MedCalc Bench
1.0.0
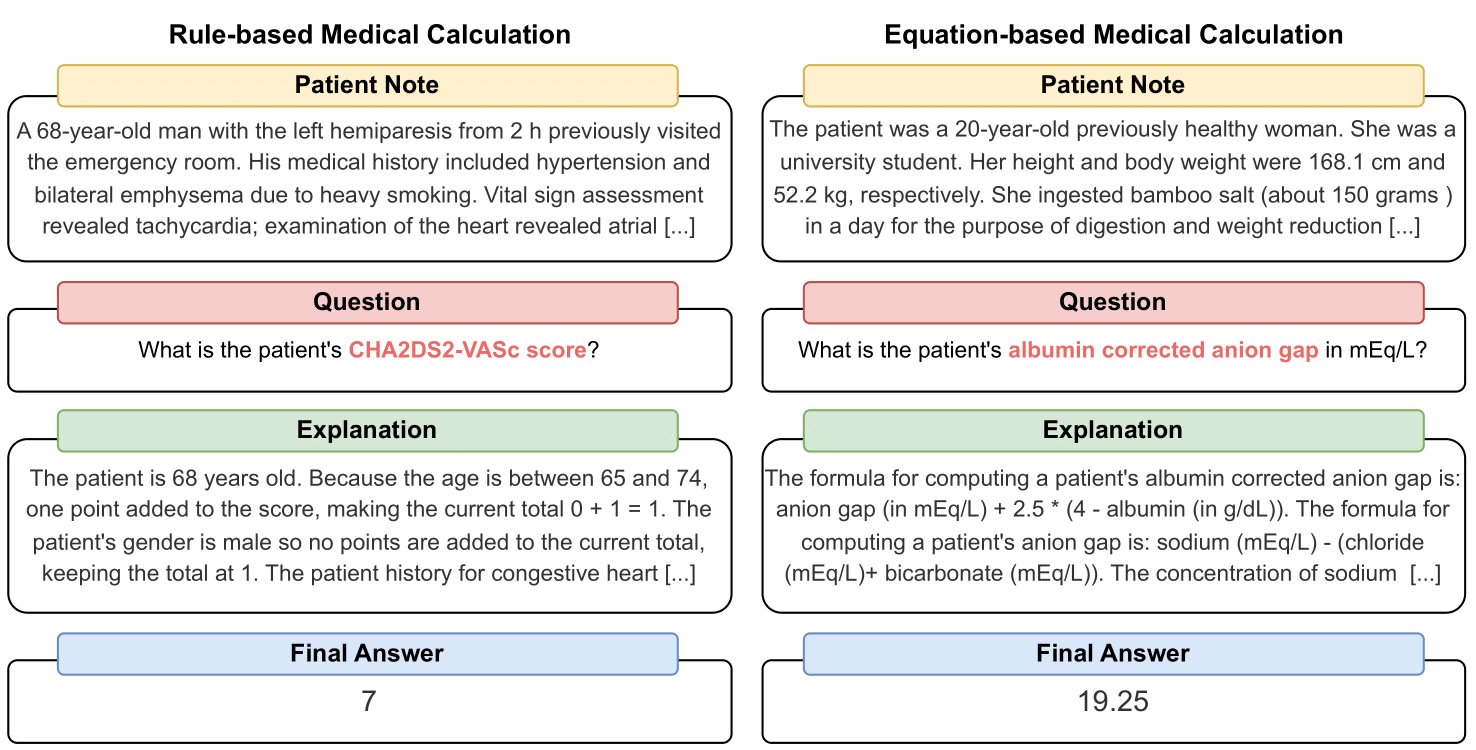
MedCalc-Bench เป็นชุดข้อมูลการคำนวณทางการแพทย์ชุดแรกที่ใช้วัดประสิทธิภาพของ LLM เพื่อทำหน้าที่เป็นเครื่องคิดเลขทางคลินิก แต่ละตัวอย่างในชุดข้อมูลประกอบด้วยบันทึกของผู้ป่วย คำถามที่ขอให้คำนวณมูลค่าทางคลินิกเฉพาะ ค่าคำตอบสุดท้าย และวิธีการแก้ปัญหาทีละขั้นตอนที่อธิบายวิธีการได้รับคำตอบสุดท้าย ชุดข้อมูลของเราครอบคลุมงานการคำนวณที่แตกต่างกัน 55 งาน ซึ่งเป็นการคำนวณตามกฎหรือการคำนวณตามสมการ ชุดข้อมูลนี้ประกอบด้วยชุดข้อมูลการฝึกอบรมจำนวน 10,053 อินสแตนซ์ และชุดข้อมูลการทดสอบจำนวน 1,047 อินสแตนซ์
โดยรวมแล้ว เราหวังว่าชุดข้อมูลและเกณฑ์มาตรฐานของเราทำหน้าที่เป็นตัวเรียกร้องให้ปรับปรุงทักษะการใช้เหตุผลเชิงคำนวณของ LLM ในสถานพยาบาล
ดูการพิมพ์ล่วงหน้าของเราได้ที่: https://arxiv.org/abs/2406.12036
หากต้องการดาวน์โหลด CSV สำหรับชุดข้อมูลการประเมิน MedCalc-Bench โปรดดาวน์โหลดไฟล์ test_data.csv ภายในโฟลเดอร์ dataset ของที่เก็บนี้ คุณยังสามารถดาวน์โหลดชุดการทดสอบแยกจาก HuggingFace ได้ที่ https://huggingface.co/datasets/ncbi/MedCalc-Bench
นอกเหนือจากอินสแตนซ์การประเมิน 1,047 รายการแล้ว เรายังจัดเตรียมชุดข้อมูลการฝึกอบรมจำนวน 10,053 อินสแตนซ์ ซึ่งสามารถใช้สำหรับการปรับแต่ง LLM แบบโอเพ่นซอร์สอย่างละเอียด (ดูส่วน C ของภาคผนวก) ข้อมูลการฝึกอบรมสามารถพบได้ในไฟล์ dataset/train_data.csv.zip และสามารถแตกไฟล์เพื่อรับ train_data.csv ได้ ชุดข้อมูลการฝึกอบรมนี้ยังสามารถพบได้ในส่วนแยกรถไฟของลิงก์ HuggingFace
แต่ละอินสแตนซ์ในชุดข้อมูลประกอบด้วยข้อมูลต่อไปนี้:
หากต้องการติดตั้งแพ็กเกจทั้งหมดที่จำเป็นสำหรับโปรเจ็กต์นี้ โปรดรันคำสั่งต่อไปนี้: conda env create -f environment.yml คำสั่งนี้จะสร้างสภาพแวดล้อม conda medcalc-bench สำหรับการรันโมเดล OpenAI คุณจะต้องระบุคีย์ OpenAI ของคุณในสภาพแวดล้อม conda นี้ คุณสามารถทำได้โดยดำเนินการคำสั่งต่อไปนี้ในสภาพแวดล้อม medcalc-bench : export OPENAI_API_KEY = YOUR_API_KEY โดยที่ YOUR_API_KEY คือคีย์ OpenAI API ของคุณ นอกจากนี้ คุณจะต้องจัดเตรียมโทเค็น HuggingFace ของคุณในสภาพแวดล้อมนี้โดยการรันคำสั่งต่อไปนี้: export HUGGINGFACE_TOKEN=your_hugging_face_token โดยที่ your_hugging_face_token คือโทเค็น Huggingface ของคุณ
