spelltest
v0.0.4
- หากคุณพบว่าโครงการนี้มีประโยชน์ โปรดพิจารณาให้ดาวแก่โครงการนี้! การสนับสนุนของคุณเป็นแรงบันดาลใจให้ฉันปรับปรุงมันต่อไป! -
แอปพลิเคชันที่ขับเคลื่อนด้วย AI ในปัจจุบันส่วนใหญ่ขึ้นอยู่กับโมเดลภาษาขนาดใหญ่ (LLM) เช่น GPT-4 เพื่อนำเสนอโซลูชันที่เป็นนวัตกรรม อย่างไรก็ตาม การรับรองว่าพวกเขาให้คำตอบที่เกี่ยวข้องและถูกต้องในทุกสถานการณ์ถือเป็นความท้าทาย การทดสอบการสะกดแก้ไขปัญหานี้โดยการจำลองการตอบสนองของ LLM โดยใช้ลักษณะผู้ใช้สังเคราะห์และเทคนิคการประเมินเพื่อประเมินการตอบสนองเหล่านี้โดยอัตโนมัติ (แต่ยังต้องมีการควบคุมดูแลโดยมนุษย์)
spellforge.yaml : project_name : ...
# describe users
users :
...
# describe quality metrics
metrics :
...
# describe prompts of your LLM app
prompts :
...
# finally describe simulations
simulations :
...

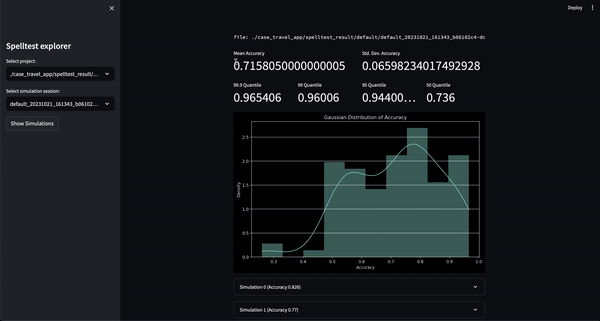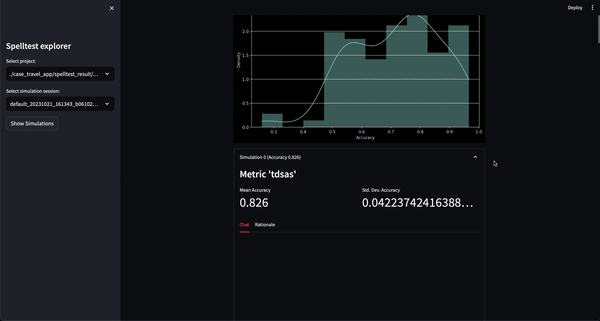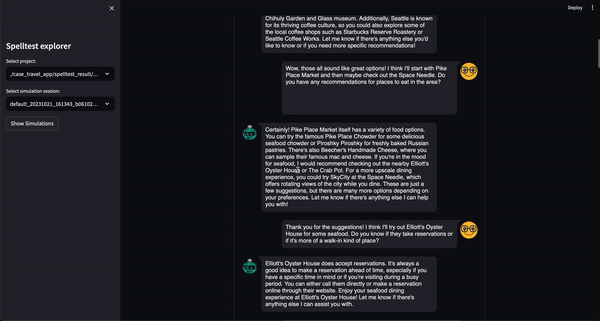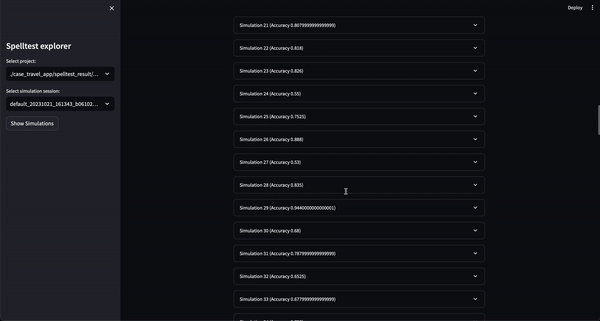
ตอนนี้คุณสามารถลองใช้โปรเจ็กต์นี้ในสภาพแวดล้อมเชิงโต้ตอบบนเว็บผ่าน Google Colab ได้แล้ว! ไม่จำเป็นต้องติดตั้ง
เพียงคลิกที่ป้ายด้านบนเพื่อเริ่มต้น!
