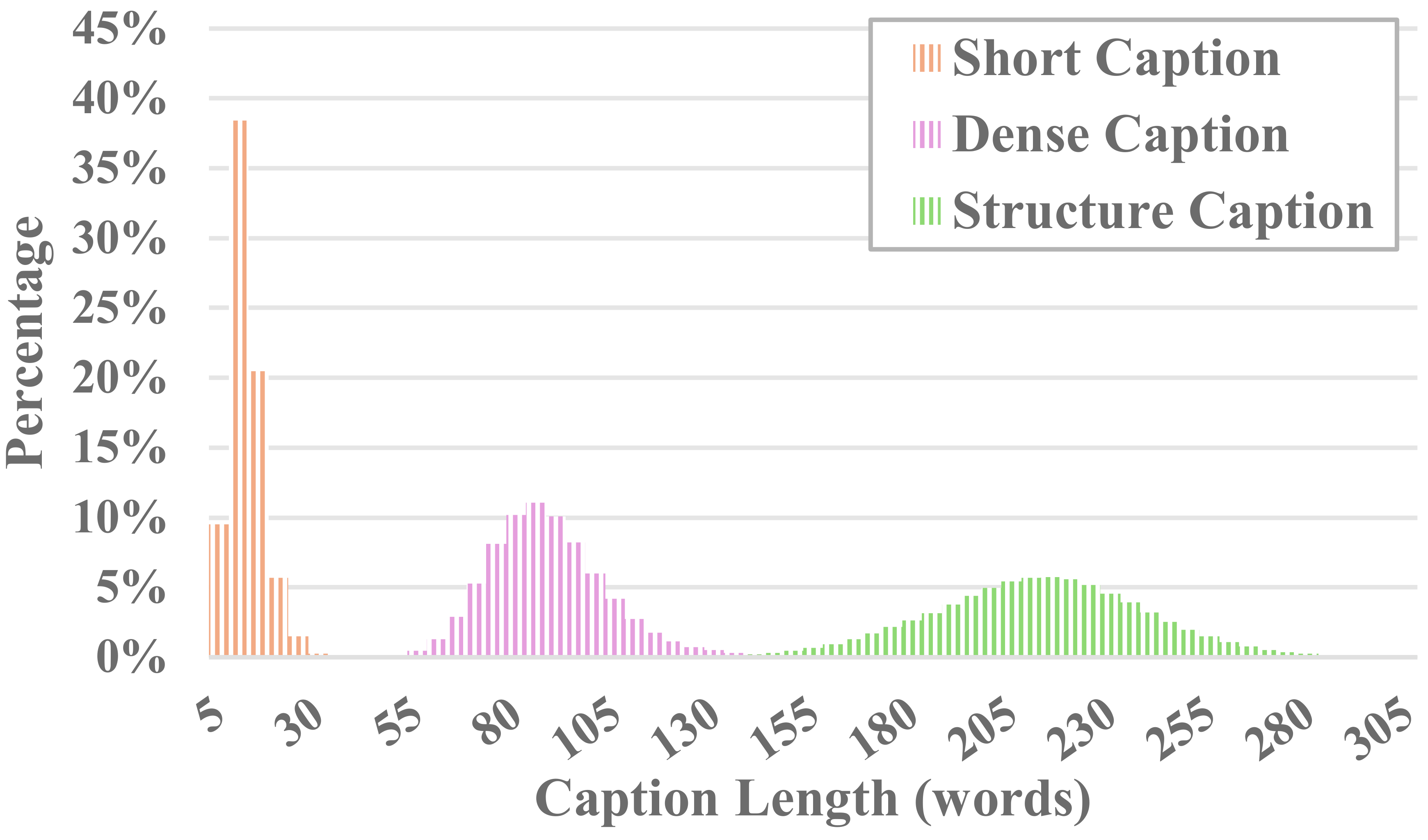
วิดีโอแต่ละรายการใน MiraData จะมาพร้อมกับคำบรรยายที่มีโครงสร้าง คำอธิบายภาพเหล่านี้ให้คำอธิบายโดยละเอียดจากมุมมองที่หลากหลาย ซึ่งช่วยเพิ่มความสมบูรณ์ของชุดข้อมูล
คำบรรยายหกประเภท
เราทดสอบวิธี Visual LLM แบบโอเพ่นซอร์สที่มีอยู่และ GPT-4V และพบว่าคำบรรยายของ GPT-4V แสดงความแม่นยำและความเชื่อมโยงที่ดีขึ้นในการทำความเข้าใจความหมายในแง่ของลำดับเวลา
เพื่อสร้างสมดุลระหว่างต้นทุนคำอธิบายประกอบและความถูกต้องของคำบรรยาย เราจะสุ่มตัวอย่าง 8 เฟรมสำหรับวิดีโอแต่ละรายการอย่างสม่ำเสมอ และจัดเรียงเป็นตารางขนาด 2x4 ของรูปภาพขนาดใหญ่รูปเดียว จากนั้น เราใช้โมเดลคำบรรยายของ Panda-70M เพื่ออธิบายประกอบวิดีโอแต่ละรายการด้วยคำบรรยายหนึ่งประโยค ซึ่งทำหน้าที่เป็นคำใบ้สำหรับเนื้อหาหลัก และป้อนลงในข้อความแจ้งที่ได้รับการปรับแต่งของเรา ด้วยการป้อนข้อความแจ้งที่ปรับแต่งอย่างละเอียดและรูปภาพขนาดใหญ่ 2x4 ให้กับ GPT-4V เราจึงสามารถแสดงคำบรรยายสำหรับหลายมิติได้อย่างมีประสิทธิภาพในการสนทนารอบเดียว เนื้อหาพร้อมท์เฉพาะเจาะจงสามารถพบได้ใน Caption_gpt4v.py และเรายินดีต้อนรับทุกท่านที่มีส่วนร่วมในข้อมูลข้อความและวิดีโอคุณภาพสูงยิ่งขึ้น -

เพื่อประเมินการสร้างวิดีโอที่มีขนาดยาว เราได้ออกแบบตัวชี้วัดการประเมิน 17 รายการใน MiraBench จาก 6 มุมมอง รวมถึงความสอดคล้องของเวลา ความแรงของการเคลื่อนไหวตามเวลา ความสม่ำเสมอของ 3D คุณภาพของภาพ การจัดตำแหน่งข้อความ-วิดีโอ และความสม่ำเสมอในการกระจาย ตัวชี้วัดเหล่านี้ครอบคลุมมาตรฐานการประเมินทั่วไปส่วนใหญ่ที่ใช้ในรุ่นการสร้างวิดีโอก่อนหน้าและการวัดประสิทธิภาพการแปลงข้อความเป็นวิดีโอ
