ke dialogue
1.0.0


นี่คือการดำเนินการตามรายงาน:
การเรียนรู้ฐานความรู้พร้อมพารามิเตอร์สำหรับระบบการสนทนาเชิงงาน Andrea Madotto , Samuel Cahyawijaya, Genta Indra Winata, Yan Xu, Zihan Liu, Zhaojiang Lin, การค้นพบ Pascale Fung ของ EMNLP 2020 [PDF]
หากคุณใช้ซอร์สโค้ดหรือชุดข้อมูลใดๆ ที่รวมอยู่ในชุดเครื่องมือนี้ในงานของคุณ โปรดอ้างอิงเอกสารต่อไปนี้ bibtex มีดังต่อไปนี้:
@บทความ{madotto2020การเรียนรู้,
title={การเรียนรู้ฐานความรู้พร้อมพารามิเตอร์สำหรับระบบการสนทนาเชิงงาน},
ผู้แต่ง={มาดอตโต, อันเดรียและจายาวิจายา, ซามูเอลและวินาตา, เกนตา อินดราและซู, หยานและหลิว, ซีฮานและลิน, จ้าวเจียงและฟุง, ปาสกาล},
วารสาร={arXiv พิมพ์ล่วงหน้า arXiv:2009.13656},
ปี={2020}
-
ระบบการสนทนาที่มุ่งเน้นงานมีทั้งแบบแยกส่วนพร้อมการติดตามสถานะการสนทนา (DST) และขั้นตอนการจัดการที่แยกจากกัน หรือสามารถฝึกอบรมได้จากต้นทางถึงปลายทาง ไม่ว่าในกรณีใด ฐานความรู้ (KB) มีบทบาทสำคัญในการตอบสนองคำขอของผู้ใช้ ระบบแบบโมดูลาร์อาศัย DST ในการโต้ตอบกับ KB ซึ่งมีราคาแพงในแง่ของคำอธิบายประกอบและเวลาอนุมาน ระบบ end-to-end ใช้ KB เป็นอินพุตโดยตรง แต่ไม่สามารถปรับขนาดได้เมื่อ KB มีขนาดใหญ่กว่าสองสามร้อยรายการ ในบทความนี้ เราเสนอวิธีการฝัง KB ทุกขนาดลงในพารามิเตอร์โมเดลโดยตรง โมเดลผลลัพธ์ไม่ต้องการการตอบสนอง DST หรือเทมเพลตใดๆ หรือ KB เป็นอินพุต และสามารถอัปเดต KB แบบไดนามิกผ่านการปรับแต่งอย่างละเอียด เราประเมินโซลูชันของเราในชุดข้อมูลการสนทนาเชิงงานห้าชุดที่มีขนาด KB ขนาดเล็ก กลาง และใหญ่ การทดลองของเราแสดงให้เห็นว่าโมเดลแบบ end-to-end สามารถฝังฐานความรู้ในพารามิเตอร์ได้อย่างมีประสิทธิภาพ และบรรลุประสิทธิภาพการแข่งขันในชุดข้อมูลที่ประเมินทั้งหมด
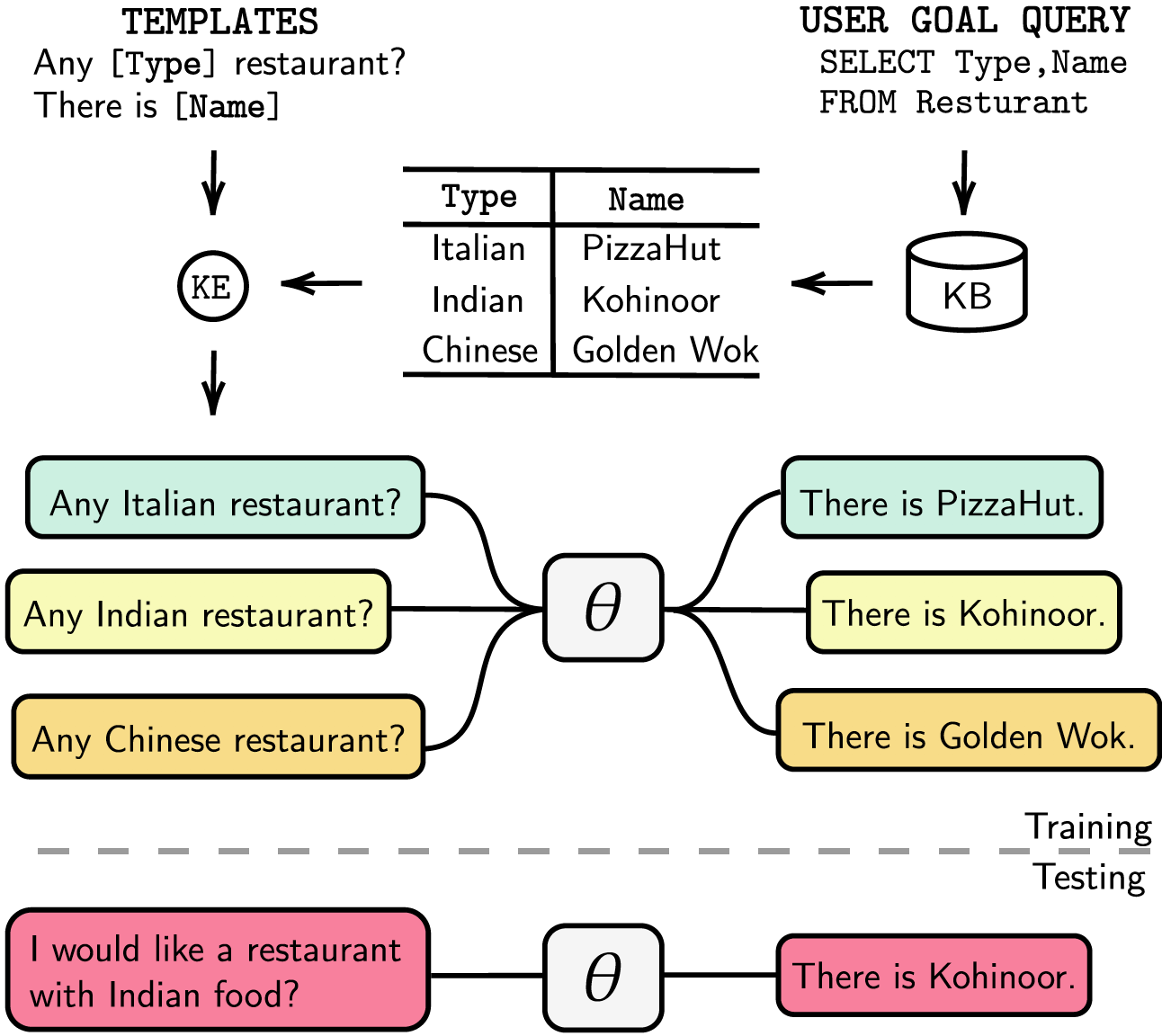
เราแสดงรายการการขึ้นต่อกันของเราใน requirements.txt คุณสามารถติดตั้งการขึ้นต่อกันได้โดยการเรียกใช้
❱❱❱ pip install -r requirements.txt นอกจากนี้ โค้ดของเรายังรองรับ fp16 ด้วย apex ด้วย คุณสามารถค้นหาแพ็คเกจได้จาก https://github.com/NVIDIA/apex
ชุดข้อมูล ดาวน์โหลด ชุดข้อมูล ที่ประมวลผลล่วงหน้าแล้ววางไฟล์ zip ไว้ในโฟลเดอร์ ./knowledge_embed/babi5 แตกไฟล์ zip โดยดำเนินการ
