paperchat
1.0.0
ยินดีต้อนรับสู่ arXivchat!
arXivchat เป็นซอฟต์แวร์ที่ใช้ LLM ซึ่งให้คุณพูดคุยเกี่ยวกับเอกสารที่ตีพิมพ์ของ arXiv ในรูปแบบการสนทนา มันทำงานเป็นเครื่องมือ cli, ผู้ให้บริการ API และปลั๊กอิน ChatGPT
ทำโดยผู้ประกอบการส่งต่อ เราทำงานร่วมกับคนที่ฉลาดที่สุดในโครงการที่เกี่ยวข้องกับ LLM และ ML
คุณยินดีเป็นอย่างยิ่งที่จะมีส่วนร่วม!
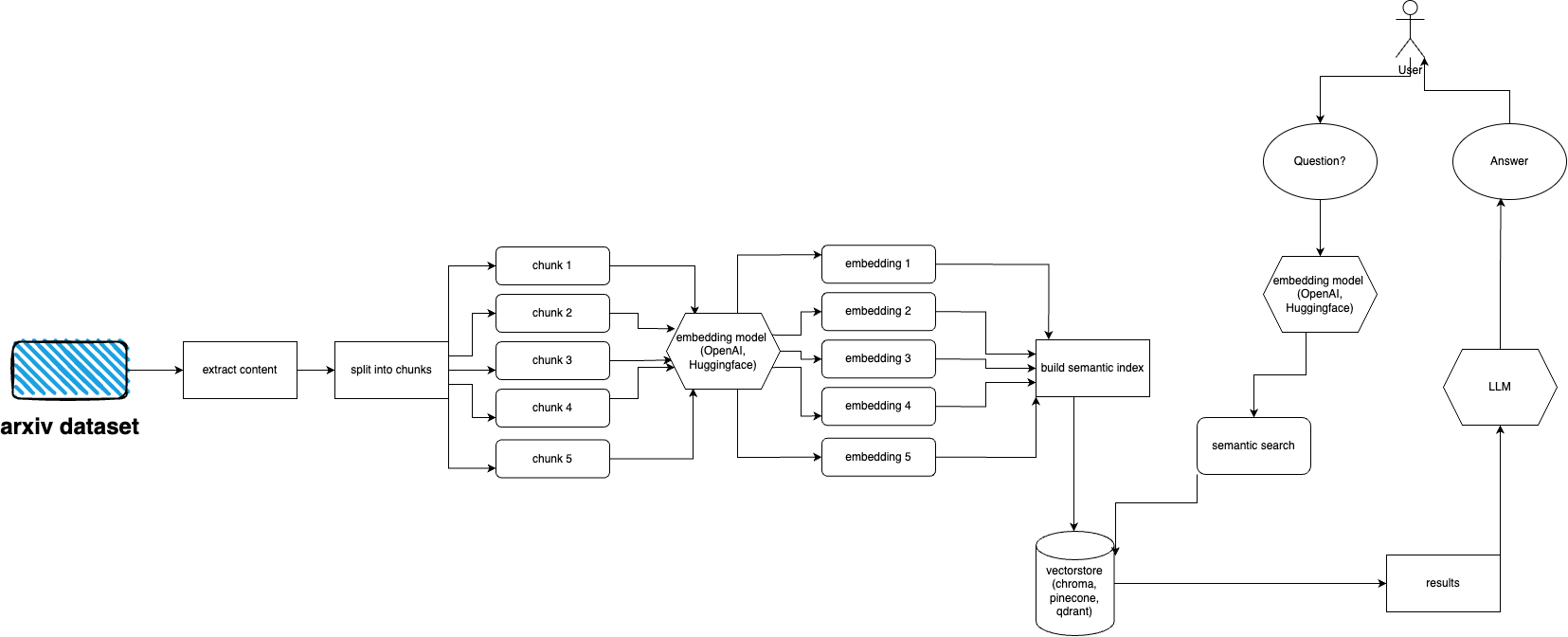
ทำตามขั้นตอนเหล่านี้เพื่อตั้งค่าและเรียกใช้ปลั๊กอิน arXiv อย่างรวดเร็ว:
ติดตั้ง Python 3.10 หากยังไม่ได้ติดตั้ง
โคลนพื้นที่เก็บข้อมูล: git clone https://github.com/Forward-Operators/arxivchat.git
นำทางไปยังไดเร็กทอรีที่เก็บโคลน: cd /path/to/arxivchat
ติดตั้งบทกวี: pip install poetry
สร้างสภาพแวดล้อมเสมือนจริงใหม่ด้วย Python 3.10: poetry env use python3.10
เปิดใช้งานสภาพแวดล้อมเสมือนจริง: poetry shell
ติดตั้งการพึ่งพาแอป: poetry install
ตั้งค่าตัวแปรสภาพแวดล้อมที่ต้องการ:
export DATABASE= < your_datastore >
export OPENAI_API_KEY= < your_openai_api_key >
# Add the environment variables for your chosen vector DB.
# Pinecone
export PINECONE_API_KEY= < your_pinecone_api_key >
export PINECONE_ENVIRONMENT= < your_pinecone_environment >
export PINECONE_INDEX= < your_pinecone_index >
# Qdrant
export QDRANT_URL= < your_qdrant_url >
export QDRANT_PORT= < your_qdrant_port >
export QDRANT_GRPC_PORT= < your_qdrant_grpc_port >
export QDRANT_API_KEY= < your_qdrant_api_key >
export QDRANT_COLLECTION= < your_qdrant_collection >
# Chroma
export CHROMA_HOST= < your_chroma_host >
export CHROMA_PORT= < your_chroma_port >
export CHROMA_COLLECTION= < your_chroma_collection >
# Embeddings
export EMBEDDINGS= < openai or huggingface >
export CUDA_ENABLED= < True or False > - needed for huggingface
รัน API ในเครื่อง: cd app/; gunicorn --worker-class uvicorn.workers.UvicornWorker --config ./gunicorn_conf.py main:app
เข้าถึงเอกสารประกอบ API ได้ที่ http://0.0.0.0:8000/docs และทดสอบจุดสิ้นสุด API
arXiv มีชุดข้อมูลสิ่งพิมพ์เกือบ 2 ล้านฉบับ การดึงข้อมูลมากเกินไปจากเว็บไซต์ของพวกเขาถือเป็นการขัดต่อ ToS ของ arXiv (เนื่องจากสร้างภาระงาน) โชคดีที่คนดีๆ จาก kaggle ร่วมกับ Cornell University ได้สร้างชุดข้อมูลที่เปิดเผยต่อสาธารณะซึ่งคุณสามารถใช้ได้ ชุดข้อมูลสามารถใช้ได้ฟรีผ่านที่เก็บข้อมูล Google Cloud Storage และอัปเดตทุกสัปดาห์
ตอนนี้ปัญหาหลักคือ - จะรับเฉพาะชุดย่อยของชุดข้อมูลทั้งหมดได้อย่างไร ถ้าเราไม่ต้องการนำเข้าไฟล์ PDF มากกว่า 5 เทราไบต์ ชุดข้อมูลแบ่งออกเป็นไดเรกทอรีต่อเดือนต่อปี ดังนั้นหากคุณต้องการรับสิ่งพิมพ์ทั้งหมดตั้งแต่เดือนกันยายนปี 2021 คุณก็เรียกใช้: gsutil cp -r gs://arxiv-dataset/arxiv/pdf/2109/ ./local_directory
หากคุณต้องการรับชุดข้อมูลทั้งหมด: gsutil cp -r gs://arxiv-dataset/arxiv/pdf/ ./a_local_directory/
แต่ถ้าคุณต้องการรับเฉพาะชุดย่อย (สำหรับหมวดหมู่และวันที่ที่กำหนด) ลองดูที่ไฟล์ download.py