หากต้องการทำซ้ำตารางที่ 2 จากกระดาษ ให้ cd ลงในโฟลเดอร์ evaluation ก่อน จากนั้น โปรดรันคำสั่งต่อไปนี้: python run.py --model <model_name> and --prompt <prompt_style>
ตัวเลือกสำหรับ --model อยู่ด้านล่าง:
ตัวเลือกสำหรับ --prompt อยู่ด้านล่าง:
จากนี้ คุณจะได้รับไฟล์ jsonl หนึ่งไฟล์ที่แสดงสถานะของทุกคำถาม: เมื่อรัน run.py ผลลัพธ์จะถูกบันทึกในไฟล์ชื่อ <model>_<prompt>.jsonl ไฟล์นี้สามารถพบได้ในโฟลเดอร์ outputs
แต่ละอินสแตนซ์ใน jsonl จะมีข้อมูลเมตาต่อไปนี้เชื่อมโยงอยู่:
{
"Row Number": Row index of the item,
"Calculator Name": Name of calculation task,
"Calculator ID": ID of the calculator,
"Category": type of calculation (risk, severity, diagnosis for rule-based calculators and lab, risk, physical, date, dosage for equation-based calculators),
"Note ID": ID of the note taken directly from MedCalc-Bench,
"Patient Note": Paragraph which is the patient note taken directly from MedCalc-Bench,
"Question": Question asking for a specific medical value to be computed,
"LLM Answer": Final Answer Value from LLM,
"LLM Explanation": Step-by-Step explanation by LLM,
"Ground Truth Answer": Ground truth answer value,
"Ground Truth Explanation": Step-by-step ground truth explanation,
"Result": "Correct" or "Incorrect"
}
นอกจากนี้ เรายังจัดเตรียมค่าเฉลี่ยความแม่นยำและเปอร์เซ็นต์ส่วนเบี่ยงเบนมาตรฐานสำหรับแต่ละหมวดหมู่ย่อยใน json ชื่อ results_<model>_<prompt_style>.json ความแม่นยำสะสมและค่าเบี่ยงเบนมาตรฐานของอินสแตนซ์ทั้งหมด 1,047 รายการสามารถพบได้ภายใต้คีย์ "โดยรวม" ของ JSON ไฟล์นี้สามารถพบได้ในโฟลเดอร์ results
นอกจากผลลัพธ์สำหรับตารางที่ 2 ในรายงานหลักแล้ว เรายังแจ้งให้ LLM เขียนโค้ดเพื่อคำนวณทางคณิตศาสตร์ แทนที่จะให้ LLM ดำเนินการเอง ผลลัพธ์นี้สามารถพบได้ในภาคผนวก D เนื่องจากการประมวลผลที่จำกัด เราจึงรันผลลัพธ์สำหรับ GPT-3.5 และ GPT-4 เท่านั้น หากต้องการตรวจสอบพร้อมท์และทำงานภายใต้การตั้งค่านี้ โปรดตรวจสอบไฟล์ generate_code_prompt.py ในโฟลเดอร์ evaluation
