lorax
v0.12.0: Multi-LoRA prefix caching, fp8 kv cache, Mllama, function calling

LoRAX: เซิร์ฟเวอร์การอนุมาน Multi-LoRA ที่ปรับขนาดได้ถึง 1,000 LLM ที่ปรับแต่งอย่างละเอียด
LoRAX (LoRA eXchange) เป็นเฟรมเวิร์กที่ช่วยให้ผู้ใช้สามารถให้บริการโมเดลที่ได้รับการปรับแต่งหลายพันโมเดลบน GPU ตัวเดียว ซึ่งช่วยลดต้นทุนการให้บริการได้อย่างมากโดยไม่กระทบต่อปริมาณงานหรือเวลาแฝง
สารบัญ
คุณสมบัติ
โมเดล
?เริ่มต้นใช้งาน
ความต้องการ
เปิดเซิร์ฟเวอร์ LoRAX
พรอมต์ผ่าน REST API
พร้อมท์ผ่านไคลเอนต์ Python
สนทนาผ่าน OpenAI API
ขั้นตอนต่อไป
รับทราบ
แผนการทำงาน
การโหลดอะแดปเตอร์แบบไดนามิก: รวมอะแดปเตอร์ LoRA ที่ได้รับการปรับแต่งอย่างละเอียดจาก HuggingFace, Predibase หรือระบบไฟล์ใดๆ ในคำขอของคุณ โดยระบบจะโหลดทันทีทันเวลาโดยไม่บล็อกคำขอที่เกิดขึ้นพร้อมกัน รวมอะแดปเตอร์ตามคำขอเพื่อสร้างชุดที่ทรงพลังทันที
การรวมชุดต่อเนื่องที่แตกต่างกัน: แพ็คคำขอสำหรับอะแดปเตอร์ที่แตกต่างกันเข้าด้วยกันเป็นชุดเดียวกัน ทำให้เวลาแฝงและปริมาณงานเกือบคงที่ด้วยจำนวนอะแดปเตอร์ที่ทำงานพร้อมกัน
การกำหนดตารางเวลาการแลกเปลี่ยนอะแดปเตอร์: ดึงข้อมูลล่วงหน้าและถ่ายโอนอะแดปเตอร์ระหว่าง GPU และหน่วยความจำ CPU แบบอะซิงโครนัส กำหนดเวลาการร้องขอเป็นชุดเพื่อเพิ่มประสิทธิภาพปริมาณงานโดยรวมของระบบ
การอนุมานที่ปรับให้เหมาะสม: การเพิ่มประสิทธิภาพปริมาณงานสูงและเวลาแฝงต่ำ รวมถึงเทนเซอร์แบบขนาน, เคอร์เนล CUDA ที่คอมไพล์ไว้ล่วงหน้า (การสนใจแบบแฟลช, การสนใจเพจ, SGMV), การหาปริมาณ, การสตรีมโทเค็น
พร้อมสำหรับการผลิต อิมเมจ Docker ที่สร้างไว้ล่วงหน้า แผนภูมิ Helm สำหรับ Kubernetes ตัววัด Prometheus และการติดตามแบบกระจายด้วย Open Telemetry API ที่เข้ากันได้กับ OpenAI รองรับการสนทนาแบบหลายรอบ อะแดปเตอร์ส่วนตัวผ่านการแยกผู้เช่าตามคำขอ เอาต์พุตที่มีโครงสร้าง (โหมด JSON)
- ฟรีสำหรับใช้ในเชิงพาณิชย์: ลิขสิทธิ์ Apache 2.0 พูดพอแล้ว?.
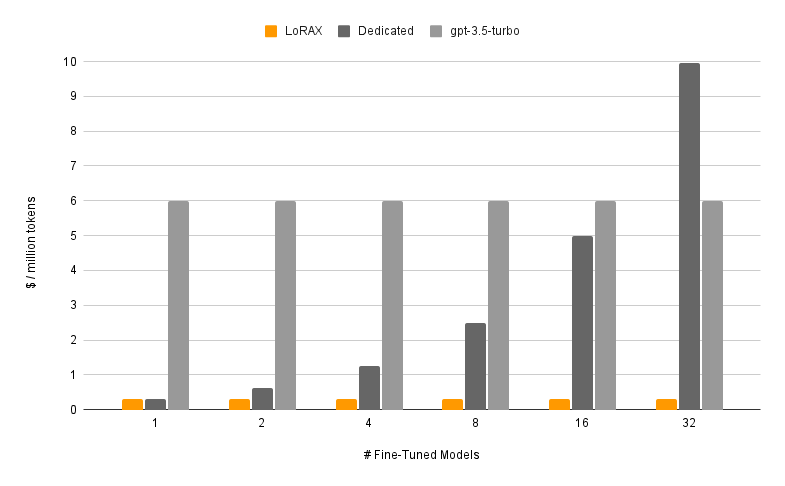
การให้บริการโมเดลที่ได้รับการปรับแต่งอย่างละเอียดด้วย LoRAX ประกอบด้วยสององค์ประกอบ:
โมเดลพื้นฐาน: โมเดลขนาดใหญ่ที่ได้รับการฝึกไว้ล่วงหน้าที่ใช้ร่วมกันกับอะแดปเตอร์ทั้งหมด
อะแดปเตอร์: น้ำหนักของอะแดปเตอร์เฉพาะงานโหลดแบบไดนามิกตามคำขอ
LoRAX รองรับโมเดลภาษาขนาดใหญ่จำนวนหนึ่งเป็นโมเดลพื้นฐาน รวมถึง Llama (รวมถึง CodeLlama), Mistral (รวมถึง Zephyr) และ Qwen ดูสถาปัตยกรรมที่รองรับสำหรับรายการโมเดลพื้นฐานที่รองรับทั้งหมด
โมเดลพื้นฐานสามารถโหลดได้ใน fp16 หรือวัดปริมาณด้วย bitsandbytes , GPT-Q หรือ AWQ
อะแดปเตอร์ที่รองรับ ได้แก่ อะแดปเตอร์ LoRA ที่ได้รับการฝึกอบรมโดยใช้ไลบรารี PEFT และ Ludwig เลเยอร์เชิงเส้นใดๆ ในโมเดลสามารถปรับได้ผ่าน LoRA และโหลดใน LoRAX
เราขอแนะนำให้เริ่มต้นด้วยอิมเมจ Docker ที่สร้างไว้ล่วงหน้าเพื่อหลีกเลี่ยงการคอมไพล์เคอร์เนล CUDA แบบกำหนดเองและการขึ้นต่อกันอื่นๆ
ความต้องการระบบขั้นต่ำที่จำเป็นในการรัน LoRAX ได้แก่:
Nvidia GPU (รุ่น Ampere หรือสูงกว่า)
ไดรเวอร์อุปกรณ์ที่รองรับ CUDA 11.8 และสูงกว่า
ระบบปฏิบัติการลินุกซ์
นักเทียบท่า (สำหรับคำแนะนำนี้)
ติดตั้ง nvidia-container-toolkit จากนั้น
sudo systemctl daemon-reload
sudo systemctl restart docker
model=mistralai/Mistral-7B-Instruct-v0.1
ปริมาณ=$PWD/ข้อมูล
นักเทียบท่าวิ่ง --gpus ทั้งหมด --shm-size 1g -p 8080:80 -v $volume:/data
ghcr.io/predibase/lorax:main --model-id $modelสำหรับบทช่วยสอนแบบเต็มรวมถึงการสตรีมโทเค็นและไคลเอนต์ Python โปรดดูการเริ่มต้นใช้งาน - Docker
LLM ฐานพร้อมท์:
curl 127.0.0.1:8080/สร้าง
-X โพสต์
-d '{ "inputs": "[INST] Natalia ขายคลิปให้กับเพื่อนของเธอ 48 คนในเดือนเมษายน จากนั้นเธอก็ขายคลิปได้ครึ่งหนึ่งในเดือนพฤษภาคม Natalia ขายคลิปทั้งหมดได้กี่คลิปในเดือนเมษายนและพฤษภาคม [/INST] ", "พารามิเตอร์": { "max_new_tokens": 64 } }'
-H 'ประเภทเนื้อหา: application/json'แจ้งอะแดปเตอร์ LoRA:
curl 127.0.0.1:8080/สร้าง
-X โพสต์
-d '{ "inputs": "[INST] Natalia ขายคลิปให้กับเพื่อนของเธอ 48 คนในเดือนเมษายน จากนั้นเธอก็ขายคลิปได้ครึ่งหนึ่งในเดือนพฤษภาคม Natalia ขายคลิปทั้งหมดได้กี่คลิปในเดือนเมษายนและพฤษภาคม [/INST] ", "พารามิเตอร์": { "max_new_tokens": 64, "adapter_id": "vineetsharma/qlora-อะแดปเตอร์-Mistral-7B-Instruct-v0.1-gsm8k" } }'
-H 'ประเภทเนื้อหา: application/json'ดูข้อมูลอ้างอิง - REST API สำหรับรายละเอียดทั้งหมด
