distrifuser
v0.0.1beta0
[29 ก.ค. 2024] รองรับ DistriFusion ใน ColossalAI!
[4 เมษายน 2024] DistriFusion ได้รับเลือกให้เป็นโปสเตอร์ ไฮไลต์ ใน CVPR 2024!
[29 ก.พ. 2024] CVPR 2024 ยอมรับ DistriFusion! รหัสของเราเปิดเผยต่อสาธารณะ!
 เราขอแนะนำ DistriFusion ซึ่งเป็นอัลกอริธึมที่ไม่ต้องฝึกฝนเพื่อควบคุม GPU หลายตัวเพื่อเร่งการอนุมานแบบจำลองการแพร่กระจายโดยไม่ทำให้คุณภาพของภาพลดลง Naïve Patch (ภาพรวม (b)) ประสบปัญหาการกระจายตัวเนื่องจากขาดการโต้ตอบของแพตช์ ตัวอย่างที่นำเสนอสร้างขึ้นด้วย SDXL โดยใช้ตัวอย่างออยเลอร์ 50 ขั้นตอนที่ความละเอียด 1280×1920 และเวลาแฝงจะวัดบน A100 GPU
เราขอแนะนำ DistriFusion ซึ่งเป็นอัลกอริธึมที่ไม่ต้องฝึกฝนเพื่อควบคุม GPU หลายตัวเพื่อเร่งการอนุมานแบบจำลองการแพร่กระจายโดยไม่ทำให้คุณภาพของภาพลดลง Naïve Patch (ภาพรวม (b)) ประสบปัญหาการกระจายตัวเนื่องจากขาดการโต้ตอบของแพตช์ ตัวอย่างที่นำเสนอสร้างขึ้นด้วย SDXL โดยใช้ตัวอย่างออยเลอร์ 50 ขั้นตอนที่ความละเอียด 1280×1920 และเวลาแฝงจะวัดบน A100 GPU
DistriFusion: การอนุมานแบบขนานแบบกระจายสำหรับโมเดลการแพร่กระจายที่มีความละเอียดสูง
มู่หยาง ลี*, เทียนเล่อ ไฉ*, เจียซิน เฉา, ฉินเซิง จาง, ฮั่นไฉ, จุนเจี๋ยไป๋, หยางชิง เจีย, หมิง-หยู หลิว, ไค ลี่ และซงฮาน
MIT, พรินซ์ตัน, Lepton AI และ NVIDIA
ใน CVPR 2024
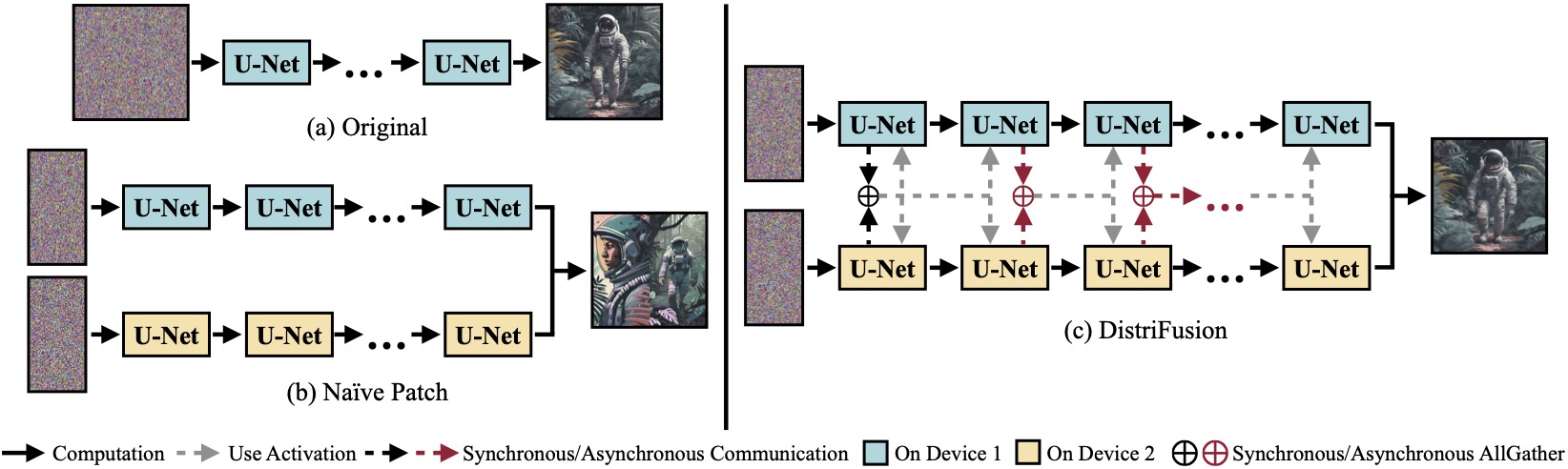 (a) โมเดลการแพร่กระจายดั้งเดิมที่ทำงานบนอุปกรณ์เดียว (b) การแบ่งภาพออกเป็น 2 แพตช์โดยไม่ได้ตั้งใจใน 2 GPU มีรอยต่อที่ชัดเจนที่ขอบเขตเนื่องจากไม่มีการโต้ตอบระหว่างแพตช์ (c) DistriFusion ของเราใช้การสื่อสารแบบซิงโครนัสสำหรับการโต้ตอบกับแพตช์ในขั้นตอนแรก หลังจากนั้น เราจะนำการเปิดใช้งานจากขั้นตอนก่อนหน้ากลับมาใช้ใหม่ผ่านการสื่อสารแบบอะซิงโครนัส ด้วยวิธีนี้ ค่าใช้จ่ายในการสื่อสารจึงสามารถซ่อนอยู่ในไปป์ไลน์การคำนวณได้
(a) โมเดลการแพร่กระจายดั้งเดิมที่ทำงานบนอุปกรณ์เดียว (b) การแบ่งภาพออกเป็น 2 แพตช์โดยไม่ได้ตั้งใจใน 2 GPU มีรอยต่อที่ชัดเจนที่ขอบเขตเนื่องจากไม่มีการโต้ตอบระหว่างแพตช์ (c) DistriFusion ของเราใช้การสื่อสารแบบซิงโครนัสสำหรับการโต้ตอบกับแพตช์ในขั้นตอนแรก หลังจากนั้น เราจะนำการเปิดใช้งานจากขั้นตอนก่อนหน้ากลับมาใช้ใหม่ผ่านการสื่อสารแบบอะซิงโครนัส ด้วยวิธีนี้ ค่าใช้จ่ายในการสื่อสารจึงสามารถซ่อนอยู่ในไปป์ไลน์การคำนวณได้
