BabyGPT Build_GPT_From_Scratch
1.0.0
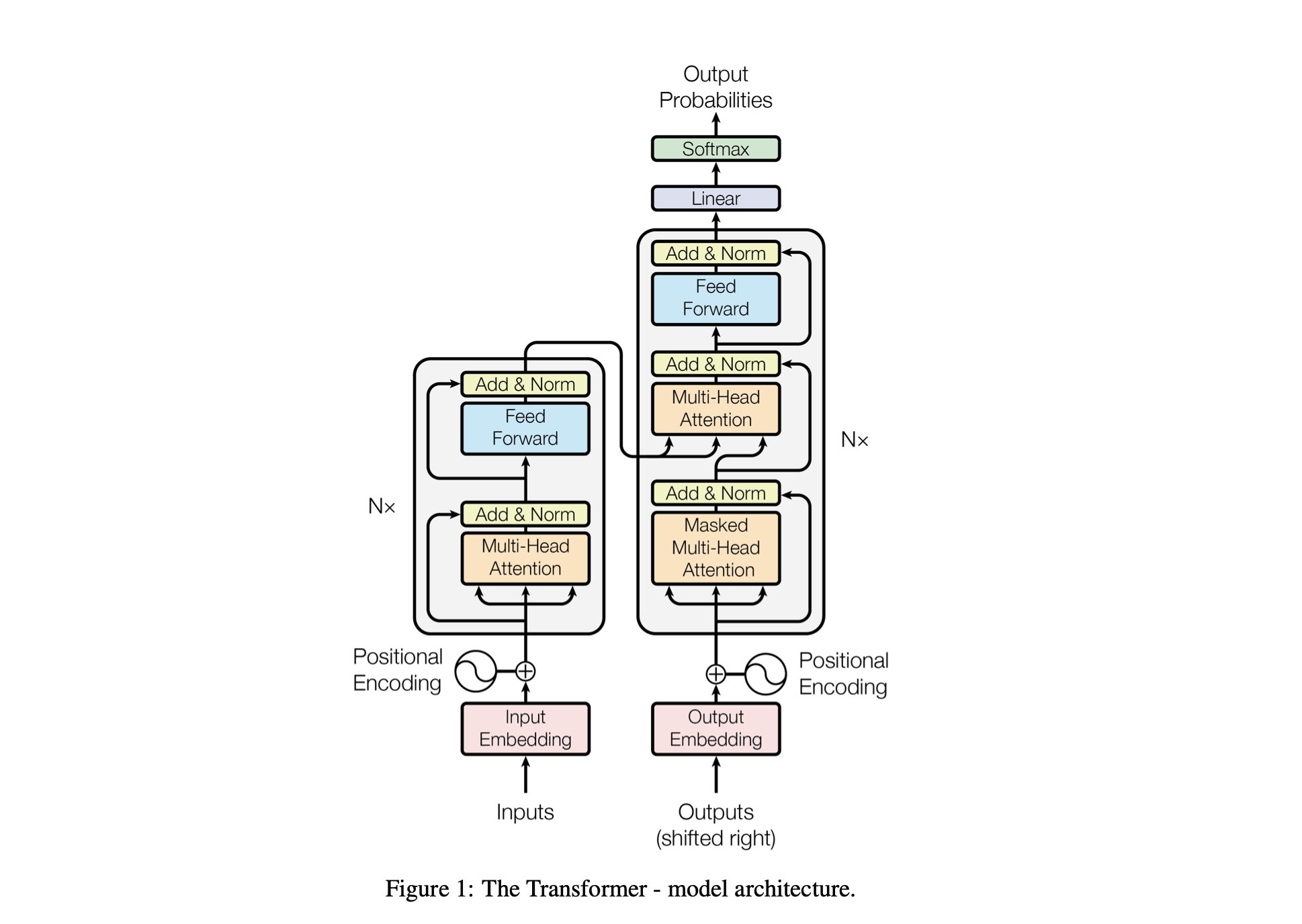
Baby GPT เป็นโครงการสำรวจที่ออกแบบมาเพื่อสร้างแบบจำลองภาษาที่คล้ายกับ GPT แบบค่อยเป็นค่อยไป โครงการเริ่มต้นด้วย Bigram Model ที่เรียบง่าย และค่อยๆ รวมเอาแนวคิดขั้นสูงจากสถาปัตยกรรมโมเดล Transformer
ประสิทธิภาพของโมเดลได้รับการปรับแต่งโดยใช้ไฮเปอร์พารามิเตอร์ต่อไปนี้:
batch_size : จำนวนลำดับที่ประมวลผลแบบขนานระหว่างการฝึกblock_size : ความยาวของลำดับที่กำลังประมวลผลโดยโมเดลd_model : จำนวนฟีเจอร์ในโมเดล (ขนาดของการฝัง)d_k : จำนวนฟีเจอร์ต่อหัวความสนใจnum_iter : จำนวนการวนซ้ำการฝึกทั้งหมดที่โมเดลจะดำเนินการNx : จำนวนบล็อกหรือเลเยอร์ของหม้อแปลงในโมเดลeval_interval : ช่วงเวลาที่คำนวณและประเมินการสูญเสียของโมเดลlr_rate : อัตราการเรียนรู้สำหรับเครื่องมือเพิ่มประสิทธิภาพ Adamdevice : ตั้งค่าเป็น 'cuda' โดยอัตโนมัติหากมี GPU ที่ใช้งานร่วมกันได้ มิฉะนั้นจะมีค่าเริ่มต้นเป็น 'cpu'eval_iters : จำนวนการวนซ้ำเพื่อเฉลี่ยการสูญเสียการประเมินh : จำนวนหัวความสนใจในกลไกความสนใจแบบหลายหัวdropout_rate : อัตราการออกกลางคันที่ใช้ระหว่างการฝึกเพื่อป้องกันการออกกำลังกายมากเกินไปไฮเปอร์พารามิเตอร์เหล่านี้ได้รับการคัดเลือกมาอย่างดีเพื่อสร้างสมดุลให้กับความสามารถของโมเดลในการเรียนรู้จากข้อมูลโดยไม่ต้องติดตั้งมากเกินไป และเพื่อจัดการทรัพยากรการคำนวณอย่างมีประสิทธิภาพ
| ไฮเปอร์พารามิเตอร์ | รุ่นซีพียู | รุ่นจีพียู |