ติดตั้ง:
pip ติดตั้ง lorax-client.php
วิ่ง:
จาก lorax import Clientclient = Client("http://127.0.0.1:8080")# Prompt the base LLMprompt = "[INST] Natalia ขายคลิปให้เพื่อนของเธอ 48 คนในเดือนเมษายน จากนั้นเธอก็ขายคลิปได้ครึ่งหนึ่งในเดือนพฤษภาคม . Natalia ขายได้ทั้งหมดกี่คลิปในเดือนเมษายนและพฤษภาคม [/INST]"print(client.generate(prompt, max_new_tokens=64).generated_text)# พรอมต์ LoRA adapteradapter_id = "vineetsharma/qlora-adapter-Mistral-7B-Instruct-v0.1-gsm8k"print(client.generate(prompt, max_new_tokens=64, adapter_id=adapter_id).generated_text )ดูข้อมูลอ้างอิง - ไคลเอนต์ Python สำหรับรายละเอียดทั้งหมด
สำหรับวิธีอื่นๆ ในการรัน LoRAX โปรดดูการเริ่มต้นใช้งาน - Kubernetes การเริ่มต้นใช้งาน - SkyPilot และการเริ่มต้นใช้งาน - ภายในเครื่อง
LoRAX รองรับการสนทนาแบบหลายรอบรวมกับการโหลดอะแดปเตอร์แบบไดนามิกผ่าน API ที่เข้ากันได้กับ OpenAI เพียงระบุอะแดปเตอร์ใดๆ ให้เป็นพารามิเตอร์ model
จากการนำเข้า openai OpenAIclient = OpenAI(api_key="EMPTY",base_url="http://127.0.0.1:8080/v1",
)resp = client.chat.completions.create(model="alignment-handbook/zephyr-7b-dpo-lora",ข้อความ=[
{"role": "system", "content": "คุณเป็นแชทบอทที่เป็นมิตรที่ตอบสนองสไตล์โจรสลัดอยู่เสมอ",
-
{"role": "user", "content": "มนุษย์สามารถกินเฮลิคอปเตอร์ได้กี่ลำในการนั่งครั้งเดียว"},
],max_tokens=100,
)พิมพ์("การตอบสนอง:", resp.choices[0].message.content)ดู API ที่เข้ากันได้กับ OpenAI สำหรับรายละเอียด
นี่คือโมเดล Mistral-7B ที่ได้รับการปรับแต่งอย่างละเอียดอื่นๆ ที่น่าสนใจให้ลอง:
Alignment-handbook/zephyr-7b-dpo-lora: Mistral-7b ได้รับการปรับแต่งอย่างละเอียดบนชุดข้อมูล Zephyr-7B ด้วย DPO
IlyaGusev/saiga_mistral_7b_lora: แชทบอทภาษารัสเซียที่ใช้ Open-Orca/Mistral-7B-OpenOrca
Undi95/Mistral-7B-roleplay_alpaca-lora: ปรับแต่งอย่างละเอียดโดยใช้การแสดงบทบาทสมมติ
คุณสามารถค้นหาอะแดปเตอร์ LoRA เพิ่มเติมได้ที่นี่ หรือลองปรับแต่งอะแดปเตอร์ของคุณเองด้วย PEFT หรือ Ludwig
LoRAX ถูกสร้างขึ้นบนการอนุมานการสร้างข้อความของ HuggingFace ซึ่งแยกจาก v0.9.4 (Apache 2.0)
นอกจากนี้เรายังขอขอบคุณ Punica ที่ทำงานเกี่ยวกับเคอร์เนล SGMV ซึ่งใช้เพื่อเพิ่มความเร็วในการอนุมานหลายอะแดปเตอร์ภายใต้ภาระงานหนัก
ติดตามแผนงานของเราได้ที่นี่