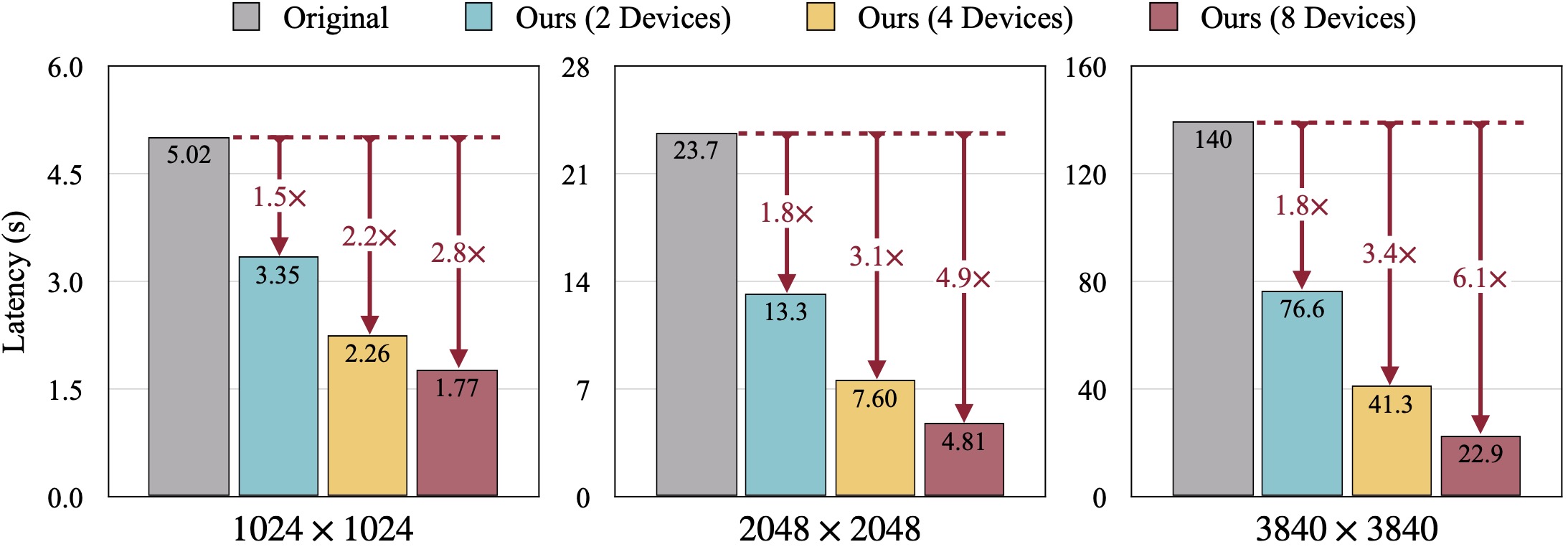
 ผลลัพธ์เชิงคุณภาพของ SDXL FID จะถูกคำนวณโดยเทียบกับภาพความจริงจากพื้นดิน DistriFusion ของเราสามารถลดเวลาแฝงตามจำนวนอุปกรณ์ที่ใช้ในขณะที่ยังคงความเที่ยงตรงของภาพไว้
ผลลัพธ์เชิงคุณภาพของ SDXL FID จะถูกคำนวณโดยเทียบกับภาพความจริงจากพื้นดิน DistriFusion ของเราสามารถลดเวลาแฝงตามจำนวนอุปกรณ์ที่ใช้ในขณะที่ยังคงความเที่ยงตรงของภาพไว้
อ้างอิง:
หลังจากติดตั้ง PyTorch คุณควรจะสามารถติดตั้ง distrifuser ด้วย PyPI ได้
pip install distrifuserหรือผ่าน GitHub:
pip install git+https://github.com/mit-han-lab/distrifuser.gitหรือเพื่อการพัฒนาในท้องถิ่น
git clone [email protected]:mit-han-lab/distrifuser.git
cd distrifuser
pip install -e . ใน scripts/sdxl_example.py เรามีสคริปต์ขั้นต่ำสำหรับการรัน SDXL ด้วย DistriFusion
import torch
from distrifuser . pipelines import DistriSDXLPipeline
from distrifuser . utils import DistriConfig
distri_config = DistriConfig ( height = 1024 , width = 1024 , warmup_steps = 4 )
pipeline = DistriSDXLPipeline . from_pretrained (
distri_config = distri_config ,
pretrained_model_name_or_path = "stabilityai/stable-diffusion-xl-base-1.0" ,
variant = "fp16" ,
use_safetensors = True ,
)
pipeline . set_progress_bar_config ( disable = distri_config . rank != 0 )
image = pipeline (
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k" ,
generator = torch . Generator ( device = "cuda" ). manual_seed ( 233 ),
). images [ 0 ]
if distri_config . rank == 0 :
image . save ( "astronaut.png" ) โดยเฉพาะอย่างยิ่ง distrifuser ของเราใช้ API เดียวกันกับตัวกระจายและสามารถใช้ในลักษณะเดียวกันได้ คุณเพียงแค่ต้องกำหนด DistriConfig และใช้ DistriSDXLPipeline ที่ห่อไว้ของเราเพื่อโหลดโมเดล SDXL ที่ผ่านการฝึกอบรมแล้ว จากนั้น เราสามารถสร้างภาพเหมือน StableDiffusionXLPipeline ในดิฟฟิวเซอร์ได้ คำสั่งที่กำลังรันอยู่คือ