หากต้องการเรียกใช้โค้ดนี้ เพียงใส่ cd ลงในโฟลเดอร์ evaluations แล้วเรียกใช้สิ่งต่อไปนี้: python generate_code_prompt.py --gpt <gpt_model> ตัวเลือกสำหรับ <gpt_model> คือ 4 สำหรับการรัน GPT-4 หรือ 35 สำหรับการรัน GPT-3.5-turbo-16k ผลลัพธ์จะได้รับการบันทึกในไฟล์ jsonl ชื่อ: code_exec_{model_name}.jsonl ในโฟลเดอร์ outputs โปรดทราบว่าในกรณีนี้ model_name จะเป็น gpt_4 หากคุณเลือกที่จะทำงานโดยใช้ GPT-4 มิฉะนั้น model_name จะเป็น gpt_35_16k หากคุณเลือกที่จะรันด้วย GPT-3.5-turbo
ข้อมูลเมตาสำหรับแต่ละอินสแตนซ์ในไฟล์ jsonl สำหรับผลลัพธ์ของตัวแปลโค้ดเป็นข้อมูลอินสแตนซ์เดียวกันที่ให้ไว้ในส่วนด้านบน ข้อแตกต่างเพียงอย่างเดียวคือ เราจัดเก็บประวัติการแชท LLM ระหว่างผู้ใช้และผู้ช่วย และมีคีย์ "ประวัติการแชท LLM" แทนคีย์ "คำอธิบาย LLM" นอกจากนี้ หมวดหมู่ย่อยและความแม่นยำโดยรวมจะถูกจัดเก็บไว้ในไฟล์ JSON ชื่อ results_<model_name>_code_augmented.json JSON นี้อยู่ในโฟลเดอร์ results
งานวิจัยนี้ได้รับการสนับสนุนจากโครงการวิจัยภายใน NIH หอสมุดแพทยศาสตร์แห่งชาติ นอกจากนี้ การมีส่วนร่วมของ Soren Dunn ยังดำเนินการโดยใช้ทรัพยากรคอมพิวเตอร์และข้อมูลขั้นสูงของ Delta ซึ่งได้รับการสนับสนุนโดยมูลนิธิวิทยาศาสตร์แห่งชาติ (รางวัล OAC โทร: 2005572) และรัฐอิลลินอยส์ Delta เป็นความพยายามร่วมกันของ University of Illinois Urbana-Champaign (UIUC) และ National Center for Supercomputing Applications (NCSA)
สำหรับการดูแลบันทึกผู้ป่วยใน MedCalc-Bench เราจะใช้เฉพาะบันทึกผู้ป่วยที่เปิดเผยต่อสาธารณะจากบทความรายงานกรณีที่ตีพิมพ์ใน PubMed Central และบทความสั้น ๆ ของผู้ป่วยที่ไม่เปิดเผยตัวตนที่แพทย์สร้างขึ้น ด้วยเหตุนี้ จึงไม่มีการเปิดเผยข้อมูลสุขภาพส่วนบุคคลที่สามารถระบุตัวตนได้ในการศึกษานี้ แม้ว่า MedCalc-Bench ได้รับการออกแบบมาเพื่อประเมินความสามารถในการคำนวณทางการแพทย์ของ LLM แต่ก็ควรสังเกตว่าชุดข้อมูลไม่ได้มีไว้สำหรับใช้ในการวินิจฉัยโดยตรงหรือการตัดสินใจทางการแพทย์โดยไม่ได้รับการตรวจสอบและควบคุมโดยผู้เชี่ยวชาญทางคลินิก บุคคลไม่ควรเปลี่ยนพฤติกรรมด้านสุขภาพโดยอาศัยการศึกษาของเราเพียงอย่างเดียว