รับประกันคุณภาพ : จำลองการโต้ตอบของผู้ใช้เพื่อการตอบสนองที่เหมาะสมที่สุด
ประสิทธิภาพและการประหยัด : ประหยัดค่าใช้จ่ายในการทดสอบด้วยตนเอง
บูรณาการขั้นตอนการทำงานที่ราบรื่น : ลงตัวกับกระบวนการพัฒนาของคุณได้อย่างราบรื่น
โปรดทราบว่านี่เป็นเวอร์ชันแรกของการทดสอบการสะกดคำ ด้วยเหตุนี้จึงยังไม่ได้รับการทดสอบอย่างกว้างขวางในสภาพแวดล้อมและกรณีการใช้งานที่หลากหลาย ในการตัดสินใจใช้เวอร์ชันนี้ แสดงว่าคุณยอมรับว่าคุณกำลังใช้กรอบงานการทดสอบการสะกดคำโดยยอมรับความเสี่ยงเอง เราขอแนะนำให้ผู้ใช้รายงานปัญหาหรือข้อบกพร่องที่พบเพื่อช่วยในการปรับปรุงโครงการ
ในส่วนของค่าใช้จ่ายในการดำเนินงาน สิ่งสำคัญที่ควรทราบก็คือ การรันการจำลองด้วย Spelltest จะมีค่าใช้จ่ายตามการใช้งาน OpenAI API ไม่มีการประมาณต้นทุนหรือจำกัดงบประมาณในขณะนี้ สำหรับบริบท การเรียกใช้การจำลอง 100 ชุดอาจมีค่าใช้จ่ายประมาณ 0.7 ถึง 1.8 เหรียญสหรัฐ (gpt-3.5-turbo) ขึ้นอยู่กับปัจจัยหลายประการ รวมถึง LLM ที่เฉพาะเจาะจงและความซับซ้อนของการจำลอง
เมื่อพิจารณาถึงต้นทุนเหล่านี้แล้ว เราขอแนะนำอย่างยิ่งให้เริ่มต้นด้วยการจำลองจำนวนน้อยลงเพื่อลดต้นทุนเริ่มต้นและช่วยให้คุณประมาณค่าใช้จ่ายในอนาคตได้ดีขึ้น เมื่อคุณคุ้นเคยกับเฟรมเวิร์กและผลกระทบด้านต้นทุนมากขึ้น คุณสามารถปรับจำนวนการจำลองตามงบประมาณและความต้องการของคุณได้
โปรดจำไว้ว่าเป้าหมายของ Spelltest คือการรับรองการตอบสนองคุณภาพสูงจาก LLM ในขณะที่ยังคงความคุ้มค่าที่สุดเท่าที่จะเป็นไปได้ในกระบวนการพัฒนาและทดสอบ AI ของคุณ

Spelltest ใช้แนวทางที่โดดเด่นในการประกันคุณภาพ ด้วยการใช้บุคลิกของผู้ใช้สังเคราะห์ เราไม่เพียงแต่จำลองการโต้ตอบเท่านั้น แต่ยังรวบรวมความคาดหวังของผู้ใช้ที่ไม่ซ้ำใครด้วย โดยจัดให้มีสภาพแวดล้อมที่มีบริบทมากมายสำหรับการทดสอบ บริบทเชิงลึกนี้ช่วยให้เราประเมินคุณภาพของการตอบสนอง LLM ในลักษณะที่สะท้อนการใช้งานในโลกแห่งความเป็นจริงได้อย่างใกล้ชิด
ผลลัพธ์? คะแนนคุณภาพตั้งแต่ 0.0 ถึง 1.0 ทำหน้าที่เป็นการซ้อมเครื่องแต่งกายที่ครอบคลุมก่อนที่แอปของคุณจะได้พบกับผู้ใช้จริง ไม่ว่าจะอยู่ในโหมดแชทหรือโหมดเสร็จสิ้น Spelltest ช่วยให้มั่นใจว่าการตอบสนองของ LLM สอดคล้องกับความคาดหวังของผู้ใช้อย่างใกล้ชิด ช่วยเพิ่มความพึงพอใจของผู้ใช้โดยรวม
ติดตั้งเฟรมเวิร์กโดยใช้ pip:
pip install spelltest .spellforge.yaml เป็นศูนย์กลางของการทดสอบการสะกดคำ ซึ่งประกอบด้วยโปรไฟล์ผู้ใช้สังเคราะห์ ตัวชี้วัด ข้อความแจ้ง และการจำลอง ด้านล่างนี้คือรายละเอียดของโครงสร้าง:
ผู้ใช้สังเคราะห์เลียนแบบผู้ใช้ในชีวิตจริง โดยแต่ละคนมีภูมิหลัง ความคาดหวัง และความเข้าใจในแอปไม่ซ้ำกัน การกำหนดค่าสำหรับผู้ใช้สังเคราะห์ประกอบด้วย:
พรอมต์ย่อย : เหล่านี้เป็นองค์ประกอบเชิงพรรณนาที่ให้บริบทแก่โปรไฟล์ผู้ใช้ ประกอบด้วย:
description : บทสรุปเกี่ยวกับผู้ใช้สังเคราะห์expectation : สิ่งที่ผู้ใช้คาดหวังจากการโต้ตอบuser_knowledge_about_app : ระดับความคุ้นเคยกับแอปผู้ใช้สังเคราะห์แต่ละคนยังมี:
name : ตัวระบุสำหรับผู้ใช้สังเคราะห์llm_name : โมเดล LLM ที่จะใช้ (ทดสอบกับรุ่น OpenAI เท่านั้น)temperature : ...ตัวอย่างการกำหนดค่าผู้ใช้สังเคราะห์:
...
nomad :
name : " Busy Nomad in Seattle "
llm_name : gpt-3.5-turbo
temperature : 0.7
description : " You're a very busy nomad who struggles with planning. You're moved to Seattle and looking at how to spend your first Saturday exploring the city "
expectation : " Well-planned objective, detailed, and comprehensive schedule that meets user's requirements "
user_knowledge_about_app : " The app receives text input about travel requirements (i.e., place, preferences, short description of the family and their interests) and returns a travel schedule that accommodates all family members’ needs and interests. "
metrics : __all__
... ตัวชี้วัดใช้ในการประเมินและให้คะแนนการตอบสนองของ LLM แต่ละเมตริกจะมี description ย่อยที่ให้บริบทเกี่ยวกับสิ่งที่เมตริกประเมิน
ตัวอย่างการกำหนดค่าเมตริกอย่างง่าย:
...
metrics :
accuracy :
description : " Accuracy "
...ตัวอย่างการกำหนดค่าเมตริกที่ซับซ้อน/กำหนดเอง:
...
metrics :
tpas :
description : " TPAS - The Travel Plan Accuracy Score. This metric measures the accuracy of the generated response by evaluating the inclusion of the expected output, well-scheduled travel plan and nothing else. The TPAS is a numerical value between 0 and 100, with 100 representing a perfect match to the expected output and 0 indicating non-accurate result. "
... ข้อความแจ้งคือคำถามหรืองานที่แอปทำ สิ่งเหล่านี้ถูกใช้ในการจำลองเพื่อทดสอบความสามารถของ LLM ในการสร้างการตอบสนองที่เหมาะสม แต่ละพร้อมท์ถูกกำหนดด้วย description และข้อความหรืองาน prompt จริง
...
