Awesome Attention Heads
vey on LLM attention heads
สำคัญ
เกี่ยวกับการซื้อคืนนี้ นี่คือแพลตฟอร์มเพื่อรับ การวิจัยล่าสุด เกี่ยวกับ Attention Heads ของ LLM ประเภทต่างๆ นอกจากนี้เรายังได้จัดทำ แบบสำรวจ จากผลงานที่ยอดเยี่ยมเหล่านี้อีกด้วย
หากคุณต้องการ อ้างอิงผลงานของเรา นี่คือรายการ bibtex ของเรา: CITATION.bib
หากคุณต้องการดูเฉพาะ รายการเอกสาร ที่เกี่ยวข้อง โปรดข้ามไปที่นี่โดยตรง
หากคุณต้องการสนับสนุน Repo นี้ โปรดดูที่นี่
ด้วยการพัฒนา Large Language Model (LLM) โครงสร้างเครือข่ายพื้นฐานของ Transformer ก็กำลังได้รับการศึกษาอย่างกว้างขวาง การค้นคว้าโครงสร้าง Transformer ช่วยให้เราเข้าใจ "กล่องดำ" นี้ได้ดีขึ้น และปรับปรุงการตีความโมเดลได้ เมื่อเร็วๆ นี้ มีงานจำนวนมากขึ้นที่แนะนำว่าแบบจำลองประกอบด้วยสองพาร์ติชันที่แตกต่างกัน ได้แก่ กลไกความสนใจที่ใช้สำหรับพฤติกรรม การอนุมาน และการวิเคราะห์ และ Feed-Forward Networks (FFN) สำหรับการจัดเก็บความรู้ แบบแรกมีความสำคัญอย่างยิ่งต่อการเปิดเผยความสามารถในการทำงานของแบบจำลอง ซึ่งนำไปสู่การศึกษาชุดหนึ่งที่สำรวจฟังก์ชันต่างๆ ภายในกลไกความสนใจ ซึ่งเราเรียกว่า Attention Head Mining
ในแบบสำรวจนี้ เราเจาะลึกถึงกลไกที่เป็นไปได้ว่าความสนใจใน LLM มีส่วนช่วยในกระบวนการให้เหตุผลอย่างไร
ไฮไลท์:
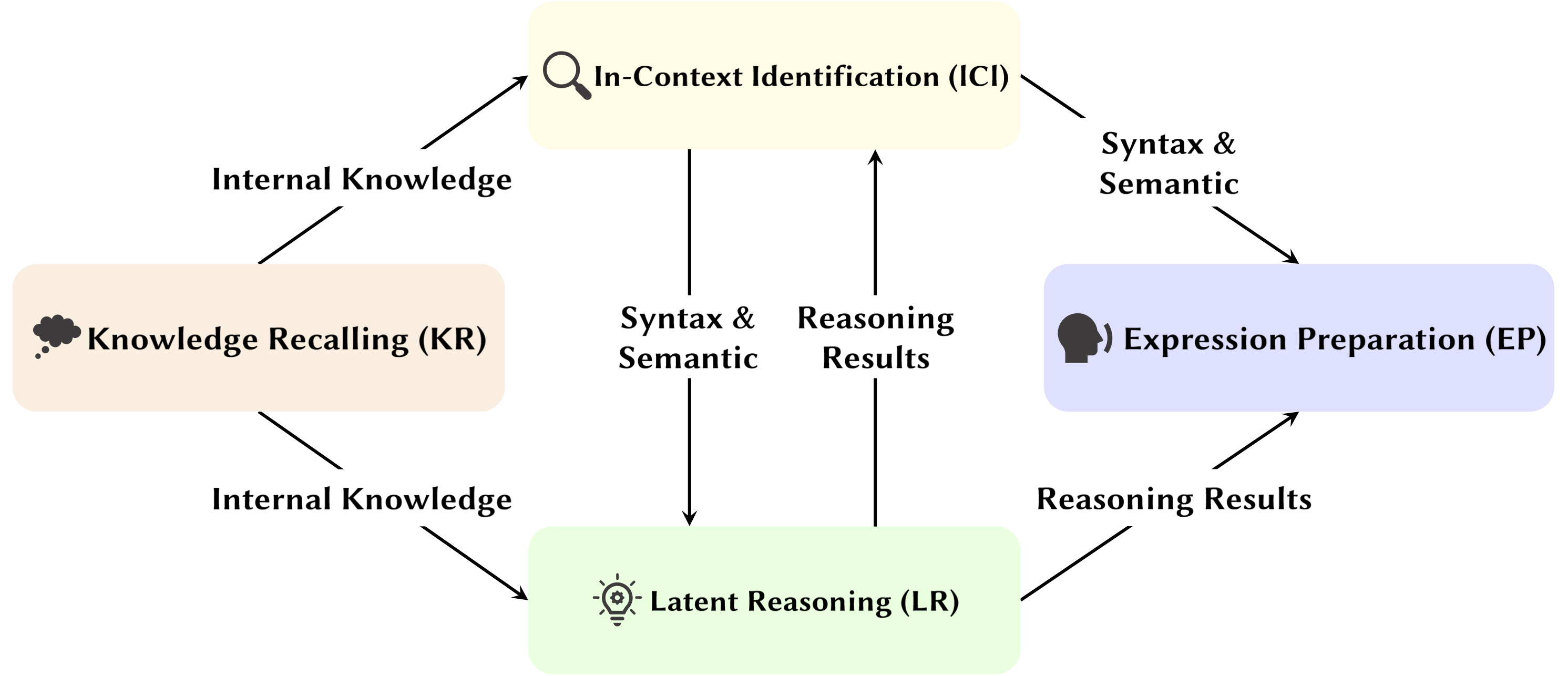
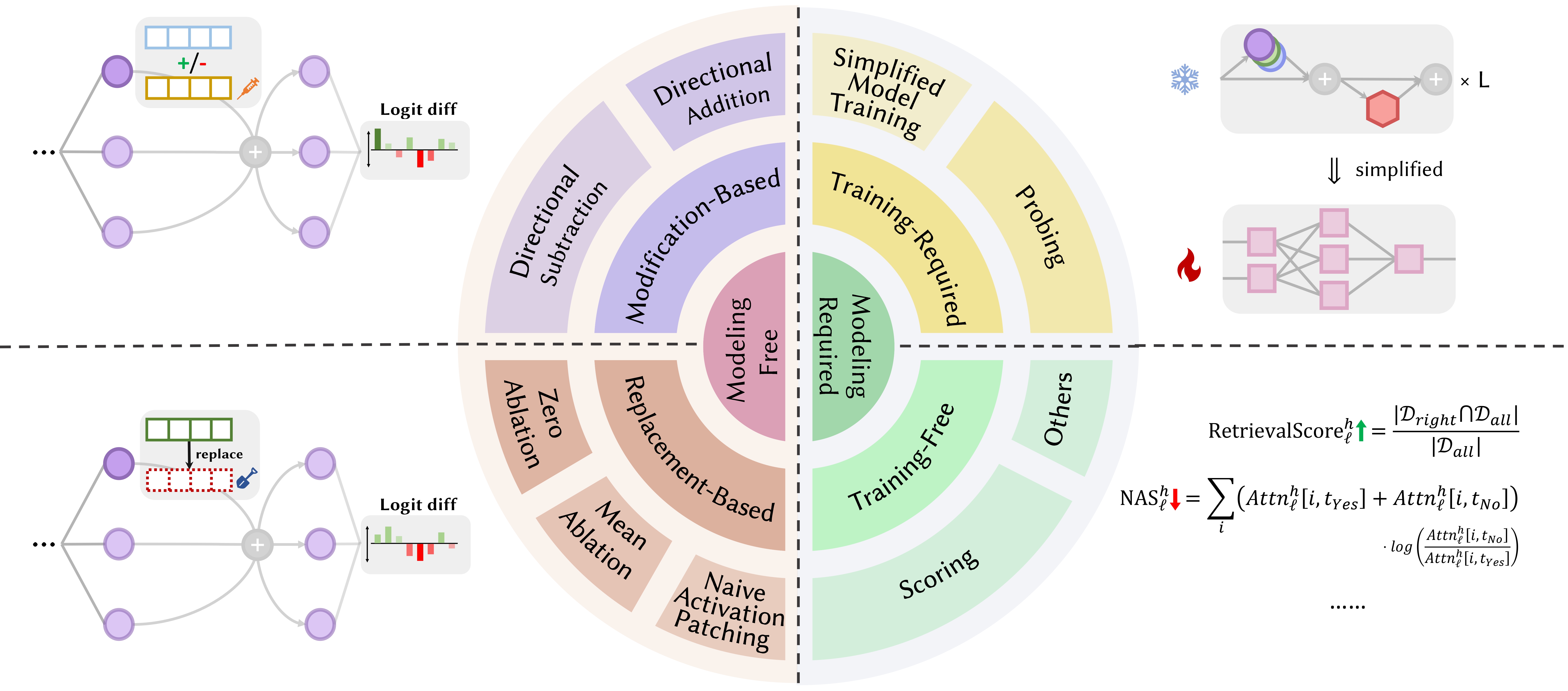
เอกสารด้านล่างนี้เรียงลำดับตาม วันที่ตีพิมพ์ :
ปี 2567
| วันที่ | กระดาษและบทสรุป | แท็ก | ลิงค์ |
| 15-11-2567 | SEEKR: การเก็บรักษาความรู้แบบเน้นความสนใจแบบเลือกสรรเพื่อการเรียนรู้อย่างต่อเนื่องของแบบจำลองภาษาขนาดใหญ่ | ||
| • เสนอ SEEKR ซึ่งเป็นวิธีเก็บรักษาความรู้ที่เน้นความสนใจแบบเลือกสรรสำหรับการเรียนรู้อย่างต่อเนื่องใน LLM โดยมุ่งเน้นที่หัวความสนใจหลักเพื่อการกลั่นที่มีประสิทธิภาพ • ประเมินผลการเรียนรู้อย่างต่อเนื่อง TRACE และ SuperNI • SEEKR ได้รับประสิทธิภาพที่เทียบเคียงหรือดีกว่าด้วยข้อมูลการเล่นซ้ำเพียง 1% เมื่อเทียบกับวิธีอื่น | |||
| 06-11-2024 | Transformers แก้ปัญหาลอจิกเชิงประพจน์ได้อย่างไร: การวิเคราะห์เชิงกลไก | ||
| • ระบุวงจรความสนใจเฉพาะในหม้อแปลงที่แก้ปัญหาตรรกะเชิงประพจน์ โดยเน้นที่กลไก "การวางแผน" และ "การให้เหตุผล" • วิเคราะห์หม้อแปลงขนาดเล็กและ Mistral-7B โดยใช้แพตช์การเปิดใช้งานเพื่อเปิดเผยเส้นทางการให้เหตุผล • พบหัวหน้าความสนใจที่แตกต่างกันซึ่งเชี่ยวชาญด้านตำแหน่งของกฎ การประมวลผลข้อเท็จจริง และการตัดสินใจในการใช้เหตุผลเชิงตรรกะ | |||
| 01-11-2024 | Attention Tracker: การตรวจจับการโจมตีแบบฉีดพร้อมท์ใน LLM | ||
| • Proposed Attention Tracker ซึ่งเป็นเครื่องป้องกันที่เรียบง่ายแต่ไร้การฝึกอบรมที่มีประสิทธิภาพ ซึ่งจะตรวจจับการโจมตีแบบฉีดทันทีโดยพิจารณาจากหัวที่สำคัญที่ระบุ • ระบุหัวที่สำคัญโดยใช้ประโยคสุ่มที่สร้างโดย LLM ชุดเล็กๆ รวมกับการโจมตีแบบเพิกเฉยที่ไร้เดียงสา • Attention Tracker มีผลกับ LM ทั้งขนาดเล็กและขนาดใหญ่ โดยระบุข้อจำกัดที่สำคัญของวิธีการตรวจจับโดยไม่ต้องผ่านการฝึกอบรมก่อนหน้านี้ | |||
| 28-10-2024 | เลขคณิตที่ไม่มีอัลกอริธึม: โมเดลภาษาแก้คณิตศาสตร์ด้วยถุงแห่งการเรียนรู้ | ||
| • ระบุชุดย่อยของแบบจำลอง (วงจร) ที่อธิบายพฤติกรรมส่วนใหญ่ของแบบจำลองสำหรับตรรกะทางคณิตศาสตร์พื้นฐาน และตรวจสอบการทำงานของแบบจำลอง • วิเคราะห์รูปแบบความสนใจโดยใช้พรอมต์เลขคณิตสองตัวถูกดำเนินการด้วยเลขอารบิคและตัวดำเนินการพื้นฐานสี่ตัว (+, −, ×, ۞) • สำหรับการบวก การลบ และการหาร หัวสนใจ 6 หัวจะให้ความเที่ยงตรงสูง (โดยเฉลี่ย 97%) ในขณะที่การคูณต้องใช้ 20 หัวจึงจะมีความเที่ยงตรงเกิน 90% | |||
| 21-10-2024 | การประเมินทางจิตวิทยาเกี่ยวกับความไวของแบบจำลองภาษาต่อบทบาทการโต้แย้ง | ||
| • สังเกตหัวเรื่องในสภาพแวดล้อมที่เป็นภาพรวมมากขึ้น • วิเคราะห์รูปแบบความสนใจภายใต้เงื่อนไขของการแลกเปลี่ยนอาร์กิวเมนต์และการแทนที่อาร์กิวเมนต์ • แม้ว่าจะสามารถแยกแยะบทบาทได้ แต่โมเดลอาจประสบปัญหาในการใช้ข้อมูลบทบาทอาร์กิวเมนต์อย่างถูกต้อง เนื่องจากปัญหาอยู่ที่ว่าข้อมูลนี้ถูกเข้ารหัสเป็นการแสดงคำกริยาอย่างไร ส่งผลให้ความละเอียดอ่อนของบทบาทลดลง | |||
| 10-10-2024 | หัวหน้าความสนใจที่ไม่เคลื่อนไหวและอยู่เฉยๆ: ปรากฏการณ์โทเคนสุดขีดที่ทำให้เกิดความลึกลับอย่างมีกลไกใน LLM | ||