❱❱❱ cd ./knowledge_embed/babi5
❱❱❱ unzip dialog-bAbI-tasks.zipสร้างบทสนทนาแบบแยกศัพท์จากชุดข้อมูล bAbI-5 ผ่าน
❱❱❱ python3 generate_delexicalization_babi.pyสร้างข้อมูลคำศัพท์จากชุดข้อมูล bAbI-5 ผ่าน
❱❱❱ python generate_dialogues_babi5.py --dialogue_path ./dialog-bAbI-tasks/dialog-babi-task5trn_record-delex.txt --knowledge_path ./dialog-bAbI-tasks/dialog-babi-kb-all.txt --output_folder ./dialog-bAbI-tasks --num_augmented_knowledge <num_augmented_knowledge> --num_augmented_dialogue <num_augmented_dialogues> --random_seed 0 โดยที่ <num_augmented_knowledge> สูงสุดคือ 558 (แนะนำ) และ <num_augmented_dialogues> คือ 264 เนื่องจากสอดคล้องกับจำนวนความรู้และจำนวนบทสนทนาในชุดข้อมูล bAbI-5
ปรับแต่ง GPT-2
เราจัดให้ มีจุดตรวจ ของโมเดล GPT-2 ที่ปรับแต่งมาอย่างดีในชุดการฝึก bAbI คุณยังสามารถเลือกที่จะฝึกโมเดลได้ด้วยตัวเองโดยใช้คำสั่งต่อไปนี้
❱❱❱ cd ./modeling/babi5
❱❱❱ python main.py --model_checkpoint gpt2 --dataset BABI --dataset_path ../../knowledge_embed/babi5/dialog-bAbI-tasks --n_epochs <num_epoch> --kbpercentage <num_augmented_dialogues> โปรดทราบว่าค่าของ --kbpercentage เท่ากับ <num_augmented_dialogues> ค่าที่มาจากการใช้ศัพท์ พารามิเตอร์นี้ใช้สำหรับการเลือกไฟล์เสริมที่จะฝังลงในชุดข้อมูลรถไฟ
คุณสามารถประเมินโมเดลได้โดยการรันสคริปต์ต่อไปนี้
❱❱❱ python evaluate.py --model_checkpoint <model_checkpoint_folder> --dataset BABI --dataset_path ../../knowledge_embed/babi5/dialog-bAbI-tasks การให้คะแนน bAbI-5 เมื่อต้องการรันตัวบันทึกสำหรับโมเดลงาน bAbI-5 คุณสามารถรันคำสั่งต่อไปนี้ Scorer จะอ่าน result.json ทั้งหมดภายใต้โฟลเดอร์ runs ที่สร้างจาก evaluate.py
python scorer_BABI5.py --model_checkpoint <model_checkpoint> --dataset BABI --dataset_path ../../knowledge_embed/babi5/dialog-bAbI-tasks --kbpercentage 0ชุดข้อมูล
ดาวน์โหลด ชุดข้อมูล ที่ประมวลผลล่วงหน้าแล้ววางไฟล์ ZIP ไว้ใต้โฟลเดอร์ . ./knowledge_embed/camrest แตกไฟล์ zip โดยดำเนินการ
❱❱❱ cd ./knowledge_embed/camrest
❱❱❱ unzip CamRest.zipสร้างบทสนทนาแบบแยกคำจากชุดข้อมูล CamRest ผ่าน