prompts :
book_flight :
file : book-flight-prompt.txt
... การจำลองระบุสถานการณ์การทดสอบ องค์ประกอบหลัก ได้แก่ prompt , users , llm_name , temperature , size , chat_mode และ quality_threshold
project_name : " Travel schedule app "
# describe users
users :
nomad :
name : " Busy Nomad in Seattle "
llm_name : gpt-3.5-turbo
temperature : 0.7
description : " You're a very busy nomad who struggles with planning. You're moved to Seattle and looking at how to spend your first Saturday exploring the city "
expectation : " Well-planned objective, detailed, and comprehensive schedule that meets user's requirements "
user_knowledge_about_app : " The app receives text input about travel requirements (i.e., place, preferences, short description of the family and their interests) and returns a travel schedule that accommodates all family members’ needs and interests. "
metrics : __all__
family_weekend :
name : " The Adventurous Family from Chicago "
llm_name : gpt-3.5-turbo
temperature : 0.7
description : " You're a family of four (two adults and two children) based in Chicago looking to plan an exciting, yet relaxed weekend getaway outside the city. The objective is to explore a new environment that is kid-friendly and offers a mix of adventure and downtime. "
expectation : " A balanced travel schedule that combines fun activities suitable for children and relaxation opportunities for the entire family, considering travel times and kid-friendly amenities. "
user_knowledge_about_app : " The app receives text input about travel requirements (i.e., place, preferences, short description of the family and their interests) and returns a travel schedule that accommodates all family members’ needs and interests. "
metrics : __all__
retired_couple :
name : " Retired Couple Exploring Berlin "
llm_name : gpt-3.5-turbo
temperature : 0.7
description : " You're a retired couple from the US, wanting to explore Berlin and soak in its rich history and culture over a 10-day vacation. You’re looking for a mixture of sightseeing, cultural experiences, and leisure activities, with a comfortable pace suitable for your age. "
expectation : " A comprehensive travel plan that provides a relaxed pace, ensuring enough time to explore and enjoy each location, and includes historical and cultural experiences. It should also consider comfort and accessibility. "
user_knowledge_about_app : " The app accepts text input detailing travel requirements (i.e., destination, preferences, duration, and a brief description of travelers) and returns a well-organized travel itinerary tailored to those specifics. "
