gpt neox
GPT-NeoX 2.0
พื้นที่เก็บข้อมูลนี้จะบันทึกไลบรารีของ EleutherAI สำหรับการฝึกโมเดลภาษาขนาดใหญ่บน GPU เฟรมเวิร์กปัจจุบันของเราอิงตามโมเดลภาษา Megatron ของ NVIDIA และเสริมด้วยเทคนิคจาก DeepSpeed รวมถึงการเพิ่มประสิทธิภาพใหม่ๆ บางอย่าง เรามุ่งมั่นที่จะทำให้ repo นี้เป็นสถานที่รวมศูนย์และเข้าถึงได้ เพื่อรวบรวมเทคนิคสำหรับการฝึกอบรมโมเดลภาษาแบบถดถอยอัตโนมัติในวงกว้าง และเร่งการวิจัยเกี่ยวกับการฝึกอบรมในวงกว้าง ห้องสมุดนี้มีการใช้งานอย่างแพร่หลายในห้องปฏิบัติการทางวิชาการ อุตสาหกรรม และของรัฐบาล รวมถึงโดยนักวิจัยที่ Oak Ridge National Lab, CarperAI, Stability AI, Together.ai, Korea University, Carnegie Mellon University และ University of Tokyo และอื่นๆ อีกมากมาย GPT-NeoX มีเอกลักษณ์เฉพาะในบรรดาไลบรารีที่คล้ายคลึงกัน รองรับระบบและฮาร์ดแวร์ที่หลากหลาย รวมถึงการเปิดตัวผ่าน Slurm, MPI และ IBM Job Step Manager และได้รับการรันในระดับบน AWS, CoreWeave, ORNL Summit, ORNL Frontier, LUMI และ คนอื่น.
หากคุณไม่ต้องการฝึกโมเดลด้วยพารามิเตอร์นับพันล้านตั้งแต่เริ่มต้น นี่อาจเป็นไลบรารีที่ไม่ถูกต้องที่จะใช้ สำหรับความต้องการในการอนุมานทั่วไป เราขอแนะนำให้คุณใช้ไลบรารี Hugging Face transformers แทน ซึ่งรองรับรุ่น GPT-NeoX
GPT-NeoX ใช้ประโยชน์จากคุณสมบัติและเทคโนโลยีหลายอย่างเช่นเดียวกับไลบรารี Megatron-DeepSpeed ที่ได้รับความนิยม แต่มีการใช้งานที่เพิ่มขึ้นอย่างมากและการเพิ่มประสิทธิภาพแบบใหม่ คุณสมบัติที่สำคัญ ได้แก่ :
[9/9/2024] ขณะนี้เราสนับสนุนการเรียนรู้ตามความชอบผ่าน DPO, KTO และการสร้างแบบจำลองการให้รางวัล
[9/9/2024] ขณะนี้เรารองรับการผสานรวมกับ Comet ML ซึ่งเป็นแพลตฟอร์มการตรวจสอบแมชชีนเลิร์นนิง
[5/21/2024] ตอนนี้เรารองรับ RWKV ด้วยความขนานของไปป์ไลน์แล้ว! ดูการประชาสัมพันธ์สำหรับไปป์ไลน์ RWKV และ RWKV+
[3/21/2024] ตอนนี้เรารองรับ Mixture-of-Experts (MoE) แล้ว
[3/17/2024] ขณะนี้เรารองรับ GPU AMD MI250X แล้ว
[3/15/2024] ตอนนี้เราสนับสนุน Mamba ด้วยความเท่าเทียมของเทนเซอร์! ดูประชาสัมพันธ์
[8/10/2023] ตอนนี้เรารองรับจุดตรวจสอบด้วย AWS S3 แล้ว! เปิดใช้งานด้วยตัวเลือกการกำหนดค่า s3_path (สำหรับรายละเอียดเพิ่มเติม โปรดดูที่ PR)
[20/9/2023] ตั้งแต่ #1035 เราได้เลิกใช้งาน Flash Attention 0.x และ 1.x และย้ายการสนับสนุนไปยัง Flash Attention 2.x แล้ว เราไม่เชื่อว่าสิ่งนี้จะทำให้เกิดปัญหา แต่หากคุณมีกรณีการใช้งานเฉพาะที่ต้องการการสนับสนุนแฟลชเก่าโดยใช้ GPT-NeoX ล่าสุด โปรดแจ้งปัญหา
[8/10/2023] เรามีการสนับสนุนรุ่นทดลองสำหรับ LLaMA 2 และ Flash Attention v2 ที่ได้รับการสนับสนุนในโครงการ Math-LM ของเราซึ่งจะมีการอัปสตรีมในปลายเดือนนี้
[5/17/2023] หลังจากแก้ไขข้อบกพร่องเบ็ดเตล็ดแล้ว ตอนนี้เรารองรับ bf16 อย่างสมบูรณ์แล้ว
[4/11/2023] เราได้อัปเกรดการใช้งาน Flash Attention เพื่อรองรับการฝังตำแหน่งของ Alibi แล้ว
[3/9/2023] เราได้เปิดตัว GPT-NeoX 2.0.0 ซึ่งเป็นเวอร์ชันอัปเกรดที่สร้างจาก DeepSpeed ล่าสุด ซึ่งจะมีการซิงค์เป็นประจำในอนาคต
ก่อนวันที่ 3/9/2023 GPT-NeoX ใช้ DeeperSpeed ซึ่งอิงตาม DeepSpeed เวอร์ชันเก่า (0.3.15) เพื่อที่จะย้ายไปยังอัปสตรีม DeepSpeed เวอร์ชันล่าสุดในขณะที่อนุญาตให้ผู้ใช้เข้าถึง GPT-NeoX และ DeeperSpeed เวอร์ชันเก่าได้ เราได้แนะนำรุ่นสองเวอร์ชันสำหรับไลบรารีทั้งสอง:
โค้ดเบสนี้ได้รับการพัฒนาและทดสอบสำหรับ Python 3.8-3.10 และ PyTorch 1.8-2.0 เป็นหลัก นี่ไม่ใช่ข้อกำหนดที่เข้มงวด และเวอร์ชันอื่นๆ และการรวมไลบรารีอาจใช้งานได้
หากต้องการติดตั้งการพึ่งพาพื้นฐานที่เหลือ ให้รัน:
pip install -r requirements/requirements.txt
pip install -r requirements/requirements-wandb.txt # optional, if logging using WandB
pip install -r requirements/requirements-tensorboard.txt # optional, if logging via tensorboard
pip install -r requirements/requirements-comet.txt # optional, if logging via Cometจากรูทของพื้นที่เก็บข้อมูล
คำเตือน
