AMRICA
1.0.0
AMRICA (AMR Inspector for Cross-Language Alignments) เป็นเครื่องมือง่ายๆ สำหรับการจัดตำแหน่งและการแสดง AMR ด้วยภาพ (Banarescu, 2013) ทั้งสำหรับบริบทสองภาษาและสำหรับข้อตกลงระหว่างผู้อธิบายประกอบแบบภาษาเดียว ขึ้นอยู่กับและขยายระบบ Smatch (Cai, 2012) เพื่อระบุข้อตกลงระหว่างผู้จดบันทึก AMR
นอกจากนี้ยังสามารถใช้ AMRICA เพื่อแสดงภาพการจัดตำแหน่งแบบแมนนวลที่คุณได้แก้ไขหรือคอมไพล์ด้วยตัวเอง (ดู Common Flags)
ดาวน์โหลดซอร์สหลามจาก github
เราถือว่าคุณมี pip หากต้องการติดตั้งการขึ้นต่อกัน (สมมติว่าคุณมีการขึ้นต่อกันของกราฟวิซตามที่ระบุไว้ด้านล่างแล้ว) เพียงเรียกใช้:
pip install argparse_config networkx==1.8 pygraphviz pynlpl
pygraphviz ต้องการให้ Graphviz ทำงาน บน Linux คุณอาจต้องติดตั้ง graphviz libgraphviz-dev pkg-config นอกจากนี้ เพื่อเตรียมข้อมูลการจัดตำแหน่งสองภาษา คุณจะต้องมี GIZA++ และอาจเป็น JAMR
./disagree.py -i sample.amr -o sample_out_dir/
คำสั่งนี้จะอ่าน AMR ใน sample.amr (คั่นด้วยบรรทัดว่าง) และใส่การแสดงภาพกราฟวิซในไฟล์ .png ที่อยู่ใน sample_out_dir/
ในการสร้างการแสดงภาพการจัดแนว Smatch เราจำเป็นต้องมีไฟล์อินพุต AMR พร้อมด้วยฟิลด์ ::tok หรือ ::snt แต่ละฟิลด์ที่มีประโยคโทเค็น, ฟิลด์ ::id ที่มี ID ประโยค และฟิลด์ ::annotator หรือ ::anno ที่มี ID ของคำอธิบายประกอบ คำอธิบายประกอบสำหรับประโยคใดประโยคหนึ่งจะแสดงตามลำดับ และคำอธิบายประกอบแรกถือเป็นมาตรฐานทองคำสำหรับวัตถุประสงค์ในการแสดงภาพ