metrics : __all__
# describe quality metrics
metrics :
tpas : # name of your metric
description : " TPAS - The Travel Plan Accuracy Score. This metric measures the accuracy of the generated response by evaluating the inclusion of the expected output, well-scheduled travel plan and nothing else. The TPAS is a numerical value between 0 and 100, with 100 representing a perfect match to the expected output and 0 indicating non-accurate result. "
# describe prompts
prompts :
smart-prompt :
file : ./smart-prompt # expected that prompt located in this file
# finally describe simulations
simulations :
test1 :
prompt : smart-prompt
users : __all__
llm_name : gpt-3.5-turbo
temperature : 0.7
size : 5
chat_mode : true # completion mode if `false`
quality_threshold : 80
การกำหนดค่าแบบเต็มพร้อมไฟล์พร้อมต์อยู่ที่นี่
ต้นทุน OpenAI : การใช้เฟรมเวิร์กนี้อาจนำไปสู่การร้องขอ OpenAI จำนวนมาก โดยเฉพาะอย่างยิ่งเมื่อรันการจำลองอย่างกว้างขวาง ซึ่งอาจส่งผลให้บัญชี OpenAI ของคุณมีค่าใช้จ่ายจำนวนมาก ตรวจสอบให้แน่ใจว่าคุณคำนึงถึงงบประมาณ OpenAI ของคุณและเข้าใจรูปแบบการกำหนดราคา ฉันไม่รับผิดชอบต่อค่าใช้จ่ายใดๆ ที่เกิดขึ้น
การเปิดตัวครั้งแรก : Spelltest เวอร์ชันนี้ยังอยู่ในช่วงเริ่มต้นและไม่มีการรับประกันความเสถียร โปรดใช้ด้วยความระมัดระวังและให้ข้อเสนอแนะหรือรายงานปัญหาได้ตามสบาย
export OPENAI_API_KEYS= < your api keys >
spelltest --config_file .spellforge.yamlตรวจสอบผลลัพธ์ของการจำลอง
spelltest --analyzeการรวมการทดสอบการสะกดเข้ากับไปป์ไลน์การเผยแพร่ของคุณจะช่วยปรับปรุงกลยุทธ์การใช้งานของคุณโดยผสมผสานการทดสอบอัตโนมัติที่สอดคล้องกัน ขั้นตอนสำคัญนี้ช่วยให้แน่ใจว่าแอปพลิเคชันที่ใช้ LLM ของคุณรักษามาตรฐานคุณภาพระดับสูงโดยการจำลองและประเมินการโต้ตอบของผู้ใช้อย่างเป็นระบบก่อนที่จะเผยแพร่ใดๆ แนวทางปฏิบัตินี้สามารถประหยัดเวลาได้มาก ลดข้อผิดพลาดด้วยตนเอง และให้ข้อมูลเชิงลึกที่สำคัญว่าการเปลี่ยนแปลงหรือคุณสมบัติใหม่จะส่งผลต่อประสบการณ์ผู้ใช้อย่างไร
คู่มือนี้จะแนะนำคุณตลอดขั้นตอนการตั้งค่าและทำให้การผสานรวมอย่างต่อเนื่องสำหรับโปรเจ็กต์ของคุณเป็นแบบอัตโนมัติ
ก่อนที่คุณจะเริ่มต้น ตรวจสอบให้แน่ใจว่าคุณมีข้อกำหนดเบื้องต้นต่อไปนี้:
พื้นที่เก็บข้อมูล GitHub ที่มีโปรเจ็กต์ของคุณ
เข้าถึง SpellForge ด้วยคีย์ API หากคุณยังไม่มี คุณสามารถขอรับได้จากเว็บไซต์ SpellForge
คีย์ OpenAI API สำหรับการใช้บริการ OpenAI หากคุณยังไม่มี คุณสามารถขอรับได้จากเว็บไซต์ OpenAI
.spellforge.yaml สร้างไฟล์ .spellforge.yaml ในไดเรกทอรีรากของโปรเจ็กต์ของคุณ ไฟล์นี้จะมีคำแนะนำสำหรับการทดสอบการสะกด
สร้างไฟล์เวิร์กโฟลว์ GitHub Actions เช่น .github/workflows/.spelltest.yaml เพื่อทำการทดสอบ SpellForge โดยอัตโนมัติ ใส่รหัสต่อไปนี้ลงในไฟล์นี้:
# .spelltest.yaml
name : Spelltest CI
on :
push :