| • แสดงให้เห็นว่าปรากฏการณ์ที่รุนแรงเกิดขึ้นจากกลไกที่ทำงานอยู่เฉยๆ ในหัวความสนใจ ควบคู่ไปกับกลไกการเสริมกำลังซึ่งกันและกันระหว่างการฝึกล่วงหน้า • การใช้หม้อแปลงแบบธรรมดาที่ได้รับการฝึกอบรมเกี่ยวกับงาน Bigram-Backcopy (BB) เพื่อวิเคราะห์ปรากฏการณ์โทเค็นที่รุนแรง และขยายไปยัง LLM ที่ได้รับการฝึกอบรมล่วงหน้า • คุณสมบัติคงที่และไดนามิกหลายประการของปรากฏการณ์โทเค็นสุดขั้วที่ทำนายโดยงาน BB สอดคล้องกับการสังเกตใน LLM ที่ได้รับการฝึกล่วงหน้า | |||
| 10-10-2024 | ในบทบาทของผู้นำความสนใจในความปลอดภัยของโมเดลภาษาขนาดใหญ่ | ||
| • เสนอตัวชี้วัดใหม่ซึ่งปรับให้เหมาะกับความสนใจแบบหลายหัว ซึ่งก็คือคะแนนความสำคัญของหัวหน้าด้านความปลอดภัย (เรือ) เพื่อประเมินการมีส่วนร่วมของหัวหน้าแต่ละคนต่อความปลอดภัยของแบบจำลอง • ดำเนินการวิเคราะห์การทำงานของหัวแจ้งเตือนด้านความปลอดภัยเหล่านี้ โดยสำรวจคุณลักษณะและกลไกต่างๆ • หัวความสนใจบางอย่างมีความสำคัญอย่างยิ่งต่อความปลอดภัย หัวนิรภัยซ้อนทับกันในรุ่นที่ปรับแต่งมาอย่างดี และการระเหยหัวเหล่านี้จะส่งผลกระทบน้อยที่สุดต่อความช่วยเหลือ | |||
| 14-10-2024 | DuoAttention: การอนุมาน LLM บริบทแบบยาวที่มีประสิทธิภาพพร้อมหัวดึงข้อมูลและสตรีมมิ่ง | ||
| • เปิดตัว DuoAttention ซึ่งเป็นเฟรมเวิร์กที่ช่วยลดทั้งการถอดรหัสและการเติมหน่วยความจำล่วงหน้าของ LLM และความหน่วงโดยไม่กระทบต่อความสามารถในบริบทแบบยาว โดยอิงจากการค้นพบ Retrieval Heads และ Streaming Heads ภายใน LLM • ทดสอบผลกระทบของกรอบงานต่อประสิทธิภาพของ LLM ในงานทั้งบริบทสั้นและยาว ตลอดจนประสิทธิภาพการอนุมาน • ด้วยการใช้แคช KV เต็มรูปแบบกับการดึงข้อมูลส่วนหัวเท่านั้น DuoAttention จะลดการใช้หน่วยความจำและเวลาแฝงลงอย่างมากสำหรับทั้งการถอดรหัสและการกรอกข้อมูลล่วงหน้าในแอปพลิเคชันที่มีบริบทยาว | |||
| 14-10-2024 | การล็อคความปลอดภัยของ LLM ที่ได้รับการปรับแต่งอย่างละเอียด | ||
| • แนะนำ SafetyLock ซึ่งเป็นวิธีการใหม่และมีประสิทธิภาพในการรักษาความปลอดภัยของโมเดลภาษาขนาดใหญ่ที่ได้รับการปรับแต่งอย่างละเอียดในระดับความเสี่ยงและสถานการณ์การโจมตีต่างๆ โดยอิงจากการค้นพบ Safety Heads ภายใน LLM • ประเมินประสิทธิผลของ SafetyLock ในการเพิ่มความปลอดภัยของโมเดลและประสิทธิภาพการอนุมาน • ด้วยการใช้เวคเตอร์การแทรกแซงกับส่วนหัวด้านความปลอดภัย SafetyLock สามารถปรับเปลี่ยนการเปิดใช้งานภายในของโมเดลไปสู่ความไม่เป็นอันตรายในระหว่างการอนุมาน เพื่อให้บรรลุการจัดตำแหน่งความปลอดภัยที่แม่นยำโดยมีผลกระทบต่อการตอบสนองน้อยที่สุด | |||
| 11-10-2024 | สิ่งเดียวกันแต่แตกต่าง: ความเหมือนและความแตกต่างทางโครงสร้างในการสร้างแบบจำลองภาษาหลายภาษา | ||
| • ดำเนินการศึกษาเชิงลึกเกี่ยวกับส่วนประกอบเฉพาะที่แบบจำลองหลายภาษาใช้เมื่อปฏิบัติงานที่ต้องใช้กระบวนการทางสัณฐานวิทยาเฉพาะภาษา • ตรวจสอบความแตกต่างด้านการทำงานของส่วนประกอบแบบจำลองภายในเมื่อปฏิบัติงานเป็นภาษาอังกฤษและภาษาจีน • Copy head มีความถี่ในการเปิดใช้งานสูงพอๆ กันในทั้งสองภาษา ในขณะที่ Past tense head มักเปิดใช้งานในภาษาอังกฤษเท่านั้น | |||
| 08-10-2024 | กลมแล้วรอบเราไป! อะไรทำให้การเข้ารหัสตำแหน่งแบบโรตารีมีประโยชน์ | ||
| • ให้การวิเคราะห์เชิงลึกเกี่ยวกับภายในของโมเดล Gemma 7B ที่ได้รับการฝึกอบรมเพื่อทำความเข้าใจวิธีการใช้ RoPE ในระดับกลไก • เข้าใจการใช้ความถี่ที่แตกต่างกันในการสืบค้นและคีย์ • พบว่าความถี่สูงสุดใน RoPE ถูกใช้อย่างชาญฉลาดโดย Gemma 7B เพื่อสร้างส่วนหัวความสนใจ 'ตำแหน่ง' พิเศษ (หัวทแยงมุม, หัวโทเค็นก่อนหน้า) ในขณะที่ความถี่ต่ำถูกใช้โดยหัว Apostrophe | |||
| 06-10-2024 | ทบทวนวงจรอนุมานการเรียนรู้ในบริบทในแบบจำลองภาษาขนาดใหญ่ | ||
| • เสนอวงจรอนุมาน 3 ขั้นตอนที่ครอบคลุมเพื่อระบุลักษณะกระบวนการอนุมานของ ICL • แบ่ง ICL ออกเป็นสามขั้นตอน: สรุป, ผสานความหมาย และดึงข้อมูลและคัดลอกคุณลักษณะ วิเคราะห์บทบาทแต่ละขั้นตอนใน ICL และกลไกการปฏิบัติงาน • พบว่าก่อน Induction Heads Forerunner Token Heads จะรวมการแสดงข้อความสาธิตจากโทเค็น forerunner เข้ากับโทเค็นป้ายกำกับที่เกี่ยวข้องก่อน โดยคัดเลือกโดยพิจารณาจากความเข้ากันได้ระหว่างการสาธิตและซีแมนทิกส์ของป้ายกำกับ | |||
| 01-10-2024 | การสลายตัวของความสนใจแบบกระจัดกระจายนำไปใช้กับการติดตามวงจร | ||
| • เปิดตัว Sparse Attention Decomposition โดยใช้ SVD บนเมทริกซ์ Attention Head เพื่อติดตามเส้นทางการสื่อสารในโมเดล GPT-2 • นำไปใช้กับการติดตามวงจรใน GPT-2 ขนาดเล็กสำหรับงาน Indirect Object Identification (IOI) • ระบุสัญญาณการสื่อสารที่มีนัยสำคัญกระจัดกระจายระหว่างหัวความสนใจ ปรับปรุงความสามารถในการตีความ | |||