torchrun --nproc_per_node= $N_GPUS scripts/sdxl_example.py โดยที่ $N_GPUS คือหมายเลข GPU ที่คุณต้องการใช้
นอกจากนี้เรายังจัดเตรียมสคริปต์ขั้นต่ำสำหรับการรัน SD1.4/2 ด้วย DistriFusion ใน scripts/sd_example.py การใช้งานก็เหมือนกัน
ผลลัพธ์การวัดประสิทธิภาพของเราใช้ PyTorch 2.2 และตัวกระจาย 0.24.0 ขั้นแรก คุณอาจต้องติดตั้งการขึ้นต่อกันเพิ่มเติมบางอย่าง:
pip install git+https://github.com/zhijian-liu/torchprofile datasets torchmetrics dominate clean-fid คุณสามารถใช้ scripts/generate_coco.py เพื่อสร้างภาพที่มีคำบรรยาย COCO คำสั่งคือ
torchrun --nproc_per_node=$N_GPUS scripts/generate_coco.py --no_split_batch
โดยที่ $N_GPUS คือหมายเลข GPU ที่คุณต้องการใช้ ตามค่าเริ่มต้น ผลลัพธ์ที่สร้างขึ้นจะถูกเก็บไว้ใน results/coco คุณยังสามารถปรับแต่งได้ด้วย --output_root ข้อโต้แย้งเพิ่มเติมบางประการที่คุณอาจต้องการปรับแต่ง:
--num_inference_steps : จำนวนขั้นตอนการอนุมาน เราใช้ 50 เป็นค่าเริ่มต้น--guidance_scale : มาตราส่วนคำแนะนำแบบไม่มีตัวแยกประเภท เราใช้ 5 เป็นค่าเริ่มต้น--scheduler : ตัวอย่างการแพร่กระจาย เราใช้ตัวอย่าง DDIM เป็นค่าเริ่มต้น คุณยังสามารถใช้ euler สำหรับตัวอย่างออยเลอร์และ dpm-solver สำหรับตัวแก้ปัญหา DPM--warmup_steps : จำนวนขั้นตอนการอุ่นเครื่องเพิ่มเติม (4 โดยค่าเริ่มต้น)--sync_mode : โหมดการซิงโครไนซ์ GroupNorm ที่แตกต่างกัน ตามค่าเริ่มต้น จะใช้ GroupNorm แบบอะซิงโครนัสที่แก้ไขแล้วของเรา--parallelism : กระบวนทัศน์ความเท่าเทียมที่คุณใช้ โดยค่าเริ่มต้น จะเป็นแพตช์ขนานกัน คุณสามารถใช้ tensor สำหรับเทนเซอร์แบบขนานและ naive_patch สำหรับแพทช์ไร้เดียงสา หลังจากที่คุณสร้างภาพทั้งหมดแล้ว คุณสามารถใช้สคริปต์ scripts/compute_metrics.py ของเราเพื่อคำนวณ PSNR, LPIPS และ FID การใช้งานก็คือ
python scripts/compute_metrics.py --input_root0 $IMAGE_ROOT0 --input_root1 $IMAGE_ROOT1 โดยที่ $IMAGE_ROOT0 และ $IMAGE_ROOT1 เป็นเส้นทางไปยังโฟลเดอร์รูปภาพที่คุณพยายามเปรียบเทียบ หาก IMAGE_ROOT0 เป็นไฟล์ Ground-truth โปรดเพิ่มแฟล็ก --is_gt สำหรับการปรับขนาด นอกจากนี้ เรายังจัดเตรียมสคริปต์ scripts/dump_coco.py เพื่อถ่ายโอนข้อมูลภาพที่มาจากความจริง
