multimedia gpt
1.0.0
Multimedia GPT เชื่อมต่อ OpenAI GPT ของคุณกับภาพและเสียง ตอนนี้คุณสามารถส่งรูปภาพ ไฟล์บันทึกเสียง และเอกสาร PDF โดยใช้คีย์ OpenAI API ของคุณ และรับการตอบกลับทั้งในรูปแบบข้อความและรูปภาพ ขณะนี้เรากำลังเพิ่มการสนับสนุนสำหรับวิดีโอ ทั้งหมดนี้เกิดขึ้นได้ด้วยตัวจัดการพร้อมท์ที่ได้รับแรงบันดาลใจและสร้างขึ้นจาก Microsoft Visual ChatGPT
นอกเหนือจากโมเดลพื้นฐานการมองเห็นทั้งหมดที่กล่าวถึงใน Microsoft Visual ChatGPT แล้ว Multimedia GPT ยังรองรับ OpenAI Whisper และ OpenAI DAALLE! ซึ่งหมายความว่า คุณไม่จำเป็นต้องมี GPU ของคุณเองอีกต่อไปสำหรับการจดจำเสียงและสร้างภาพ (แม้ว่าคุณจะยังทำได้ก็ตาม!)
โมเดลการแชทพื้นฐานสามารถกำหนดค่าเป็น OpenAI LLM ใดก็ได้ รวมถึง ChatGPT และ GPT-4 เราตั้งค่าเริ่มต้นเป็น text-davinci-003
คุณสามารถแยกโปรเจ็กต์นี้และเพิ่มโมเดลที่เหมาะกับกรณีการใช้งานของคุณเองได้ วิธีง่ายๆ ในการทำเช่นนี้คือผ่าน llama_index คุณจะต้องสร้างคลาสใหม่สำหรับโมเดลของคุณใน model.py และเพิ่มเมธอดนักวิ่ง run_<model_name> ใน multimedia_gpt.py ดูตัวอย่าง run_pdf
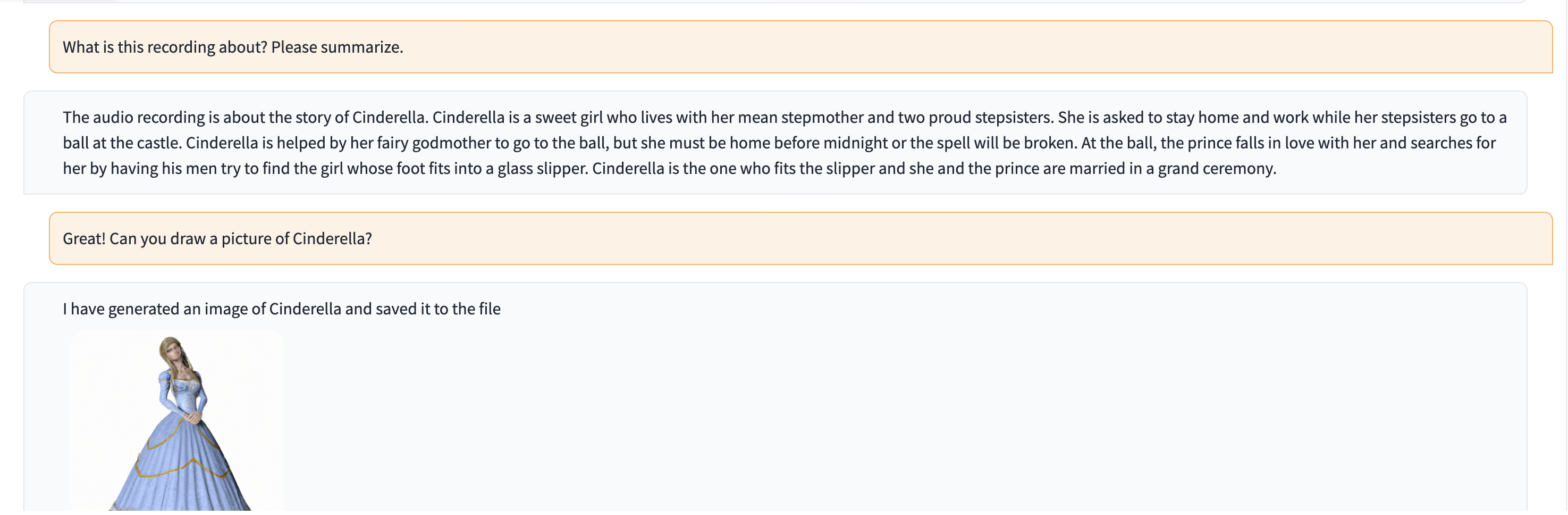
ในการสาธิตนี้ ChatGPT จะถูกป้อนด้วยบันทึกของบุคคลที่บอกเล่าเรื่องราวของซินเดอเรลล่า
# Clone this repository
git clone https://github.com/fengyuli2002/multimedia-gpt
cd multimedia-gpt
# Prepare a conda environment
conda create -n multimedia-gpt python=3.8
conda activate multimedia-gptt
pip install -r requirements.txt
# prepare your private OpenAI key (for Linux / MacOS)
echo " export OPENAI_API_KEY='yourkey' " >> ~ /.zshrc
# prepare your private OpenAI key (for Windows)
setx OPENAI_API_KEY “ < yourkey > ”
# Start Multimedia GPT!
# You can specify the GPU/CPU assignment by "--load", the parameter indicates which foundation models to use and
# where it will be loaded to. The model and device are separated by '_', different models are separated by ','.
# The available Visual Foundation Models can be found in models.py
# For example, if you want to load ImageCaptioning to cuda:0 and whisper to cpu
# (whisper runs remotely, so it doesn't matter where it is loaded to)
# You can use: "ImageCaptioning_cuda:0,Whisper_cpu"
# Don't have GPUs? No worry, you can run DALLE and Whisper on cloud using your API key!
python multimedia_gpt.py --load ImageCaptioning_cpu,DALLE_cpu,Whisper_cpu
# Additionally, you can configure the which OpenAI LLM to use by the "--llm" tag, such as
python multimedia_gpt.py --llm text-davinci-003
# The default is gpt-3.5-turbo (ChatGPT). โปรเจ็กต์นี้เป็นงานทดลองและจะไม่นำไปใช้กับสภาพแวดล้อมการใช้งานจริง เป้าหมายของเราคือการสำรวจพลังแห่งการกระตุ้นเตือน