ตามค่าเริ่มต้น ingester คาดว่าไฟล์นี้จะอยู่ที่ /mnt/dataset/arxiv/pdf โดยมีไฟล์ pdf ทั้งหมดอยู่ที่นั่น
ตรวจสอบและเรียกใช้ python scripy.py เพื่อนำเข้าข้อมูล คุณยังสามารถเปิดใช้งานการดีบักได้หากมีบางอย่างไม่ทำงาน
สิ่งที่ต้องทำ: อาจเปลี่ยนสิ่งนี้เป็นตัวโหลดไดเรกทอรี สิ่งที่ต้องทำ: ใช้การปรับใช้คื่นฉ่ายและใช้ตัวทำงานสำหรับการนำเข้า
python cli.py 
ถามคำถามเกี่ยวกับหัวข้อที่คุณเคยป้อนฐานข้อมูลมาก่อน ส่งกลับข้อมูลเกี่ยวกับแหล่งที่มาเช่นกัน ทำงานอย่างต่อเนื่อง อีกทางเลือกหนึ่งคือใช้ REST API (เรียกใช้ uvicorn main:app --reload --host 0.0.0.0 --port 8000 จากไดเร็กทอรี app ) หรือใช้เป็นปลั๊กอิน ChatGPT (หลังจากปรับใช้)
มีไฟล์ Terraform ในไดเร็กทอรี deployment ใช้อันที่เหมาะกับคุณที่สุด มีไฟล์ README อยู่ในแต่ละไฟล์พร้อมคำแนะนำ คุณยังสามารถสร้างอิมเมจ Docker และเรียกใช้ได้ทุกที่ที่คุณต้องการ แม้ว่าไฟล์ภาพจะค่อนข้างใหญ่ก็ตาม
สำหรับตอนนี้สามารถปรับใช้เป็น Cloud Run โดยใช้อิมเมจนักเทียบท่าได้ ดังนั้นจึงเป็นการปรับใช้ API เท่านั้น การนำเข้าข้อมูลจะต้องดำเนินการบนเครื่องอื่น (ฉันขอแนะนำ Compute Engine ที่เปิดใช้งาน GPU โดยเฉพาะอย่างยิ่งหากคุณต้องการใช้การฝัง Hugging Face และเนื่องจากคุณสามารถเมานต์ดาต้าจาก Google Storage ได้โดยตรงโดยใช้ gcsfuse ) โซลูชันที่เป็นไปได้ในการใช้ที่เก็บข้อมูล GCS กับคลาวด์ วิ่ง
ในตอนนี้สามารถปรับใช้เป็นแอปคอนเทนเนอร์ได้ (การปรับใช้เฉพาะ API เท่านั้น คุณต้องปรับใช้อีกครั้งสำหรับการนำเข้า)
AWS ยังไม่รองรับ เร็วๆ นี้.
arxivchat ใช้ text-embedding-ada-002 สำหรับ OpenAI ตามค่าเริ่มต้น คุณสามารถเปลี่ยนได้ใน app/tools/factory.py
สำหรับตอนนี้ คุณสามารถใช้โมเดลใดก็ได้ที่ใช้งานได้กับ sentence_transformers คุณสามารถเปลี่ยนโมเดลได้ใน app/tools/factory.py
หากคุณมีปัญหาใด ๆ โปรดใช้ปัญหา GitHub เพื่อรายงานปัญหาเหล่านั้น
เรายินดีที่คุณช่วยทำให้ arXivchat ดียิ่งขึ้นไปอีก! หากต้องการมีส่วนร่วม โปรดทำตามขั้นตอนเหล่านี้:
arXivchat ได้รับการเผยแพร่ภายใต้ใบอนุญาต MIT