| 2024-09-09 | เปิดตัวหัวเหนี่ยวนำ: พลวัตการฝึกอบรมที่พิสูจน์ได้และการเรียนรู้คุณลักษณะใน Transformers | ||
| • บทความนี้แนะนำกลไกส่วนหัวการเหนี่ยวนำทั่วไป โดยอธิบายว่าส่วนประกอบของหม้อแปลงทำงานร่วมกันเพื่อดำเนินการเรียนรู้ในบริบท (ICL) บนโซ่มาร์คอฟ n-gram ได้อย่างไร • จะวิเคราะห์หม้อแปลงแบบให้ความสนใจสองชั้นพร้อมโฟลว์แบบไล่ระดับเพื่อทำนายโทเค็นในสายโซ่มาร์คอฟ • การไหลแบบไล่ระดับมาบรรจบกัน ช่วยให้ ICL ผ่านกลไกหัวเหนี่ยวนำตามคุณลักษณะที่เรียนรู้ | |||
| 16-08-2024 | การตีความเชิงกลไกของการให้เหตุผลแบบตรรกศาสตร์ในแบบจำลองภาษาแบบถดถอยอัตโนมัติ | ||
| • การศึกษาแนะนำการตีความเชิงกลไกของการให้เหตุผลเชิงเหตุผลใน LM โดยระบุวงจรการให้เหตุผลที่ไม่ขึ้นกับเนื้อหา • การค้นพบวงจรเพื่อหาเหตุผลและตรวจสอบการปนเปื้อนของอคติในความเชื่อในหัวความสนใจ • ระบุวงจรการให้เหตุผลที่จำเป็นที่สามารถถ่ายทอดข้ามรูปแบบการอ้างเหตุผลได้ แต่เสี่ยงต่อการปนเปื้อนจากความรู้ของโลกที่ได้รับการฝึกอบรมล่วงหน้า | |||
| 01-08-2024 | การเพิ่มความสอดคล้องทางความหมายของโมเดลภาษาขนาดใหญ่ผ่านการแก้ไขโมเดล: แนวทางที่เน้นการตีความ | ||
| • แนะนำแนวทางการแก้ไขแบบจำลองที่คุ้มค่าโดยเน้นที่หัวความสนใจเพื่อเพิ่มความสอดคล้องทางความหมายใน LLM โดยไม่ต้องเปลี่ยนแปลงพารามิเตอร์อย่างกว้างขวาง • วิเคราะห์หัวความสนใจ ใส่อคติ และทดสอบกับชุดข้อมูล NLU และ NLG • บรรลุการปรับปรุงที่โดดเด่นในด้านความสอดคล้องทางความหมายและประสิทธิภาพของงาน โดยมีภาพรวมที่ชัดเจนในงานเพิ่มเติม | |||
| 31-07-2024 | การแก้ไขอคติเชิงลบในแบบจำลองภาษาขนาดใหญ่ผ่านการจัดตำแหน่งคะแนนความสนใจเชิงลบ | ||
| • เปิดตัวคะแนนความสนใจเชิงลบ (NAS) เพื่อหาปริมาณและแก้ไขอคติเชิงลบในแบบจำลองภาษา • ระบุหัวความสนใจที่มีอคติเชิงลบและเสนอการจัดคะแนนความสนใจเชิงลบ (NASA) เพื่อการปรับแต่งอย่างละเอียด • NASA ลดช่องว่างการเรียกคืนที่แม่นยำได้อย่างมีประสิทธิภาพ ในขณะที่ยังคงลักษณะทั่วไปในงานการตัดสินใจแบบไบนารี่ | |||
| 29-07-2024 | การตรวจจับและทำความเข้าใจช่องโหว่ในโมเดลภาษาผ่านการตีความเชิงกลไก | ||
| • แนะนำวิธีการโดยใช้ Mechanistic Interpretability (MI) เพื่อตรวจจับและทำความเข้าใจช่องโหว่ใน LLM โดยเฉพาะการโจมตีจากฝ่ายตรงข้าม • วิเคราะห์ GPT-2 Small เพื่อหาช่องโหว่ในการทำนายคำย่อ 3 ตัวอักษร • ระบุและอธิบายจุดอ่อนเฉพาะในรูปแบบที่เกี่ยวข้องกับงานได้สำเร็จ | |||
| 22-07-2024 | RazorAttention: การบีบอัดแคช KV ที่มีประสิทธิภาพผ่านหัวดึงข้อมูล | ||
| • เปิดตัว RazorAttention ซึ่งเป็นเทคนิคการบีบอัดแคช KV ที่ไม่ต้องใช้การฝึกอบรม โดยใช้หัวดึงข้อมูลและโทเค็นการชดเชยเพื่อรักษาข้อมูลโทเค็นที่สำคัญ • ประเมิน RazorAttention บนโมเดลภาษาขนาดใหญ่ (LLM) เพื่อประสิทธิภาพ • สามารถลดขนาดแคช KV ลงได้มากกว่า 70% โดยไม่ส่งผลกระทบต่อประสิทธิภาพที่เห็นได้ชัดเจน | |||
| 21-07-2024 | ตอบ รวบรวม เอซ: ทำความเข้าใจว่า Transformers ตอบคำถามแบบเลือกตอบอย่างไร | ||
| • บทความนี้แนะนำการฉายคำศัพท์และการเปิดใช้งานแพตช์เพื่อระบุสถานะที่ซ่อนอยู่ซึ่งทำนายคำตอบ MCQA ที่ถูกต้อง • ระบุหัวและชั้นความสนใจหลักที่รับผิดชอบในการเลือกคำตอบในหม้อแปลงไฟฟ้า • หัวความสนใจในเลเยอร์กลางมีความสำคัญอย่างยิ่งต่อการคาดเดาคำตอบที่แม่นยำ โดยหัวที่กระจัดกระจายมีบทบาทเฉพาะตัว | |||
| 09-07-2024 | หัวเหนี่ยวนำเป็นกลไกสำคัญสำหรับการจับคู่รูปแบบในการเรียนรู้ในบริบท | ||
| • บทความนี้ระบุว่าหัวการปฐมนิเทศมีความสำคัญต่อการจับคู่รูปแบบในการเรียนรู้ในบริบท (ICL) • ประเมิน Llama-3-8B และ InternLM2-20B เกี่ยวกับการจดจำรูปแบบนามธรรมและงาน NLP • การระเหยหัวเหนี่ยวนำจะลดประสิทธิภาพของ ICL ลงถึง ~32% ทำให้ประสิทธิภาพใกล้เคียงกับการสุ่มเพื่อการจดจำรูปแบบ | |||
| 02-07-2024 | การตีความกลไกเลขคณิตในแบบจำลองภาษาขนาดใหญ่ผ่านการวิเคราะห์เซลล์ประสาทเปรียบเทียบ | ||
| • เปิดตัวการวิเคราะห์เปรียบเทียบเซลล์ประสาท (CNA) เพื่อสร้างแผนผังกลไกทางคณิตศาสตร์ในหัวความสนใจของแบบจำลองภาษาขนาดใหญ่ • วิเคราะห์ความสามารถทางคณิตศาสตร์ การตัดแต่งแบบจำลองสำหรับงานทางคณิตศาสตร์ และการแก้ไขแบบจำลองเพื่อลดอคติทางเพศ • ระบุเซลล์ประสาทเฉพาะที่รับผิดชอบด้านเลขคณิต ทำให้สามารถปรับปรุงประสิทธิภาพและบรรเทาอคติผ่านการจัดการเซลล์ประสาทแบบกำหนดเป้าหมาย | |||