|---|---|---|
device | 'ซีพียู' | 'cuda' หากมี มิฉะนั้น 'cpu' |
batch_size | 16 | 64 |
block_size | 8 | 256 |
num_iter | 10,000 | 10,000 |
eval_interval | 500 | 500 |
eval_iters | 100 | 200 |
d_model | 16 | 512 |
d_k | 4 | 16 |
Nx | 2 | 6 |
dropout_rate | 0.2 | 0.2 |
lr_rate | 0.005 (5e-3) | 0.001 (1e-3) |
h | 2 | 6 |
open('./GPT Series/input.txt', 'r', encoding = 'utf-8')chars_to_int และ int_to_charsencode และกลับด้วยฟังก์ชัน decodetrain_data ) และชุดการตรวจสอบความถูกต้อง ( valid_data )get_batch เตรียมข้อมูลเป็นชุดย่อยสำหรับการฝึกBigramLMMini-batching เป็นเทคนิคในการเรียนรู้ของเครื่องโดยแบ่งข้อมูลการฝึกอบรมออกเป็นชุดย่อย มินิแบทช์แต่ละชุดจะได้รับการประมวลผลแยกกันระหว่างการฝึกโมเดล วิธีการนี้ช่วยในเรื่อง:
# Function to create mini-batches for training or validation.
def get_batch ( split ):
# Select data based on training or validation split.
data = train_data if split == "train" else valid_data
# Generate random start indices for data blocks, ensuring space for 'block_size' elements.
ix = torch . randint ( len ( data ) - block_size , ( batch_size ,))
# Create input (x) and target (y) sequences from data blocks.
x = torch . stack ([ data [ i : i + block_size ] for i in ix ])
y = torch . stack ([ data [ i + 1 : i + block_size + 1 ] for i in ix ])