ตามที่อธิบายไว้ในวินาทีที่ 1 เครื่องคิดเลขทางการแพทย์มักใช้ในสถานพยาบาล ด้วยความสนใจที่เพิ่มขึ้นอย่างรวดเร็วในการใช้ LLM สำหรับแอปพลิเคชันเฉพาะโดเมน ผู้ปฏิบัติงานด้านการดูแลสุขภาพอาจแจ้งให้แชทบอท เช่น ChatGPT ทำงานการคำนวณทางการแพทย์โดยตรง อย่างไรก็ตาม ความสามารถของ LLM ในงานเหล่านี้ยังไม่เป็นที่ทราบแน่ชัด เนื่องจากการดูแลสุขภาพเป็นโดเมนที่มีเดิมพันสูง และการคำนวณทางการแพทย์ที่ไม่ถูกต้องอาจนำไปสู่ผลลัพธ์ร้ายแรง รวมถึงการวินิจฉัยผิดพลาด แผนการรักษาที่ไม่เหมาะสม และอันตรายที่อาจเกิดกับผู้ป่วย การประเมินประสิทธิภาพของ LLM ในการคำนวณทางการแพทย์อย่างละเอียดจึงเป็นสิ่งสำคัญ น่าประหลาดใจที่ผลการประเมินชุดข้อมูล MedCalc-Bench ของเราแสดงให้เห็นว่า LLM ที่ศึกษาทั้งหมดประสบปัญหาในการคำนวณทางการแพทย์ โมเดล GPT-4 ที่มีความสามารถมากที่สุดมีความแม่นยำเพียง 50% ด้วยการเรียนรู้แบบครั้งเดียวและการกระตุ้นความคิดแบบลูกโซ่ ด้วยเหตุนี้ การศึกษาของเราจึงบ่งชี้ว่า LLM ในปัจจุบันยังไม่พร้อมที่จะใช้สำหรับการคำนวณทางการแพทย์ ควรสังเกตว่าแม้ว่าคะแนนที่สูงใน MedCalc-Bench จะไม่รับประกันความเป็นเลิศในงานการคำนวณทางการแพทย์ แต่การล้มเหลวในชุดข้อมูลนี้บ่งชี้ว่าแบบจำลองต่างๆ จะต้องไม่ได้รับการพิจารณาเพื่อวัตถุประสงค์ดังกล่าวเลย กล่าวอีกนัยหนึ่ง เราเชื่อว่าการผ่าน MedCalc-Bench ควรเป็นเงื่อนไขที่จำเป็น (แต่ไม่เพียงพอ) สำหรับแบบจำลองที่จะใช้สำหรับการคำนวณทางการแพทย์
สำหรับการเปลี่ยนแปลงชุดข้อมูลนี้ (เช่น การเพิ่มบันทึกหรือเครื่องคิดเลขใหม่) เราจะอัปเดตคำสั่ง README, test_set.csv และ train_set.csv เราจะยังคงเก็บชุดข้อมูลเวอร์ชันเก่าเหล่านี้ไว้ในไฟล์ archive/ โฟลเดอร์ นอกจากนี้เรายังจะอัปเดตชุดรถไฟและชุดทดสอบสำหรับ HuggingFace ด้วยเช่นกัน
เครื่องมือนี้แสดงผลการวิจัยที่ดำเนินการในสาขาวิชาชีววิทยาคอมพิวเตอร์ NCBI/NLM ข้อมูลที่ผลิตบนเว็บไซต์นี้ไม่ได้มีวัตถุประสงค์เพื่อใช้ในการวินิจฉัยโดยตรงหรือการตัดสินใจทางการแพทย์โดยไม่ได้รับการตรวจสอบและกำกับดูแลโดยผู้เชี่ยวชาญทางคลินิก บุคคลไม่ควรเปลี่ยนพฤติกรรมด้านสุขภาพของตนโดยอาศัยข้อมูลที่ผลิตบนเว็บไซต์นี้เพียงอย่างเดียว NIH ไม่ได้ตรวจสอบความถูกต้องหรือประโยชน์ของข้อมูลที่ผลิตโดยเครื่องมือนี้โดยอิสระ หากคุณมีคำถามเกี่ยวกับข้อมูลที่ผลิตบนเว็บไซต์นี้ โปรดดูผู้เชี่ยวชาญด้านการดูแลสุขภาพ ข้อมูลเพิ่มเติมเกี่ยวกับนโยบายข้อจำกัดความรับผิดชอบของ NCBI มีอยู่
ชุดข้อมูลของเราประกอบด้วยบันทึกย่อที่ได้รับการออกแบบจากฟังก์ชันที่ใช้เทมเพลตที่ใช้งานใน Python เขียนด้วยลายมือโดยแพทย์ หรือนำมาจากชุดข้อมูล Open-Patients ของเรา ทั้งนี้ขึ้นอยู่กับเครื่องคิดเลข