หากคุณต้องการแสดงภาพคำอธิบายประกอบเดี่ยวต่อประโยคโดยไม่มีข้อตกลงระหว่างผู้อธิบาย คุณสามารถใช้ไฟล์ AMR ที่มีคำอธิบายประกอบเพียงตัวเดียว ในกรณีนี้ ช่องข้อมูลคำอธิบายประกอบและรหัสประโยคเป็นทางเลือก กราฟที่ได้จะเป็นสีดำทั้งหมด
สำหรับการจัดแนวสองภาษา เราจะเริ่มต้นด้วยไฟล์ AMR สองไฟล์ โดยไฟล์หนึ่งจะมีคำอธิบายประกอบเป้าหมาย และอีกไฟล์หนึ่งมีคำอธิบายประกอบแหล่งที่มาในลำดับเดียวกัน โดยมีฟิลด์ ::tok และ ::id สำหรับแต่ละคำอธิบายประกอบ หากเราต้องการการจัดตำแหน่ง JAMR สำหรับด้านใดด้านหนึ่ง เราจะรวมการจัดตำแหน่งเหล่านั้นไว้ในฟิลด์ ::alignments
การจัดตำแหน่งประโยคควรอยู่ในรูปแบบของไฟล์ .NBEST สำหรับการจัดตำแหน่ง GIZA++ สองไฟล์ หนึ่งไฟล์เป้าหมายต้นทาง และหนึ่งไฟล์แหล่งที่มาเป้าหมาย หากต้องการสร้างสิ่งเหล่านี้ ให้ใช้แฟล็ก --nbestalignments ในไฟล์กำหนดค่า GIZA++ ของคุณโดยตั้งค่าเป็นจำนวน nbest ที่คุณต้องการ
คุณสามารถตั้งค่าสถานะได้ที่บรรทัดคำสั่งหรือในไฟล์กำหนดค่า ตำแหน่งของไฟล์ปรับแต่งสามารถตั้งค่าได้ด้วย -c CONF_FILE ที่บรรทัดคำสั่ง
นอกจาก --conf_file แล้ว ยังมีแฟล็กอื่นๆ อีกมากมายที่ใช้กับข้อความทั้งภาษาเดียวและสองภาษา --outdir DIR เป็นสิ่งเดียวที่จำเป็น และระบุไดเร็กทอรีที่เราจะเขียนไฟล์รูปภาพ
แฟล็กที่ใช้ร่วมกันซึ่งเป็นทางเลือกคือ:
--verbose เพื่อพิมพ์ประโยคในขณะที่เราจัดเรียงประโยค--no-verbose เพื่อแทนที่การตั้งค่าเริ่มต้นแบบละเอียด--json FILE.json เพื่อเขียนกราฟการจัดตำแหน่งไปยังไฟล์ .json--num_restarts N เพื่อระบุจำนวนการรีสตาร์ทแบบสุ่ม Smatch ควรดำเนินการ--align_out FILE.csv เพื่อเขียนการจัดตำแหน่งลงในไฟล์--align_in FILE.csv เพื่ออ่านการจัดตำแหน่งจากดิสก์แทนที่จะเรียกใช้ Smatch--layout เพื่อแก้ไขพารามิเตอร์เลย์เอาต์เป็นกราฟวิซไฟล์การจัดตำแหน่ง .csv อยู่ในรูปแบบที่ชุดการจับคู่กราฟแต่ละชุดคั่นด้วยบรรทัดว่าง และแต่ละบรรทัดภายในชุดประกอบด้วยความคิดเห็นหรือบรรทัดที่ระบุการจัดตำแหน่ง ตัวอย่างเช่น:
3 它 - 1 it
2 多长 - -1
-1 - 2 take
ฟิลด์ที่คั่นด้วยแท็บคือดัชนีโหนดทดสอบ (ที่ประมวลผลโดย Smatch), ป้ายกำกับโหนดทดสอบ, ดัชนีโหนดทอง และป้ายกำกับโหนดทอง
การจัดตำแหน่งแบบภาษาเดียวจำเป็นต้องมีแฟล็กเพิ่มเติมหนึ่งรายการ --infile FILE.amr โดยที่ FILE.amr ตั้งค่าเป็นตำแหน่งของไฟล์ AMR
ต่อไปนี้เป็นตัวอย่างไฟล์ปรับแต่ง:
[default]
infile: data/events_amr.txt
outdir: data/events_png/
json: data/events.json
verbose
ในการจัดแนวสองภาษา จะต้องมีแฟล็กที่จำเป็นเพิ่มเติม
--src_amr FILE สำหรับไฟล์ AMR คำอธิบายประกอบต้นฉบับ--tgt_amr FILE สำหรับไฟล์ AMR คำอธิบายประกอบเป้าหมาย--align_tgt2src FILE.A3.NBEST สำหรับไฟล์ GIZA++ .NBEST ที่จัดตำแหน่งเป้าหมายต่อแหล่งที่มา (โดยมีเป้าหมายเป็น vcb1) สร้างด้วย --nbestalignments N--align_src2tgt FILE.A3.NBEST สำหรับไฟล์ GIZA++ .NBEST ที่จัดตำแหน่งจากต้นทางถึงเป้าหมาย (โดยมีแหล่งที่มาเป็น vcb1) สร้างด้วย --nbestalignments N ตอนนี้ถ้า --nbestalignments N ถูกตั้งค่าเป็น >1 เราควรระบุด้วย --num_aligned_in_file หากเราต้องการนับเฉพาะยอด --num_align_read ไว้เช่นกัน
--nbestalignments เป็นแฟล็กที่ใช้งานยาก เนื่องจากจะสร้างเฉพาะในการรันการจัดตำแหน่งขั้นสุดท้ายเท่านั้น ฉันสามารถทำให้มันใช้งานได้กับการตั้งค่าเริ่มต้นของ GIZA++ เท่านั้นเอง
เนื่องจาก AMRICA เป็นรูปแบบของ Smatch เราจึงควรเริ่มต้นด้วยการทำความเข้าใจ Smatch Smatch พยายามระบุการจับคู่ระหว่างโหนดตัวแปรของการแสดง AMR สองตัวของประโยคเดียวกันเพื่อวัดข้อตกลงระหว่างผู้อธิบายประกอบ ควรเลือกการจับคู่เพื่อเพิ่มคะแนน Smatch ให้สูงสุด ซึ่งจะกำหนดจุดให้กับแต่ละขอบที่ปรากฏในกราฟทั้งสอง โดยแบ่งออกเป็นสามหมวดหมู่ แต่ละหมวดหมู่จะแสดงอยู่ในคำอธิบายประกอบ "ใช้เวลาไม่นาน" ต่อไปนี้
(t / take-10
:ARG0 (i / it)
:ARG1 (l2 / long
:polarity -))
(instance, t, take-10)(ARG0, t, i)(polarity, l2, -)เนื่องจากปัญหาในการค้นหาการจับคู่เพื่อเพิ่มคะแนน Smatch ให้เป็น NP-Complete Smatch จึงใช้อัลกอริธึมการปีนเขาเพื่อประมาณวิธีแก้ปัญหาที่ดีที่สุด โดยจะเพาะเมล็ดโดยการจับคู่แต่ละโหนดกับโหนดที่ใช้ป้ายกำกับร่วมกันหากเป็นไปได้ และจับคู่โหนดที่เหลือในกราฟขนาดเล็ก (ต่อไปนี้คือเป้าหมาย) โดยการสุ่ม จากนั้น Smatch จะดำเนินการขั้นตอนหนึ่งโดยการค้นหาการกระทำที่จะเพิ่มคะแนนได้มากที่สุดโดยการสลับการจับคู่โหนดเป้าหมายสองโหนด หรือย้ายการจับคู่จากโหนดต้นทางไปยังโหนดต้นทางที่ไม่ตรงกัน โดยทำซ้ำขั้นตอนนี้จนกว่าจะไม่มีขั้นตอนใดที่สามารถเพิ่มคะแนน Smatch ได้ทันที
เพื่อหลีกเลี่ยงการปรับให้เหมาะสมภายในเครื่อง โดยทั่วไป Smatch จะรีสตาร์ท 5 ครั้ง
สำหรับรายละเอียดด้านเทคนิคเกี่ยวกับผลงานภายในของ AMRICA การอ่านเอกสารสาธิต NAACL ของเราอาจมีประโยชน์มากกว่า
AMRICA เริ่มต้นด้วยการแทนที่โหนดคงที่ทั้งหมดด้วยโหนดตัวแปรที่เป็นอินสแตนซ์ของป้ายกำกับของค่าคงที่ นี่เป็นสิ่งจำเป็นเพื่อให้เราสามารถจัดตำแหน่งโหนดคงที่และตัวแปรได้ ดังนั้นคะแนนเดียวที่เพิ่มให้กับคะแนน AMRICA จะมาจากการจับคู่ตัวแปร-ตัวแปร Edge และป้ายกำกับอินสแตนซ์
ในขณะที่ Smatch พยายามจับคู่ทุกโหนดในกราฟที่เล็กกว่ากับบางโหนดในกราฟที่ใหญ่กว่า AMRICA จะลบการจับคู่ที่ไม่เพิ่มคะแนน Smatch ที่แก้ไขแล้วหรือคะแนน AMRICA
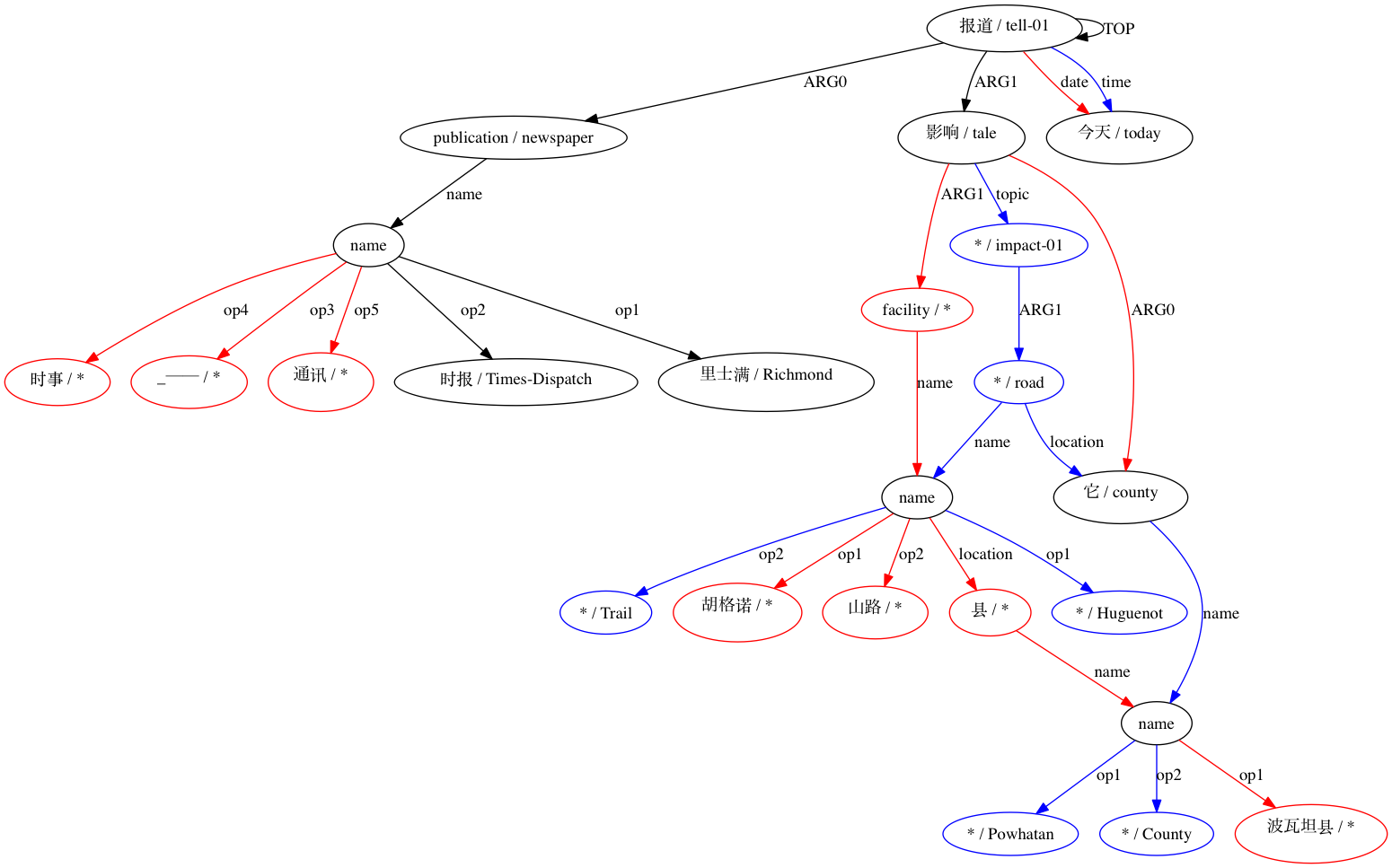
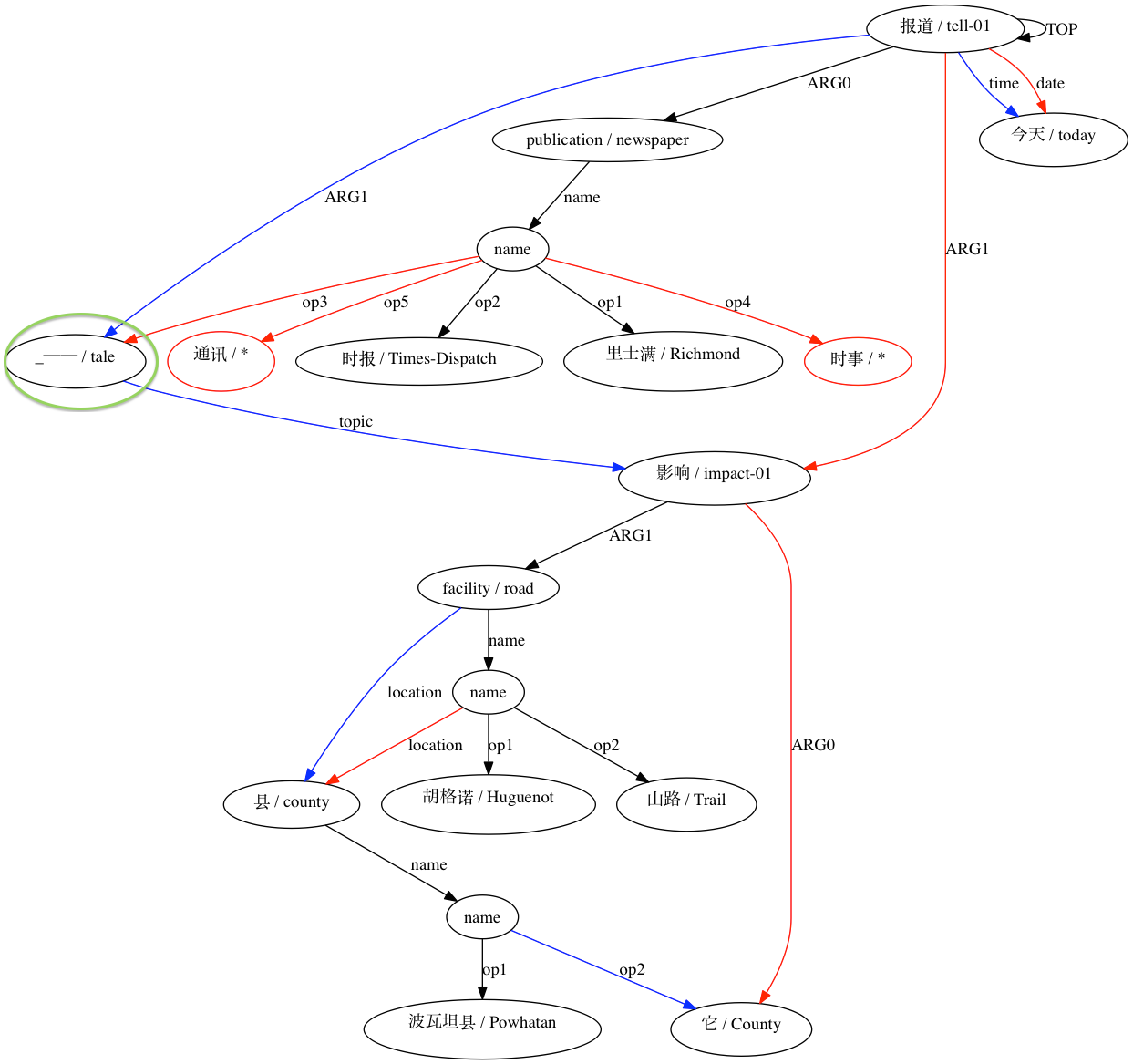
AMRICA จะสร้างไฟล์ภาพจากกราฟกราฟวิซของการจัดตำแหน่ง หากโหนดหรือขอบปรากฏเฉพาะในข้อมูลสีทอง จะเป็นสีแดง หากโหนดหรือขอบนั้นปรากฏเฉพาะในข้อมูลทดสอบเท่านั้น จะเป็นสีน้ำเงิน หากโหนดหรือขอบมีการจับคู่ในการจัดตำแหน่งสุดท้ายของเรา โหนดนั้นจะเป็นสีดำ
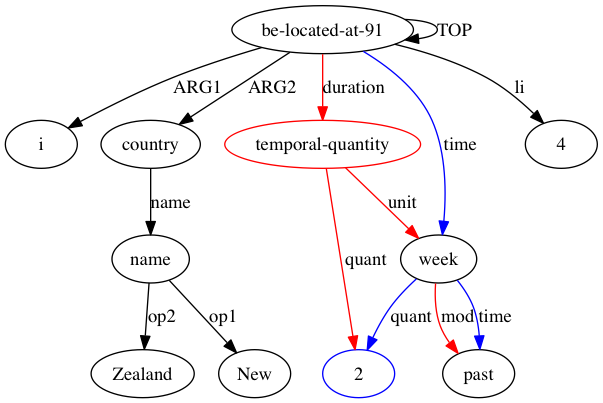