# Move data to GPU if available for faster processing.
x , y = x . to ( device ), y . to ( device )
return x , y | ปัจจัย | ขนาดชุดเล็ก | ขนาดชุดใหญ่ |
|---|---|---|
| เสียงไล่ระดับ | สูงกว่า (ความแปรปรวนในการอัปเดตมากขึ้น) | ต่ำกว่า (การอัปเดตที่สอดคล้องกันมากขึ้น) |
| การบรรจบกัน | มีแนวโน้มที่จะสำรวจวิธีแก้ปัญหาเพิ่มเติม รวมถึงแนวคิดขั้นต่ำที่ประจบประแจงด้วย | มักจะมาบรรจบกันที่จุดต่ำสุดที่คมชัดยิ่งขึ้น |
| ลักษณะทั่วไป | อาจจะดีกว่า (เนื่องจากขั้นต่ำที่ประจบประแจง) | อาจแย่ลง (เนื่องจากค่าขั้นต่ำที่คมชัดกว่า) |
| อคติ | ต่ำกว่า (มีโอกาสน้อยที่จะเหมาะกับรูปแบบข้อมูลการฝึกมากเกินไป) | สูงกว่า (อาจเกินพอดีกับรูปแบบข้อมูลการฝึกอบรม) |
| ความแปรปรวน | สูงกว่า (เนื่องจากมีการสำรวจพื้นที่โซลูชันมากขึ้น) | ต่ำกว่า (เนื่องจากการสำรวจในพื้นที่โซลูชันน้อยลง) |
| ต้นทุนการคำนวณ | สูงกว่าในแต่ละยุค (อัปเดตเพิ่มเติม) | ลดลงในแต่ละยุค (อัปเดตน้อยลง) |
| การใช้หน่วยความจำ | ต่ำกว่า | สูงกว่า |
ฟังก์ชัน estimate_loss จะคำนวณการสูญเสียโดยเฉลี่ยสำหรับแบบจำลองตามจำนวนการวนซ้ำที่ระบุ (eval_iters) ใช้เพื่อประเมินประสิทธิภาพของโมเดลโดยไม่ส่งผลกระทบต่อพารามิเตอร์ แบบจำลองได้รับการตั้งค่าเป็นโหมดการประเมินเพื่อปิดใช้งานบางเลเยอร์ เช่น การออกกลางคัน เพื่อการคำนวณการสูญเสียที่สอดคล้องกัน หลังจากคำนวณการสูญเสียโดยเฉลี่ยสำหรับทั้งข้อมูลการฝึกและการตรวจสอบแล้ว โมเดลจะเปลี่ยนกลับเป็นโหมดการฝึก ฟังก์ชันนี้จำเป็นสำหรับการติดตามกระบวนการฝึกอบรมและทำการปรับเปลี่ยนหากจำเป็น
@ torch . no_grad () # Disables gradient calculation to save memory and computations
def estimate_loss ():
result = {} # Dictionary to store the results
model . eval () # Puts the model in evaluation mode
# Iterates over the data splits (training and validation)
for split in [ 'train' , 'valid_date' ]:
# Initializes a tensor to store the losses for each iteration
losses = torch . zeros ( eval_iters )
# Loops over the number of iterations to calculate the average loss
for e in range ( eval_iters ):
X , Y = get_batch ( split ) # Fetches a batch of data
logits , loss = model ( X , Y ) # Gets the model outputs and computes the loss
losses [ e ] = loss . item () # Records the loss for this iteration
