horovod
v0.28.1: Build fixes (ROCm, GCC 12)
Horovod เป็นเฟรมเวิร์กการฝึกอบรมการเรียนรู้เชิงลึกแบบกระจายสำหรับ TensorFlow, Keras, PyTorch และ Apache MXNet เป้าหมายของ Horovod คือการทำให้การเรียนรู้เชิงลึกแบบกระจายใช้งานได้รวดเร็วและใช้งานง่าย
Horovod เป็นเจ้าภาพโดย LF AI & Data Foundation (LF AI & Data) หากคุณเป็นบริษัทที่มุ่งมั่นอย่างยิ่งที่จะใช้เทคโนโลยีโอเพ่นซอร์สในด้านปัญญาประดิษฐ์ เครื่องจักร และการเรียนรู้เชิงลึก และต้องการสนับสนุนชุมชนของโครงการโอเพ่นซอร์สในโดเมนเหล่านี้ ลองพิจารณาเข้าร่วม LF AI & Data Foundation สำหรับรายละเอียดเกี่ยวกับผู้ที่เกี่ยวข้องและวิธีที่ Horovod มีบทบาท โปรดอ่านประกาศของ Linux Foundation
สารบัญ
แรงจูงใจหลักสำหรับโปรเจ็กต์นี้คือการทำให้ง่ายต่อการใช้สคริปต์การฝึกอบรม GPU ตัวเดียวและปรับขนาดให้ประสบความสำเร็จในการฝึกอบรมกับ GPU หลายตัวพร้อมกัน สิ่งนี้มีสองด้าน:
ภายในที่ Uber เราพบว่าโมเดล MPI นั้นตรงไปตรงมามากกว่ามากและต้องการการเปลี่ยนแปลงโค้ดน้อยกว่าโซลูชันก่อนหน้านี้มาก เช่น Distributed TensorFlow พร้อมเซิร์ฟเวอร์พารามิเตอร์ เมื่อเขียนสคริปต์การฝึกอบรมเพื่อขยายขนาดด้วย Horovod แล้ว สคริปต์ดังกล่าวจะสามารถทำงานบน GPU ตัวเดียว หลาย GPU หรือแม้แต่หลายโฮสต์ โดยไม่ต้องเปลี่ยนแปลงโค้ดเพิ่มเติมใดๆ ดูส่วนการใช้งานสำหรับรายละเอียดเพิ่มเติม
นอกจากจะใช้งานง่ายแล้ว Horovod ยังรวดเร็วอีกด้วย ด้านล่างนี้เป็นแผนภูมิที่แสดงเกณฑ์มาตรฐานที่ทำบนเซิร์ฟเวอร์ 128 เครื่องที่มี Pascal GPU 4 ตัว ซึ่งแต่ละเครื่องเชื่อมต่อกันด้วยเครือข่าย 25 Gbit/s ที่รองรับ RoCE:
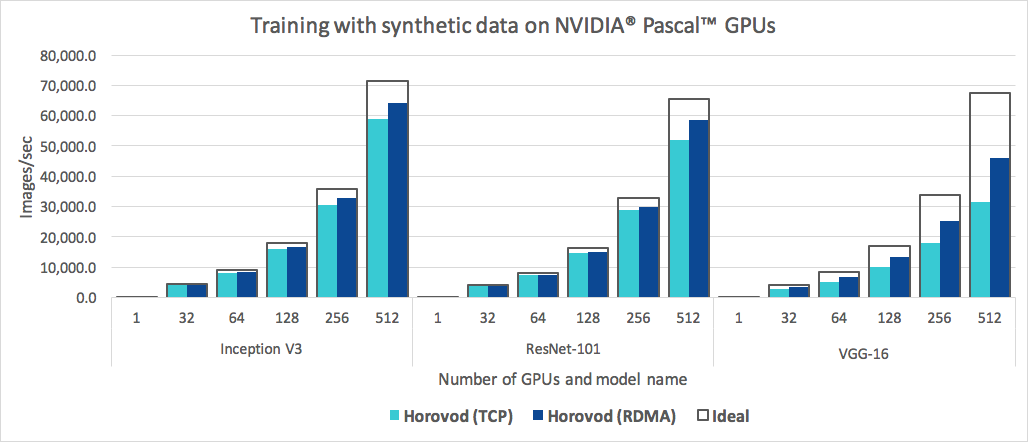
Horovod บรรลุประสิทธิภาพในการปรับขนาด 90% สำหรับทั้ง Inception V3 และ ResNet-101 และประสิทธิภาพการปรับขนาด 68% สำหรับ VGG-16 ดูเกณฑ์มาตรฐานเพื่อดูวิธีสร้างตัวเลขเหล่านี้
แม้ว่าการติดตั้ง MPI และ NCCL เองอาจดูยุ่งยากเป็นพิเศษ แต่ทีมที่เกี่ยวข้องกับโครงสร้างพื้นฐานจะต้องดำเนินการเพียงครั้งเดียว ในขณะที่คนอื่นๆ ในบริษัทที่สร้างแบบจำลองสามารถเพลิดเพลินกับความเรียบง่ายของการฝึกอบรมพวกเขาในวงกว้าง
วิธีติดตั้ง Horovod บน Linux หรือ macOS:
หากคุณได้ติดตั้ง TensorFlow จาก PyPI ตรวจสอบให้แน่ใจว่าได้ติดตั้ง g++-5 ขึ้นไป ตั้งแต่ TensorFlow 2.10 เป็นต้นไป จำเป็นต้องมีคอมไพเลอร์ที่สอดคล้องกับ C++17 เช่น g++8 หรือสูงกว่า
หากคุณได้ติดตั้ง PyTorch จาก PyPI ตรวจสอบให้แน่ใจว่าได้ติดตั้ง g++-5 ขึ้นไป
หากคุณได้ติดตั้งแพ็คเกจใดแพ็คเกจหนึ่งจาก Conda ตรวจสอบให้แน่ใจว่าได้ติดตั้งแพ็คเกจ gxx_linux-64 Conda แล้ว
