bulk
1.0.0
Bulk เป็นเครื่องมือสำหรับนักพัฒนาซอฟต์แวร์ที่รวดเร็วในการใช้ป้ายกำกับจำนวนมาก ด้วยชุดข้อมูลที่เตรียมไว้พร้อมการฝัง 2 มิติ ก็สามารถสร้างอินเทอร์เฟซที่ช่วยให้คุณสามารถเพิ่มคำอธิบายประกอบจำนวนมากได้อย่างรวดเร็ว แม้ว่าจะมีคำอธิบายประกอบที่ละเอียดน้อยกว่าก็ตาม
python -m pip install --upgrade pip
python -m pip install bulk
อนาคตของการเป็นกลุ่มคือการนำเสนอวิดเจ็ตที่สามารถช่วยคุณได้ในสมุดบันทึก ในขณะนี้ BaseTextExplorer เป็นวิดเจ็ตหลักที่รองรับ เมื่อพิจารณาข้อมูลที่ประมวลผลล่วงหน้าแล้ว คุณสามารถใช้ explorer เพื่อสำรวจ UMAP แบบ 2 มิติของการฝังข้อความได้
import pandas as pd
from umap import UMAP
from sklearn . pipeline import make_pipeline
# pip install "embetter[text]"
from embetter . text import SentenceEncoder
# Build a sentence encoder pipeline with UMAP at the end.
enc = SentenceEncoder ( 'all-MiniLM-L6-v2' )
umap = UMAP ()
text_emb_pipeline = make_pipeline (
enc , umap
)
# Load sentences
sentences = list ( pd . read_csv ( "tests/data/text.csv" )[ 'text' ])
# Calculate embeddings
X_tfm = text_emb_pipeline . fit_transform ( sentences )
# Write to disk. Note! Text column must be named "text"
df = pd . DataFrame ({ "text" : sentences })
df [ 'x' ] = X_tfm [:, 0 ]
df [ 'y' ] = X_tfm [:, 1 ]หากต้องการใช้วิดเจ็ต คุณเพียงแค่ต้องเรียกใช้สิ่งนี้:
from bulk . widgets import BaseTextExplorer
widget = BaseTextExplorer ( df )
widget . show ()ซึ่งจะช่วยให้เราสำรวจคลัสเตอร์ที่ปรากฏในข้อมูลของเราได้อย่างรวดเร็ว คุณสามารถกดเคอร์เซอร์ของเมาส์ค้างไว้เพื่อเข้าสู่โหมดการเลือก และเมื่อคุณเลือกรายการ คุณจะเห็นชุดย่อยแบบสุ่มปรากฏขึ้นทางด้านขวา คุณสามารถสุ่มตัวอย่างใหม่จากการเลือกของคุณโดยคลิกปุ่มตัวอย่างใหม่
เมื่อคุณทำการเลือก คุณจะเห็นวิดเจ็ตในการอัปเดตที่ถูกต้อง แต่คุณยังสามารถดึงข้อมูลจากแอตทริบิวต์ Python ได้อีกด้วย
widget . selected_idx
widget . selected_texts
widget . selected_dataframeความสามารถในการสำรวจคลัสเตอร์เหล่านี้เป็นเรื่องที่เรียบร้อย แต่รู้สึกว่าเราอาจสำรวจทุกสิ่งได้ง่ายขึ้นหากเรามีเครื่องมือเพิ่มเติม โดยเฉพาะอย่างยิ่ง เราต้องการมีตัวเข้ารหัสเพื่อที่เราจะได้ใช้การสืบค้นในพื้นที่ฝังตัวของเรา UI ด้านล่างจะช่วยให้เราสามารถสำรวจแบบโต้ตอบได้มากขึ้นโดยการอัปเดตสีด้วยข้อความแจ้ง
from embetter . text import SentenceEncoder
enc = SentenceEncoder ( 'all-MiniLM-L6-v2' )
# Pay attention here! The rows in df needs to align with the rows in X!
widget = BaseTextExplorer ( df , X = X , encoder = enc )
widget . show ()ด้วยเครื่องมืออย่าง ipywidget และ anywidget เราจึงสามารถเริ่มสร้างเครื่องมือบางอย่างเพื่อให้สมุดบันทึกเป็นที่ที่สามารถตอบสนองความต้องการข้อมูลของคุณได้ ด้วยวิดเจ็ตที่เหมาะสม คุณจะไม่สามารถจองโน้ตบุ๊ก Jupyter ได้เลย!