# Stores the mean loss for the current split in the result dictionary
result [ split ] = losses . mean ()
model . train () # Sets the model back to training mode
return result # Returns the dictionary with the computed losses การเข้ารหัสตำแหน่ง : การเพิ่มข้อมูลตำแหน่งให้กับโมเดลด้วย positional_encodings_table ในคลาส BigramLM เราเพิ่มการเข้ารหัสตำแหน่งลงในการฝังตัวละครของเราเช่นเดียวกับในสถาปัตยกรรมหม้อแปลงไฟฟ้า
ที่นี่เราตั้งค่าและใช้เครื่องมือเพิ่มประสิทธิภาพ AdamW สำหรับการฝึกโมเดลโครงข่ายประสาทเทียมใน PyTorch เครื่องมือเพิ่มประสิทธิภาพ Adam ได้รับความนิยมในสถานการณ์การเรียนรู้เชิงลึกหลายๆ สถานการณ์ เพราะมันรวมข้อดีของส่วนขยายอื่นๆ อีก 2 รายการของการไล่ระดับแบบสุ่ม: AdaGrad และ RMSProp อดัมคำนวณอัตราการเรียนรู้แบบปรับตัวสำหรับแต่ละพารามิเตอร์ นอกเหนือจากการจัดเก็บค่าเฉลี่ยการสลายแบบเอกซ์โพเนนเชียลของการไล่ระดับสีในอดีตเช่น RMSProp แล้ว Adam ยังเก็บค่าเฉลี่ยการสลายแบบเอกซ์โปเนนเชียลของการไล่ระดับสีในอดีต ซึ่งคล้ายกับโมเมนตัม ช่วยให้เครื่องมือเพิ่มประสิทธิภาพสามารถปรับอัตราการเรียนรู้สำหรับแต่ละน้ำหนักของโครงข่ายประสาทเทียม ซึ่งสามารถนำไปสู่การฝึกอบรมที่มีประสิทธิภาพมากขึ้นเกี่ยวกับชุดข้อมูลและสถาปัตยกรรมที่ซับซ้อน
AdamW ปรับเปลี่ยนวิธีที่การรวมน้ำหนักลดลงเข้ากับกระบวนการปรับให้เหมาะสม โดยแก้ไขปัญหาเกี่ยวกับเครื่องมือเพิ่มประสิทธิภาพ Adam ดั้งเดิม โดยที่น้ำหนักลดลงไม่ได้แยกออกจากการอัปเดตการไล่ระดับสีอย่างดี ซึ่งนำไปสู่การประยุกต์ใช้การปรับให้เป็นมาตรฐานที่ต่ำกว่ามาตรฐาน บางครั้งการใช้ AdamW อาจส่งผลให้ประสิทธิภาพการฝึกอบรมดีขึ้นและลักษณะทั่วไปของข้อมูลที่มองไม่เห็น เราเลือก AdamW เนื่องจากความสามารถในการจัดการกับการสูญเสียน้ำหนักได้อย่างมีประสิทธิภาพมากกว่าเครื่องมือเพิ่มประสิทธิภาพ Adam มาตรฐาน ซึ่งอาจนำไปสู่การปรับปรุงการฝึกฝนโมเดลและลักษณะทั่วไป
optimizer = torch . optim . AdamW ( model . parameters (), lr = lr_rate )
for iter in range ( num_iter ):
# estimating the loss for per X interval
if iter % eval_interval == 0 :
losses = estimate_loss ()
print ( f"step { iter } : train loss is { losses [ 'train' ]:.5f } and validation loss is { losses [ 'valid_date' ]:.5f } " )
# sampling a mini batch of data
xb , yb = get_batch ( "train" )
# Forward Pass
logits , loss = model ( xb , yb )
