chatdocs
0.2.6
แชทกับเอกสารของคุณแบบออฟไลน์โดยใช้ AI ไม่มีข้อมูลออกจากระบบของคุณ จำเป็นต้องเชื่อมต่ออินเทอร์เน็ตเพื่อติดตั้งเครื่องมือและดาวน์โหลดโมเดล AI เท่านั้น มันขึ้นอยู่กับ PrivateGPT แต่มีคุณสมบัติเพิ่มเติม
สารบัญ
chatdocs.yml| ส่วนขยาย | รูปแบบ |
|---|---|
.csv | ซีเอสวี |
.docx , .doc | เอกสารเวิร์ด |
.enex | EverNote |
.eml | อีเมล |
.epub | EPub |
.html | HTML |
.md | มาร์กดาวน์ |
.msg | ข้อความ Outlook |
.odt | เปิดข้อความเอกสาร |
.pdf | รูปแบบเอกสารพกพา (PDF) |
.pptx , .ppt | เอกสารพาวเวอร์พอยท์ |
.txt | ไฟล์ข้อความ (UTF-8) |
ติดตั้งเครื่องมือโดยใช้:
pip install chatdocsดาวน์โหลดโมเดล AI โดยใช้:
chatdocs downloadตอนนี้สามารถทำงานแบบออฟไลน์ได้โดยไม่ต้องเชื่อมต่ออินเทอร์เน็ต
เพิ่มไดเร็กทอรีที่มีเอกสารเพื่อสนทนาโดยใช้:
chatdocs add /path/to/documentsเอกสารที่ประมวลผลจะถูกจัดเก็บไว้ในไดเร็กทอรี
dbตามค่าเริ่มต้น
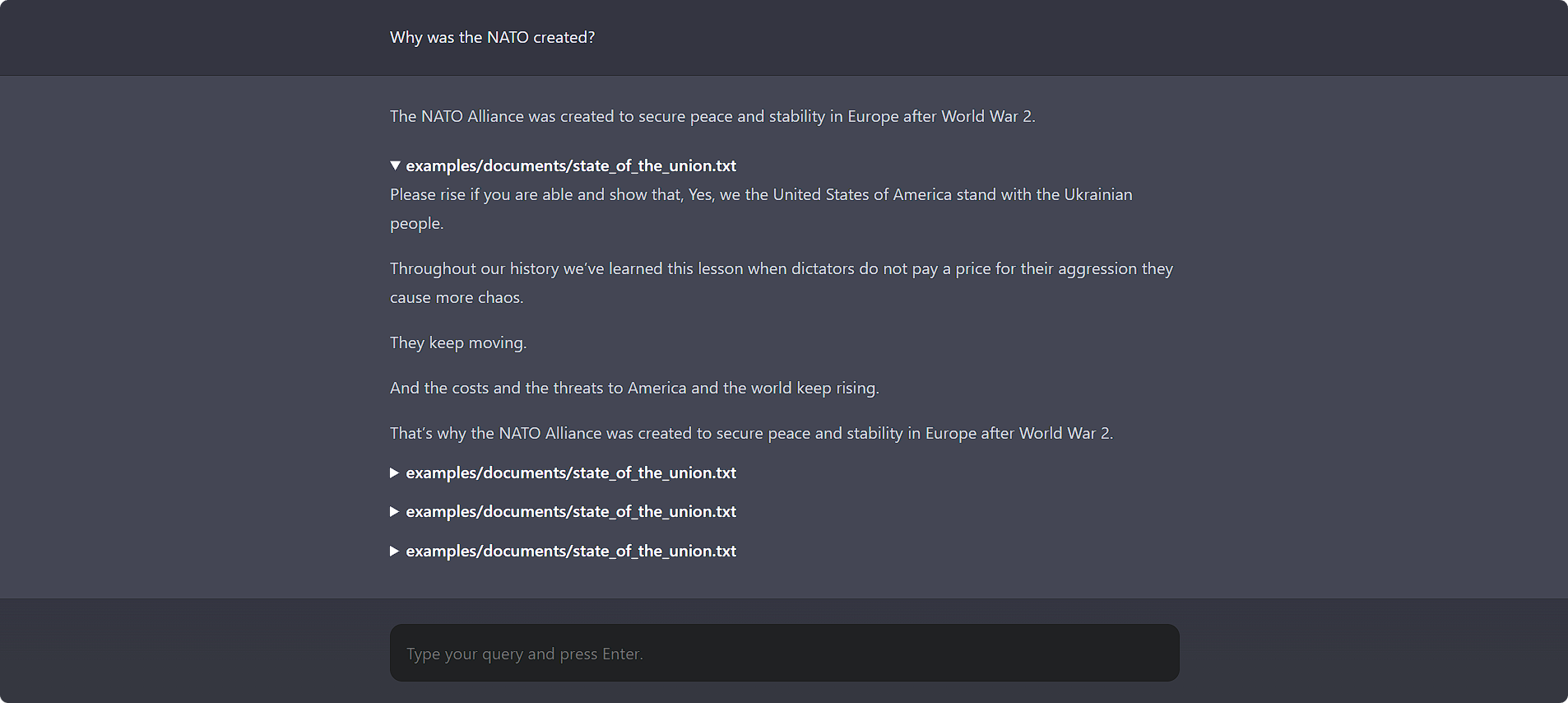
สนทนากับเอกสารของคุณโดยใช้:
chatdocs uiเปิด http://localhost:5000 ในเบราว์เซอร์ของคุณเพื่อเข้าถึง UI ของเว็บ
นอกจากนี้ยังมีอินเทอร์เฟซบรรทัดคำสั่งที่ดี:
chatdocs chat
ตัวเลือกการกำหนดค่าทั้งหมดสามารถเปลี่ยนแปลงได้โดยใช้ไฟล์กำหนดค่า chatdocs.yml สร้างไฟล์ chatdocs.yml ในบางไดเร็กทอรีและรันคำสั่งทั้งหมดจากไดเร็กทอรีนั้น สำหรับการอ้างอิง โปรดดูไฟล์ chatdocs.yml เริ่มต้น
คุณไม่จำเป็นต้องคัดลอกไฟล์ทั้งหมด เพียงเพิ่มตัวเลือกการกำหนดค่าที่คุณต้องการเปลี่ยนแปลง เนื่องจากไฟล์จะถูกรวมเข้ากับการกำหนดค่าเริ่มต้น ตัวอย่างเช่น ดูที่ tests/fixtures/chatdocs.yml ซึ่งเปลี่ยนตัวเลือกการกำหนดค่าเพียงบางส่วนเท่านั้น
หากต้องการเปลี่ยนโมเดลการฝัง ให้เพิ่มและเปลี่ยนแปลงสิ่งต่อไปนี้ใน chatdocs.yml ของคุณ :
embeddings :
model : hkunlp/instructor-largeหมายเหตุ: เมื่อคุณเปลี่ยนโมเดลการฝัง ให้ลบไดเร็กทอรี
