serverless rag ynetnews bedrock demo
1.0.0
การตอบคำถาม (QA) เป็นงานสำคัญที่เกี่ยวข้องกับการแยกคำตอบของคำถามที่เป็นข้อเท็จจริงในภาษาธรรมชาติ โดยทั่วไป ระบบ QA จะประมวลผลคำค้นหากับฐานความรู้ที่มีข้อมูลที่มีโครงสร้างหรือไม่มีโครงสร้าง และสร้างการตอบกลับด้วยข้อมูลที่ถูกต้อง การรับรองความถูกต้องแม่นยำสูงเป็นกุญแจสำคัญในการพัฒนาระบบตอบคำถามที่มีประโยชน์ เชื่อถือได้ และเชื่อถือได้ โดยเฉพาะในกรณีการใช้งานระดับองค์กร
โมเดล AI เจนเนอเรชั่น เช่น Amazon Titan, Anthropic Claude และ AI21 Jurassic 2 ใช้การแจกแจงความน่าจะเป็นเพื่อสร้างการตอบคำถาม โมเดลเหล่านี้ได้รับการฝึกฝนเกี่ยวกับข้อมูลข้อความจำนวนมหาศาล ซึ่งช่วยให้คาดการณ์สิ่งที่จะเกิดขึ้นถัดไปในลำดับหรือคำใดที่อาจตามหลังคำใดคำหนึ่งโดยเฉพาะ อย่างไรก็ตาม โมเดลเหล่านี้ไม่สามารถให้คำตอบที่ถูกต้องหรือกำหนดได้สำหรับทุกคำถาม เนื่องจากข้อมูลมีความไม่แน่นอนในระดับหนึ่งอยู่เสมอ
องค์กรต่างๆ จำเป็นต้องค้นหาข้อมูลเฉพาะโดเมนและข้อมูลที่เป็นกรรมสิทธิ์ และใช้ข้อมูลดังกล่าวเพื่อตอบคำถาม และโดยทั่วไปคือข้อมูลซึ่งโมเดลดังกล่าวไม่ได้รับการฝึกอบรม
ใน repo นี้ เราจะสำรวจรูปแบบ QA ต่อไปนี้:
เราใช้การดึงข้อมูล Augmented Generation ซึ่งปรับปรุงจากข้อแรกที่เราเชื่อมโยงคำถามของเรากับบริบทที่เกี่ยวข้องมากที่สุดเท่าที่จะเป็นไปได้ ซึ่งมีแนวโน้มที่จะมีคำตอบหรือข้อมูลที่เรากำลังมองหา ความท้าทายที่นี่ มีการจำกัดจำนวนข้อมูลเชิงบริบทที่สามารถนำมาใช้ได้ โดยพิจารณาจากขีดจำกัดโทเค็นของโมเดล 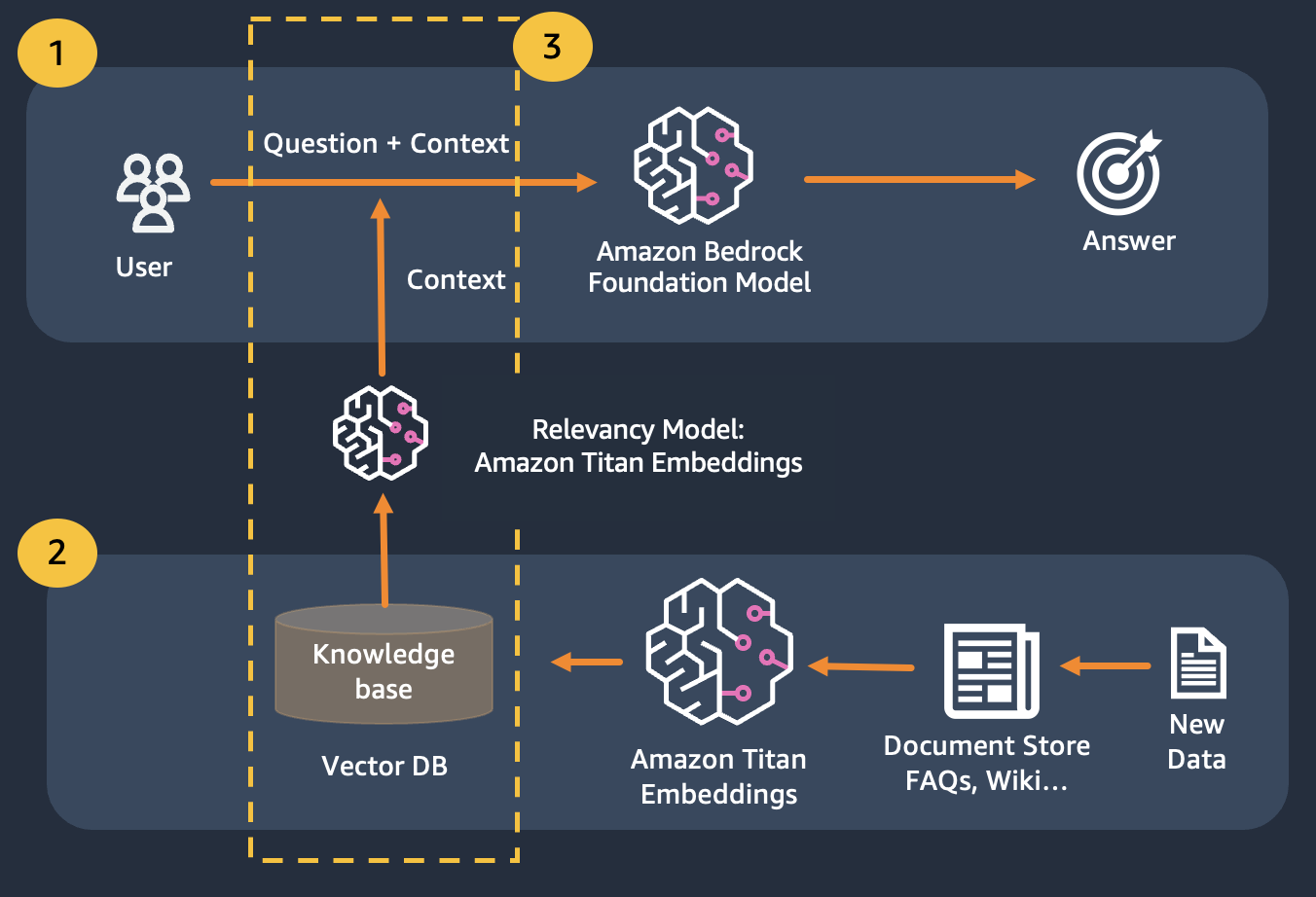