| 01-07-2024 | ควบคุมโมเดลภาษาขนาดใหญ่สำหรับการดึงข้อมูลข้ามภาษา | ||
| • เปิดตัวการเปิดใช้งานการดึงข้อมูลหลายภาษาแบบนำทาง (ASMR) โดยใช้การเปิดใช้งานการบังคับเลี้ยวเพื่อเป็นแนวทาง LLM เพื่อการดึงข้อมูลข้ามภาษาที่ได้รับการปรับปรุง • ระบุหัวความสนใจใน LLM ที่ส่งผลต่อความถูกต้องและการเชื่อมโยงทางภาษา และการเปิดใช้งานระบบบังคับเลี้ยวที่ใช้ • ASMR บรรลุประสิทธิภาพที่ล้ำสมัยบนเกณฑ์มาตรฐาน CLIR เช่น XOR-TyDi QA และ MKQA | |||
| 25-06-2024 | Transformers เรียนรู้โครงสร้างสาเหตุด้วยการไล่ระดับสีอย่างไร | ||
| • ให้คำอธิบายว่าหม้อแปลงเรียนรู้โครงสร้างเชิงสาเหตุผ่านอัลกอริธึมการฝึกแบบไล่ระดับได้อย่างไร • วิเคราะห์ประสิทธิภาพของหม้อแปลงสองชั้นในงานที่เรียกว่าลำดับสุ่มพร้อมโครงสร้างเชิงสาเหตุ • การไล่ระดับไล่ระดับบนหม้อแปลงสองชั้นแบบง่าย เรียนรู้ที่จะแก้ปัญหานี้โดยการเข้ารหัสกราฟสาเหตุแฝงในชั้นความสนใจแรก เป็นกรณีพิเศษ เมื่อลำดับถูกสร้างขึ้นจากห่วงโซ่มาร์คอฟในบริบท หม้อแปลงจะเรียนรู้ที่จะพัฒนาหัวเหนี่ยวนำ | |||
| 21-06-2024 | MoA: การผสมผสานของความสนใจแบบเบาบางสำหรับการบีบอัดโมเดลภาษาขนาดใหญ่อัตโนมัติ | ||
| • บทความนี้แนะนำ Mixture of Attention (MoA) ซึ่งปรับแต่งการกำหนดค่าความสนใจแบบกระจัดกระจายที่แตกต่างกันสำหรับส่วนหัวและเลเยอร์ที่แตกต่างกัน เพิ่มประสิทธิภาพหน่วยความจำ ปริมาณงาน และการแลกเปลี่ยนความแม่นยำ-ความหน่วง • โมเดลโปรไฟล์ MoA สำรวจการกำหนดค่าความสนใจ และปรับปรุงการบีบอัด LLM • MoA เพิ่มความยาวบริบทที่มีประสิทธิภาพ 3.9× ในขณะที่ลดการใช้หน่วยความจำ GPU ลง 1.2-1.4× | |||
| 19-06-2024 | เรื่องความยากของการให้เหตุผลแบบลูกโซ่แห่งความคิดที่ซื่อสัตย์ในแบบจำลองภาษาขนาดใหญ่ | ||
| • แนะนำกลยุทธ์ใหม่สำหรับการเรียนรู้ในบริบท การปรับแต่ง และการแก้ไขการเปิดใช้งานเพื่อปรับปรุงความซื่อสัตย์ของการใช้เหตุผลแบบ Chain-of-Thought (CoT) ใน LLM • ทดสอบกลยุทธ์เหล่านี้กับเกณฑ์มาตรฐานต่างๆ เพื่อประเมินประสิทธิผล • พบว่าประสบความสำเร็จอย่างจำกัดในการเพิ่มความน่าเชื่อถือของ CoT โดยเน้นถึงความท้าทายในการบรรลุการให้เหตุผลที่ซื่อสัตย์อย่างแท้จริงใน LLM | |||
| 04-06-2024 | หัวหน้าฝ่ายวนซ้ำ: การศึกษากลไกของห่วงโซ่แห่งความคิด | ||
| • เปิดตัว "หัวเรื่องวนซ้ำ" ซึ่งเป็นหัวความสนใจเฉพาะที่ช่วยให้การให้เหตุผลซ้ำในหม้อแปลงสำหรับงานลูกโซ่แห่งความคิด (CoT) • การวิเคราะห์กลไกความสนใจ การติดตามการเกิดขึ้นของ CoT และการทดสอบความสามารถในการถ่ายโอนทักษะของ CoT ระหว่างงานต่างๆ • ส่วนหัวของวนซ้ำสนับสนุนการให้เหตุผล CoT ได้อย่างมีประสิทธิภาพ ปรับปรุงความสามารถในการตีความแบบจำลองและประสิทธิภาพของงาน | |||
| 03-06-2024 | LoFiT: การปรับแต่งแบบละเอียดในการนำเสนอ LLM | ||
| • แนะนำการปรับแต่งแบบละเอียดเฉพาะท้องถิ่นในการนำเสนอ LLM (LoFiT) ซึ่งเป็นเฟรมเวิร์กสองขั้นตอนเพื่อระบุส่วนหัวของความสนใจที่สำคัญของงานที่กำหนด และเรียนรู้เวกเตอร์ออฟเซ็ตเฉพาะงานเพื่อแทรกแซงการแสดงของส่วนหัวที่ระบุ • ระบุชุดความสนใจที่สำคัญกระจัดกระจายเพื่อปรับปรุงความแม่นยำต่อเนื่องในด้านความจริงและการใช้เหตุผล • LoFiT มีประสิทธิภาพเหนือกว่าวิธีการแทรกแซงแบบเป็นตัวแทนอื่นๆ และบรรลุประสิทธิภาพที่เทียบเคียงได้กับวิธี PEFT บน TruthfulQA, CLUTRR และ MQuAKE แม้ว่าจะแทรกแซงเพียง 10% ของหัวความสนใจทั้งหมดใน LLM ก็ตาม | |||
| 28-05-2024 | วงจรความรู้ในหม้อแปลงที่ผ่านการฝึกอบรมมาแล้ว | ||
| • แนะนำ "วงจรความรู้" ในหม้อแปลงไฟฟ้า ซึ่งเผยให้เห็นว่าความรู้เฉพาะเจาะจงได้รับการเข้ารหัสอย่างไรผ่านการมีปฏิสัมพันธ์ระหว่างหัวความสนใจ หัวหน้าความสัมพันธ์ และ MLP • วิเคราะห์ GPT-2 และ TinyLLAMA เพื่อระบุวงจรความรู้ ประเมินเทคนิคการแก้ไขความรู้ • แสดงให้เห็นว่าวงจรความรู้มีส่วนทำให้เกิดพฤติกรรมแบบจำลอง เช่น ภาพหลอน และการเรียนรู้ในบริบทได้อย่างไร | |||
| 23-05-2024 | การเชื่อมโยงการเรียนรู้ในบริบทใน Transformers กับหน่วยความจำ Episodic ของมนุษย์ | ||
| • เชื่อมโยงการเรียนรู้ในบริบทในโมเดล Transformer เข้ากับหน่วยความจำฉากของมนุษย์ โดยเน้นความคล้ายคลึงกันระหว่างหัวเหนี่ยวนำและโมเดลการบำรุงรักษาและการดึงข้อมูลตามบริบท (CMR) • การวิเคราะห์ LLM ที่ใช้ Transformer เพื่อแสดงพฤติกรรมคล้าย CMR ในหัวความสนใจ • หัวที่มีลักษณะคล้าย CMR โผล่ขึ้นมาในชั้นกลาง สะท้อนถึงอคติด้านความจำของมนุษย์ | |||
| 07-05-2024 | GPT-2 ทำนายคำย่ออย่างไร การแยกและการทำความเข้าใจวงจรผ่านการตีความเชิงกลไก | ||