# Zeroing Gradients: Before computing the gradients, existing gradients are reset to zero. This is necessary because gradients accumulate by default in PyTorch.
optimizer . zero_grad ( set_to_none = True )
# Backward Pass or Backpropogation: Computing Gradients
loss . backward ()
# Updating the Model Parameters
optimizer . step ()การเอาใจใส่ตนเองเป็นกลไกที่ช่วยให้แบบจำลองชั่งน้ำหนักความสำคัญของส่วนต่างๆ ของข้อมูลอินพุตที่แตกต่างกัน เป็นองค์ประกอบสำคัญของสถาปัตยกรรม Transformer ซึ่งช่วยให้โมเดลมุ่งเน้นไปที่ส่วนที่เกี่ยวข้องของลำดับอินพุตสำหรับการคาดการณ์
Dot-Product Attention : กลไกความสนใจอย่างง่ายที่คำนวณผลรวมถ่วงน้ำหนักของค่าโดยอิงจาก dot product ระหว่างข้อความค้นหาและคีย์
Scaled Dot-Product Attention : การปรับปรุงความสนใจ dot-product ที่ลดขนาด dot product ตามขนาดของคีย์ ป้องกันไม่ให้การไล่ระดับสีเล็กเกินไปในระหว่างการฝึก
OneHeadSelfAttention : การใช้กลไกการเอาใจใส่ตนเองแบบหัวเดียวที่ช่วยให้แบบจำลองสามารถไปที่ตำแหน่งต่างๆ ของลำดับอินพุตได้ คลาส SelfAttention จะแสดงสัญชาตญาณเบื้องหลังกลไกความสนใจและเวอร์ชันที่ปรับขนาดแล้ว
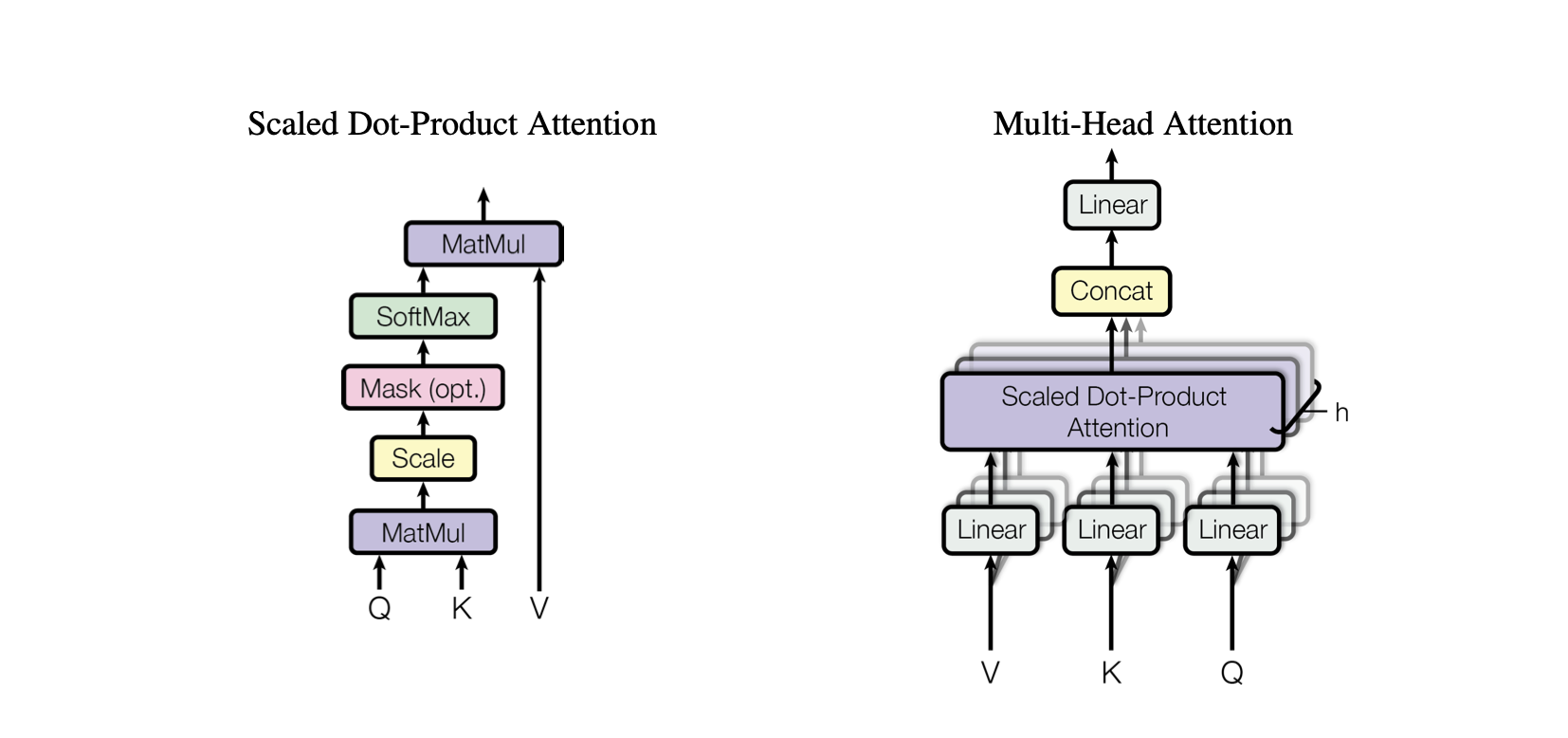
โมเดลที่เกี่ยวข้องแต่ละโมเดลในโครงการ Baby GPT จะต่อยอดจากโมเดลก่อนหน้านี้ทีละน้อย โดยเริ่มจากสัญชาตญาณเบื้องหลังกลไกการเอาใจใส่ตนเอง ตามมาด้วยการใช้งานจริงของดอตโปรดัคและความสนใจดอทโปรดัคที่มีขนาดขยาย และสิ้นสุดในการบูรณาการโมเดลหนึ่ง- หัวหน้าโมดูลความสนใจตนเอง
class SelfAttention ( nn . Module ):
"""Self Attention (One Head)"""
""" d_k = C """
def __init__ ( self , d_k ):
super (). __init__ () #superclass initialization for proper torch functionality
# keys
self . keys = nn . Linear ( d_model , d_k , bias = False )
# queries
self . queries = nn . Linear ( d_model , d_k , bias = False )
# values
self . values = nn . Linear ( d_model , d_k , bias = False )
# buffer for the model
self . register_buffer ( 'tril' , torch . tril ( torch . ones ( block_size , block_size )))
def forward ( self , X ):
"""Computing Attention Matrix"""
B , T , C = X . shape
# Keys matrix K
K = self . keys ( X ) # (B, T, C)
# Query matrix Q
Q = self . queries ( X ) # (B, T, C)
# Scaled Dot Product
scaled_dot_product = Q @ K . transpose ( - 2 , - 1 ) * 1 / math . sqrt ( C ) # (B, T, T)