ความสนใจหลักของโครงการนี้คือการทำงานเกี่ยวกับเครื่องมือสำหรับคุณภาพข้อมูล ความสามารถในการเลือกจุดข้อมูลจำนวนมากทำให้รู้สึกเหมือนเป็นจุดเริ่มต้นที่ดี บางทีคุณอาจพบชุดย่อยที่น่าสนใจมาใส่คำอธิบายประกอบก่อน บางทีคุณอาจแปลกใจเมื่อเห็นกลุ่มย่อยสองกลุ่มที่แตกต่างกันซึ่งควรจะเป็นกลุ่มเดียว สิ่งดีๆ เหล่านี้เกิดขึ้นได้ในสมุดบันทึก!
Bulk ยังมาพร้อมกับเว็บแอปขนาดเล็กที่ใช้ Bokeh เพื่อให้อินเทอร์เฟซคำอธิบายประกอบตามการแสดง UMAP ของการฝัง มันมีอินเทอร์เฟซสำหรับข้อความ อินเทอร์เฟซนี้เป็นอินเทอร์เฟซ/คุณลักษณะดั้งเดิมของโปรเจ็กต์นี้
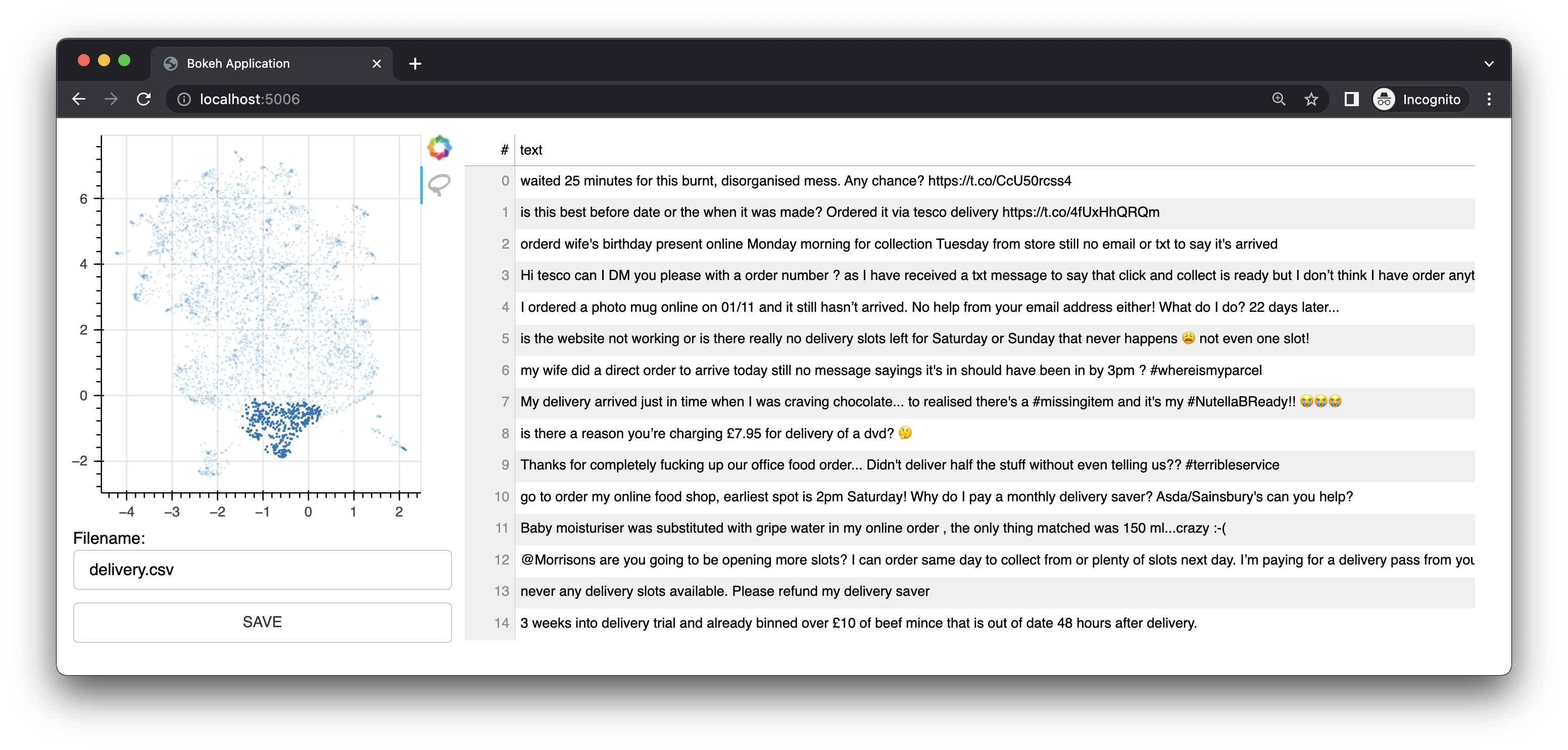
นอกจากนี้ยังมีส่วนต่อประสานรูปภาพ