❱❱❱ python3 generate_delexicalization_CAMREST.pyสร้างข้อมูลคำศัพท์จากชุดข้อมูล CamRest ผ่าน
❱❱❱ python generate_dialogues_CAMREST.py --dialogue_path ./CamRest/train_record-delex.txt --knowledge_path ./CamRest/KB.json --output_folder ./CamRest --num_augmented_knowledge <num_augmented_knowledge> --num_augmented_dialogue <num_augmented_dialogues> --random_seed 0 โดยที่ <num_augmented_knowledge> สูงสุดคือ 201 (แนะนำ) และ <num_augmented_dialogues> คือ 156 ค่อนข้างมาก เนื่องจากสอดคล้องกับจำนวนความรู้และจำนวนบทสนทนาในชุดข้อมูล CamRest
ปรับแต่ง GPT-2
เราจัดเตรียม จุดตรวจ ของรุ่น GPT-2 ที่ได้รับการปรับแต่งอย่างละเอียดในชุดฝึกอบรม CamRest คุณยังสามารถเลือกที่จะฝึกโมเดลได้ด้วยตัวเองโดยใช้คำสั่งต่อไปนี้
❱❱❱ cd ./modeling/camrest/
❱❱❱ python main.py --model_checkpoint gpt2 --dataset CAMREST --dataset_path ../../knowledge_embed/camrest/CamRest --n_epochs <num_epoch> --kbpercentage <num_augmented_dialogues> โปรดทราบว่าค่าของ --kbpercentage เท่ากับ <num_augmented_dialogues> ค่าที่มาจากการใช้ศัพท์ พารามิเตอร์นี้ใช้สำหรับการเลือกไฟล์เสริมที่จะฝังลงในชุดข้อมูลรถไฟ
คุณสามารถประเมินโมเดลได้โดยการรันสคริปต์ต่อไปนี้
❱❱❱ python evaluate.py --model_checkpoint <model_checkpoint_folder> --dataset CAMREST --dataset_path ../../knowledge_embed/camrest/CamRest การให้คะแนน CamRest หากต้องการรันตัวบันทึกสำหรับโมเดลงาน bAbI 5 คุณสามารถรันคำสั่งต่อไปนี้ Scorer จะอ่าน result.json ทั้งหมดภายใต้โฟลเดอร์ runs ที่สร้างจาก evaluate.py
python scorer_CAMREST.py --model_checkpoint <model_checkpoint> --dataset CAMREST --dataset_path ../../knowledge_embed/camrest/CamRest --kbpercentage 0ชุดข้อมูล
ดาวน์โหลด ชุดข้อมูล ที่ประมวลผลล่วงหน้าแล้ววางไว้ใต้โฟลเดอร์ . ./knowledge_embed/smd
❱❱❱ cd ./knowledge_embed/smd
❱❱❱ unzip SMD.zipปรับแต่ง GPT-2
เราจัดเตรียม จุดตรวจ ของโมเดล GPT-2 ที่ได้รับการปรับแต่งอย่างละเอียดในชุดฝึกอบรม SMD ดาวน์โหลดจุดตรวจสอบและวางไว้ใต้โฟลเดอร์ . ./modeling
❱❱❱ cd ./knowledge_embed/smd
❱❱❱ mkdir ./runs