ใน AMRICA แทนที่จะเพิ่มหนึ่งจุดสำหรับแต่ละป้ายกำกับอินสแตนซ์ที่ตรงกันอย่างสมบูรณ์ เราจะเพิ่มจุดตามคะแนนความน่าจะเป็นบนป้ายกำกับเหล่านั้นที่สอดคล้องกัน คะแนนความน่าจะเป็น ë(aLt,Ls[i]|Lt,Wt,Ls,Ws) พร้อมชุดป้ายกำกับเป้าหมาย Lt, ชุดป้ายกำกับแหล่งที่มา Ls, ประโยคเป้าหมาย Wt, ประโยคแหล่งที่มา Ws และการจัดตำแหน่ง aLt,Ls[i] การแมป Lt[ i] บนฉลากบางอัน Ls[aLt,Ls[i]] คำนวณจากความน่าจะเป็นที่กำหนดโดยกฎต่อไปนี้:
โดยทั่วไป AMRICA แบบสองภาษาดูเหมือนจะจำเป็นต้องรีสตาร์ทแบบสุ่มมากกว่า AMRICA แบบภาษาเดียวเพื่อให้ทำงานได้ดี จำนวนการรีสตาร์ทนี้สามารถแก้ไขได้ด้วยแฟล็ก --num_restarts
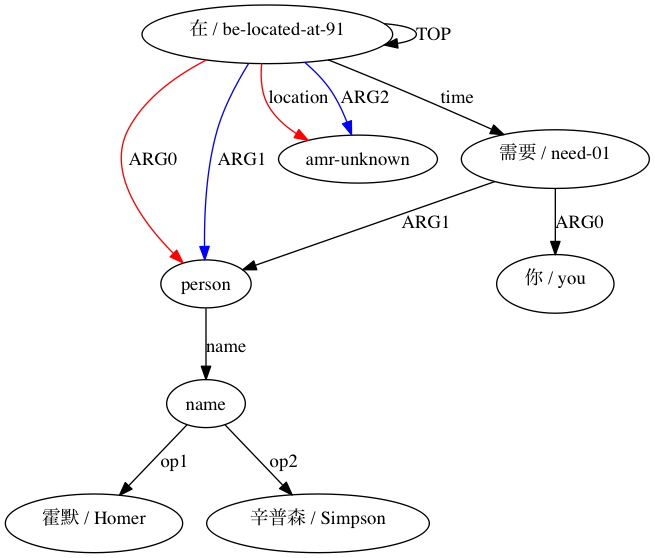
เราสามารถสังเกตระดับที่การใช้การประมาณแบบ Smatch (ในที่นี้มีการกำหนดค่าเริ่มต้นแบบสุ่ม 20 รายการ) ปรับปรุงความแม่นยำมากกว่าการเลือกการจับคู่ที่น่าจะเป็นไปได้จากข้อมูลการจัดตำแหน่งแบบดิบ (การกำหนดค่าเริ่มต้นอัจฉริยะ) สำหรับการจับคู่ที่ประกาศความเข้ากันได้ทางโครงสร้างโดย (Xue 2014)
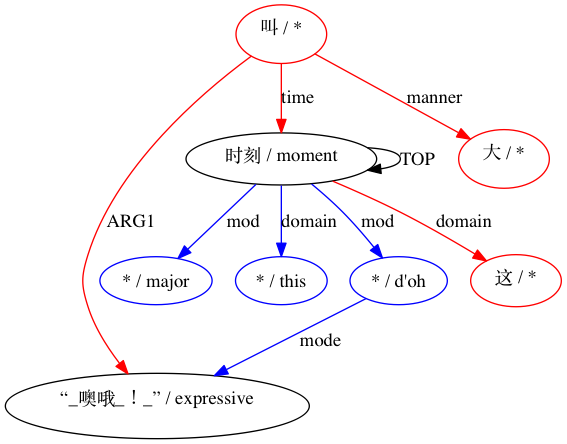
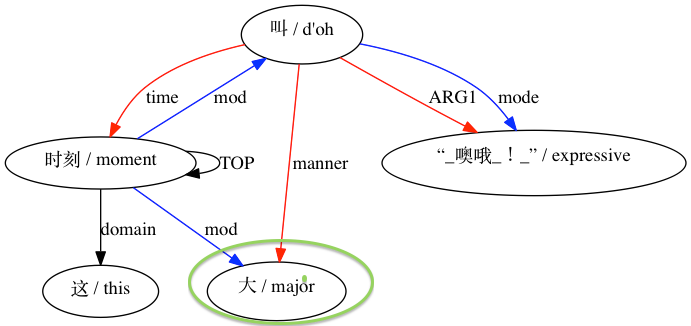
สำหรับการจับคู่ที่ถือว่าเข้ากันไม่ได้:
ซอฟต์แวร์นี้ได้รับการพัฒนาบางส่วนโดยได้รับการสนับสนุนจาก National Science Foundation (USA) ภายใต้รางวัล 1349902 และ 0530118 University of Edinburgh เป็นองค์กรการกุศลที่จดทะเบียนในสกอตแลนด์ โดยมีหมายเลขทะเบียน SC005336