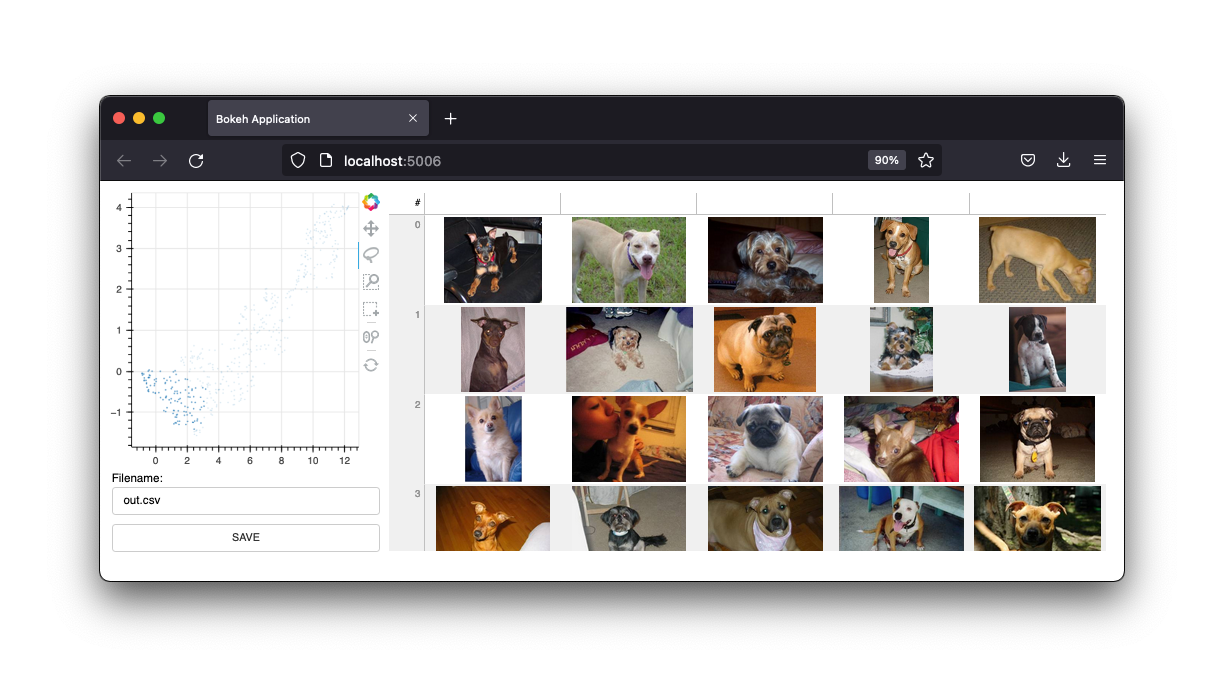
เราจะเก็บอินเทอร์เฟซเหล่านี้ไว้ แต่อนาคตของโครงการนี้จะเป็นวิดเจ็ตจากสมุดบันทึก Jupyter อย่างไรก็ตาม webapp ยังคงมีประโยชน์อย่างแน่นอน
หากคุณต้องการเรียนรู้เพิ่มเติม คุณอาจชื่นชอบวิดีโอนี้บน YouTube สำหรับข้อความ และวิดีโอนี้บน YouTube สำหรับคอมพิวเตอร์วิทัศน์
หากต้องการใช้ข้อความจำนวนมาก คุณจะต้องเตรียมไฟล์ CSV ก่อน
บันทึก
ตัวอย่างด้านล่างใช้ embetter เพื่อสร้างการฝังและ umap เพื่อลดขนาด แต่คุณสามารถใช้เครื่องมือฝังข้อความอะไรก็ได้ตามใจชอบ คุณจะต้องติดตั้งเครื่องมือเหล่านี้แยกกัน โปรดทราบว่า embetter ใช้ตัวแปลงประโยคภายใต้ประทุน