❱❱❱ unzip ./knowledge_embed/smd/SMD_gpt2_graph_False_adj_False_edge_False_unilm_False_flattenKB_False_historyL_1000000000_lr_6.25e-05_epoch_10_weighttie_False_kbpercentage_0_layer_12.zip -d ./runsคุณยังสามารถเลือกที่จะฝึกโมเดลได้ด้วยตัวเองโดยใช้คำสั่งต่อไปนี้
❱❱❱ cd ./modeling/smd
❱❱❱ python main.py --dataset SMD --lr 6.25e-05 --n_epochs 10 --kbpercentage 0 --layers 12เตรียมเสวนาที่ฝังความรู้
ประการแรก เราต้องสร้างฐานข้อมูลสำหรับการสืบค้น SQL
❱❱❱ cd ./knowledge_embed/smd
❱❱❱ python generate_dialogues_SMD.py --build_db --split test จากนั้นเราจะสร้างบทสนทนาตามเทมเพลตที่ออกแบบไว้ล่วงหน้าตามโดเมน คำสั่งต่อไปนี้ช่วยให้คุณสร้างบทสนทนาในโดเมน weather ได้ โปรดแทนที่ weather ด้วย navigate หรือ schedule ใน dialogue_path และอาร์กิวเมนต์ domain หากคุณต้องการสร้างบทสนทนาในอีกสองโดเมน คุณยังสามารถเปลี่ยนจำนวนเทมเพลตที่ใช้ในกระบวนการเปลี่ยนคำศัพท์ใหม่ได้ด้วยการเปลี่ยนอาร์กิวเมนต์ num_augmented_dialogue
❱❱❱ python generate_dialogues_SMD.py --split test --dialogue_path ./templates/weather_template.txt --domain weather --num_augmented_dialogue 100 --output_folder ./SMD/testปรับโมเดล GPT-2 ที่ปรับแต่งอย่างละเอียดเข้ากับชุดทดสอบ
❱❱❱ python evaluate_finetune.py --dataset SMD --model_checkpoint runs/SMD_gpt2_graph_False_adj_False_edge_False_unilm_False_flattenKB_False_historyL_1000000000_lr_6.25e-05_epoch_10_weighttie_False_kbpercentage_0_layer_12 --top_k 1 --eval_indices 0,303 --filter_domain ""คุณยังเร่งกระบวนการปรับแต่งให้เร็วขึ้นได้ด้วยการทำการทดสอบแบบขนาน โปรดแก้ไขการตั้งค่า GPU ใน #L14 ของโค้ด
❱❱❱ python runner_expe_SMD.py ชุดข้อมูล
ดาวน์โหลด ชุดข้อมูล ที่ประมวลผลล่วงหน้าแล้ววางไว้ใต้โฟลเดอร์ . ./knowledge_embed/mwoz
❱❱❱ cd ./knowledge_embed/mwoz
❱❱❱ unzip mwoz.zipเตรียมบทสนทนาที่ฝังความรู้ (คุณสามารถข้ามขั้นตอนนี้ได้ หากคุณดาวน์โหลดไฟล์ zip ด้านบน)
คุณสามารถเตรียมชุดข้อมูลได้โดยการรัน
❱❱❱ bash generate_MWOZ_all_data.shเชลล์สคริปต์สร้างบทสนทนาแบบแยกศัพท์จากชุดข้อมูล MWOZ โดยการเรียก
❱❱❱ python generate_delex_MWOZ_ATTRACTION.py