โค้ดเบสของเราอาศัย DeeperSpeed ซึ่งเป็นทางแยกของไลบรารี DeepSpeed ที่มีการเปลี่ยนแปลงเพิ่มเติมบางอย่าง เราขอแนะนำอย่างยิ่งให้ใช้ Anaconda, เครื่องเสมือน หรือการแยกสภาพแวดล้อมในรูปแบบอื่นก่อนดำเนินการต่อ หากไม่ดำเนินการดังกล่าวอาจทำให้ที่เก็บข้อมูลอื่นๆ ที่ต้องอาศัย DeepSpeed เสียหาย
ขณะนี้เรารองรับ AMD GPUs (MI100, MI250X) ผ่านการคอมไพล์เคอร์เนล JIT เมล็ดพืชที่หลอมละลายจะถูกสร้างและบรรจุตามความจำเป็น เพื่อหลีกเลี่ยงการรอในระหว่างการเปิดตัวงาน คุณสามารถทำสิ่งต่อไปนี้สำหรับการสร้างล่วงหน้าด้วยตนเอง:
python
from megatron . fused_kernels import load
load () สิ่งนี้จะปรับกระบวนการสร้างโดยอัตโนมัติผ่านผู้จำหน่าย GPU ที่แตกต่างกัน (AMD, NVIDIA) โดยไม่ต้องเปลี่ยนโค้ดเฉพาะแพลตฟอร์ม หากต้องการทดสอบเคอร์เนลหลอมเพิ่มเติมโดยใช้ pytest ให้ใช้ pytest tests/model/test_fused_kernels.py
หากต้องการใช้ Flash-Attention ให้ติดตั้งการขึ้นต่อกันเพิ่มเติมใน ./requirements/requirements-flashattention.txt และตั้งค่าประเภทความสนใจในการกำหนดค่าของคุณตามลำดับ (ดูการกำหนดค่า) สิ่งนี้สามารถช่วยเพิ่มความเร็วได้อย่างมีนัยสำคัญมากกว่าความสนใจปกติในสถาปัตยกรรม GPU บางตัว รวมถึง Ampere GPU (เช่น A100) ดูพื้นที่เก็บข้อมูลสำหรับรายละเอียดเพิ่มเติม
การฝึกอบรมการสนับสนุน NeoX และ Deep(er)Speed บนหลายโหนดที่แตกต่างกัน และคุณมีทางเลือกในการใช้ Launcher ที่แตกต่างกันเพื่อประสานงานแบบหลายโหนด
โดยทั่วไปจำเป็นต้องมี "hostfile" ในที่ที่สามารถเข้าถึงได้ด้วยรูปแบบ:
node1_ip slots=8
node2_ip slots=8 โดยที่คอลัมน์แรกประกอบด้วยที่อยู่ IP สำหรับแต่ละโหนดในการตั้งค่าของคุณและจำนวนช่องคือจำนวน GPU ที่โหนดสามารถเข้าถึงได้ ในการกำหนดค่าของคุณ คุณต้องส่งผ่านเส้นทางไปยังไฟล์โฮสต์ด้วย "hostfile": "/path/to/hostfile" อีกทางหนึ่งคือเส้นทางไปยังไฟล์โฮสต์สามารถอยู่ในตัวแปรสภาพแวดล้อม DLTS_HOSTFILE
pdsh เป็นตัวเรียกใช้งานเริ่มต้น และหากคุณใช้ pdsh สิ่งที่คุณต้องทำทั้งหมด (นอกเหนือจากการตรวจสอบให้แน่ใจว่า pdsh ได้รับการติดตั้งในสภาพแวดล้อมของคุณ) จะถูกตั้งค่า {"launcher": "pdsh"} ในไฟล์ปรับแต่งของคุณ
หากใช้ MPI คุณต้องระบุไลบรารี MPI (ปัจจุบัน DeepSpeed/GPT-NeoX รองรับ mvapich , openmpi , mpich และ impi แม้ว่า openmpi จะเป็นโปรแกรมที่ใช้และทดสอบบ่อยที่สุดก็ตาม) รวมทั้งส่งแฟล็ก deepspeed_mpi ในไฟล์กำหนดค่าของคุณ:
{
"launcher" : " openmpi " ,
"deepspeed_mpi" : true
} ด้วยการตั้งค่าสภาพแวดล้อมของคุณอย่างเหมาะสมและไฟล์การกำหนดค่าที่ถูกต้อง คุณสามารถใช้ deepy.py ได้เหมือนกับสคริปต์ Python ปกติ และเริ่ม (ตัวอย่าง) งานฝึกอบรมด้วย:
python3 deepy.py train.py /path/to/configs/my_model.yml
การใช้ Slurm อาจมีส่วนร่วมมากกว่าเล็กน้อย เช่นเดียวกับ MPI คุณต้องเพิ่มสิ่งต่อไปนี้ในการกำหนดค่าของคุณ:
{
"launcher" : " slurm " ,
"deepspeed_slurm" : true
} หากคุณไม่มีสิทธิ์เข้าถึง ssh ไปยังโหนดคอมพิวเตอร์ในคลัสเตอร์ Slurm ของคุณ คุณจะต้องเพิ่ม {"no_ssh_check": true}
มีหลายกรณีที่ตัวเลือกการเริ่มต้นเริ่มต้นข้างต้นไม่เพียงพอ
ในกรณีเหล่านี้ คุณจะต้องแก้ไขยูทิลิตี้ DeepSpeed multinode runner เพื่อรองรับการใช้งานของคุณ โดยทั่วไปแล้ว การปรับปรุงเหล่านี้จัดอยู่ในสองประเภท:
ในกรณีนี้ คุณต้องเพิ่มคลาส multinode runner ใหม่ให้กับ deepspeed/launcher/multinode_runner.py และแสดงเป็นตัวเลือกการกำหนดค่าใน GPT-NeoX ตัวอย่างวิธีที่เราทำสิ่งนี้สำหรับ Summit JSRun อยู่ในการคอมมิต DeeperSpeed และคอมมิต GPT-NeoX นี้ตามลำดับ
เราพบหลายกรณีที่เราต้องการแก้ไขคำสั่งเรียกใช้ MPI/Slurm เพื่อการเพิ่มประสิทธิภาพหรือแก้ไขจุดบกพร่อง (เช่น เพื่อแก้ไขการเชื่อมโยง CPU ของ Slurm srun หรือแท็กบันทึก MPI ด้วยอันดับ) ในกรณีนี้ คุณต้องแก้ไขคำสั่ง run ของคลาส multinode runner ภายใต้เมธอด get_cmd (เช่น mpirun_cmd สำหรับ OpenMPI) ตัวอย่างวิธีที่เราทำสิ่งนี้เพื่อจัดเตรียมคำสั่งรันที่ได้รับการปรับปรุงและติดแท็กอันดับโดยใช้ Slurm และ OpenMPI สำหรับคลัสเตอร์ Stability อยู่ในสาขา DeeperSpeed นี้
โดยทั่วไป คุณจะไม่สามารถมีไฟล์โฮสต์คงที่เพียงไฟล์เดียวได้ ดังนั้นคุณต้องมีสคริปต์เพื่อสร้างไฟล์แบบไดนามิกเมื่องานของคุณเริ่มต้น สคริปต์ตัวอย่างในการสร้างไฟล์โฮสต์แบบไดนามิกโดยใช้ Slurm และ 8 GPU ต่อโหนดคือ:
#! /bin/bash
GPUS_PER_NODE=8
mkdir -p /sample/path/to/hostfiles
# need to add the current slurm jobid to hostfile name so that we don't add to previous hostfile
hostfile=/sample/path/to/hostfiles/hosts_ $SLURM_JOBID
# be extra sure we aren't appending to a previous hostfile
rm $hostfile & > /dev/null
# loop over the node names
for i in ` scontrol show hostnames $SLURM_NODELIST `
do
# add a line to the hostfile
echo $i slots= $GPUS_PER_NODE >> $hostfile
done $SLURM_JOBID และ $SLURM_NODELIST เป็นตัวแปรสภาพแวดล้อมที่ Slurm จะสร้างให้คุณ ดูเอกสารประกอบชุดเพื่อดูรายการตัวแปรสภาพแวดล้อม Slurm ที่พร้อมใช้งานทั้งหมดที่ตั้งค่า ณ เวลาที่สร้างงาน
จากนั้น คุณสามารถสร้างสคริปต์ sbatch เพื่อเริ่มต้นงาน GPT-NeoX ของคุณได้ สคริปต์ sbatch แบบเปลือยบนคลัสเตอร์แบบ Slurm ที่มี 8 GPU ต่อโหนดจะมีลักษณะดังนี้:
#! /bin/bash
# SBATCH --job-name="neox"
# SBATCH --partition=your-partition
# SBATCH --nodes=1
# SBATCH --ntasks-per-node=8
# SBATCH --gres=gpu:8
# Some potentially useful distributed environment variables
export HOSTNAMES= ` scontrol show hostnames " $SLURM_JOB_NODELIST " `
export MASTER_ADDR= $( scontrol show hostnames " $SLURM_JOB_NODELIST " | head -n 1 )
export MASTER_PORT=12802
export COUNT_NODE= ` scontrol show hostnames " $SLURM_JOB_NODELIST " | wc -l `
# Your hostfile creation script from above
./write_hostfile.sh
# Tell DeepSpeed where to find our generated hostfile via DLTS_HOSTFILE
export DLTS_HOSTFILE=/sample/path/to/hostfiles/hosts_ $SLURM_JOBID
# Launch training
python3 deepy.py train.py /sample/path/to/your/configs/my_model.yml
จากนั้น คุณสามารถเริ่มต้นการฝึกซ้อมด้วย sbatch my_sbatch_script.sh
นอกจากนี้เรายังจัดเตรียมการกำหนดค่า Dockerfile และ Docker-compose หากคุณต้องการเรียกใช้ NeoX ในคอนเทนเนอร์
ข้อกำหนดในการเรียกใช้คอนเทนเนอร์คือต้องมีไดรเวอร์ GPU ที่เหมาะสม การติดตั้ง Docker ที่ทันสมัย และติดตั้งชุดเครื่องมือ nvidia-container-toolkit เพื่อทดสอบว่าการติดตั้งของคุณดีหรือไม่ คุณสามารถใช้ "ปริมาณงานตัวอย่าง" ซึ่งก็คือ:
docker run --rm --runtime=nvidia --gpus all ubuntu nvidia-smi
หากจะทำงาน คุณจะต้องส่งออก NEOX_DATA_PATH และ NEOX_CHECKPOINT_PATH ในสภาพแวดล้อมของคุณเพื่อระบุไดเร็กทอรีข้อมูลและไดเร็กทอรีสำหรับจัดเก็บและโหลดจุดตรวจสอบ:
export NEOX_DATA_PATH=/mnt/sda/data/enwiki8 #or wherever your data is stored on your system
export NEOX_CHECKPOINT_PATH=/mnt/sda/checkpoints
จากนั้นจากไดเร็กทอรี gpt-neox คุณสามารถสร้างอิมเมจและรันเชลล์ในคอนเทนเนอร์ได้
docker compose run gpt-neox bash
หลังจากสร้างแล้ว คุณควรจะทำสิ่งนี้ได้:
mchorse@537851ed67de:~$ echo $(pwd)
/home/mchorse
mchorse@537851ed67de:~$ ls -al
total 48
drwxr-xr-x 1 mchorse mchorse 4096 Jan 8 05:33 .
drwxr-xr-x 1 root root 4096 Jan 8 04:09 ..
-rw-r--r-- 1 mchorse mchorse 220 Feb 25 2020 .bash_logout
-rw-r--r-- 1 mchorse mchorse 3972 Jan 8 04:09 .bashrc
drwxr-xr-x 4 mchorse mchorse 4096 Jan 8 05:35 .cache
drwx------ 3 mchorse mchorse 4096 Jan 8 05:33 .nv
-rw-r--r-- 1 mchorse mchorse 807 Feb 25 2020 .profile
drwxr-xr-x 2 root root 4096 Jan 8 04:09 .ssh
drwxrwxr-x 8 mchorse mchorse 4096 Jan 8 05:35 chk
drwxrwxrwx 6 root root 4096 Jan 7 17:02 data
drwxr-xr-x 11 mchorse mchorse 4096 Jan 8 03:52 gpt-neox
สำหรับงานที่ต้องวิ่งระยะยาวคุณควรวิ่ง
docker compose up -d
เพื่อรันคอนเทนเนอร์ในโหมดเดี่ยว จากนั้นรันในเซสชันเทอร์มินัลที่แยกจากกัน
docker compose exec gpt-neox bash
จากนั้นคุณสามารถรันงานใดๆ ที่คุณต้องการจากภายในคอนเทนเนอร์ได้
ข้อกังวลเมื่อใช้งานเป็นเวลานานหรืออยู่ในโหมดแยก ได้แก่
หากคุณต้องการเรียกใช้คอนเทนเนอร์อิมเมจที่สร้างไว้ล่วงหน้าจาก dockerhub คุณสามารถเรียกใช้คำสั่งเขียนนักเทียบท่าด้วย -f docker-compose-dockerhub.yml แทนได้ เช่น