# Masking upper triangle
scaled_dot_product_masked = scaled_dot_product . masked_fill ( self . tril [: T , : T ] == 0 , float ( '-inf' ))
# SoftMax transformation
attention_matrix = F . softmax ( scaled_dot_product_masked , dim = - 1 ) # (B, T, T)
# Weighted Aggregation
V = self . values ( X ) # (B, T, C)
output = attention_matrix @ V # (B, T, C)
retur คลาส SelfAttention แสดงถึงองค์ประกอบพื้นฐานของรุ่น Transformer ซึ่งห่อหุ้มกลไกการเอาใจใส่ตนเองด้วยหัวเดียว ต่อไปนี้เป็นข้อมูลเชิงลึกเกี่ยวกับส่วนประกอบและกระบวนการ:
การเริ่มต้น : ตัวสร้าง __init__(self, d_k) เริ่มต้นเลเยอร์เชิงเส้นสำหรับคีย์ ข้อความค้นหา และค่า ทั้งหมดนี้มีมิติข้อมูล d_k การแปลงเชิงเส้นเหล่านี้จะฉายอินพุตไปยังพื้นที่ย่อยต่างๆ เพื่อการคำนวณความสนใจในภายหลัง
Buffers : self.register_buffer('tril', torch.tril(torch.ones(block_size, block_size))) ลงทะเบียนเมทริกซ์สามเหลี่ยมด้านล่างเป็นบัฟเฟอร์ถาวรที่ไม่ถือเป็นพารามิเตอร์โมเดล เมทริกซ์นี้ใช้สำหรับการมาสก์ในกลไกความสนใจเพื่อป้องกันไม่ให้มีการพิจารณาตำแหน่งในอนาคตในแต่ละขั้นตอนการคำนวณ (มีประโยชน์ในการเอาใจใส่ตนเองของตัวถอดรหัส)
ส่งต่อ : วิธี forward(self, X) กำหนดการคำนวณที่ดำเนินการทุกครั้งที่เรียกใช้โมดูลการเอาใจใส่ตนเอง
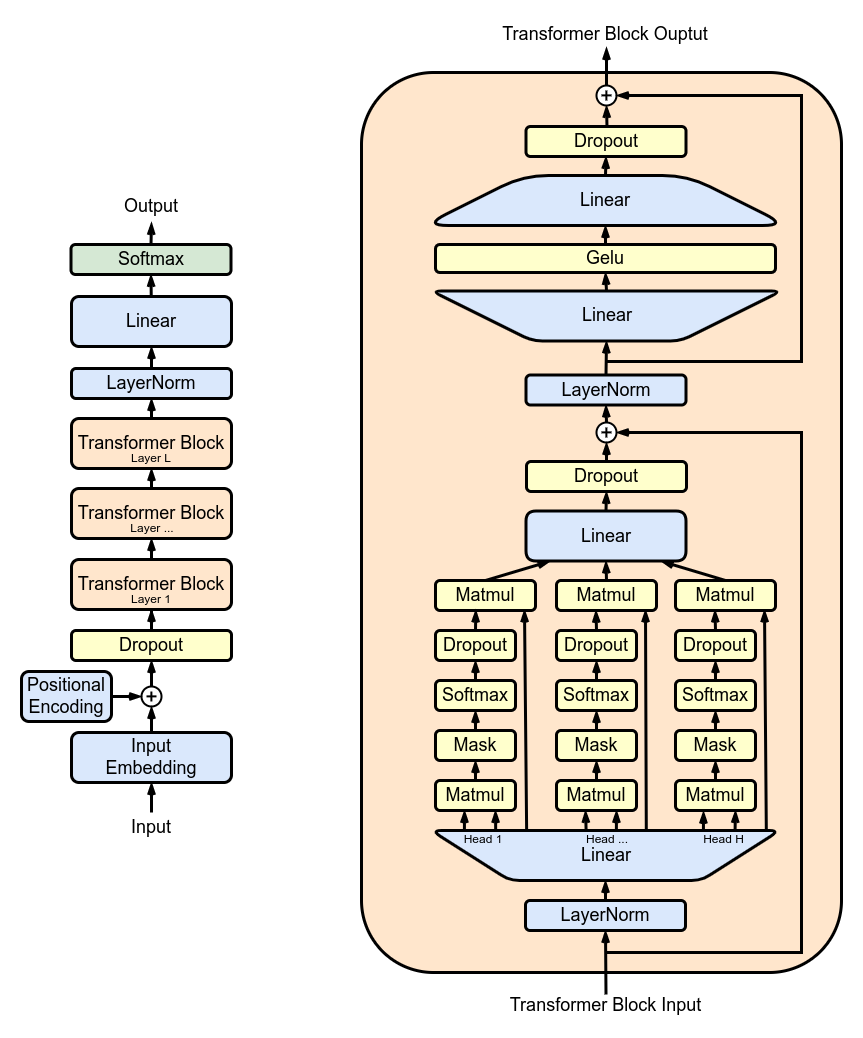
MultiHeadAttention : การรวมเอาต์พุตจากหัว SelfAttention หลายตัวในคลาส MultiHeadAttention คลาส MultiHeadAttention เป็นการนำกลไกการเอาใจใส่ตนเองมาใช้แบบขยายโดยมีหัวเดียวจากขั้นตอนที่แล้ว แต่ตอนนี้หัวสนใจหลายอันทำงานพร้อมกัน โดยแต่ละหัวจะเน้นไปที่ส่วนต่างๆ ของอินพุต
class MultiHeadAttention ( nn . Module ):
"""Multi Head Self Attention"""
"""h: #heads"""
def __init__ ( self , h , d_k ):
super (). __init__ ()
# initializing the heads, we want h times attention heads wit size d_k
self . heads = nn . ModuleList ([ SelfAttention ( d_k ) for _ in range ( h )])
# adding linear layer to project the concatenated heads to the original dimension
self . projections = nn . Linear ( h * d_k , d_model )
# adding dropout layer
self . droupout = nn . Dropout ( dropout_rate )
def forward ( self , X ):
