storm
v1.0.0 & EMNLP 2024 Paper Accepted!
- ตัวอย่างงานวิจัย | สตอร์ม กระดาษ | กระดาษร่วมพายุ | เว็บไซต์ |
ข่าวล่าสุด
[2024/09] ขณะนี้โค้ดเบส Co-STORM เปิดตัวแล้วและรวมเข้ากับแพ็คเกจ knowledge-storm Python v1.0.0 รัน pip install knowledge-storm --upgrade เพื่อตรวจสอบ
[2024/09] เราขอแนะนำ STORM การทำงานร่วมกัน (Co-STORM) เพื่อสนับสนุนการดูแลจัดการความรู้การทำงานร่วมกันระหว่างมนุษย์และ AI! Co-STORM Paper ได้รับการยอมรับให้เข้าร่วมการประชุมหลัก EMNLP 2024
[2024/07] ตอนนี้คุณสามารถติดตั้งแพ็คเกจของเราด้วย pip install knowledge-storm !
[2024/07] เราเพิ่ม VectorRM เพื่อรองรับการลงดินบนเอกสารที่ผู้ใช้ให้มา เสริมการรองรับเครื่องมือค้นหาที่มีอยู่ ( YouRM , BingSearch ) (ดู #58)
[2024/07] เราเปิดตัวไฟสาธิตสำหรับนักพัฒนาซึ่งเป็นอินเทอร์เฟซผู้ใช้ขั้นต่ำที่สร้างด้วยเฟรมเวิร์ก streamlit ใน Python ซึ่งมีประโยชน์สำหรับการพัฒนาในพื้นที่และการโฮสต์การสาธิต (ชำระเงิน #54)
[2024/06] เราจะนำเสนอ STORM ในงาน NAACL 2024! พบกับเราได้ที่ Poster Session 2 ในวันที่ 17 มิถุนายน หรือตรวจสอบเอกสารการนำเสนอของเรา
[2024/05] เราเพิ่มการสนับสนุน Bing Search ใน rm.py ทดสอบ STORM ด้วย GPT-4o - ตอนนี้เรากำหนดค่าส่วนการสร้างบทความในการสาธิตของเราโดยใช้โมเดล GPT-4o
[2024/04] เราเปิดตัวโค้ดเบส STORM เวอร์ชันที่ได้รับการปรับปรุงใหม่! เรากำหนดอินเทอร์เฟซสำหรับไปป์ไลน์ STORM และปรับใช้ STORM-wiki อีกครั้ง (ตรวจสอบ src/storm_wiki ) เพื่อสาธิตวิธีการสร้างอินสแตนซ์ของไปป์ไลน์ เรามี API เพื่อรองรับการปรับแต่งโมเดลภาษาต่างๆ และการผสานรวมการดึงข้อมูล/การค้นหา
แม้ว่าระบบจะไม่สามารถผลิตบทความที่พร้อมตีพิมพ์ซึ่งมักต้องมีการแก้ไขจำนวนมาก แต่บรรณาธิการวิกิพีเดียที่มีประสบการณ์พบว่ามีประโยชน์ในขั้นตอนก่อนการเขียน
ผู้คนมากกว่า 70,000 คนได้ลองใช้ตัวอย่างการวิจัยสดของเรา ลองใช้งานเพื่อดูว่า STORM สามารถช่วยการเดินทางสำรวจความรู้ของคุณได้อย่างไร และโปรดให้ข้อเสนอแนะเพื่อช่วยเราปรับปรุงระบบ!
STORM แบ่งการสร้างบทความขนาดยาวพร้อมการอ้างอิงออกเป็นสองขั้นตอน:
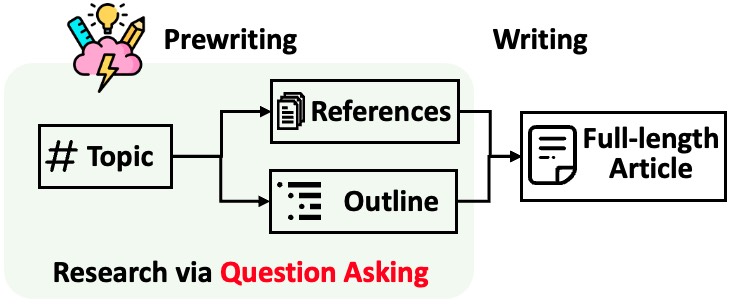
STORM ระบุแกนหลักของการทำให้กระบวนการวิจัยเป็นอัตโนมัติโดยจะมีคำถามดีๆ มาให้ถามโดยอัตโนมัติ การแจ้งให้โมเดลภาษาถามคำถามโดยตรงนั้นทำงานได้ไม่ดีนัก เพื่อปรับปรุงความลึกและความกว้างของคำถาม STORM จึงใช้สองกลยุทธ์:
Co-STORM เสนอ โปรโตคอลวาทกรรมการทำงานร่วมกัน ซึ่งใช้นโยบายการจัดการการเลี้ยวเพื่อสนับสนุนการทำงานร่วมกันที่ราบรื่นระหว่างกัน
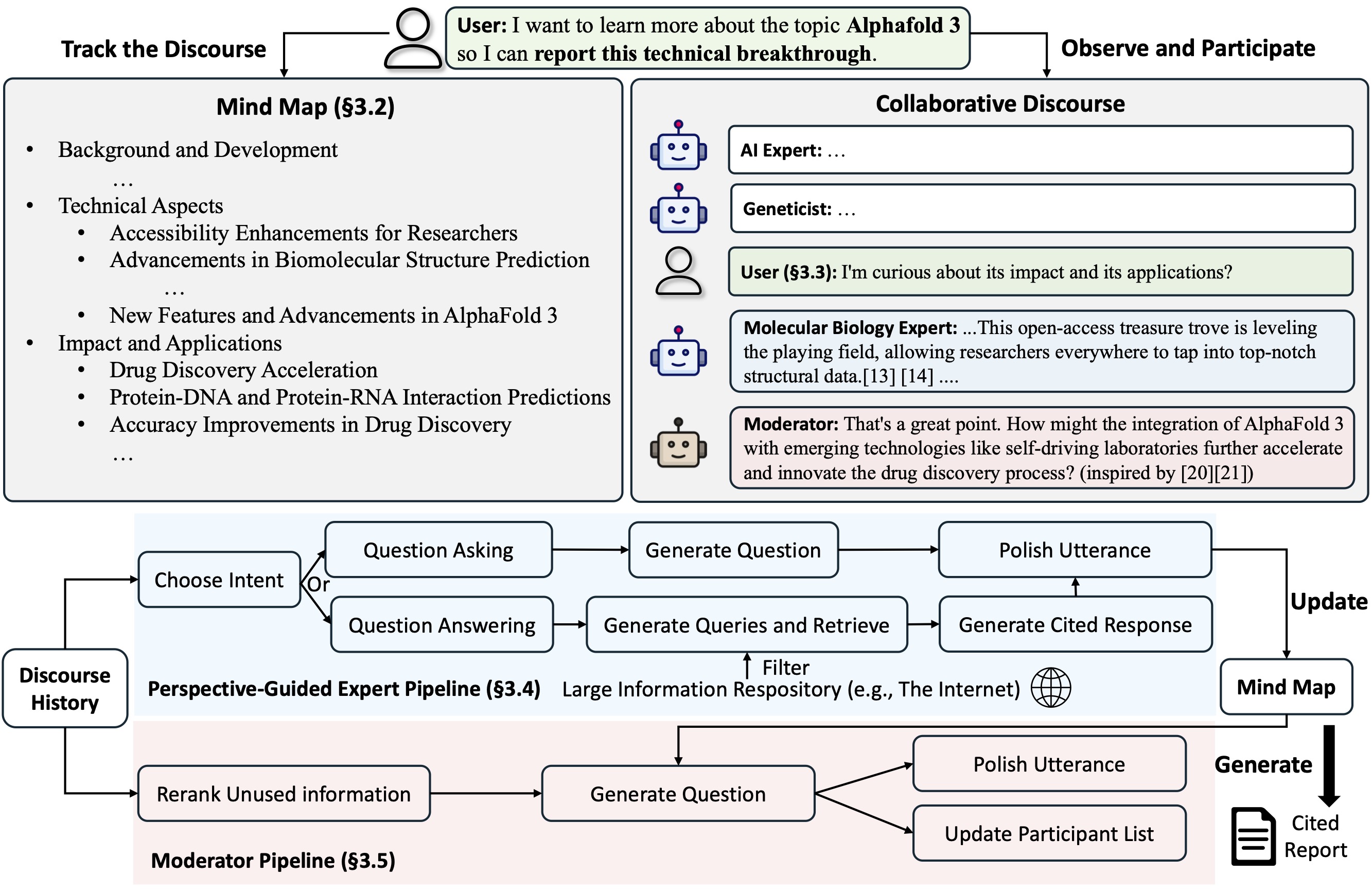
Co-STORM ยังรักษา แผนที่ความคิด ที่ได้รับการปรับปรุงแบบไดนามิก ซึ่งจัดระเบียบข้อมูลที่รวบรวมไว้เป็นโครงสร้างแนวคิดแบบลำดับชั้น โดยมีเป้าหมายเพื่อ สร้างพื้นที่แนวคิดที่ใช้ร่วมกันระหว่างผู้ใช้ที่เป็นมนุษย์และระบบ แผนที่ความคิดได้รับการพิสูจน์แล้วว่าช่วยลดภาระทางจิตเมื่อวาทกรรมมีความยาวและเจาะลึก
ทั้ง STORM และ Co-STORM ได้รับการติดตั้งในลักษณะโมดูลาร์สูงโดยใช้ dspy
หากต้องการติดตั้งไลบรารีพายุความรู้ ให้ใช้ pip install knowledge-storm
คุณยังสามารถติดตั้งซอร์สโค้ดซึ่งช่วยให้คุณสามารถปรับเปลี่ยนพฤติกรรมของเอ็นจิ้น STORM ได้โดยตรง
โคลนที่เก็บ git
git clone https://github.com/stanford-oval/storm.git
cd stormติดตั้งแพ็คเกจที่จำเป็น
conda create -n storm python=3.11
conda activate storm
pip install -r requirements.txtปัจจุบันการสนับสนุนแพ็คเกจของเรา:
OpenAIModel , AzureOpenAIModel , ClaudeModel , VLLMClient , TGIClient , TogetherClient , OllamaClient , GoogleModel , DeepSeekModel , GroqModel เป็นส่วนประกอบของโมเดลภาษาYouRM , BingSearch , VectorRM , SerperRM , BraveRM , SearXNG , DuckDuckGoSearchRM , TavilySearchRM , GoogleSearch และ AzureAISearch เป็นส่วนประกอบของโมดูลการดึงข้อมูล- ขอชื่นชมการประชาสัมพันธ์สำหรับการบูรณาการโมเดลภาษาเพิ่มเติมเข้ากับ Knowledge_storm/lm.py และเครื่องมือค้นหา/ตัวดึงข้อมูลเข้าไปใน Knowledge_storm/rm.py!
ทั้ง STORM และ Co-STORM ทำงานในเลเยอร์การดูแลจัดการข้อมูล คุณต้องตั้งค่าโมดูลการดึงข้อมูลและโมดูลโมเดลภาษาเพื่อสร้างคลาส Runner ตามลำดับ
กลไกการจัดการความรู้ STORM ถูกกำหนดให้เป็นคลาส Python STORMWikiRunner แบบธรรมดา นี่คือตัวอย่างการใช้เครื่องมือค้นหา You.com และโมเดล OpenAI
import os
from knowledge_storm import STORMWikiRunnerArguments , STORMWikiRunner , STORMWikiLMConfigs
from knowledge_storm . lm import OpenAIModel
from knowledge_storm . rm import YouRM
lm_configs = STORMWikiLMConfigs ()
openai_kwargs = {
'api_key' : os . getenv ( "OPENAI_API_KEY" ),
'temperature' : 1.0 ,
'top_p' : 0.9 ,
}
# STORM is a LM system so different components can be powered by different models to reach a good balance between cost and quality.
# For a good practice, choose a cheaper/faster model for `conv_simulator_lm` which is used to split queries, synthesize answers in the conversation.
# Choose a more powerful model for `article_gen_lm` to generate verifiable text with citations.
gpt_35 = OpenAIModel ( model = 'gpt-3.5-turbo' , max_tokens = 500 , ** openai_kwargs )
gpt_4 = OpenAIModel ( model = 'gpt-4o' , max_tokens = 3000 , ** openai_kwargs )
lm_configs . set_conv_simulator_lm ( gpt_35 )
lm_configs . set_question_asker_lm ( gpt_35 )
lm_configs . set_outline_gen_lm ( gpt_4 )
lm_configs . set_article_gen_lm ( gpt_4 )
lm_configs . set_article_polish_lm ( gpt_4 )
# Check out the STORMWikiRunnerArguments class for more configurations.
engine_args = STORMWikiRunnerArguments (...)
rm = YouRM ( ydc_api_key = os . getenv ( 'YDC_API_KEY' ), k = engine_args . search_top_k )
runner = STORMWikiRunner ( engine_args , lm_configs , rm ) อินสแตนซ์ STORMWikiRunner สามารถเกิดขึ้นได้ด้วยวิธี run แบบง่าย:
topic = input ( 'Topic: ' )
runner . run (
topic = topic ,
do_research = True ,
do_generate_outline = True ,
do_generate_article = True ,
do_polish_article = True ,
)
runner . post_run ()
runner . summary ()do_research : หากเป็นจริง ให้จำลองการสนทนาด้วยมุมมองที่แตกต่างกันเพื่อรวบรวมข้อมูลเกี่ยวกับหัวข้อนั้น มิฉะนั้นให้โหลดผลลัพธ์do_generate_outline : หากเป็นจริง ให้สร้างโครงร่างสำหรับหัวข้อ มิฉะนั้นให้โหลดผลลัพธ์do_generate_article : หากเป็นจริง ให้สร้างบทความสำหรับหัวข้อตามโครงร่างและข้อมูลที่รวบรวม มิฉะนั้นให้โหลดผลลัพธ์do_polish_article : หากเป็นจริง ให้ขัดเกลาบทความโดยเพิ่มส่วนสรุปและ (เป็นทางเลือก) ลบเนื้อหาที่ซ้ำกัน มิฉะนั้นให้โหลดผลลัพธ์ กลไกการจัดการความรู้ Co-STORM ถูกกำหนดให้เป็นคลาส Python CoStormRunner แบบธรรมดา นี่คือตัวอย่างการใช้เครื่องมือค้นหา Bing และโมเดล OpenAI
from knowledge_storm . collaborative_storm . engine import CollaborativeStormLMConfigs , RunnerArgument , CoStormRunner
from knowledge_storm . lm import OpenAIModel
from knowledge_storm . logging_wrapper import LoggingWrapper
from knowledge_storm . rm import BingSearch
# Co-STORM adopts the same multi LM system paradigm as STORM
lm_config : CollaborativeStormLMConfigs = CollaborativeStormLMConfigs ()
openai_kwargs = {
"api_key" : os . getenv ( "OPENAI_API_KEY" ),
"api_provider" : "openai" ,
"temperature" : 1.0 ,
"top_p" : 0.9 ,
"api_base" : None ,
}
question_answering_lm = OpenAIModel ( model = gpt_4o_model_name , max_tokens = 1000 , ** openai_kwargs )
discourse_manage_lm = OpenAIModel ( model = gpt_4o_model_name , max_tokens = 500 , ** openai_kwargs )
utterance_polishing_lm = OpenAIModel ( model = gpt_4o_model_name , max_tokens = 2000 , ** openai_kwargs )
warmstart_outline_gen_lm = OpenAIModel ( model = gpt_4o_model_name , max_tokens = 500 , ** openai_kwargs )
question_asking_lm = OpenAIModel ( model = gpt_4o_model_name , max_tokens = 300 , ** openai_kwargs )
knowledge_base_lm = OpenAIModel ( model = gpt_4o_model_name , max_tokens = 1000 , ** openai_kwargs )
lm_config . set_question_answering_lm ( question_answering_lm )
lm_config . set_discourse_manage_lm ( discourse_manage_lm )
lm_config . set_utterance_polishing_lm ( utterance_polishing_lm )
lm_config . set_warmstart_outline_gen_lm ( warmstart_outline_gen_lm )
lm_config . set_question_asking_lm ( question_asking_lm )
lm_config . set_knowledge_base_lm ( knowledge_base_lm )
# Check out the Co-STORM's RunnerArguments class for more configurations.
topic = input ( 'Topic: ' )
runner_argument = RunnerArgument ( topic = topic , ...)
logging_wrapper = LoggingWrapper ( lm_config )
bing_rm = BingSearch ( bing_search_api_key = os . environ . get ( "BING_SEARCH_API_KEY" ),
k = runner_argument . retrieve_top_k )
costorm_runner = CoStormRunner ( lm_config = lm_config ,
runner_argument = runner_argument ,
logging_wrapper = logging_wrapper ,
rm = bing_rm ) อินสแตนซ์ CoStormRunner สามารถปรากฏได้โดยใช้เมธอด warmstart() และ step(...)
# Warm start the system to build shared conceptual space between Co-STORM and users
costorm_runner . warm_start ()
# Step through the collaborative discourse
# Run either of the code snippets below in any order, as many times as you'd like
# To observe the conversation:
conv_turn = costorm_runner . step ()
# To inject your utterance to actively steer the conversation:
costorm_runner . step ( user_utterance = "YOUR UTTERANCE HERE" )
# Generate report based on the collaborative discourse
costorm_runner . knowledge_base . reorganize ()
article = costorm_runner . generate_report ()
print ( article )เราจัดเตรียมสคริปต์ไว้ในโฟลเดอร์ตัวอย่างของเราเพื่อเริ่มต้นใช้งาน STORM และ Co-STORM อย่างรวดเร็วด้วยการกำหนดค่าที่แตกต่างกัน
เราขอแนะนำให้ใช้ secrets.toml เพื่อตั้งค่าคีย์ API สร้างไฟล์ secrets.toml ใต้ไดเร็กทอรีรากและเพิ่มเนื้อหาต่อไปนี้:
# Set up OpenAI API key.
OPENAI_API_KEY= " your_openai_api_key "
# If you are using the API service provided by OpenAI, include the following line:
OPENAI_API_TYPE= " openai "
# If you are using the API service provided by Microsoft Azure, include the following lines:
OPENAI_API_TYPE= " azure "
AZURE_API_BASE= " your_azure_api_base_url "
AZURE_API_VERSION= " your_azure_api_version "
# Set up You.com search API key.
YDC_API_KEY= " your_youcom_api_key " วิธีรัน STORM ด้วยโมเดลตระกูล gpt ที่มีการกำหนดค่าเริ่มต้น:
รันคำสั่งต่อไปนี้
python examples/storm_examples/run_storm_wiki_gpt.py
--output-dir $OUTPUT_DIR
--retriever you
--do-research
--do-generate-outline
--do-generate-article
--do-polish-articleหากต้องการรัน STORM โดยใช้โมเดลภาษาที่คุณชื่นชอบหรือใช้งานบนคลังข้อมูลของคุณเอง: ลองดูที่ examples/storm_examples/README.md
หากต้องการรัน Co-STORM ด้วยโมเดลตระกูล gpt ที่มีการกำหนดค่าเริ่มต้น
BING_SEARCH_API_KEY="xxx" และ ENCODER_API_TYPE="xxx" ไปที่ secrets.tomlpython examples/costorm_examples/run_costorm_gpt.py
--output-dir $OUTPUT_DIR
--retriever bingหากคุณได้ติดตั้งซอร์สโค้ดแล้ว คุณสามารถปรับแต่ง STORM ตามกรณีการใช้งานของคุณเองได้ เครื่องยนต์ STORM ประกอบด้วย 4 โมดูล:
อินเทอร์เฟซสำหรับแต่ละโมดูลถูกกำหนดไว้ใน knowledge_storm/interface.py ในขณะที่การใช้งานจะถูกสร้างอินสแตนซ์ใน knowledge_storm/storm_wiki/modules/* โมดูลเหล่านี้สามารถปรับแต่งได้ตามความต้องการเฉพาะของคุณ (เช่น การสร้างส่วนต่างๆ ในรูปแบบสัญลักษณ์แสดงหัวข้อย่อย แทนที่จะเป็นย่อหน้าเต็ม)
หากคุณได้ติดตั้งซอร์สโค้ดแล้ว คุณสามารถปรับแต่ง Co-STORM ตามกรณีการใช้งานของคุณเองได้
knowledge_storm/interface.py ในขณะที่การใช้งานจะถูกสร้างอินสแตนซ์ใน knowledge_storm/collaborative_storm/modules/co_storm_agents.py นโยบายเอเจนต์ LLM ต่างๆ สามารถปรับแต่งได้DiscourseManager ใน knowledge_storm/collaborative_storm/engine.py สามารถปรับแต่งและปรับปรุงเพิ่มเติมได้ เพื่ออำนวยความสะดวกในการศึกษาการรวบรวมความรู้อัตโนมัติและการค้นหาข้อมูลที่ซับซ้อน โครงการของเราจึงเผยแพร่ชุดข้อมูลต่อไปนี้:
ชุดข้อมูล FreshWiki คือชุดบทความ Wikipedia คุณภาพสูง 100 บทความโดยเน้นที่หน้าที่แก้ไขมากที่สุดตั้งแต่เดือนกุมภาพันธ์ 2022 ถึงกันยายน 2023 ดูส่วนที่ 2.1 ในรายงาน STORM สำหรับรายละเอียดเพิ่มเติม
คุณสามารถดาวน์โหลดชุดข้อมูลจาก Huggingface ได้โดยตรง เพื่อบรรเทาปัญหาการปนเปื้อนของข้อมูล เราจึงเก็บถาวรซอร์สโค้ดสำหรับไปป์ไลน์การสร้างข้อมูลที่สามารถทำซ้ำได้ในอนาคต
เพื่อศึกษาความสนใจของผู้ใช้ในข้อมูลที่ซับซ้อนในการหางานในป่า เราใช้ข้อมูลที่รวบรวมจากตัวอย่างการวิจัยเว็บเพื่อสร้างชุดข้อมูล WildSeek เราสุ่มตัวอย่างข้อมูลเพื่อให้มั่นใจถึงความหลากหลายของหัวข้อและคุณภาพของข้อมูล จุดข้อมูลแต่ละจุดเป็นคู่ที่ประกอบด้วยหัวข้อและเป้าหมายของผู้ใช้ในการดำเนินการค้นหาหัวข้ออย่างละเอียด สำหรับรายละเอียดเพิ่มเติม โปรดดูส่วนที่ 2.2 และภาคผนวก A ของรายงาน Co-STORM
ชุดข้อมูล WildSeek มีอยู่ที่นี่
สำหรับการทดลองกระดาษ STORM โปรดเปลี่ยนไปใช้สาขา NAACL-2024-code-backup ที่นี่
สำหรับการทดลองกระดาษ Co-STORM โปรดเปลี่ยนไปใช้สาขา EMNLP-2024-code-backup (ตัวยึดตำแหน่งสำหรับตอนนี้ จะมีการอัปเดตเร็วๆ นี้)
ทีมงานของเรากำลังทำงานอย่างแข็งขันในเรื่อง:
หากคุณมีคำถามหรือข้อเสนอแนะ โปรดอย่าลังเลที่จะเปิดประเด็นหรือดึงคำขอ เรายินดีรับการมีส่วนร่วมเพื่อปรับปรุงระบบและฐานโค้ด!
ผู้ติดต่อ: Yijia Shao และ Yucheng Jiang
เราขอขอบคุณ Wikipedia สำหรับเนื้อหาโอเพ่นซอร์สที่ยอดเยี่ยม ชุดข้อมูล FreshWiki มาจาก Wikipedia ซึ่งได้รับอนุญาตภายใต้ใบอนุญาต Creative Commons Attribution-ShareAlike (CC BY-SA)
เราขอขอบคุณ Michelle Lam มากที่ออกแบบโลโก้สำหรับโปรเจ็กต์นี้ และ Dekun Ma ที่เป็นผู้นำในการพัฒนา UI
โปรดอ้างอิงเอกสารของเราหากคุณใช้รหัสนี้หรือบางส่วนในงานของคุณ:
@misc { jiang2024unknownunknowns ,
title = { Into the Unknown Unknowns: Engaged Human Learning through Participation in Language Model Agent Conversations } ,
author = { Yucheng Jiang and Yijia Shao and Dekun Ma and Sina J. Semnani and Monica S. Lam } ,
year = { 2024 } ,
eprint = { 2408.15232 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL } ,
url = { https://arxiv.org/abs/2408.15232 } ,
}
@inproceedings { shao2024assisting ,
title = { {Assisting in Writing Wikipedia-like Articles From Scratch with Large Language Models} } ,
author = { Yijia Shao and Yucheng Jiang and Theodore A. Kanell and Peter Xu and Omar Khattab and Monica S. Lam } ,
year = { 2024 } ,
booktitle = { Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) }
}