❱❱❱ python generate_delex_MWOZ_HOTEL.py
❱❱❱ python generate_delex_MWOZ_RESTAURANT.py
❱❱❱ python generate_delex_MWOZ_TRAIN.py
❱❱❱ python generate_redelex_augmented_MWOZ.py
❱❱❱ python generate_MWOZ_dataset.pyปรับแต่ง GPT-2
เราจัดให้ มีจุดตรวจ ของโมเดล GPT-2 ที่ปรับแต่งมาอย่างดีในชุดการฝึก MWOZ ดาวน์โหลดจุดตรวจสอบและวางไว้ใต้โฟลเดอร์ . ./modeling
❱❱❱ cd ./knowledge_embed/mwoz
❱❱❱ mkdir ./runs
❱❱❱ unzip ./mwoz.zip -d ./runsคุณยังสามารถเลือกที่จะฝึกโมเดลได้ด้วยตัวเองโดยใช้คำสั่งต่อไปนี้
❱❱❱ cd ./modeling/mwoz
❱❱❱ python main.py --model_checkpoint gpt2 --dataset MWOZ_SINGLE --max_history 50 --train_batch_size 6 --kbpercentage 100 --fp16 O2 --gradient_accumulation_steps 3 --balance_sampler --n_epochs 10 การเริ่มต้นใช้งาน เราใช้รุ่นเซิร์ฟเวอร์ชุมชน neo4j และไลบรารี apoc สำหรับการประมวลผลข้อมูลกราฟ apoc ถูกใช้เพื่อทำให้แบบสอบถามขนานกันใน neo4j เพื่อให้เราสามารถประมวลผลกราฟขนาดใหญ่ได้เร็วขึ้น
ก่อนที่จะดำเนินการในส่วนชุดข้อมูล คุณต้องแน่ใจว่าคุณได้ติดตั้ง neo4j (https://neo4j.com/download-center/#community) และ apoc (https://neo4j.com/developer/neo4j-apoc/) แล้ว บนระบบของคุณ
หากคุณไม่คุ้นเคยกับไวยากรณ์ CYPHER และ apoc คุณสามารถทำตามบทช่วยสอนใน https://neo4j.com/developer/cypher/ และ https://neo4j.com/blog/intro-user-defined-procedures-apoc/
ชุดข้อมูล ดาวน์โหลด ชุดข้อมูล ต้นฉบับและวางไฟล์ zip ไว้ในโฟลเดอร์ . ./knowledge_embed/opendialkg แตกไฟล์ zip โดยดำเนินการ
❱❱❱ cd ./knowledge_embed/opendialkg
❱❱❱ unzip https://drive.google.com/file/d/1llH4-4-h39sALnkXmGR8R6090xotE0PE/view?usp=sharing.zipสร้างบทสนทนาแบบแยกศัพท์จากชุดข้อมูล opendialkg ผ่าน ( คำเตือน : ต้องใช้เวลาทำงานประมาณ 12 ชั่วโมง)
❱❱❱ python3 generate_delexicalization_DIALKG.py สคริปต์นี้จะสร้าง ./opendialkg/dialogkg_train_meta.pt ซึ่งจะใช้เพื่อสร้างบทสนทนาที่ใช้คำศัพท์ จากนั้นคุณสามารถสร้างบทสนทนาแบบศัพท์จากชุดข้อมูล opendialkg ผ่านทาง