branches : [ "main" ]
env :
SPELLTEST_CONFIG_PATH : ${{ env.SPELLTEST_CONFIG_PATH }}
OPENAI_API_KEY : ${{ secrets.OPENAI_API_KEY }}
jobs :
test :
runs-on : ubuntu-latest
steps :
- uses : actions/checkout@v3
- name : Install SpellTest library
run : pip install spelltest
- name : Run tests
run : spelltest --config_file $SPELLTEST_CONFIG_PATHเวิร์กโฟลว์นี้จะถูกทริกเกอร์ทุกครั้งที่กดไปที่สาขาหลัก และจะดำเนินการทดสอบ SpellForge ของคุณ
ไปที่ที่เก็บ GitHub ของคุณแล้วไปที่แท็บ "การตั้งค่า"
ในส่วน "ความลับ" ให้เพิ่มความลับใหม่ 2 รายการ:
OPENAI_API_KEY : ตั้งค่าความลับนี้เป็นคีย์ OpenAI API ของคุณ
เพิ่มตัวแปรสภาพแวดล้อม GitHub:
SPELLTEST_CONFIG_PATH : ตั้งค่าตัวแปรนี้เป็นพาธแบบเต็มไปยังไฟล์ .spellforge.yaml ภายในที่เก็บของคุณ
สิ่งเหล่านี้เป็นการจำลองการโต้ตอบของผู้ใช้จริงด้วยคุณลักษณะเฉพาะและความคาดหวัง
พื้นหลังของผู้ใช้ (ช่อง description ใน .spellforge.yaml ): ข้อความย่อยที่ให้ภาพรวมว่าผู้ใช้สังเคราะห์รายนี้คือใคร และปัญหาที่พวกเขาต้องการแก้ไขโดยใช้แอป เช่น นักเดินทางที่จัดการตารางเวลาของตน
ความคาดหวังของผู้ใช้ ( ฟิลด์ expectation ): พร้อมท์ย่อยที่กำหนดสิ่งที่ผู้ใช้สังเคราะห์คาดว่าจะเป็นการโต้ตอบที่ประสบความสำเร็จหรือวิธีแก้ปัญหาจากการใช้แอป
การตระหนักรู้ด้านสิ่งแวดล้อม (ฟิลด์ user_knowledge_about_app ): พรอมต์ย่อยที่ทำให้แน่ใจว่าผู้ใช้สังเคราะห์เข้าใจบริบทของแอปพลิเคชัน เพื่อให้มั่นใจว่าสถานการณ์การทดสอบที่สมจริง
พรอมต์ย่อยที่แสดงถึงมาตรฐานหรือเกณฑ์ที่ใช้ในการประเมินและให้คะแนนการตอบสนองที่สร้างโดย LLM ในการจำลอง การวัดมีตั้งแต่การวัดทั่วไปไปจนถึงการวัดแบบกำหนดเองเฉพาะการใช้งานมากขึ้น
ตัวอย่างเมตริกทั่วไป:
ความคล้ายคลึงกันทางความหมาย : วัดว่าคำตอบที่ให้มานั้นใกล้เคียงกับคำตอบที่คาดไว้มากน้อยเพียงใดในแง่ของความหมาย
ความเป็นพิษ : ประเมินการตอบสนองต่อภาษาหรือเนื้อหาใดๆ ที่อาจถือว่าไม่เหมาะสมหรือเป็นอันตราย
ความคล้ายคลึงกันของโครงสร้าง : เปรียบเทียบโครงสร้างและรูปแบบของการตอบสนองที่สร้างขึ้นกับมาตรฐานที่กำหนดไว้ล่วงหน้าหรือผลลัพธ์ที่คาดหวัง
ตัวอย่างเมตริกที่กำหนดเองเพิ่มเติม:
TPAS (คะแนนความแม่นยำของแผนการเดินทาง) : "หน่วยวัดนี้วัดความแม่นยำของการตอบสนองที่สร้างขึ้นโดยการประเมินการรวมผลลัพธ์ที่คาดหวังและคุณภาพของแผนการเดินทางที่เสนอ TPAS เป็นค่าตัวเลขระหว่าง 0 ถึง 100 โดยที่ 100 แสดงถึงความสมบูรณ์แบบ ตรงกับผลลัพธ์ที่คาดหวัง และ 0 แสดงถึงผลลัพธ์ที่ไม่ถูกต้อง"
EES (คะแนนการมีส่วนร่วมในการเอาใจใส่) : "EES ประเมินการสะท้อนความเห็นอกเห็นใจของการตอบสนองของ LLM โดยการประเมินความเข้าใจ การตรวจสอบ และองค์ประกอบที่สนับสนุนในข้อความ จะให้คะแนนระดับการเอาใจใส่ที่ถ่ายทอด EES มีช่วงตั้งแต่ 0 ถึง 100 โดยที่ 100 หมายถึง การตอบสนองอย่างเห็นอกเห็นใจ ในขณะที่ 0 แสดงถึงการขาดการมีส่วนร่วมอย่างเห็นอกเห็นใจ"
ทำให้แอปพลิเคชันที่ใช้ LLM ของคุณดีขึ้นด้วย Spelltest!