สามารถแก้ไขได้โดยใช้ Retrival Augmented Generation (RAG)
RAG รวมการใช้การฝังเพื่อสร้างดัชนีคลังข้อมูลของเอกสารเพื่อสร้างฐานความรู้และการใช้ LLM เพื่อแยกข้อมูลจากชุดย่อยของเอกสารในฐานความรู้
ในขั้นตอนการเตรียมการสำหรับ RAG เอกสารที่สร้างฐานความรู้จะถูกแบ่งออกเป็นชิ้นที่มีขนาดคงที่ (ตรงกับขนาดอินพุตสูงสุดของโมเดลการฝังที่เลือก) จากนั้นจะถูกส่งต่อไปยังโมเดลเพื่อรับเวกเตอร์การฝัง การฝังร่วมกับส่วนต้นฉบับของเอกสารและข้อมูลเมตาเพิ่มเติมจะถูกจัดเก็บไว้ในฐานข้อมูลเวกเตอร์ ฐานข้อมูลเวกเตอร์ได้รับการปรับให้เหมาะสมเพื่อทำการค้นหาความคล้ายคลึงกันระหว่างเวกเตอร์อย่างมีประสิทธิภาพ
ลูกค้าที่มีการจัดเก็บข้อมูลที่อาจมีความเป็นส่วนตัวหรือมีการเปลี่ยนแปลงบ่อยครั้ง แนวทาง RAG ช่วยแก้ปัญหา 2 ประการ ลูกค้าที่มีความท้าทายดังต่อไปนี้จะได้รับประโยชน์จากห้องปฏิบัติการแห่งนี้
หลังจากโมดูลนี้ คุณควรมีความเข้าใจที่ดีเกี่ยวกับ:
ในโมดูลนี้ เราจะอธิบายวิธีการนำรูปแบบ QA ไปใช้กับ Bedrock นอกจากนี้ เราได้เตรียมการฝังที่จะโหลดในฐานข้อมูลเวกเตอร์สำหรับคุณ
โปรดทราบว่าคุณสามารถใช้ Titan Embeddings เพื่อรับการฝังคำถามของผู้ใช้ จากนั้นใช้การฝังเหล่านั้นเพื่อดึงเอกสารที่เกี่ยวข้องมากที่สุดจากฐานข้อมูลเวกเตอร์ สร้างพร้อมท์เพื่อเชื่อมเอกสาร 3 อันดับแรกเข้าด้วยกัน และเรียกใช้โมเดล LLM ผ่านทาง Bedrock