❱❱❱ python generate_dialogues_DIALKG.py --random_seed <random_seed> --batch_size 100 --max_iteration <max_iter> --stop_count <stop_count> --connection_string bolt://localhost:7687 สคริปต์นี้จะสร้างตัวอย่างบทสนทนาที่ตัวอย่าง batch_size * max_iter แต่ในทุกชุดอาจมีความเป็นไปได้ที่ไม่มีตัวเลือกที่ถูกต้องและส่งผลให้มีตัวอย่างน้อยลง จำนวนการสร้างถูกจำกัดด้วยปัจจัยอื่นที่เรียกว่า stop_count ซึ่งจะหยุดการสร้างหากจำนวนตัวอย่างที่สร้างขึ้นมากกว่าเท่ากับ stop_count ที่ระบุ ไฟล์จะสร้างไฟล์ 4 ไฟล์: ./opendialkg/db_count_records_{random_seed}.csv , ./opendialkg/used_count_records_{random_seed}.csv และ ./opendialkg/generation_iteration_{random_seed}.csv ซึ่งใช้สำหรับตรวจสอบการเปลี่ยนแปลงการกระจายของ นับในฐานข้อมูล และ ./opendialkg/generated_dialogue_bs100_rs{random_seed}.json ซึ่งมีตัวอย่างที่สร้างขึ้น
หมายเหตุ :
neo4j ภายใน generate_delexicalization_DIALKG.py และ generate_dialogues_DIALKG.py ด้วยตนเองปรับแต่ง GPT-2
เราจัดเตรียม จุดตรวจ ของโมเดล GPT-2 ที่ปรับแต่งมาอย่างดีในชุดการฝึก opendialkg คุณยังสามารถเลือกที่จะฝึกโมเดลได้ด้วยตัวเองโดยใช้คำสั่งต่อไปนี้
❱❱❱ cd ./modeling/opendialkg
❱❱❱ python main.py --dataset_path ../../knowledge_embed/opendialkg/opendialkg --model_checkpoint gpt2 --dataset DIALKG --n_epochs 50 --kbpercentage <random_seed> --train_batch_size 8 --valid_batch_size 8 โปรดทราบว่าค่าของ --kbpercentage เท่ากับ <random_seed> ค่าที่มาจากพจนานุกรม พารามิเตอร์นี้ใช้สำหรับการเลือกไฟล์เสริมที่จะฝังลงในชุดข้อมูลรถไฟ
คุณสามารถประเมินโมเดลได้โดยการรันสคริปต์ต่อไปนี้
❱❱❱ python evaluate.py --model_checkpoint <model_checkpoint_folder> --dataset DIALKG --dataset_path ../../knowledge_embed/opendialkg/opendialkg การให้คะแนน OpenDialKG หากต้องการรันตัวบันทึกสำหรับโมเดลงาน bAbI-5 คุณสามารถรันคำสั่งต่อไปนี้ Scorer จะอ่าน result.json ทั้งหมดภายใต้โฟลเดอร์ runs ที่สร้างจาก evaluate.py
python scorer_DIALKG5.py --model_checkpoint <model_checkpoint> --dataset DIALKG ../../knowledge_embed/opendialkg/opendialkg --kbpercentage 0 สำหรับรายละเอียดเกี่ยวกับการทดลอง ไฮเปอร์พารามิเตอร์ และผลการประเมิน คุณสามารถดูได้จากเอกสารหลักและเนื้อหาเสริมในงานของเรา