ติดตั้งแพ็คเกจ horovod pip
หากต้องการทำงานบน CPU:
$ pip install horovodหากต้องการทำงานบน GPU ที่มี NCCL:
$ HOROVOD_GPU_OPERATIONS=NCCL pip install horovodสำหรับรายละเอียดเพิ่มเติมเกี่ยวกับการติดตั้ง Horovod ด้วยการรองรับ GPU โปรดอ่าน Horovod บน GPU
สำหรับรายการตัวเลือกการติดตั้ง Horovod ทั้งหมด โปรดอ่านคู่มือการติดตั้ง
หากคุณต้องการใช้ MPI ให้อ่าน Horovod ด้วย MPI
หากคุณต้องการใช้ Conda โปรดอ่านการสร้างสภาพแวดล้อม Conda ด้วยการรองรับ GPU สำหรับ Horovod
หากคุณต้องการใช้ Docker ให้อ่าน Horovod ใน Docker
หากต้องการรวบรวม Horovod จากแหล่งที่มา ให้ทำตามคำแนะนำใน Contributor Guide
หลักการสำคัญของ Horovod ขึ้นอยู่กับแนวคิด MPI เช่น ขนาด อันดับ อันดับในท้องถิ่น allreduce allgather การออกอากาศ และ alltoall ดูหน้านี้สำหรับรายละเอียดเพิ่มเติม
ดูหน้าเหล่านี้สำหรับตัวอย่าง Horovod และแนวทางปฏิบัติที่ดีที่สุด:
หากต้องการใช้ Horovod ให้เพิ่มสิ่งต่อไปนี้ในโปรแกรมของคุณ:
hvd.init() เพื่อเริ่มต้น Horovodปักหมุด GPU แต่ละตัวให้เป็นกระบวนการเดียวเพื่อหลีกเลี่ยงความขัดแย้งด้านทรัพยากร
ด้วยการตั้งค่าทั่วไปของ GPU หนึ่งตัวต่อกระบวนการ ให้ตั้งค่านี้เป็น อันดับในเครื่อง กระบวนการแรกบนเซิร์ฟเวอร์จะได้รับการจัดสรร GPU ตัวแรก กระบวนการที่สองจะได้รับการจัดสรร GPU ตัวที่สอง และอื่น ๆ
ปรับขนาดอัตราการเรียนรู้ตามจำนวนพนักงาน
ขนาดกลุ่มที่มีประสิทธิภาพในการฝึกอบรมแบบกระจายแบบซิงโครนัสจะปรับขนาดตามจำนวนพนักงาน อัตราการเรียนรู้ที่เพิ่มขึ้นจะชดเชยขนาดชุดงานที่เพิ่มขึ้น
รวมเครื่องมือเพิ่มประสิทธิภาพใน hvd.DistributedOptimizer
เครื่องมือเพิ่มประสิทธิภาพแบบกระจายมอบหมายการคำนวณการไล่ระดับสีให้กับเครื่องมือเพิ่มประสิทธิภาพดั้งเดิม เฉลี่ยการไล่ระดับสีโดยใช้ allreduce หรือ allgather จากนั้นจึงใช้การไล่ระดับสีโดยเฉลี่ยเหล่านั้น
ออกอากาศสถานะตัวแปรเริ่มต้นจากอันดับ 0 ไปยังกระบวนการอื่นๆ ทั้งหมด
นี่เป็นสิ่งจำเป็นเพื่อให้แน่ใจว่าคนงานทุกคนมีการเริ่มต้นที่สอดคล้องกัน เมื่อการฝึกอบรมเริ่มต้นด้วยการสุ่มน้ำหนักหรือเรียกคืนจากจุดตรวจ
ตัวอย่างการใช้ TensorFlow v1 (ดูไดเร็กทอรีตัวอย่างสำหรับตัวอย่างการฝึกอบรมแบบเต็ม):
import tensorflow as tf
import horovod . tensorflow as hvd
# Initialize Horovod
hvd . init ()
# Pin GPU to be used to process local rank (one GPU per process)
config = tf . ConfigProto ()
config . gpu_options . visible_device_list = str ( hvd . local_rank ())