คุณสามารถใช้ scripts/run_sdxl.py เพื่อเปรียบเทียบเวลาแฝงในวิธีการต่างๆ ของเรา คำสั่งคือ
torchrun --nproc_per_node= $N_GPUS scripts/run_sdxl.py --mode benchmark --output_type latent โดยที่ $N_GPUS คือหมายเลข GPU ที่คุณต้องการใช้ เช่นเดียวกับ scripts/generate_coco.py คุณสามารถเปลี่ยนข้อโต้แย้งบางอย่างได้:
--num_inference_steps : จำนวนขั้นตอนการอนุมาน เราใช้ 50 เป็นค่าเริ่มต้น--image_size : ขนาดรูปภาพที่สร้างขึ้น โดยค่าเริ่มต้นจะเป็น 1024×1024--no_split_batch : ปิดใช้งานการแยกแบทช์สำหรับคำแนะนำที่ไม่มีตัวแยกประเภท--warmup_steps : จำนวนขั้นตอนการอุ่นเครื่องเพิ่มเติม (4 โดยค่าเริ่มต้น)--sync_mode : โหมดการซิงโครไนซ์ GroupNorm ที่แตกต่างกัน ตามค่าเริ่มต้น จะใช้ GroupNorm แบบอะซิงโครนัสที่แก้ไขแล้วของเรา--parallelism : กระบวนทัศน์ความเท่าเทียมที่คุณใช้ โดยค่าเริ่มต้น จะเป็นแพตช์ขนานกัน คุณสามารถใช้ tensor สำหรับเทนเซอร์แบบขนานและ naive_patch สำหรับแพทช์ไร้เดียงสา--warmup_times / --test_times : จำนวนการวอร์มอัพ/การทดสอบรัน โดยค่าเริ่มต้นจะเป็น 5 และ 20 ตามลำดับ หากคุณใช้รหัสนี้เพื่อการวิจัยของคุณ โปรดอ้างอิงรายงานของเรา
@inproceedings { li2023distrifusion ,
title = { DistriFusion: Distributed Parallel Inference for High-Resolution Diffusion Models } ,
author = { Li, Muyang and Cai, Tianle and Cao, Jiaxin and Zhang, Qinsheng and Cai, Han and Bai, Junjie and Jia, Yangqing and Liu, Ming-Yu and Li, Kai and Han, Song } ,
booktitle = { Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) } ,
year = { 2024 }
}โค้ดของเราได้รับการพัฒนาบนพื้นฐานของ Huggingface/diffusers และ lmxyy/sige เราขอขอบคุณ torchprofile สำหรับการวัด MACs, clean-fid สำหรับการคำนวณ FID และ Lightning-AI/torchmetrics สำหรับ PSNR และ LPIPS
เราขอขอบคุณ Jun-Yan Zhu และ Ligeng Zhu สำหรับการสนทนาที่เป็นประโยชน์และข้อเสนอแนะอันมีค่า โครงการนี้ได้รับการสนับสนุนจาก MIT-IBM Watson AI Lab, Amazon, MIT Science Hub และมูลนิธิวิทยาศาสตร์แห่งชาติ