import pandas as pd
from umap import UMAP
from sklearn . pipeline import make_pipeline
# pip install "embetter[text]"
from embetter . text import SentenceEncoder
# Build a sentence encoder pipeline with UMAP at the end.
text_emb_pipeline = make_pipeline (
SentenceEncoder ( 'all-MiniLM-L6-v2' ),
UMAP ()
)
# Load sentences
sentences = list ( pd . read_csv ( "original.csv" )[ 'sentences' ])
# Calculate embeddings
X_tfm = text_emb_pipeline . fit_transform ( sentences )
# Write to disk. Note! Text column must be named "text"
df = pd . DataFrame ({ "text" : sentences })
df [ 'x' ] = X_tfm [:, 0 ]
df [ 'y' ] = X_tfm [:, 1 ]
df . to_csv ( "ready.csv" , index = False ) ตอนนี้คุณสามารถใช้ไฟล์ ready.csv นี้เพื่อใช้การติดป้ายกำกับจำนวนมากได้
python -m bulk text ready.csv
หากคุณกำลังมองหาไฟล์ตัวอย่างเพื่อทดลองเล่น คุณสามารถดาวน์โหลดไฟล์สาธิต .csv ได้ในพื้นที่เก็บข้อมูลนี้ ชุดข้อมูลนี้มีชุดย่อยของชุดข้อมูลที่พบใน Kaggle คุณสามารถค้นหาต้นฉบับได้ที่นี่
คุณยังสามารถส่งคอลัมน์เพิ่มเติมไปยังไฟล์ csv ที่เรียกว่า "สี" ได้ คอลัมน์นี้จะถูกใช้เพื่อระบายสีจุดต่างๆ ในอินเทอร์เฟซ
คุณยังสามารถส่ง --keywords ไปยังแอปบรรทัดคำสั่งเพื่อเน้นองค์ประกอบที่มีคำหลักเฉพาะได้
python -m bulk text ready.csv --keywords "deliver,card,website,compliment"
ตัวอย่างด้านล่างใช้ไลบรารี embetter เพื่อสร้างชุดข้อมูลสำหรับการติดป้ายกำกับรูปภาพจำนวนมาก
บันทึก
ตัวอย่างด้านล่างใช้ embetter เพื่อสร้างการฝังและ umap เพื่อลดขนาด แต่คุณสามารถใช้เครื่องมือฝังข้อความอะไรก็ได้ตามใจชอบ คุณจะต้องติดตั้งเครื่องมือเหล่านี้แยกกัน โปรดทราบว่า embetter ใช้ TIMM ใต้ฝากระโปรง
import pathlib
import pandas as pd
from sklearn . pipeline import make_pipeline
from umap import UMAP
from sklearn . preprocessing import MinMaxScaler
# pip install "embetter[vision]"
from embetter . grab import ColumnGrabber
from embetter . vision import ImageLoader , TimmEncoder
# Build image encoding pipeline
image_emb_pipeline = make_pipeline (
ColumnGrabber ( "path" ),
ImageLoader ( convert = "RGB" ),
TimmEncoder ( 'xception' ),
UMAP (),
MinMaxScaler ()
)
# Make dataframe with image paths
img_paths = list ( pathlib . Path ( "downloads" , "pets" ). glob ( "*" ))
dataf = pd . DataFrame ({
"path" : [ str ( p ) for p in img_paths ]
})
# Make csv file with Umap'ed model layer
# Note! Bulk assumes the image path column to be called "path"!
X = image_emb_pipeline . fit_transform ( dataf )
dataf [ 'x' ] = X [:, 0 ]
dataf [ 'y' ] = X [:, 1 ]
dataf . to_csv ( "ready.csv" , index = False )สิ่งนี้จะสร้างไฟล์ csv ที่สามารถโหลดจำนวนมากได้ทาง;
python -m bulk image ready.csv
คุณยังสามารถสร้างชุดภาพขนาดย่อสำหรับรูปภาพของคุณได้ สิ่งนี้มีประโยชน์หากคุณกำลังทำงานกับชุดข้อมูลขนาดใหญ่
python -m bulk util resize ready.csv ready2.csv temp
สิ่งนี้จะสร้างโฟลเดอร์ชื่อ temp พร้อมรูปภาพที่ปรับขนาดแล้วทั้งหมด จากนั้นคุณสามารถใช้โฟลเดอร์นี้เป็นอาร์กิวเมนต์ --thumbnail-path
python -m bulk image ready2.csv --thumbnail-path temp
คุณยังสามารถใช้จำนวนมากเพื่อดาวน์โหลดชุดข้อมูลบางชุดเพื่อเล่นด้วย สำหรับข้อมูลเพิ่มเติม:
python -m bulk download --help
อินเทอร์เฟซอาจช่วยให้คุณติดป้ายกำกับได้อย่างรวดเร็ว แต่ตัวป้ายกำกับอาจมีเสียงดังพอสมควร กรณีการใช้งานที่ตั้งใจไว้สำหรับเครื่องมือนี้คือการเตรียมชุดย่อยที่น่าสนใจเพื่อใช้ในภายหลังใน prodi.gy