# Build model...
loss = ...
opt = tf . train . AdagradOptimizer ( 0.01 * hvd . size ())
# Add Horovod Distributed Optimizer
opt = hvd . DistributedOptimizer ( opt )
# Add hook to broadcast variables from rank 0 to all other processes during
# initialization.
hooks = [ hvd . BroadcastGlobalVariablesHook ( 0 )]
# Make training operation
train_op = opt . minimize ( loss )
# Save checkpoints only on worker 0 to prevent other workers from corrupting them.
checkpoint_dir = '/tmp/train_logs' if hvd . rank () == 0 else None
# The MonitoredTrainingSession takes care of session initialization,
# restoring from a checkpoint, saving to a checkpoint, and closing when done
# or an error occurs.
with tf . train . MonitoredTrainingSession ( checkpoint_dir = checkpoint_dir ,
config = config ,
hooks = hooks ) as mon_sess :
while not mon_sess . should_stop ():
# Perform synchronous training.
mon_sess . run ( train_op )คำสั่งตัวอย่างด้านล่างแสดงวิธีการเรียกใช้การฝึกอบรมแบบกระจาย ดู Run Horovod สำหรับรายละเอียดเพิ่มเติม รวมถึงการปรับแต่ง RoCE/InfiniBand และเคล็ดลับในการจัดการกับอาการแฮงค์
วิธีรันบนเครื่องที่มี 4 GPU:
$ horovodrun -np 4 -H localhost:4 python train.pyวิธีรันบน 4 เครื่องโดยแต่ละเครื่องมี 4 GPU:
$ horovodrun -np 16 -H server1:4,server2:4,server3:4,server4:4 python train.py หากต้องการรันโดยใช้ Open MPI โดยไม่มีตัวห่อ horovodrun โปรดดูการเรียกใช้ Horovod ด้วย Open MPI
หากต้องการทำงานใน Docker โปรดดู Horovod ใน Docker
หากต้องการทำงานบน Kubernetes โปรดดู Helm Chart, Kubeflow MPI Operator, FfDL และ Polyaxon
หากต้องการทำงานบน Spark โปรดดู Horovod on Spark
หากต้องการวิ่งบนเรย์ ดูที่ Horovod on Ray
หากต้องการทำงานในภาวะเอกฐาน ดูที่ ภาวะเอกฐาน
หากต้องการทำงานในคลัสเตอร์ LSF HPC (เช่น Summit) โปรดดูที่ LSF
หากต้องการทำงานบน Hadoop Yarn โปรดดูที่ TonY
Gloo เป็นไลบรารีการสื่อสารแบบโอเพ่นซอร์สที่พัฒนาโดย Facebook
Gloo มาพร้อมกับ Horovod และอนุญาตให้ผู้ใช้เรียกใช้ Horovod โดยไม่ต้องติดตั้ง MPI
สำหรับสภาพแวดล้อมที่รองรับทั้ง MPI และ Gloo คุณสามารถเลือกใช้ Gloo ตอนรันไทม์ได้โดยส่งอาร์กิวเมนต์ --gloo ไปที่ horovodrun :
$ horovodrun --gloo -np 2 python train.pyHorovod รองรับการผสมและจับคู่กลุ่ม Horovod กับไลบรารี MPI อื่นๆ เช่น mpi4py โดยมีเงื่อนไขว่า MPI ถูกสร้างขึ้นด้วยการรองรับแบบมัลติเธรด
คุณสามารถตรวจสอบการสนับสนุนมัลติเธรด MPI ได้โดยการสอบถามฟังก์ชัน hvd.mpi_threads_supported()
import horovod . tensorflow as hvd
# Initialize Horovod
hvd . init ()