| • การศึกษาความสามารถในการตีความเชิงกลไกครั้งแรกบน GPT-2 สำหรับการทำนายคำย่อหลายโทเค็นโดยใช้หัวความสนใจ • ระบุและตีความวงจรของหัวความสนใจ 8 หัวที่รับผิดชอบในการทำนายคำย่อ • แสดงให้เห็นว่า 8 หัวเหล่านี้ (~ 5% ของทั้งหมด) มีสมาธิกับฟังก์ชันการทำนายด้วยตัวย่อ | |||
| 02-05-2024 | การตีความและปรับปรุงแบบจำลองภาษาขนาดใหญ่ในการคำนวณทางคณิตศาสตร์ | ||
| • แนะนำการตรวจสอบโดยละเอียดเกี่ยวกับกลไกภายในของ LLM ผ่านงานทางคณิตศาสตร์ ตามไปป์ไลน์ 'ระบุ-วิเคราะห์-ละเอียด' • วิเคราะห์ความสามารถของแบบจำลองในการทำงานทางคณิตศาสตร์ที่เกี่ยวข้องกับตัวถูกดำเนินการสองตัว เช่น การบวก การลบ การคูณ และการหาร • พบว่า LLM มักเกี่ยวข้องกับเศษส่วนเล็กน้อย (< 5%) ของส่วนหัวความสนใจ ซึ่งมีบทบาทสำคัญในการมุ่งเน้นไปที่ตัวถูกดำเนินการและตัวดำเนินการในระหว่างกระบวนการคำนวณ | |||
| 02-05-2024 | หัวเหนี่ยวนำต้องทำอย่างไร? การศึกษากลไกของวงจรการเรียนรู้ในบริบทและการก่อตัว | ||
| • แนะนำกรอบการทำงานเชิงสาเหตุที่ได้รับแรงบันดาลใจจากออพโตเจเนติกส์ เพื่อศึกษาการก่อตัวของหัวเหนี่ยวนำ (IH) ในหม้อแปลงไฟฟ้า • วิเคราะห์การเกิดขึ้นของ IH ในหม้อแปลงโดยใช้ข้อมูลสังเคราะห์ และระบุวงจรย่อยพื้นฐานสามตัวที่รับผิดชอบในการสร้าง IH • ค้นพบว่าวงจรย่อยเหล่านี้โต้ตอบเพื่อขับเคลื่อนการก่อตัวของ IH ซึ่งสอดคล้องกับการเปลี่ยนแปลงเฟสในการสูญเสียแบบจำลอง | |||
| 24-04-2024 | หัวหน้าการดึงข้อมูลจะอธิบายข้อเท็จจริงตามบริบทแบบยาวอย่างมีกลไก | ||
| • ระบุ "หัวดึง" ในโมเดลหม้อแปลงที่รับผิดชอบในการดึงข้อมูลข้ามบริบทที่ยาว • การตรวจสอบอย่างเป็นระบบของหัวดึงข้อมูลในแบบจำลองต่างๆ รวมถึงการวิเคราะห์บทบาทของพวกเขาในการให้เหตุผลแบบลูกโซ่แห่งความคิด • การตัดแต่งหัวดึงข้อมูลจะทำให้เกิดอาการประสาทหลอน ในขณะที่การตัดแต่งหัวดึงข้อมูลไม่ได้จะไม่ส่งผลต่อความสามารถในการดึงข้อมูล | |||
| 27-03-2024 | การแทรกแซงเวลาอนุมานแบบไม่เชิงเส้น: การปรับปรุงความจริงของ LLM | ||
| • แนะนำการแทรกแซงเวลาการอนุมานแบบไม่เชิงเส้น (NL-ITI) ซึ่งเพิ่มความเป็นจริงของ LLM โดยการตรวจสอบและการแทรกแซงหลายโทเค็นโดยไม่มีการปรับแต่งอย่างละเอียด • ประเมิน NL-ITI บนชุดข้อมูลแบบปรนัย รวมถึง TruthfulQA • ได้รับการปรับปรุงสัมพัทธ์ 16% ในความแม่นยำ MC1 บน TruthfulQA เหนือ ITI พื้นฐาน | |||
| 28-02-2024 | วิธีคิดทีละขั้นตอน: ความเข้าใจเชิงกลไกของการให้เหตุผลแบบลูกโซ่ | ||
| • ให้การวิเคราะห์เชิงลึกของการให้เหตุผลโดยใช้ CoT ใน LLM ในแง่ขององค์ประกอบการทำงานของระบบประสาท • แยกการให้เหตุผลโดยใช้ CoT จากการให้เหตุผลสมมติเป็นองค์ประกอบของงานย่อยจำนวนคงที่ซึ่งต้องมีการตัดสินใจ การคัดลอก และการให้เหตุผลแบบอุปนัย โดยวิเคราะห์กลไกแยกจากกัน • พบว่าหัวความสนใจดำเนินการเคลื่อนย้ายข้อมูลระหว่างโทเค็นที่เกี่ยวข้องกับออนโทโลยี (หรือเกี่ยวข้องเชิงลบ) ส่งผลให้เกิดการแสดงตัวตนที่ชัดเจนสำหรับคู่โทเค็นเหล่านี้ | |||
| 28-02-2024 | การตัดหัวยุติความขัดแย้ง: กลไกในการตีความและบรรเทาความขัดแย้งทางความรู้ในรูปแบบภาษา | ||
| • แนะนำวิธี PH3 เพื่อตัดหัวความสนใจที่ขัดแย้งกัน บรรเทาความขัดแย้งของความรู้ในแบบจำลองภาษาโดยไม่ต้องอัปเดตพารามิเตอร์ • ใช้ PH3 เพื่อควบคุมการพึ่งพาหน่วยความจำภายในของ LM เทียบกับบริบทภายนอก และทดสอบประสิทธิภาพของงาน QA แบบโอเพ่นโดเมน • PH3 ปรับปรุงการใช้หน่วยความจำภายใน 44.0% และการใช้งานบริบทภายนอก 38.5% | |||
| 27-02-2024 | เส้นทางการไหลของข้อมูล: การตีความโมเดลภาษาตามขนาดโดยอัตโนมัติ | ||
| • แนะนำ "เส้นทางการไหลของข้อมูล" โดยใช้การระบุแหล่งที่มาสำหรับการตีความแบบจำลองภาษาตามกราฟ โดยหลีกเลี่ยงการเปิดใช้งานแพตช์ • ทดลองกับ Llama 2 โดยระบุหัวความสนใจหลักและรูปแบบพฤติกรรมในโดเมนและงานต่างๆ • เปิดเผยส่วนประกอบโมเดลพิเศษ; ระบุบทบาทที่สอดคล้องกันสำหรับหัวหน้าความสนใจ เช่น การจัดการสัญญาณของคำพูดในส่วนเดียวกัน | |||
| 2024-02-20 | การระบุหัวการชักนำความหมายเพื่อทำความเข้าใจการเรียนรู้ในบริบท | ||
| • ระบุและศึกษา "หัวการเหนี่ยวนำความหมาย" ในแบบจำลองภาษาขนาดใหญ่ (LLM) ที่มีความสัมพันธ์กับความสามารถในการเรียนรู้ในบริบท • วิเคราะห์หัวความสนใจสำหรับการเข้ารหัสการพึ่งพาทางวากยสัมพันธ์และความสัมพันธ์ของกราฟความรู้ • หัวหน้าความสนใจบางคนปรับปรุงบันทึกผลลัพธ์โดยการเรียกคืนโทเค็นที่เกี่ยวข้อง ซึ่งเป็นสิ่งสำคัญสำหรับการทำความเข้าใจการเรียนรู้ในบริบทใน LLM | |||
| 16-02-2024 | วิวัฒนาการของหัวเหนี่ยวนำเชิงสถิติ: การเรียนรู้แบบโซ่มาร์คอฟในบริบท | ||
| • แนะนำงานการสร้างแบบจำลองลำดับของ Markov Chain เพื่อวิเคราะห์ว่าความสามารถในการเรียนรู้ในบริบท (ICL) เกิดขึ้นในหม้อแปลงได้อย่างไร โดยสร้าง "หัวเหนี่ยวนำทางสถิติ" • การตรวจสอบเชิงประจักษ์และเชิงทฤษฎีของการฝึกอบรมแบบหลายเฟสในหม้อแปลงไฟฟ้าในงาน Markov Chain • สาธิตการเปลี่ยนเฟสจากการทำนายแบบยูนิแกรมไปเป็นบิ๊กแกรม ซึ่งได้รับอิทธิพลจากการโต้ตอบของชั้นหม้อแปลง | |||
| 11-02-2024 | การสรุปข้อเท็จจริง: กลไกเพิ่มเติมเบื้องหลังการเรียกคืนข้อเท็จจริงใน LLM | ||
| • ระบุและอธิบาย "บรรทัดฐานเพิ่มเติม" ในการเรียกคืนข้อเท็จจริง โดยที่ LLM ใช้กลไกอิสระหลายอย่างที่ขัดขวางอย่างสร้างสรรค์ในการเรียกคืนข้อเท็จจริง • ขยายการระบุแหล่งที่มาของ logit โดยตรงเพื่อวิเคราะห์หัวความสนใจและแยกพฤติกรรมของหัวแบบผสม • แสดงให้เห็นว่าการเรียกคืนข้อเท็จจริงใน LLM เป็นผลมาจากผลรวมของการมีส่วนร่วมที่ไม่เพียงพออย่างอิสระหลายรายการ | |||
| 05-02-2024 | โมเดลภาษาขนาดใหญ่เรียนรู้ในบริบทได้อย่างไร การสืบค้นและเมทริกซ์หลักของส่วนหัวในบริบทเป็นหอคอยสองแห่งสำหรับการเรียนรู้แบบเมตริก | ||
| • แนะนำแนวคิดที่ว่าการสืบค้นและเมทริกซ์หลักในส่วนหัวในบริบททำหน้าที่เป็น "สองหอคอย" สำหรับการเรียนรู้การวัด ซึ่งอำนวยความสะดวกในการคำนวณความคล้ายคลึงกันระหว่างคุณลักษณะฉลาก • วิเคราะห์กลไกการเรียนรู้ในบริบท ระบุหัวความสนใจเฉพาะที่สำคัญสำหรับ ICL • ลดความแม่นยำของ ICL จาก 87.6% เป็น 24.4% โดยการแทรกแซงเพียง 1% ของหัวเหล่านี้ | |||
| 23-01-2024 | การเรียนรู้ภาษาในบริบท: สถาปัตยกรรมและอัลกอริทึม | ||
| • การแนะนำ "n-gram heads" ซึ่งเป็นหัวความสนใจเฉพาะของ Transformer ซึ่งเพิ่มประสิทธิภาพการเรียนรู้ภาษาในบริบท (ICLL) ผ่านการทำนายโทเค็นแบบมีเงื่อนไขอินพุต • ประเมินโมเดลประสาทในภาษาปกติจากออโตมาตะจำกัดแบบสุ่ม • หัว n-gram ที่เดินสายแบบแข็งปรับปรุงความฉงนสนเท่ห์ขึ้น 6.7% ในชุดข้อมูล SlimPajama | |||
| 16-01-2024 | พื้นฐานกลไกของการพึ่งพาข้อมูลและการเรียนรู้อย่างฉับพลันในงานจำแนกประเภทในบริบท | ||
| • เอกสารนี้จำลองพื้นฐานกลไกของการเรียนรู้ในบริบท (ICL) ผ่านการก่อตัวอย่างฉับพลันของหัวการเหนี่ยวนำในเครือข่ายที่เน้นความสนใจเท่านั้น • จำลองงาน ICL โดยใช้ข้อมูลอินพุตที่เรียบง่ายและเครือข่ายตามความสนใจแบบสองชั้น • การก่อตัวของหัวเหนี่ยวนำทำให้เกิดการเปลี่ยนแปลงอย่างกะทันหันไปยัง ICL โดยติดตามผ่านความไม่เชิงเส้นที่ซ้อนกัน | |||
| 16-01-2024 | การนำส่วนประกอบของวงจรไปใช้ซ้ำในงานต่างๆ ในโมเดลภาษาของหม้อแปลงไฟฟ้า | ||
| • บทความนี้แสดงให้เห็นว่าวงจรเฉพาะใน GPT-2 สามารถสรุปงานต่างๆ ได้ โดยท้าทายแนวคิดที่ว่าวงจรดังกล่าวเป็นงานเฉพาะงาน • ตรวจสอบการนำวงจรกลับมาใช้ซ้ำจากงาน Indirect Object Identification (IOI) ในงาน Colored Objects • การปรับหัวความสนใจทั้งสี่หัวช่วยเพิ่มความแม่นยำจาก 49.6% เป็น 93.7% ในงานวัตถุสี | |||
| 16-01-2024 | หัวหน้าผู้สืบทอด: หัวหน้าความสนใจที่เกิดซ้ำและตีความได้ในป่า | ||
| • บทความนี้จะแนะนำ "Successor Heads" ซึ่งเป็นหัวความสนใจใน LLM ที่เพิ่มโทเค็นด้วยการเรียงลำดับตามธรรมชาติ เช่น วันหรือตัวเลข • จะวิเคราะห์การก่อตัวของหัวหน้าผู้สืบทอดในขนาดและสถาปัตยกรรมของโมเดลต่างๆ เช่น GPT-2 และ Llama-2 • พบส่วนหัวที่สืบทอดกันในโมเดลตั้งแต่พารามิเตอร์ 31M ถึง 12B ซึ่งเผยให้เห็นการแสดงตัวเลขเชิงนามธรรมที่เกิดขึ้นซ้ำๆ | |||
| 16-01-2024 | เวกเตอร์ฟังก์ชันในโมเดลภาษาขนาดใหญ่ | ||
| • บทความนี้จะแนะนำ "ฟังก์ชันเวคเตอร์ (FVs)" ขนาดกะทัดรัด การนำเสนอเชิงสาเหตุของงานภายในโมเดลหม้อแปลงแบบถดถอยอัตโนมัติ • FV ได้รับการทดสอบในงาน แบบจำลอง และเลเยอร์การเรียนรู้ในบริบท (ICL) ที่หลากหลาย • สามารถสรุป FV เพื่อสร้างเวกเตอร์ที่กระตุ้นให้เกิดงานใหม่ที่ซับซ้อน ซึ่งแสดงให้เห็นถึงองค์ประกอบเวกเตอร์ภายใน | |||
| วันที่ | กระดาษและบทสรุป | แท็ก | ลิงค์ |
| 23-12-2023 | การค้นหาข้อเท็จจริง: ความพยายามในการเรียกคืนข้อเท็จจริงของวิศวกรย้อนกลับในระดับเซลล์ประสาท | ||
| • ตรวจสอบว่าเลเยอร์ MLP ในยุคแรกๆ ใน Pythia 2.8B เข้ารหัสการเรียกคืนข้อเท็จจริงโดยใช้วงจรแบบกระจาย โดยมุ่งเน้นไปที่การซ้อนทับและการฝังโทเค็นหลายโทเค็นอย่างไร • สำรวจการค้นหาข้อเท็จจริงในชั้น MLP ทดสอบสมมติฐานเกี่ยวกับกลไกการแยกโทเค็นและแฮช • การเรียกคืนข้อเท็จจริงทำหน้าที่เหมือนกับตารางค้นหาแบบกระจายโดยไม่มีกลไกภายในที่สามารถตีความได้ง่าย | |||
| 07-11-2023 | สู่การต่อเนื่องของลำดับที่ตีความได้: การวิเคราะห์วงจรที่ใช้ร่วมกันในแบบจำลองภาษาขนาดใหญ่ | ||
| • สาธิตการมีอยู่ของวงจรที่ใช้ร่วมกันสำหรับงานต่อเนื่องตามลำดับที่คล้ายกัน • วิเคราะห์และเปรียบเทียบวงจรสำหรับงานต่อเนื่องของลำดับที่คล้ายกัน ซึ่งรวมถึงการเพิ่มลำดับของเลขอารบิค คำตัวเลข และเดือน • ลำดับที่เกี่ยวข้องกับความหมายขึ้นอยู่กับกราฟย่อยของวงจรที่ใช้ร่วมกันซึ่งมีบทบาทคล้ายคลึงกันและการค้นหาวงจรย่อยที่คล้ายกันในโมเดลต่างๆ ที่มีฟังก์ชันการทำงานคล้ายคลึงกัน | |||
| 23-10-2023 | การแสดงความรู้สึกเชิงเส้นในแบบจำลองภาษาขนาดใหญ่ | ||
| • บทความระบุทิศทางเชิงเส้นในพื้นที่การเปิดใช้งานที่รวบรวมการแสดงความรู้สึกใน Large Language Models (LLM) • พวกเขาแยกทิศทางความรู้สึกนี้ออกและทดสอบกับงานต่างๆ รวมถึง Stanford Sentiment Treebank • การลดทิศทางความรู้สึกนี้จะทำให้ความแม่นยำในการจำแนกประเภทลดลง 76% โดยเน้นย้ำถึงความสำคัญของสิ่งนี้ | |||
| 06-10-2023 | การปราบปรามการคัดลอก: การทำความเข้าใจหัวเรื่องความสนใจอย่างครอบคลุม | ||
| • บทความนี้จะแนะนำแนวคิดของการปราบปรามการคัดลอกใน GPT-2 Small Attention Head (L10H7) ซึ่งช่วยลดการคัดลอกโทเค็นที่ไร้เดียงสา เพิ่มประสิทธิภาพการสอบเทียบโมเดล • บทความนี้ศึกษาและอธิบายกลไกของการปราบปรามการคัดลอกและบทบาทใน การซ่อมแซมตนเอง • มีการอธิบายผลกระทบของ L10H7 ใน GPT-2 Small ถึง 76.9% ซึ่งทำให้เป็นคำอธิบายที่ครอบคลุมมากที่สุดเกี่ยวกับบทบาทของหัวหน้าผู้สนใจ | |||
| 22-09-2023 | การแทรกแซง-เวลา: ดึงเอาคำตอบที่เป็นความจริงจากแบบจำลองภาษา | ||
| • แนะนำการแทรกแซง-เวลา (ITI) เพื่อเพิ่มความเป็นจริงของ LLM โดยการปรับการเปิดใช้งานแบบจำลองในหัวความสนใจที่เลือก • ปรับปรุงประสิทธิภาพของโมเดล LLaMA บนเกณฑ์มาตรฐาน TruthfulQA • ITI เพิ่มความจริงของโมเดล Alpaca จาก 32.5% เป็น 65.1% | |||
| 22-09-2023 | กำเนิดหม้อแปลงไฟฟ้า: มุมมองแห่งความทรงจำ | ||
| • บทความนี้นำเสนอมุมมองที่อิงหน่วยความจำเกี่ยวกับหม้อแปลง โดยเน้นความทรงจำที่เชื่อมโยงในเมทริกซ์น้ำหนักและการเรียนรู้ที่ขับเคลื่อนด้วยเกรเดียนต์ • การวิเคราะห์เชิงประจักษ์ของไดนามิกการฝึกอบรมในแบบจำลองหม้อแปลงแบบง่ายพร้อมข้อมูลสังเคราะห์ • การค้นพบการเรียนรู้บิ๊กแกรมระดับโลกอย่างรวดเร็วและการเกิดขึ้นที่ช้ากว่าของ "หัวเหนี่ยวนำ" สำหรับบิ๊กแกรมในบริบท | |||
| 13-09-2023 | การลดลงอย่างกะทันหันในการสูญเสีย: การได้มาซึ่งไวยากรณ์ การเปลี่ยนเฟส และอคติแบบเรียบง่ายใน MLM | ||
| • ระบุโครงสร้างความสนใจทางวากยสัมพันธ์ (SAS) ว่าเป็นคุณสมบัติที่เกิดขึ้นตามธรรมชาติในโมเดลภาษามาสก์ (MLM) และบทบาทในการได้มาซึ่งไวยากรณ์ • วิเคราะห์ SAS ในระหว่างการฝึกอบรมและจัดการเพื่อศึกษาผลกระทบเชิงสาเหตุต่อความสามารถทางไวยากรณ์ • SAS จำเป็นสำหรับการพัฒนาไวยากรณ์ แต่การระงับสั้นๆ จะช่วยปรับปรุงประสิทธิภาพของโมเดล | |||
| 18-07-2023 | มาตราส่วนการตีความการวิเคราะห์วงจรมีอะไรบ้าง หลักฐานจากความสามารถแบบปรนัยใน Chinchilla | ||
| • การวิเคราะห์วงจรที่ปรับขนาดได้นำไปใช้กับแบบจำลองภาษา Chinchilla 70B เพื่อทำความเข้าใจการตอบคำถามแบบปรนัย • เข้าสู่ระบบการระบุแหล่งที่มา การสร้างภาพรูปแบบความสนใจ และการเปิดใช้งานแพตช์เพื่อระบุและจัดหมวดหมู่หัวข้อความสนใจหลัก • ระบุคุณลักษณะ "รายการที่ N ในการแจงนับ" ในหัวความสนใจ แม้ว่าจะเป็นเพียงคำอธิบายบางส่วนเท่านั้น | |||
| 02-02-2023 | การตีความในป่า: วงจรสำหรับการระบุวัตถุทางอ้อมใน GPT-2 ขนาดเล็ก | ||
| • บทความนี้แนะนำคำอธิบายโดยละเอียดว่า GPT-2 ขนาดเล็กดำเนินการระบุวัตถุทางอ้อม (IOI) ได้อย่างไร โดยใช้วงจรขนาดใหญ่ที่เกี่ยวข้องกับหัวความสนใจ 28 หัวซึ่งแบ่งออกเป็น 7 คลาส • พวกเขาย้อนรอยงาน IOI ใน GPT-2 ขนาดเล็กโดยใช้การแทรกแซงเชิงสาเหตุและการคาดคะเน • การศึกษาแสดงให้เห็นว่าการตีความเชิงกลไกของแบบจำลองภาษาขนาดใหญ่นั้นมีความเป็นไปได้ | |||
| วันที่ | กระดาษและบทสรุป | แท็ก | ลิงค์ |
| 08-03-2022 | การเรียนรู้และการชักนำในบริบท | ||
| • บทความระบุ "หัวเหนี่ยวนำ" ในโมเดล Transformer ซึ่งช่วยให้สามารถเรียนรู้ในบริบทโดยการจดจำและคัดลอกรูปแบบตามลำดับ • วิเคราะห์รูปแบบความสนใจและหัวเหนี่ยวนำในเลเยอร์ต่างๆ ใน Transformer รุ่นต่างๆ • พบว่าหัวเหนี่ยวนำมีความสำคัญอย่างยิ่งในการทำให้ Transformers สามารถสรุปและดำเนินงานการเรียนรู้ในบริบทได้อย่างมีประสิทธิภาพ | |||
| 22-12-2021 | กรอบทางคณิตศาสตร์สำหรับวงจรหม้อแปลงไฟฟ้า | ||
| • แนะนำกรอบงานทางคณิตศาสตร์สำหรับวิศวกรรมย้อนกลับหม้อแปลงไฟฟ้าแบบสนใจอย่างเดียวขนาดเล็ก โดยมุ่งเน้นที่การทำความเข้าใจหัวความสนใจว่าเป็นส่วนประกอบเสริมอิสระ • วิเคราะห์หม้อแปลงศูนย์ หนึ่ง และสองชั้นเพื่อระบุบทบาทของหัวความสนใจในการเคลื่อนย้ายและองค์ประกอบของข้อมูล • ค้นพบ "หัวเหนี่ยวนำ" ซึ่งสำคัญสำหรับการเรียนรู้ในบริบทในหม้อแปลงสองชั้น | |||
| 18-05-2021 | สมมติฐานของหัวหน้า: แนวทางทางสถิติแบบรวมศูนย์เพื่อการทำความเข้าใจความสนใจแบบหลายหัวใน BERT | ||
| • บทความนี้เสนอวิธีการใหม่ที่เรียกว่า "Sparse Attention" ซึ่งช่วยลดความซับซ้อนในการคำนวณของกลไกความสนใจโดยการเลือกเน้นไปที่โทเค็นที่สำคัญ • วิธีการได้รับการประเมินในงานการแปลด้วยเครื่องและงานการจัดหมวดหมู่ข้อความ • โมเดลความสนใจแบบกระจัดกระจายมีความแม่นยำเทียบเท่ากับความสนใจหนาแน่น ในขณะเดียวกันก็ลดต้นทุนการคำนวณลงอย่างมาก | |||
| 2021-04-01 | มีความสนใจใน BERT เรียนรู้ไวยากรณ์การเลือกตั้งหรือไม่? | ||
| • การศึกษานี้แนะนำวิธีทางวากยสัมพันธ์เพื่อวิเคราะห์ไวยากรณ์เขตเลือกตั้งในหัวเรื่องความสนใจของ BERT และ RoBERTa • ไวยากรณ์เขตเลือกตั้งได้รับการแยกและวิเคราะห์การปรับแต่งก่อนและหลังการปรับแต่งในงาน SMS และ NLI • งาน NLI ช่วยเพิ่มความสามารถในการกระตุ้นไวยากรณ์การเลือกตั้ง ในขณะที่งาน SMS จะลดลงในชั้นบน | |||
| 27-11-2019 | ความสนใจใน BERT ติดตามการพึ่งพาทางวากยสัมพันธ์หรือไม่ | ||
| •กระดาษตรวจสอบว่าหัวความสนใจของแต่ละบุคคลในการพึ่งพาวากยสัมพันธ์ของเบิร์ตจับการใช้น้ำหนักความสนใจเพื่อสกัดความสัมพันธ์การพึ่งพาอาศัยกันหรือไม่ •วิเคราะห์หัวความสนใจของเบิร์ตโดยใช้น้ำหนักความสนใจสูงสุดและต้นไม้ที่ทอดสูงสุดเปรียบเทียบกับต้นไม้พึ่งพาสากล •หัวความสนใจบางอย่างติดตามการพึ่งพาทางไวยากรณ์ที่เฉพาะเจาะจงได้ดีกว่า baselines แต่ไม่มีศีรษะทำการแยกวิเคราะห์แบบองค์รวมดีกว่าอย่างมีนัยสำคัญ | |||
| 2019-11-01 | หม้อแปลงเบาบางที่ปรับตัวได้ | ||
| •แนะนำหม้อแปลงเบาบางที่ปรับตัวได้โดยใช้อัลฟ่า-เอนไซม์เพื่อให้มีความยืดหยุ่นและขึ้นอยู่กับบริบทในหัวความสนใจ •นำไปใช้กับชุดข้อมูลการแปลของเครื่องเพื่อประเมินความสามารถในการตีความและความหลากหลายของหัว •บรรลุการกระจายความสนใจที่หลากหลายและการตีความที่ดีขึ้นโดยไม่ลดความแม่นยำ | |||
| 2019-08-01 | เบิร์ตดูอะไร? การวิเคราะห์ความสนใจของเบิร์ต | ||
| •กระดาษแนะนำวิธีการวิเคราะห์กลไกความสนใจของเบิร์ตเปิดเผยรูปแบบที่สอดคล้องกับโครงสร้างภาษาศาสตร์เช่นไวยากรณ์และ coreference •การวิเคราะห์หัวความสนใจการระบุรูปแบบวากยสัมพันธ์และรูปแบบ coreferential และการพัฒนาตัวแยกประเภทการตรวจสอบตามความสนใจ •หัวความสนใจของเบิร์ตจับข้อมูลวากยสัมพันธ์ที่สำคัญโดยเฉพาะอย่างยิ่งในงานต่าง ๆ เช่นการระบุวัตถุโดยตรงและ coreference | |||
| 2019-07-01 | การวิเคราะห์ความต้องการตนเองหลายหัว: หัวพิเศษทำการยกหนักส่วนที่เหลือสามารถตัดแต่งได้ | ||
| •กระดาษแนะนำวิธีการตัดแต่งกิ่งแบบใหม่สำหรับการตั้งใจด้วยตนเองหลายหัวซึ่งเลือกเอาหัวที่สำคัญน้อยกว่าโดยไม่สูญเสียประสิทธิภาพที่สำคัญ •การวิเคราะห์หัวความสนใจของแต่ละบุคคลการระบุบทบาทเฉพาะของพวกเขาและการประยุกต์ใช้วิธีการตัดแต่งกิ่งบนโมเดลหม้อแปลง •การตัดแต่งกิ่ง 38 จาก 48 หัวในตัวเข้ารหัสนำไปสู่การลดลงของคะแนน 0.15 Bleu เท่านั้น | |||
| 2018-11-01 | การวิเคราะห์การเป็นตัวแทนของตัวเข้ารหัสในการแปลเครื่องที่ใช้หม้อแปลง | ||
| •บทความนี้วิเคราะห์การเป็นตัวแทนภายในของเลเยอร์เครื่องเข้ารหัสหม้อแปลงโดยมุ่งเน้นไปที่ข้อมูลทางไวยากรณ์และความหมายที่เรียนรู้โดยหัวการดูแลตนเอง •งานตรวจสอบการสกัดความสัมพันธ์แบบพึ่งพาและสถานการณ์การเรียนรู้การถ่ายโอน •เลเยอร์ที่ต่ำกว่าการจับไวยากรณ์ในขณะที่เลเยอร์ที่สูงขึ้นเข้ารหัสข้อมูลความหมายมากขึ้น | |||
| 2016-03-21 | การรวมกลไกการคัดลอกในการเรียนรู้ลำดับต่อลำดับ | ||
| •แนะนำกลไกการคัดลอกไปยังแบบจำลองลำดับต่อลำดับเพื่อให้สามารถคัดลอกโทเค็นอินพุตโดยตรงปรับปรุงการจัดการคำที่หายาก •นำไปใช้กับงานการแปลและการสรุปของเครื่อง •ได้รับการปรับปรุงอย่างมากในความแม่นยำในการแปลโดยเฉพาะอย่างยิ่งในการแปลคำที่หายากเมื่อเทียบกับแบบจำลองลำดับต่อลำดับมาตรฐาน | |||
เทมเพลตปัญหา:
Title: [paper's title]
Head: [head name1] (, [head name2] ...)
Published: [arXiv / ACL / ICLR / NIPS / ...]
Summary:
- Innovation:
- Tasks:
- Significant Result:


