BinaryVectorDB
1.0.0
พื้นที่เก็บข้อมูลนี้มีฐานข้อมูลเวกเตอร์แบบไบนารีสำหรับการค้นหาชุดข้อมูลขนาดใหญ่อย่างมีประสิทธิภาพ โดยมีวัตถุประสงค์เพื่อการศึกษา
โมเดลที่ฝังส่วนใหญ่แสดงเวกเตอร์เป็น float32: สิ่งเหล่านี้ใช้หน่วยความจำจำนวนมากและการค้นหาสิ่งเหล่านี้ช้ามาก ที่ Cohere เราได้เปิดตัวโมเดลการฝังรุ่นแรกที่มี int8 แบบเนทิฟและการสนับสนุนไบนารี ซึ่งให้คุณภาพการค้นหาที่ยอดเยี่ยมในราคาที่ไม่แพง:
| แบบอย่าง | มิราเคิลคุณภาพการค้นหา | เวลาในการค้นหาเอกสาร 1 ล้านฉบับ | หน่วยความจำที่ต้องการการฝังวิกิพีเดีย 250M | ราคาบน AWS (อินสแตนซ์ x2gb) |
|---|---|---|---|---|
| การฝังข้อความ OpenAI-3-small | 44.9 | 680 มิลลิวินาที | 1431GB | $65,231/ปี |
| การฝังข้อความ OpenAI-3-large | 54.9 | 1240 มิลลิวินาที | 2861GB | $130,463/ปี |
| Cohere Embed v3 (หลายภาษา) | ||||
| ฝัง v3 - float32 | 66.3 | 460 มิลลิวินาที | 954GB | $43,488/ปี |
| ฝัง v3 - ไบนารี่ | 62.8 | 24 น | 30 กิกะไบต์ | $1,359 / ปี |
| ฝัง v3 - ไบนารี + int8 rescore | 66.3 | 28 น | หน่วยความจำ 30 GB + ดิสก์ 240 GB | $1,589 / ปี |
เราสร้างการสาธิตที่ช่วยให้คุณสามารถค้นหาการฝัง Wikipedia 100 ล้านรายการสำหรับ VM ที่มีค่าใช้จ่ายเพียง $15/เดือน: การสาธิต - ค้นหาการฝัง Wikipedia 100 ล้านรายการในราคาเพียง $15/เดือน
คุณสามารถใช้ BinaryVectorDB กับข้อมูลของคุณเองได้อย่างง่ายดาย
การตั้งค่าทำได้ง่าย:
pip install BinaryVectorDB
หากต้องการใช้ตัวอย่างด้านล่างบางส่วน คุณต้องมี คีย์ Cohere API (ฟรีหรือมีค่าใช้จ่าย) จาก cohere.com คุณต้องตั้งค่าคีย์ API นี้เป็นตัวแปรสภาพแวดล้อม: export COHERE_API_KEY=your_api_key
เราจะแสดงวิธีสร้างฐานข้อมูลเวกเตอร์จากข้อมูลของคุณเองในภายหลัง ในการเริ่มต้น ให้เราใช้ ฐานข้อมูลเวกเตอร์ไบนารีที่สร้างไว้ล่วงหน้า เราโฮสต์ ฐานข้อมูลที่สร้างล่วงหน้า ต่างๆ บน https://huggingface.co/datasets/Cohere/BinaryVectorDB คุณสามารถดาวน์โหลดสิ่งเหล่านี้และใช้งานได้ภายในเครื่อง
ให้เราใช้เวอร์ชันภาษาอังกฤษอย่างง่ายจาก Wikipedia เพื่อเริ่มต้น:
wget https://huggingface.co/datasets/Cohere/BinaryVectorDB/resolve/main/wikipedia-2023-11-simple.zip
จากนั้นแตกไฟล์นี้:
unzip wikipedia-2023-11-simple.zip
คุณสามารถโหลดฐานข้อมูลได้อย่างง่ายดายโดยชี้ไปที่โฟลเดอร์ที่คลายซิปจากขั้นตอนก่อนหน้า:
from BinaryVectorDB import BinaryVectorDB
# Point it to the unzipped folder from the previous step
# Ensure that you have set your Cohere API key via: export COHERE_API_KEY=<<YOUR_KEY>>
db = BinaryVectorDB ( "wikipedia-2023-11-simple/" )
query = "Who is the founder of Facebook"
print ( "Query:" , query )
hits = db . search ( query )
for hit in hits [ 0 : 3 ]:
print ( hit )ฐานข้อมูลมีการฝัง 646,424 และขนาดรวม 962 MB อย่างไรก็ตาม มีการโหลดการฝังไบนารีเพียง 80 MB ในหน่วยความจำ เอกสารและการฝัง int8 จะถูกเก็บไว้ในดิสก์และจะโหลดเมื่อจำเป็นเท่านั้น
การแยกการฝังไบนารีในหน่วยความจำและการฝัง int8 และเอกสารบนดิสก์ช่วยให้เราปรับขนาดชุดข้อมูลขนาดใหญ่มากได้โดยไม่จำเป็นต้องใช้หน่วยความจำจำนวนมาก
การสร้างฐานข้อมูลเวกเตอร์ไบนารีของคุณเองนั้นค่อนข้างง่าย
from BinaryVectorDB import BinaryVectorDB
import os
import gzip
import json
simplewiki_file = "simple-wikipedia-example.jsonl.gz"
#If file not exist, download
if not os . path . exists ( simplewiki_file ):
cmd = f"wget https://huggingface.co/datasets/Cohere/BinaryVectorDB/resolve/main/simple-wikipedia-example.jsonl.gz"
os . system ( cmd )
# Create the vector DB with an empty folder
# Ensure that you have set your Cohere API key via: export COHERE_API_KEY=<<YOUR_KEY>>
db_folder = "path_to_an_empty_folder/"
db = BinaryVectorDB ( db_folder )
if len ( db ) > 0 :
exit ( f"The database { db_folder } is not empty. Please provide an empty folder to create a new database." )
# Read all docs from the jsonl.gz file
docs = []
with gzip . open ( simplewiki_file ) as fIn :
for line in fIn :
docs . append ( json . loads ( line ))
#Limit it to 10k docs to make the next step a bit faster
docs = docs [ 0 : 10_000 ]
# Add all documents to the DB
# docs2text defines a function that maps our documents to a string
# This string is then embedded with the state-of-the-art Cohere embedding model
db . add_documents ( doc_ids = list ( range ( len ( docs ))), docs = docs , docs2text = lambda doc : doc [ 'title' ] + " " + doc [ 'text' ]) เอกสารสามารถเป็นอ็อบเจ็กต์ที่ทำให้ซีเรียลไลซ์ได้ของ Python คุณต้องจัดเตรียมฟังก์ชันสำหรับ docs2text ที่แมปเอกสารของคุณกับสตริง ในตัวอย่างข้างต้น เราเชื่อมชื่อเรื่องและช่องข้อความเข้าด้วยกัน สตริงนี้ถูกส่งไปยังโมเดลการฝังเพื่อสร้างการฝังข้อความที่จำเป็น
การเพิ่ม / ลบ / อัปเดตเอกสารเป็นเรื่องง่าย ดู example/add_update_delete.py สำหรับสคริปต์ตัวอย่างวิธีการเพิ่ม/อัปเดต/ลบเอกสารในฐานข้อมูล
เราได้ประกาศการฝัง Cohere int8 & binary Embeddings ของเรา ซึ่งช่วยลดหน่วยความจำที่จำเป็นลง 4x และ 32x นอกจากนี้ยังเพิ่มความเร็วได้ถึง 40 เท่าในการค้นหาเวกเตอร์
เทคนิคทั้งสองจะรวมกันใน BinaryVectorDB ตัวอย่างเช่น สมมติว่าวิกิพีเดียภาษาอังกฤษมีการฝัง 42M การฝัง float32 ปกติจะต้องมีหน่วยความจำ 42*10^6*1024*4 = 160 GB เพื่อโฮสต์การฝังเท่านั้น เนื่องจากการค้นหาบน float32 ค่อนข้างช้า (ประมาณ 45 วินาทีในการฝัง 42M) เราจึงต้องเพิ่มดัชนีเช่น HNSW ซึ่งจะเพิ่มหน่วยความจำอีก 20GB ดังนั้นคุณจึงต้องมีพื้นที่ทั้งหมด 180 GB
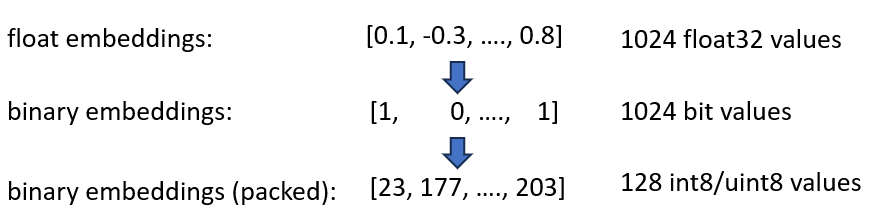
การฝังไบนารีแสดงถึงทุกมิติเป็น 1 บิต ซึ่งจะช่วยลดความต้องการหน่วยความจำลงเหลือ 160 GB / 32 = 5GB นอกจากนี้ เนื่องจากการค้นหาในพื้นที่ไบนารี่เร็วขึ้น 40 เท่า คุณจึงไม่จำเป็นต้องใช้ดัชนี HNSW อีกต่อไปในหลายกรณี คุณลดความต้องการหน่วยความจำของคุณจาก 180 GB เป็น 5 GB ซึ่งประหยัดได้มากถึง 36 เท่า
เมื่อเราสืบค้นดัชนีนี้ เราจะเข้ารหัสการสืบค้นในรูปแบบไบนารี่ด้วย และใช้ระยะแฮมมิง ระยะแฮมมิงวัดความแตกต่าง 1 บิตระหว่างเวกเตอร์ 2 ตัว นี่เป็นการดำเนินการที่รวดเร็วมาก: หากต้องการเปรียบเทียบเวกเตอร์ไบนารี่สองตัว คุณเพียงแค่ต้องมีวงจร 2-CPU: popcount(xor(vector1, vector2)) XOR เป็นการดำเนินการขั้นพื้นฐานที่สุดบน CPU ดังนั้นจึงทำงานได้อย่างรวดเร็วมาก popcount นับจำนวน 1 ในรีจิสเตอร์ ซึ่งต้องการเพียง 1 รอบ CPU เช่นกัน
โดยรวมแล้ว สิ่งนี้ทำให้เรามีโซลูชันที่รักษาคุณภาพการค้นหาได้ประมาณ 90%
เราสามารถเพิ่มคุณภาพการค้นหาจากขั้นตอนก่อนหน้าจาก 90% เป็น 95% โดยการให้คะแนน <float, binary>