docker compose run -f docker-compose-dockerhub.yml gpt-neox bash
ฟังก์ชันทั้งหมดควรเปิดใช้งานโดยใช้ deepy.py ซึ่งเป็นตัวหุ้มรอบตัวเรียกใช้งาน deepspeed
ขณะนี้เรามีฟังก์ชันหลักสามประการ:
train.py ใช้สำหรับการฝึกอบรมและปรับแต่งโมเดลeval.py ใช้เพื่อประเมินโมเดลที่ได้รับการฝึกอบรมโดยใช้ชุดประเมินโมเดลภาษาgenerate.py ใช้เพื่อสุ่มตัวอย่างข้อความจากโมเดลที่ผ่านการฝึกอบรมซึ่งสามารถเปิดใช้งานได้ด้วย:
./deepy.py [script.py] [./path/to/config_1.yml] [./path/to/config_2.yml] ... [./path/to/config_n.yml]ตัวอย่างเช่น หากต้องการเริ่มการฝึกอบรม คุณสามารถวิ่งได้
./deepy.py train.py ./configs/20B.yml ./configs/local_cluster.ymlสำหรับรายละเอียดเพิ่มเติมเกี่ยวกับจุดเริ่มต้นแต่ละจุด โปรดดูการฝึกอบรมและการปรับแต่ง การอนุมาน และการประเมินผล ตามลำดับ
พารามิเตอร์ GPT-NeoX ถูกกำหนดไว้ในไฟล์การกำหนดค่า YAML ซึ่งส่งผ่านไปยังตัวเรียกใช้งาน deepy.py เราได้จัดเตรียมตัวอย่างไฟล์ .yml ในการกำหนดค่า ซึ่งแสดงคุณสมบัติและขนาดโมเดลที่หลากหลาย
โดยทั่วไปไฟล์เหล่านี้จะเสร็จสมบูรณ์แต่ไม่ได้เหมาะสมที่สุด ตัวอย่างเช่น ขึ้นอยู่กับการกำหนดค่า GPU เฉพาะของคุณ คุณอาจต้องเปลี่ยนการตั้งค่าบางอย่าง เช่น pipe-parallel-size model-parallel-size เพื่อเพิ่มหรือลดระดับของการทำให้ขนานกัน train_micro_batch_size_per_gpu หรือ gradient-accumulation-steps เพื่อแก้ไขขนาดแบตช์ การตั้งค่าที่เกี่ยวข้อง หรือคำสั่ง zero_optimization เพื่อแก้ไขวิธีที่สถานะของเครื่องมือเพิ่มประสิทธิภาพขนานกันระหว่างผู้ปฏิบัติงาน
สำหรับคำแนะนำโดยละเอียดเพิ่มเติมเกี่ยวกับคุณสมบัติที่มีให้ใช้งานและวิธีการกำหนดค่า โปรดดูการกำหนดค่า README และสำหรับเอกสารประกอบของทุกอาร์กิวเมนต์ที่เป็นไปได้ โปรดดูที่ configs/neox_arguments.md
GPT-NeoX มีการใช้งานโดยผู้เชี่ยวชาญหลายรายการสำหรับ MoE หากต้องการเลือกระหว่างกัน ให้ระบุ moe_type ของ megablocks (ค่าเริ่มต้น) หรือ deepspeed
ทั้งสองอย่างใช้เฟรมเวิร์กการทำงานคู่ขนาน DeepSpeed MoE ซึ่งรองรับการทำงานคู่ขนานของเทนเซอร์-ผู้เชี่ยวชาญ-ข้อมูล ทั้งสองแบบอนุญาตให้คุณสลับระหว่างการทิ้งโทเค็นและแบบไร้หยด (ค่าเริ่มต้น และนี่คือสิ่งที่ Megablocks ได้รับการออกแบบมาเพื่อ) เส้นทาง Sinkhorn จะมาเร็ว ๆ นี้!
สำหรับตัวอย่างการกำหนดค่าพื้นฐานที่สมบูรณ์ โปรดดูที่ configs/125M-dmoe.yml (สำหรับ Megablocks dropless) หรือ configs/125M-moe.yml
อาร์กิวเมนต์การกำหนดค่าที่เกี่ยวข้องกับ MoE ส่วนใหญ่นำหน้าด้วย moe พารามิเตอร์การกำหนดค่าทั่วไปและค่าเริ่มต้นมีดังนี้:
moe_type: megablocks
moe_num_experts: 1 # 1 disables MoE. 8 is a reasonable value.
moe_loss_coeff: 0.1
expert_interval: 2 # See details below
enable_expert_tensor_parallelism: false # See details below
moe_expert_parallel_size: 1 # See details below
moe_token_dropping: false
คุณสามารถกำหนดค่า DeepSpeed เพิ่มเติมได้ดังต่อไปนี้:
moe_top_k: 1
moe_min_capacity: 4
moe_train_capacity_factor: 1.0 # Setting to 1.0
moe_eval_capacity_factor: 1.0 # Setting to 1.0
เลเยอร์ MoE หนึ่งเลเยอร์จะแสดงทุกเลเยอร์ของหม้อแปลง expert_interval ช่วง รวมถึงชั้นแรกด้วย ดังนั้นจะมีทั้งหมด 12 เลเยอร์:
0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11
ผู้เชี่ยวชาญจะอยู่ในเลเยอร์เหล่านี้:
0, 2, 4, 6, 8, 10
ตามค่าเริ่มต้น เราใช้ความเท่าเทียมของข้อมูลผู้เชี่ยวชาญ ดังนั้นความเท่าเทียมของเทนเซอร์ที่มีอยู่ ( model_parallel_size ) จะถูกนำมาใช้สำหรับการกำหนดเส้นทางของผู้เชี่ยวชาญ ตัวอย่างเช่น ให้ดังต่อไปนี้:
expert_parallel_size: 4
model_parallel_size: 2 # aka tensor parallelism
ด้วย GPU 32 ตัว ลักษณะการทำงานจะเป็นดังนี้:
expert_parallel_size == model_parallel_size การตั้งค่า enable_expert_tensor_parallelism จะเปิดใช้งานการทำงานแบบขนานของ Tensor-Expert-Data (TED) วิธีการตีความข้างต้นจะเป็นดังนี้:
expert_parallel_size == 1 หรือ model_parallel_size == 1โปรดทราบว่า DP จะต้องหารด้วย (MP * EP) ลงตัว สำหรับรายละเอียดเพิ่มเติม โปรดดูรายงานของ TED
ยังไม่รองรับ Pipeline Parallelism - เร็วๆ นี้!