# Verify that MPI multi-threading is supported.
assert hvd . mpi_threads_supported ()
from mpi4py import MPI
assert hvd . size () == MPI . COMM_WORLD . Get_size ()คุณยังสามารถเริ่มต้น Horovod ด้วยเครื่องมือสื่อสารย่อย mpi4py ได้ ซึ่งในกรณีนี้ เครื่องมือสื่อสารย่อยแต่ละตัวจะดำเนินการฝึกอบรม Horovod ที่เป็นอิสระ
from mpi4py import MPI
import horovod . tensorflow as hvd
# Split COMM_WORLD into subcommunicators
subcomm = MPI . COMM_WORLD . Split ( color = MPI . COMM_WORLD . rank % 2 ,
key = MPI . COMM_WORLD . rank )
# Initialize Horovod
hvd . init ( comm = subcomm )
print ( 'COMM_WORLD rank: %d, Horovod rank: %d' % ( MPI . COMM_WORLD . rank , hvd . rank ()))เรียนรู้วิธีเพิ่มประสิทธิภาพโมเดลของคุณสำหรับการอนุมานและลบการดำเนินการ Horovod ออกจากกราฟที่นี่
หนึ่งในสิ่งพิเศษเกี่ยวกับ Horovod คือความสามารถในการแทรกการสื่อสารและการคำนวณควบคู่ไปกับความสามารถใน การลด การดำเนินการทั้งหมดเป็นชุดเล็กๆ ซึ่งส่งผลให้ประสิทธิภาพดีขึ้น เราเรียกคุณลักษณะการจัดกลุ่มนี้ว่า Tensor Fusion
ดูรายละเอียดทั้งหมดและคำแนะนำในการปรับแต่งได้ที่นี่
Horovod มีความสามารถในการบันทึกไทม์ไลน์ของกิจกรรมที่เรียกว่า Horovod Timeline
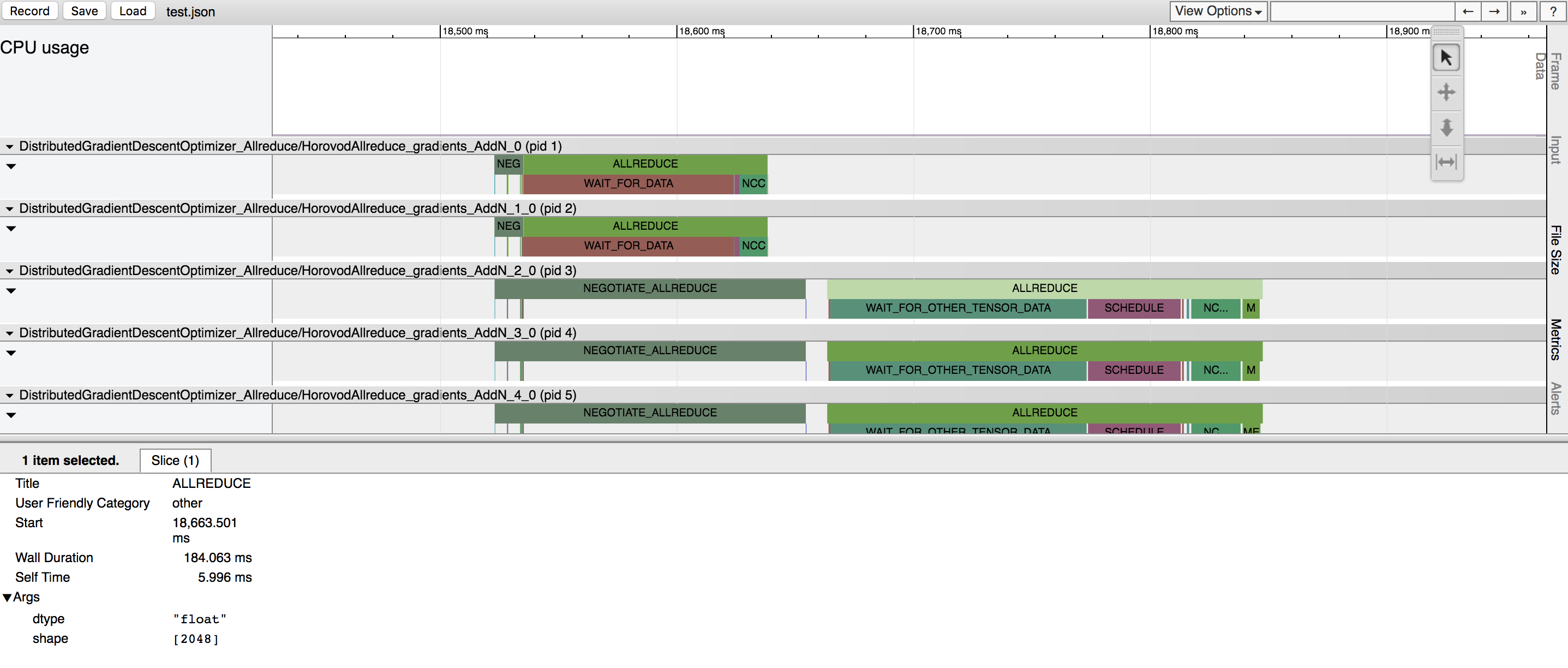
ใช้ไทม์ไลน์ Horovod เพื่อวิเคราะห์ประสิทธิภาพของ Horovod ดูรายละเอียดทั้งหมดและคำแนะนำการใช้งานได้ที่นี่
การเลือกค่าที่เหมาะสมเพื่อใช้งาน Tensor Fusion และคุณสมบัติขั้นสูงอื่นๆ ของ Horovod ได้อย่างมีประสิทธิภาพ อาจต้องอาศัยการลองผิดลองถูกในปริมาณมาก เราจัดเตรียมระบบเพื่อทำให้กระบวนการเพิ่มประสิทธิภาพการทำงานนี้เรียกว่า การปรับอัตโนมัติโดยอัตโนมัติ ซึ่งคุณสามารถเปิดใช้งานด้วยอาร์กิวเมนต์บรรทัดคำสั่งเดียวเพื่อ horovodrun
ดูรายละเอียดทั้งหมดและคำแนะนำการใช้งานได้ที่นี่
Horovod ช่วยให้คุณสามารถดำเนินการปฏิบัติการร่วมที่แตกต่างกันในกลุ่มกระบวนการต่างๆ พร้อมกันโดยมีส่วนร่วมในการฝึกอบรมแบบกระจายครั้งเดียว ตั้งค่าอ็อบเจ็กต์ hvd.process_set เพื่อใช้ความสามารถนี้
ดูชุดกระบวนการสำหรับคำแนะนำโดยละเอียด
ส่งลิงก์ไปยังคู่มือผู้ใช้ที่คุณต้องการเผยแพร่บนเว็บไซต์นี้
ดูการแก้ไขปัญหาและส่งตั๋วหากคุณไม่พบคำตอบ
โปรดอ้างอิง Horovod ในสิ่งพิมพ์ของคุณหากช่วยในการวิจัยของคุณ:
@article{sergeev2018horovod,
ผู้แต่ง = {Alexander Sergeev และ Mike Del Balso},
วารสาร = {arXiv พิมพ์ล่วงหน้า arXiv:1802.05799},
Title = {Horovod: การเรียนรู้เชิงลึกแบบกระจายที่ง่ายและรวดเร็วใน {TensorFlow}}
ปี = {2018}
-
1. Sergeev, A., Del Balso, M. (2017) พบกับ Horovod: กรอบการเรียนรู้เชิงลึกแบบโอเพ่นซอร์สของ Uber สำหรับ TensorFlow ดึงมาจาก https://eng.uber.com/horovod/
2. Sergeev, A. (2017) Horovod - TensorFlow แบบกระจายทำได้ง่าย ดึงมาจาก https://www.slideshare.net/AlexanderSergeev4/horovod-distributed-tensorflow-made-easy
3. Sergeev, A., Del Balso, M. (2018) Horovod: การเรียนรู้เชิงลึกแบบกระจายที่ง่ายและรวดเร็วใน TensorFlow ดึงข้อมูลจาก arXiv:1802.05799
ซอร์สโค้ด Horovod มีพื้นฐานมาจากพื้นที่เก็บข้อมูล Baidu tensorflow-allreduce ที่เขียนโดย Andrew Gibiansky และ Joel Hestness งานต้นฉบับของพวกเขาอธิบายไว้ในบทความ Bringing HPC Techniques to Deep Learning