เราใช้เช่นผลลัพธ์ 100 อันดับแรกจากขั้นตอนที่ 1 และคำนวณ dot_product(query_float_embedding, 2*binary_doc_embedding-1)
สมมติว่าการฝังแบบสอบถามของเราคือ [0.1, -0.3, 0.4] และการฝังเอกสารไบนารีของเราคือ [1, 0, 1] ขั้นตอนนี้จะคำนวณ:
(0.1)*(1) + (-0.3)*(-1) + 0.4*(1) = 0.1 + 0.3 + 0.4 = 0.8

เราใช้คะแนนเหล่านี้และให้คะแนนผลลัพธ์ของเราอีกครั้ง สิ่งนี้จะผลักดันคุณภาพการค้นหาจาก 90% เป็น 95% การดำเนินการนี้สามารถทำได้อย่างรวดเร็วมาก: เราได้คิวรีโฟลตที่ฝังจากโมเดลการฝัง การฝังไบนารีอยู่ในหน่วยความจำ ดังนั้นเราจึงต้องทำการดำเนินการผลรวม 100 ครั้ง
เพื่อปรับปรุงคุณภาพการค้นหาเพิ่มเติม จาก 95% เป็น 99.99% เราใช้ int8 rescoring จากดิสก์
เราบันทึกการฝังเอกสาร int8 ทั้งหมดลงในดิสก์ จากนั้นเรานำ 30 อันดับแรกจากขั้นตอนข้างต้น โหลด int8-embeddings จากดิสก์ และคำนวณ cossim(query_float_embedding, int8_doc_embedding_from_disk)
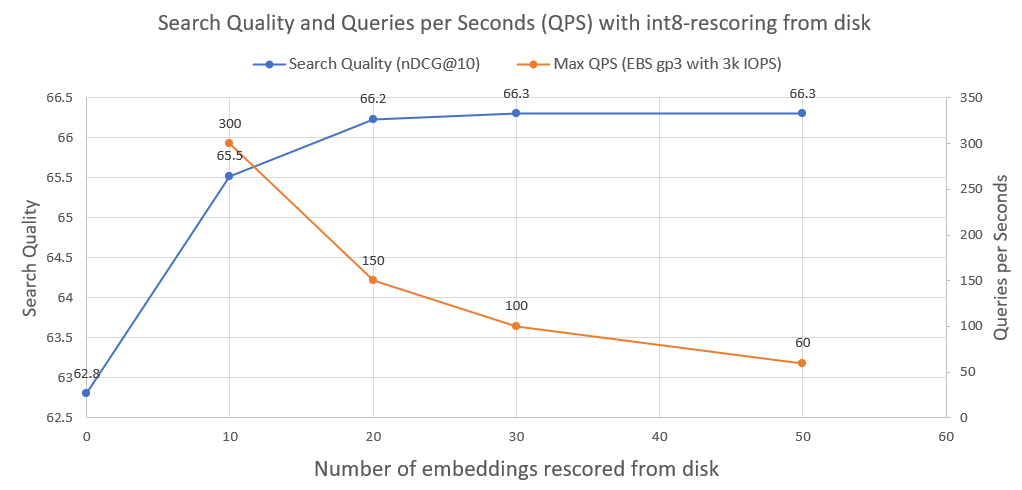
ในภาพต่อไปนี้ คุณจะเห็นว่า int8-rescoring และปรับปรุงประสิทธิภาพการค้นหาได้มากเพียงใด:
นอกจากนี้เรายังวางแผนการสืบค้นต่อวินาทีที่ระบบดังกล่าวสามารถทำได้เมื่อทำงานบนไดรฟ์เครือข่าย AWS EBS ปกติที่มี 3000 IOPS ดังที่เราเห็นแล้วว่า ยิ่งเราจำเป็นต้องโหลด int8 จากดิสก์มากเท่าใด QPS ไม่กี่ตัวเท่านั้น
ในการดำเนินการค้นหาแบบไบนารี เราใช้ดัชนี IndexBinaryFlat จาก faiss มันเพียงแค่จัดเก็บการฝังแบบไบนารี ช่วยให้สามารถจัดทำดัชนีได้เร็วมากและค้นหาได้เร็วมาก
ในการจัดเก็บเอกสารและการฝัง int8 เราใช้ RocksDict ซึ่งเป็นที่เก็บข้อมูลคีย์-ค่าบนดิสก์สำหรับ Python ที่ใช้ RocksDB
ดู BinaryVectorDB สำหรับการนำคลาสไปใช้อย่างเต็มรูปแบบ
ไม่เชิง. พื้นที่เก็บข้อมูลส่วนใหญ่มีวัตถุประสงค์เพื่อการศึกษาเพื่อแสดงเทคนิควิธีการปรับขนาดเป็นชุดข้อมูลขนาดใหญ่ การมุ่งเน้นที่ความสะดวกในการใช้งานมากขึ้น และประเด็นสำคัญบางประการที่ขาดหายไปในการนำไปปฏิบัติ เช่น ความปลอดภัยหลายกระบวนการ การย้อนกลับ เป็นต้น
หากคุณต้องการเข้าสู่การผลิตจริง ให้ใช้ฐานข้อมูลเวกเตอร์ที่เหมาะสม เช่น Vespa.ai ซึ่งจะช่วยให้คุณได้ผลลัพธ์ที่คล้ายคลึงกัน
ที่ Cohere เราช่วยให้ลูกค้าเรียกใช้ Semantic Search กับการฝังนับหมื่นล้านครั้งด้วยต้นทุนเพียงเล็กน้อย อย่าลังเลที่จะติดต่อ Nils Reimers หากคุณต้องการโซลูชันที่ปรับขนาดได้