มีชุดข้อมูลที่กำหนดค่าไว้ล่วงหน้าหลายชุด รวมถึงส่วนประกอบส่วนใหญ่จาก Pile รวมถึงชุด Pile Train เอง สำหรับการสร้างโทเค็นโดยตรงโดยใช้จุดเริ่มต้น prepare_data.py
EG หากต้องการดาวน์โหลดและสร้างโทเค็นชุดข้อมูล enwik8 ด้วย GPT2 Tokenizer โดยบันทึกลงใน ./data ที่คุณเรียกใช้ได้:
python prepare_data.py -d ./data
หรือชิ้นส่วนเดียวของกอง ( pile_subset ) ด้วยโทเค็น GPT-NeoX-20B (สมมติว่าคุณบันทึกไว้ที่ ./20B_checkpoints/20B_tokenizer.json ):
python prepare_data.py -d ./data -t HFTokenizer --vocab-file ./20B_checkpoints/20B_tokenizer.json pile_subset
ข้อมูลโทเค็นจะถูกบันทึกออกเป็นสองไฟล์: [data-dir]/[dataset-name]/[dataset-name]_text_document.bin และ [data-dir]/[dataset-name]/[dataset-name]_text_document.idx . คุณจะต้องเพิ่มคำนำหน้าที่ทั้งสองไฟล์นี้แชร์ไปยังไฟล์การกำหนดค่าการฝึกของคุณใต้ช่อง data-path เช่น:
" data-path " : " ./data/enwik8/enwik8_text_document " , หากต้องการเตรียมชุดข้อมูลของคุณเองสำหรับการฝึกด้วยข้อมูลที่กำหนดเอง ให้จัดรูปแบบเป็นไฟล์ขนาดใหญ่รูปแบบ jsonl ไฟล์เดียวโดยแต่ละรายการในรายการพจนานุกรมเป็นเอกสารแยกต่างหาก ข้อความในเอกสารควรจัดกลุ่มภายใต้คีย์ JSON เดียว เช่น "text" ข้อมูลเสริมใดๆ ที่จัดเก็บไว้ในฟิลด์อื่นๆ จะไม่ถูกนำมาใช้
ถัดไป อย่าลืมดาวน์โหลดคำศัพท์โทเค็น GPT2 และรวมไฟล์จากลิงก์ต่อไปนี้:
หรือใช้โทเค็น 20B (ซึ่งจำเป็นต้องใช้ไฟล์ Vocab เพียงไฟล์เดียวเท่านั้น):
(หรืออีกทางหนึ่ง คุณสามารถจัดเตรียมไฟล์โทเค็นไนเซอร์ใดๆ ที่สามารถโหลดได้โดยไลบรารีโทเค็นของ Hugging Face ด้วยคำสั่ง Tokenizer.from_pretrained() )
ตอนนี้คุณสามารถ pretokenize ข้อมูลของคุณโดยใช้ tools/datasets/preprocess_data.py ซึ่งมีรายละเอียดอาร์กิวเมนต์ด้านล่าง:
usage: preprocess_data.py [-h] --input INPUT [--jsonl-keys JSONL_KEYS [JSONL_KEYS ...]] [--num-docs NUM_DOCS] --tokenizer-type {HFGPT2Tokenizer,HFTokenizer,GPT2BPETokenizer,CharLevelTokenizer} [--vocab-file VOCAB_FILE] [--merge-file MERGE_FILE] [--append-eod] [--ftfy] --output-prefix OUTPUT_PREFIX
[--dataset-impl {lazy,cached,mmap}] [--workers WORKERS] [--log-interval LOG_INTERVAL]
optional arguments:
-h, --help show this help message and exit
input data:
--input INPUT Path to input jsonl files or lmd archive(s) - if using multiple archives, put them in a comma separated list
--jsonl-keys JSONL_KEYS [JSONL_KEYS ...]
space separate listed of keys to extract from jsonl. Default: text
--num-docs NUM_DOCS Optional: Number of documents in the input data (if known) for an accurate progress bar.
tokenizer:
--tokenizer-type {HFGPT2Tokenizer,HFTokenizer,GPT2BPETokenizer,CharLevelTokenizer}
What type of tokenizer to use.
--vocab-file VOCAB_FILE
Path to the vocab file
--merge-file MERGE_FILE
Path to the BPE merge file (if necessary).
--append-eod Append an <eod> token to the end of a document.
--ftfy Use ftfy to clean text
output data:
--output-prefix OUTPUT_PREFIX
Path to binary output file without suffix
--dataset-impl {lazy,cached,mmap}
Dataset implementation to use. Default: mmap
runtime:
--workers WORKERS Number of worker processes to launch
--log-interval LOG_INTERVAL
Interval between progress updates
ตัวอย่างเช่น:
python tools/datasets/preprocess_data.py
--input ./data/mydataset.jsonl.zst
--output-prefix ./data/mydataset
