CQN
1.0.0
การใช้งานใหม่ของ Coarse-to-fine Q-Network (CQN) ซึ่งเป็นอัลกอริธึม RL ตามค่าตัวอย่างที่มีประสิทธิภาพสำหรับการควบคุมอย่างต่อเนื่อง เปิดตัวใน:
การควบคุมอย่างต่อเนื่องด้วยการเรียนรู้การเสริมแรงแบบหยาบถึงละเอียด
ยังกโย ซอ, จาฟาร์ อูรุช, สตีเฟน เจมส์
แนวคิดหลักของเราคือการเรียนรู้ตัวแทน RL ที่ซูมเข้าสู่พื้นที่การดำเนินการต่อเนื่องในลักษณะหยาบถึงละเอียด ช่วยให้เราสามารถฝึกอบรมตัวแทน RL ตามมูลค่าเพื่อการควบคุมอย่างต่อเนื่องโดยมีการดำเนินการแยกกันเพียงเล็กน้อยในแต่ละระดับ
ดูหน้าเว็บโครงการของเรา https://younggyo.me/cqn/ สำหรับข้อมูลเพิ่มเติม
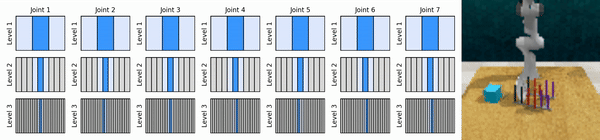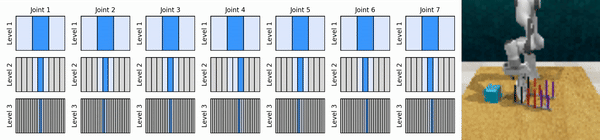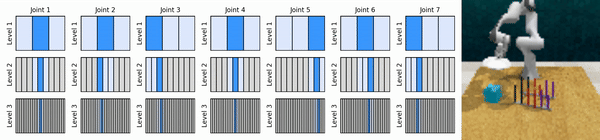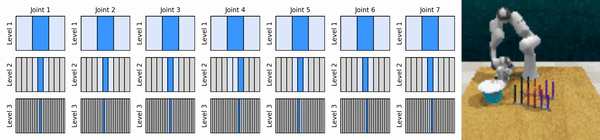
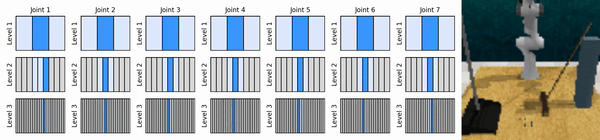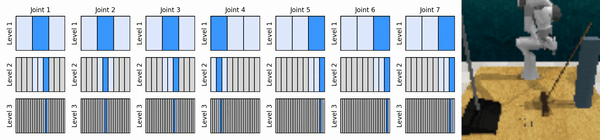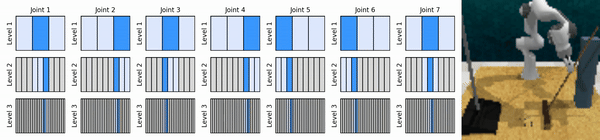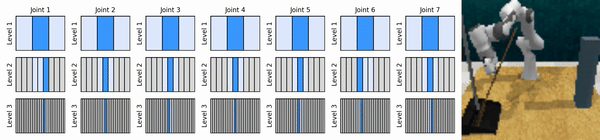
ติดตั้งสภาพแวดล้อม conda:
conda env create -f conda_env.yml
conda activate cqn
ติดตั้ง RBench และ PyRep (ควรใช้เวอร์ชันล่าสุด ณ วันที่ 10 กรกฎาคม 2024) ทำตามคำแนะนำในที่เก็บดั้งเดิมสำหรับ (1) การติดตั้ง RLBench และ PyRep และ (2) เปิดใช้งานโหมด headless (ดู README ใน RLBench & Robobase สำหรับข้อมูลเกี่ยวกับการติดตั้ง RLBench)
git clone https://github.com/stepjam/RLBench
git clone https://github.com/stepjam/PyRep
# Install PyRep
cd PyRep
git checkout 8f420be8064b1970aae18a9cfbc978dfb15747ef
pip install .
# Install RLBench
cd RLBench
git checkout b80e51feb3694d9959cb8c0408cd385001b01382
pip install .
รวบรวมการสาธิตล่วงหน้า
cd RLBench/rlbench
CUDA_VISIBLE_DEVICES=0 DISPLAY=:0.0 python dataset_generator.py --save_path=/your/own/directory --image_size 84 84 --renderer opengl3 --episodes_per_task 100 --variations 1 --processes 1 --tasks take_lid_off_saucepan --arm_max_velocity 2.0 --arm_max_acceleration 8.0
ดำเนินการทดลอง (CQN):
CUDA_VISIBLE_DEVICES=0 DISPLAY=:0.0 python train_rlbench.py rlbench_task=take_lid_off_saucepan num_demos=100 dataset_root=/your/own/directory
ดำเนินการทดสอบพื้นฐาน (DrQv2+):
CUDA_VISIBLE_DEVICES=0 DISPLAY=:0.0 python train_rlbench_drqv2plus.py rlbench_task=take_lid_off_saucepan num_demos=100 dataset_root=/your/own/directory
ทำการทดลอง:
CUDA_VISIBLE_DEVICES=0 python train_dmc.py dmc_task=cartpole_swingup
คำเตือน: CQN ไม่ได้รับการทดสอบอย่างกว้างขวางใน DMC
พื้นที่เก็บข้อมูลนี้มีพื้นฐานมาจากการใช้งาน DrQ-v2 แบบสาธารณะ
@article{seo2024continuous,
title={Continuous Control with Coarse-to-fine Reinforcement Learning},
author={Seo, Younggyo and Uru{c{c}}, Jafar and James, Stephen},
journal={arXiv preprint arXiv:2407.07787},
year={2024}
}