# running multiple self attention heads in parallel and concatinate them at channel dimension
combined_attentions = torch . cat ([ h ( X ) for h in self . heads ], dim = - 1 )
# projecting the concatenated heads to the original dimension
combined_attentions = self . projections ( combined_attentions )
# applying dropout
combined_attentions = self . droupout ( combined_attentions )
return combined_attentions
FeedForward : การใช้โครงข่ายประสาทเทียมแบบฟีดไปข้างหน้าพร้อมการเปิดใช้งาน ReLU ภายในคลาส FeedForward หากต้องการเพิ่มฟีดส่งต่อที่เชื่อมต่ออย่างสมบูรณ์นี้ให้กับโมเดลของเราเช่นเดียวกับใน Transformer Model ดั้งเดิม
class FeedForward ( nn . Module ):
"""FeedForward Layer with ReLU activation function"""
def __init__ ( self , d_model ):
super (). __init__ ()
self . net = nn . Sequential (
# 2 linear layers with ReLU activation function
nn . Linear ( d_model , 4 * d_model ),
nn . ReLU (),
nn . Linear ( 4 * d_model , d_model ),
nn . Dropout ( dropout_rate )
)
def forward ( self , X ):
# applying the feedforward layer
return self . net ( X ) TransformerBlocks : การซ้อนบล็อกหม้อแปลงโดยใช้คลาส Block เพื่อสร้างสถาปัตยกรรมเครือข่ายที่ลึกขึ้น ความลึกและความซับซ้อน: ในโครงข่ายประสาทเทียม ความลึกหมายถึงจำนวนเลเยอร์ที่ใช้ประมวลผลข้อมูล แต่ละเลเยอร์เพิ่มเติม (หรือบล็อก ในกรณีของ Transformers) ช่วยให้เครือข่ายสามารถจับคุณลักษณะที่ซับซ้อนและเป็นนามธรรมของข้อมูลอินพุตได้
การประมวลผลตามลำดับ: บล็อก Transformer แต่ละตัวจะประมวลผลเอาต์พุตของบล็อกก่อนหน้า โดยค่อยๆ สร้างความเข้าใจที่ซับซ้อนมากขึ้นเกี่ยวกับอินพุต การประมวลผลตามลำดับนี้ทำให้เครือข่ายสามารถพัฒนาการนำเสนอข้อมูลเชิงลึกแบบหลายชั้นได้ ส่วนประกอบของบล็อกหม้อแปลง
# ---------------------------------- Blocks ----------------------------------#
class Block ( nn . Module ):
"""Multiple Blocks of Transformer"""
def __init__ ( self , d_model , h ):
super (). __init__ ()
d_k = d_model // h
# Layer 4: Adding Attention layer
self . attention_head = MultiHeadAttention ( h , d_k ) # h heads of d_k dimensional self-attention
# Layer 5: Feed Forward layer
self . feedforward = FeedForward ( d_model )
# Layer Normalization 1
self . ln1 = nn . LayerNorm ( d_model )
# Layer Normalization 2
self . ln2 = nn . LayerNorm ( d_model )
# Adding additional X for Residual Connections
def forward ( self , X ):
X = X + self . attention_head ( self . ln1 ( X ))
X = X + self . feedforward ( self . ln2 ( X ))
return X ResidualConnections : เพิ่มประสิทธิภาพคลาส Block เพื่อรวมการเชื่อมต่อที่เหลือ ปรับปรุงประสิทธิภาพการเรียนรู้ การเชื่อมต่อที่เหลือหรือที่เรียกว่าการเชื่อมต่อแบบข้ามเป็นนวัตกรรมที่สำคัญในการออกแบบโครงข่ายประสาทเทียมระดับลึก โดยเฉพาะในรุ่น Transformer พวกเขาจัดการกับความท้าทายหลักประการหนึ่งในการฝึกอบรมเครือข่ายเชิงลึก: ปัญหาการไล่ระดับสีที่หายไป
# Adding additional X for Residual Connections
def forward ( self , X ):
X = X + self . attention_head ( self . ln1 ( X ))
X = X + self . feedforward ( self . ln2 ( X ))
return X LayerNorm : การเพิ่ม Layer Normalization ให้กับ Transformer ของเรา การทำให้เลเยอร์เอาต์พุตเป็นมาตรฐานด้วย nn.LayerNorm(d_model) ในคลาส Block
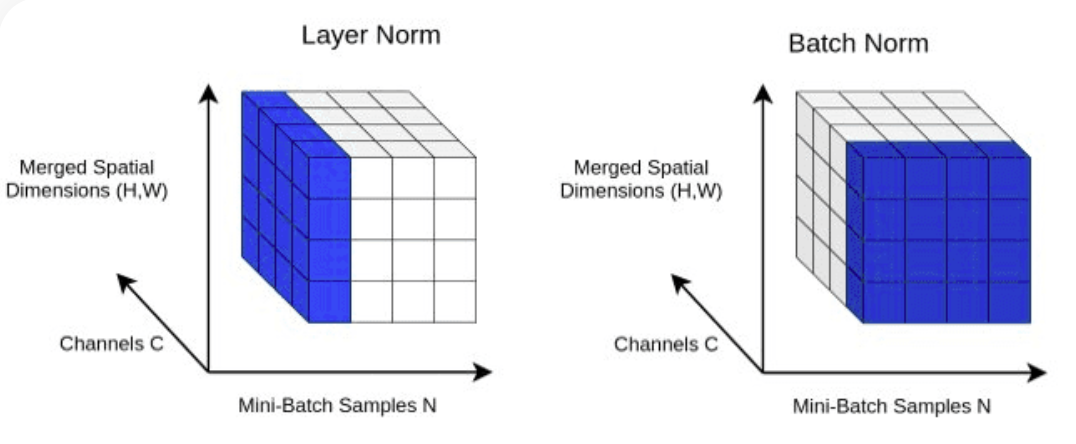
class LayerNorm :
def __init__ ( self , dim , eps = 1e-5 ):
self . eps = eps
self . gamma = torch . ones ( dim )
self . beta = torch . zeros ( dim )
def __call__ ( self , x ):
# orward pass calculaton
xmean = x . mean ( 1 , keepdim = True ) # layer mean
xvar = x . var ( 1 , keepdim = True ) # layer variance
xhat = ( x - xmean ) / torch . sqrt ( xvar + self . eps ) # normalize to unit variance
self . out = self . gamma * xhat + self . beta
return self . out
def parameters ( self ):
return [ self . gamma , self . beta ] การออกกลางคัน : จะถูกเพิ่มในเลเยอร์ SelfAttention และ FeedForward เพื่อเป็นวิธีการทำให้เป็นมาตรฐานเพื่อป้องกันการใส่มากเกินไป เราเพิ่มการออกกลางคันไปที่:
ScaleUp : เพิ่มความซับซ้อนของโมเดลด้วยการขยาย batch_size , block_size , d_model , d_k และ Nx คุณจะต้องมีชุดเครื่องมือ CUDA รวมถึงเครื่องจักรที่มี NVIDIA GPU เพื่อฝึกฝนและทดสอบโมเดลที่ใหญ่กว่านี้
หากคุณต้องการทดลองใช้ CUDA สำหรับการเร่งความเร็ว GPU ตรวจสอบให้แน่ใจว่าคุณได้ติดตั้ง PyTorch เวอร์ชันที่เหมาะสมซึ่งรองรับ CUDA
import torch
torch . cuda . is_available ()คุณสามารถทำได้โดยระบุเวอร์ชัน CUDA ในคำสั่งการติดตั้ง PyTorch เช่นในบรรทัดคำสั่ง:
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu113