ในการประเมินวิดีโอที่สร้างขึ้น โปรดตั้งค่าสภาพแวดล้อม Python ก่อนผ่าน:
pip install torch==1.12.1+cu116 torchvision==0.13.1+cu116 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu116
pip install -r requirements.txt
จากนั้น ดำเนินการประเมินผ่าน:
python calculate_score.py --meta_file data/evaluation_example/meta_generated.csv --frame_dir data/evaluation_example/frames_generated --gt_meta_file data/evaluation_example/meta_gt.csv --gt_frame_dir data/evaluation_example/frames_gt --output_folder data/evaluation_example/results --ckpt_path data/ckpt --device cuda
คุณสามารถทำตามตัวอย่างใน data/evaluation_example เพื่อประเมินวิดีโอที่คุณสร้างขึ้นเอง
โปรดดูใบอนุญาต
หากคุณพบว่าโครงการนี้มีประโยชน์สำหรับการวิจัยของคุณ โปรดอ้างอิงรายงานของเรา -
@misc{ju2024miradatalargescalevideodataset,
title={MiraData: A Large-Scale Video Dataset with Long Durations and Structured Captions},
author={Xuan Ju and Yiming Gao and Zhaoyang Zhang and Ziyang Yuan and Xintao Wang and Ailing Zeng and Yu Xiong and Qiang Xu and Ying Shan},
year={2024},
eprint={2407.06358},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2407.06358},
}
หากมีข้อสงสัยใดๆ โปรดส่งอีเมลไป [email protected]
MiraData อยู่ภายใต้ใบอนุญาต GPL-v3 และได้รับการสนับสนุนสำหรับการใช้งานเชิงพาณิชย์ หากคุณต้องการใบอนุญาตเชิงพาณิชย์สำหรับ MiraData โปรดติดต่อเรา