--vocab ./data/gpt2-vocab.json
--merge-file gpt2-merges.txt
--dataset-impl mmap
--tokenizer-type GPT2BPETokenizer
--append-eodจากนั้น คุณจะดำเนินการฝึกอบรมโดยเพิ่มการตั้งค่าต่อไปนี้ลงในไฟล์การกำหนดค่าของคุณ:
" data-path " : " data/mydataset_text_document " , การฝึกอบรมเปิดตัวโดยใช้ deepy.py ซึ่งเป็นตัวล้อมรอบตัวเรียกใช้งานของ DeepSpeed ซึ่งเรียกใช้สคริปต์เดียวกันแบบขนานกับ GPU / โหนดจำนวนมาก
รูปแบบการใช้งานทั่วไปคือ:
python ./deepy.py train.py [path/to/config1.yml] [path/to/config2.yml] ...คุณสามารถส่งการกำหนดค่าตามจำนวนที่ต้องการได้ ซึ่งทั้งหมดจะถูกรวมเข้าด้วยกันในขณะรันไทม์
คุณยังสามารถส่งผ่านคำนำหน้าการกำหนดค่าได้ ซึ่งจะถือว่าการกำหนดค่าทั้งหมดของคุณอยู่ในโฟลเดอร์เดียวกันและผนวกคำนำหน้านั้นต่อท้ายเส้นทาง
ตัวอย่างเช่น:
python ./deepy.py train.py -d configs 125M.yml local_setup.yml สิ่งนี้จะปรับใช้สคริปต์ train.py บนโหนดทั้งหมดด้วยหนึ่งกระบวนการต่อ GPU โหนดผู้ปฏิบัติงานและจำนวน GPU ระบุไว้ในไฟล์ /job/hostfile (ดูเอกสารประกอบพารามิเตอร์) หรือสามารถส่งผ่านเป็น num_gpus arg หากทำงานบนการตั้งค่าโหนดเดียว
แม้ว่าจะไม่จำเป็นอย่างเคร่งครัด แต่เราพบว่ามีประโยชน์ในการกำหนดพารามิเตอร์โมเดลในไฟล์ปรับแต่งหนึ่งไฟล์ (เช่น configs/125M.yml ) และพารามิเตอร์เส้นทางข้อมูลในอีกไฟล์หนึ่ง (เช่น configs/local_setup.yml )
GPT-NeoX-20B คือโมเดลภาษาแบบถอยหลังอัตโนมัติที่มีพารามิเตอร์ 2 หมื่นล้านพารามิเตอร์ที่ได้รับการฝึกบน Pile รายละเอียดทางเทคนิคเกี่ยวกับ GPT-NeoX-20B มีอยู่ในเอกสารที่เกี่ยวข้อง ไฟล์การกำหนดค่าสำหรับรุ่นนี้มีทั้งอยู่ที่ ./configs/20B.yml และรวมอยู่ในลิงก์ดาวน์โหลดด้านล่าง
น้ำหนักที่บางเฉียบ - (ไม่มีสถานะเครื่องมือเพิ่มประสิทธิภาพ สำหรับการอนุมานหรือการปรับแต่งอย่างละเอียด 39GB)
หากต้องการดาวน์โหลดจากบรรทัดคำสั่งไปยังโฟลเดอร์ชื่อ 20B_checkpoints ให้ใช้คำสั่งต่อไปนี้:
wget --cut-dirs=5 -nH -r --no-parent --reject " index.html* " https://the-eye.eu/public/AI/models/GPT-NeoX-20B/slim_weights/ -P 20B_checkpointsน้ำหนักเต็ม - (รวมสถานะเครื่องมือเพิ่มประสิทธิภาพ, 268GB)
หากต้องการดาวน์โหลดจากบรรทัดคำสั่งไปยังโฟลเดอร์ชื่อ 20B_checkpoints ให้ใช้คำสั่งต่อไปนี้:
wget --cut-dirs=5 -nH -r --no-parent --reject " index.html* " https://the-eye.eu/public/AI/models/GPT-NeoX-20B/full_weights/ -P 20B_checkpointsสามารถดาวน์โหลด Weights ได้โดยใช้ไคลเอนต์ BitTorrent สามารถดาวน์โหลดไฟล์ Torrent ได้ที่นี่: Slim Weights, Full Weights
นอกจากนี้เรายังมีจุดตรวจที่บันทึกไว้ 150 จุดตลอดการฝึก หนึ่งจุดทุกๆ 1,000 ก้าว เรากำลังดำเนินการหาวิธีให้บริการสิ่งเหล่านี้ได้ดีที่สุด แต่ในระหว่างนี้ ผู้ที่สนใจร่วมงานกับจุดตรวจที่ได้รับการฝึกอบรมบางส่วนสามารถส่งอีเมลถึงเราได้ที่ [email protected] เพื่อจัดเตรียมการเข้าถึง
Pythia Scaling Suite เป็นชุดโมเดลที่มีตั้งแต่พารามิเตอร์ 70M ไปจนถึงพารามิเตอร์ 12B ที่ได้รับการฝึกบน Pile ซึ่งมีจุดประสงค์เพื่อส่งเสริมการวิจัยเกี่ยวกับความสามารถในการตีความและการฝึกอบรมไดนามิกของโมเดลภาษาขนาดใหญ่ รายละเอียดเพิ่มเติมเกี่ยวกับโครงการและลิงก์ไปยังโมเดลต่างๆ สามารถพบได้ในรายงานและใน GitHub ของโครงการ
โครงการ Polyglot เป็นความพยายามในการฝึกอบรมโมเดลภาษาที่มีประสิทธิภาพซึ่งไม่ใช่ภาษาอังกฤษที่ได้รับการฝึกฝนมาล่วงหน้า เพื่อส่งเสริมการเข้าถึงเทคโนโลยีนี้แก่นักวิจัยที่อยู่นอกโรงไฟฟ้าหลักด้านการเรียนรู้ของเครื่อง EleutherAI ได้ฝึกอบรมและเผยแพร่โมเดลภาษาเกาหลีพารามิเตอร์ 1.3B, 3.8B และ 5.8B ซึ่งโมเดลที่ใหญ่ที่สุดเหนือกว่าโมเดลภาษาอื่นๆ ที่เปิดเผยต่อสาธารณะทั้งหมดในงานภาษาเกาหลี รายละเอียดเพิ่มเติมเกี่ยวกับโครงการและลิงก์ไปยังแบบจำลองต่างๆ สามารถดูได้ที่นี่