dbและเพิ่มเอกสารอีกครั้ง
หากต้องการเปลี่ยนโมเดล CTransformers (GGML/GGUF) ให้เพิ่มและเปลี่ยนแปลงสิ่งต่อไปนี้ใน chatdocs.yml ของคุณ :
ctransformers :
model : TheBloke/Wizard-Vicuna-7B-Uncensored-GGML
model_file : Wizard-Vicuna-7B-Uncensored.ggmlv3.q4_0.bin
model_type : llamaหมายเหตุ: เมื่อคุณเพิ่มโมเดลใหม่เป็นครั้งแรก ให้เรียกใช้
chatdocs downloadเพื่อดาวน์โหลดโมเดลก่อนใช้งาน
คุณยังสามารถใช้ไฟล์โมเดลโลคัลที่มีอยู่ได้:
ctransformers :
model : /path/to/ggml-model.bin
model_type : llama เพื่อใช้ ? โมเดล Transformers ให้เพิ่มสิ่งต่อไปนี้ใน chatdocs.yml ของคุณ :
llm : huggingface หากต้องการเปลี่ยน ? โมเดล Transformers เพิ่มและเปลี่ยนแปลงสิ่งต่อไปนี้ใน chatdocs.yml ของคุณ :
huggingface :
model : TheBloke/Wizard-Vicuna-7B-Uncensored-HFหมายเหตุ: เมื่อคุณเพิ่มโมเดลใหม่เป็นครั้งแรก ให้เรียกใช้
chatdocs downloadเพื่อดาวน์โหลดโมเดลก่อนใช้งาน
หากต้องการใช้โมเดล GPTQ ด้วย ? หม้อแปลงไฟฟ้า ให้ติดตั้งแพ็คเกจที่จำเป็นโดยใช้:
pip install chatdocs[gptq] หากต้องการเปิดใช้งานการรองรับ GPU (CUDA) สำหรับโมเดลการฝัง ให้เพิ่มสิ่งต่อไปนี้ใน chatdocs.yml ของคุณ :
embeddings :
model_kwargs :
device : cudaคุณอาจต้องติดตั้ง PyTorch ใหม่โดยเปิดใช้งาน CUDA โดยทำตามคำแนะนำที่นี่
หากต้องการเปิดใช้งานการรองรับ GPU (CUDA) สำหรับโมเดล CTransformers (GGML/GGUF) ให้เพิ่มสิ่งต่อไปนี้ใน chatdocs.yml ของคุณ :
ctransformers :
config :
gpu_layers : 50คุณอาจต้องติดตั้งไลบรารี CUDA โดยใช้:
pip install ctransformers[cuda] หากต้องการเปิดใช้งานการรองรับ GPU (CUDA) สำหรับ ? โมเดล Transformers เพิ่มสิ่งต่อไปนี้ใน chatdocs.yml ของคุณ :
huggingface :
device : 0คุณอาจต้องติดตั้ง PyTorch ใหม่โดยเปิดใช้งาน CUDA โดยทำตามคำแนะนำที่นี่
เอ็มไอที