Open-Patients เป็นชุดข้อมูลที่รวบรวมบันทึกผู้ป่วย 180,000 รายการมาจากแหล่งที่มาที่แตกต่างกันสามแห่ง เราได้รับอนุญาตให้ใช้ชุดข้อมูลจากแหล่งที่มาทั้งสามแห่ง แหล่งที่มาแรกคือคำถาม USMLE จาก MedQA ซึ่งเผยแพร่ภายใต้ใบอนุญาต MIT แหล่งข้อมูลที่สองของชุดข้อมูลของเราคือ Trec Clinical Decision Support และ Trec Clinical Trial ซึ่งพร้อมสำหรับการแจกจ่ายซ้ำ เนื่องจากทั้งสองชุดเป็นชุดข้อมูลของรัฐบาลที่เผยแพร่สู่สาธารณะ สุดท้าย PMC-Patients ได้รับการเผยแพร่ภายใต้ใบอนุญาต CC-BY-SA 4.0 ดังนั้นเราจึงได้รับอนุญาตให้รวม PMC-Patients ไว้ใน Open-Patients และ MedCalc-Bench แต่ชุดข้อมูลจะต้องได้รับการเผยแพร่ภายใต้ใบอนุญาตเดียวกัน ดังนั้น แหล่งที่มาของบันทึกของเรา Open-Patients และชุดข้อมูลที่รวบรวมจากนั้น MedCalc-Bench จึงได้รับการเผยแพร่ภายใต้ใบอนุญาต CC-BY-SA 4.0
บนพื้นฐานของเหตุผลของกฎใบอนุญาต ทั้ง Open-Patients และ MedCalc-Bench ปฏิบัติตามใบอนุญาต CC-BY-SA 4.0 แต่ผู้เขียนบทความนี้จะต้องรับผิดชอบทั้งหมดในกรณีที่มีการละเมิดสิทธิ์
@misc { khandekar2024medcalcbench ,
title = { MedCalc-Bench: Evaluating Large Language Models for Medical Calculations } ,
author = { Nikhil Khandekar and Qiao Jin and Guangzhi Xiong and Soren Dunn and Serina S Applebaum and Zain Anwar and Maame Sarfo-Gyamfi and Conrad W Safranek and Abid A Anwar and Andrew Zhang and Aidan Gilson and Maxwell B Singer and Amisha Dave and Andrew Taylor and Aidong Zhang and Qingyu Chen and Zhiyong Lu } ,
year = { 2024 } ,
eprint = { 2406.12036 } ,
archivePrefix = { arXiv } ,
primaryClass = { id='cs.CL' full_name='Computation and Language' is_active=True alt_name='cmp-lg' in_archive='cs' is_general=False description='Covers natural language processing. Roughly includes material in ACM Subject Class I.2.7. Note that work on artificial languages (programming languages, logics, formal systems) that does not explicitly address natural-language issues broadly construed (natural-language processing, computational linguistics, speech, text retrieval, etc.) is not appropriate for this area.' }
}