สำหรับการใช้งานส่วนใหญ่ เราขอแนะนำให้ปรับใช้โมเดลที่ได้รับการฝึกโดยใช้ไลบรารี GPT-NeoX ผ่านทางไลบรารี Hugging Face Transformers ซึ่งได้รับการปรับให้เหมาะสมสำหรับการอนุมานที่ดีกว่า
เรารองรับการสร้างสามประเภทจากแบบจำลองที่ได้รับการฝึกล่วงหน้า:
การสร้างข้อความทั้งสามประเภทสามารถเปิดใช้งานผ่าน python ./deepy.py generate.py -d configs 125M.yml local_setup.yml text_generation.yml ด้วยค่าที่เหมาะสมที่ตั้งไว้ใน configs/text_generation.yml
GPT-NeoX รองรับการประเมินงานดาวน์สตรีมผ่านชุดประเมินแบบจำลองภาษา
หากต้องการประเมินแบบจำลองที่ได้รับการฝึกในชุดสายรัดการประเมิน เพียงเรียกใช้:
python ./deepy.py eval.py -d configs your_configs.yml --eval_tasks task1 task2 ... taskn โดยที่ --eval_tasks คือรายการงานการประเมินผลตามด้วยช่องว่าง เช่น --eval_tasks lambada hellaswag piqa sciq สำหรับรายละเอียดของงานทั้งหมดที่มีอยู่ โปรดดูที่ repo การประเมิน lm
GPT-NeoX ได้รับการปรับให้เหมาะสมอย่างมากสำหรับการฝึกเท่านั้น และจุดตรวจของโมเดล GPT-NeoX ไม่สามารถใช้งานร่วมกับไลบรารีการเรียนรู้เชิงลึกอื่นๆ ได้ทันที เพื่อให้โมเดลสามารถโหลดและแชร์กับผู้ใช้ได้อย่างง่ายดาย และสำหรับการส่งออกไปยังเฟรมเวิร์กอื่นๆ ที่หลากหลาย GPT-NeoX รองรับการแปลงจุดตรวจเป็นรูปแบบ Hugging Face Transformers
แม้ว่า NeoX จะรองรับการกำหนดค่าทางสถาปัตยกรรมที่แตกต่างกันจำนวนหนึ่ง รวมถึงการฝังตำแหน่ง AliBi แต่การกำหนดค่าเหล่านี้ไม่ได้ทั้งหมดจะแมปกับการกำหนดค่าที่รองรับภายใน Hugging Face Transformers ได้อย่างสมบูรณ์
NeoX รองรับการส่งออกโมเดลที่เข้ากันได้ไปยังสถาปัตยกรรมต่อไปนี้:
การฝึกโมเดลที่ไม่เข้ากับหนึ่งในสถาปัตยกรรม Hugging Face Transformers เหล่านี้อย่างสมบูรณ์ จะต้องมีการเขียนโค้ดการสร้างแบบจำลองที่กำหนดเองสำหรับโมเดลที่ส่งออก
หากต้องการแปลงจุดตรวจสอบไลบรารี GPT-NeoX เป็นรูปแบบที่โหลดได้ของ Hugging Face ให้รัน:
python ./tools/ckpts/convert_neox_to_hf.py --input_dir /path/to/model/global_stepXXX --config_file your_config.yml --output_dir hf_model/save/location --precision {auto,fp16,bf16,fp32} --architecture {neox,mistral,llama}จากนั้นหากต้องการอัปโหลดโมเดลไปยัง Hugging Face Hub ให้รัน:
huggingface-cli login
python ./tools/ckpts/upload.pyและป้อนข้อมูลที่ร้องขอ รวมถึงโทเค็นผู้ใช้ฮับ HF
NeoX จัดเตรียมโปรแกรมอรรถประโยชน์หลายอย่างสำหรับการแปลงจุดตรวจสอบแบบจำลองที่ได้รับการฝึกอบรมมาเป็นรูปแบบที่สามารถฝึกอบรมภายในห้องสมุดได้
รุ่นหรือตระกูลรุ่นต่อไปนี้สามารถโหลดได้ใน GPT-NeoX:
เรามียูทิลิตี้สองรายการสำหรับการแปลงจากรูปแบบจุดตรวจสอบที่แตกต่างกันสองรูปแบบให้เป็นรูปแบบที่เข้ากันได้กับ GPT-NeoX
หากต้องการแปลงจุดตรวจ Llama 1 หรือ Llama 2 ที่แจกจ่ายโดย Meta AI จากรูปแบบไฟล์ต้นฉบับ (ดาวน์โหลดได้ ที่นี่ หรือ ที่นี่) ลงในไลบรารี GPT-NeoX ให้เรียกใช้
python tools/ckpts/convert_raw_llama_weights_to_neox.py --input_dir /path/to/model/parent/dir/7B --model_size 7B --output_dir /path/to/save/ckpt --num_output_shards <TENSOR_PARALLEL_SIZE> (--pipeline_parallel if pipeline-parallel-size >= 1)
หากต้องการแปลงจากโมเดล Hugging Face เป็น NeoX ที่โหลดได้ ให้รัน tools/ckpts/convert_hf_to_sequential.py ดูเอกสารประกอบภายในไฟล์นั้นสำหรับตัวเลือกเพิ่มเติม
นอกเหนือจากการจัดเก็บบันทึกในเครื่องแล้ว เรายังให้การสนับสนุนในตัวสำหรับเฟรมเวิร์กการตรวจสอบการทดลองยอดนิยม 2 รายการ ได้แก่ Weights & Biases, TensorBoard และ Comet
น้ำหนักและอคติในการบันทึกการทดลองของเราเป็นแพลตฟอร์มการตรวจสอบการเรียนรู้ของเครื่อง หากต้องการใช้ wandb เพื่อติดตามการทดลอง gpt-neox ให้ทำดังนี้
wandb login การวิ่งของคุณจะถูกบันทึกโดยอัตโนมัติ./requirements/requirements-wandb.txt ตัวอย่างการกำหนดค่ามีให้ใน ./configs/local_setup_wandb.ymlwandb_group ให้คุณตั้งชื่อกลุ่มการวิ่ง และ wandb_team ให้คุณกำหนดการวิ่งของคุณให้กับบัญชีองค์กรหรือทีม ตัวอย่างการกำหนดค่ามีให้ใน ./configs/local_setup_wandb.yml เรารองรับการใช้ TensorBoard ผ่านฟิลด์ tensorboard-dir การพึ่งพาที่จำเป็นสำหรับการตรวจสอบ TensorBoard สามารถพบได้ในและติดตั้งจาก ./requirements/requirements-tensorboard.txt
Comet เป็นแพลตฟอร์มการติดตามการเรียนรู้ของเครื่อง หากต้องการใช้ดาวหางเพื่อติดตามการทดลอง gpt-neox ให้ทำดังนี้
comet login หรือส่ง export COMET_API_KEY=<your-key-here>comet_ml และไลบรารีการพึ่งพาใด ๆ ผ่านทาง pip install -r requirements/requirements-comet.txtuse_comet: True คุณยังสามารถกำหนดตำแหน่งที่จะบันทึกข้อมูลได้ด้วย comet_workspace และ comet_project ตัวอย่างการกำหนดค่าแบบเต็มที่เปิดใช้งานดาวหางมีอยู่ใน configs/local_setup_comet.yml หากคุณต้องการจัดหาไฟล์โฮสต์เพื่อใช้กับตัวเรียกใช้งาน DeepSpeed ที่ใช้ MPI คุณสามารถตั้งค่าตัวแปรสภาพแวดล้อม DLTS_HOSTFILE ให้ชี้ไปที่ไฟล์โฮสต์ได้
เรารองรับการทำโปรไฟล์ด้วย Nsight Systems, PyTorch Profiler และ PyTorch Memory Profiling
หากต้องการใช้การทำโปรไฟล์ Nsight Systems ให้ตั้ง profile ตัวเลือกการกำหนดค่าprofile , profile_step_start และ profile_step_stop (ดูที่นี่สำหรับการใช้อาร์กิวเมนต์ และที่นี่สำหรับการกำหนดค่าตัวอย่าง)
หากต้องการเติมข้อมูลเมตริก nsys ให้เริ่มการฝึกอบรมด้วย:
nsys profile -s none -t nvtx,cuda -o <path/to/profiling/output> --force-overwrite true
--capture-range=cudaProfilerApi --capture-range-end=stop python $TRAIN_PATH/deepy.py
$TRAIN_PATH/train.py --conf_dir configs <config files>
ไฟล์เอาต์พุตที่สร้างขึ้นสามารถดูได้ด้วย Nsight Systems GUI:
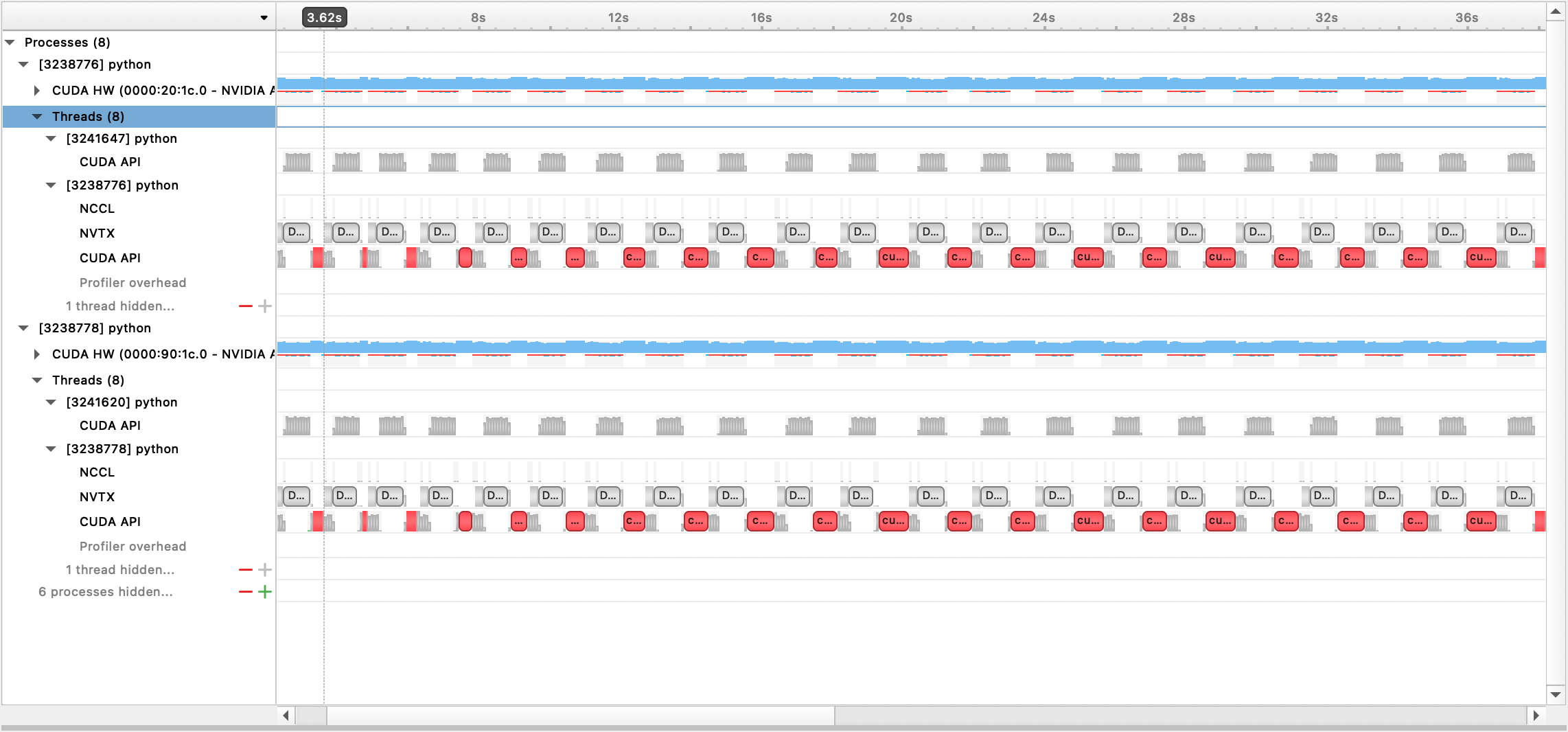
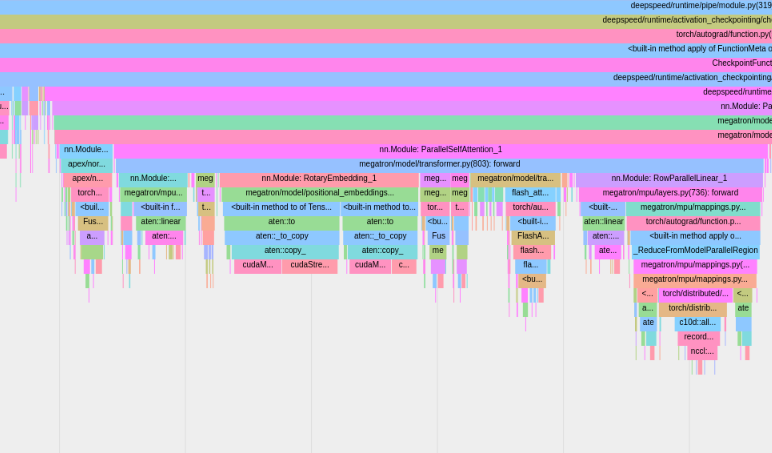
หากต้องการใช้ตัวสร้างโปรไฟล์ PyTorch ในตัว ให้ตั้งค่าตัวเลือกการกำหนดค่า profile , profile_step_start และ profile_step_stop (ดูที่นี่สำหรับการใช้อาร์กิวเมนต์ และที่นี่สำหรับการกำหนดค่าตัวอย่าง)
ตัวสร้างโปรไฟล์ PyTorch จะบันทึกการติดตามลงในไดเร็กทอรีบันทึก tensorboard ของคุณ คุณดูการติดตามเหล่านี้ภายใน TensorBoard ได้โดยทำตามขั้นตอนที่นี่
หากต้องการใช้ PyTorch Memory Profiling ให้ตั้งค่าตัวเลือกการกำหนดค่า memory_profiling และ memory_profiling_path (ดู ที่นี่ สำหรับการใช้อาร์กิวเมนต์ และ ที่นี่ สำหรับการกำหนดค่าตัวอย่าง)
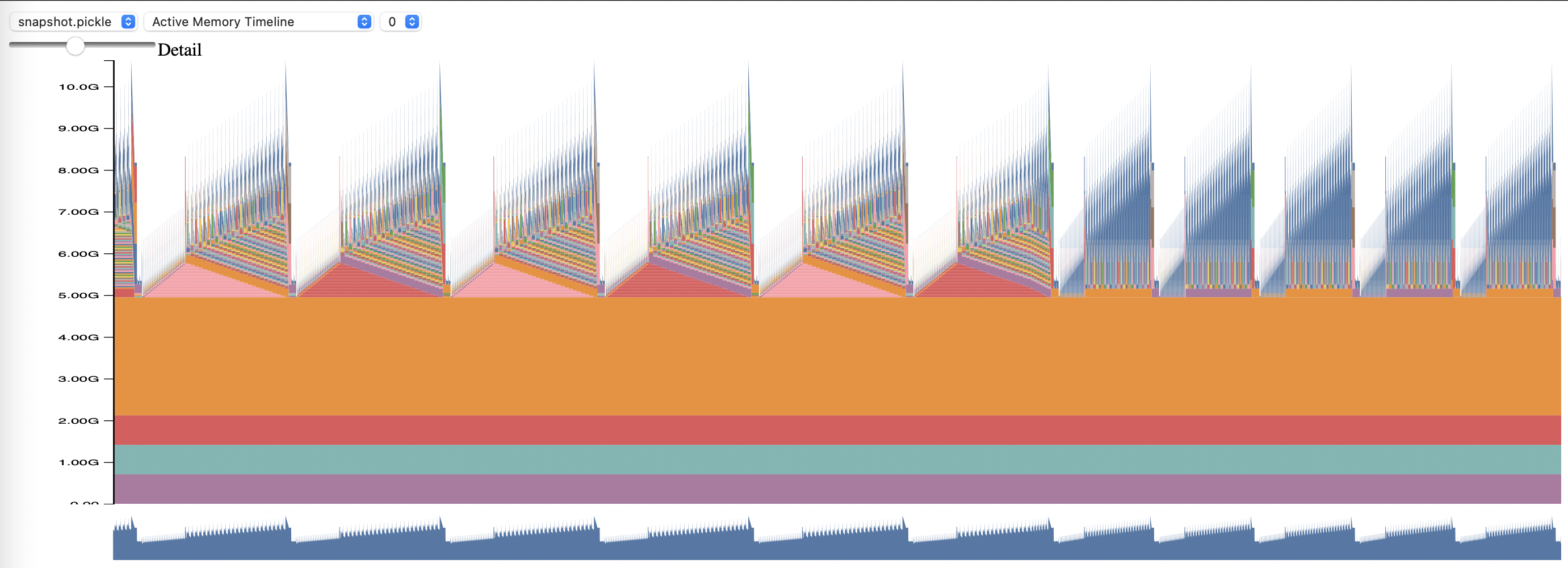
ดูโปรไฟล์ที่สร้างขึ้นด้วยสคริปต์ memory_viz.py วิ่งด้วย:
python _memory_viz.py trace_plot <generated_profile> -o trace.html
ไลบรารี GPT-NeoX ได้รับการยอมรับอย่างกว้างขวางจากนักวิจัยด้านวิชาการและอุตสาหกรรม และส่งต่อไปยังระบบ HPC จำนวนมาก
หากคุณพบว่าห้องสมุดนี้มีประโยชน์ในการวิจัยของคุณ โปรดติดต่อเราและแจ้งให้เราทราบ! เราอยากจะเพิ่มคุณเข้าไปในรายการของเรา
EleutherAI และผู้ทำงานร่วมกันของเราได้ใช้มันในสิ่งพิมพ์ต่อไปนี้:
สิ่งตีพิมพ์ต่อไปนี้โดยกลุ่มวิจัยอื่นใช้ห้องสมุดนี้:


