open_llama
1.0.0
TL; DR : เรากำลังเผยแพร่ตัวอย่างสาธารณะของ OpenLLaMA ซึ่งเป็นการจำลอง LLaMA ของ Meta AI แบบโอเพ่นซอร์สที่ได้รับอนุญาตโดยได้รับอนุญาต เรากำลังเปิดตัวซีรีส์โมเดล 3B, 7B และ 13B ที่ได้รับการฝึกเกี่ยวกับการผสมข้อมูลที่แตกต่างกัน น้ำหนักโมเดลของเราสามารถทำหน้าที่แทน LLaMA ที่ลดลงในการใช้งานที่มีอยู่ได้
ในการซื้อคืนนี้ เรานำเสนอการจำลองแบบโอเพ่นซอร์สที่ได้รับอนุญาตตามอนุญาตของโมเดลภาษาขนาดใหญ่ LLaMA ของ Meta AI เรากำลังเปิดตัวซีรีส์โมเดล 3B, 7B และ 13B ที่ได้รับการฝึกอบรมเกี่ยวกับโทเค็น 1T เราจัดเตรียมน้ำหนัก PyTorch และ JAX ของโมเดล OpenLLaMA ที่ผ่านการฝึกอบรมมาแล้ว ตลอดจนผลการประเมินและการเปรียบเทียบกับโมเดล LLaMA ดั้งเดิม โมเดล v2 นั้นดีกว่าโมเดล v1 รุ่นเก่าที่ได้รับการฝึกโดยใช้ส่วนผสมของข้อมูลที่แตกต่างกัน
เรากำลังเปิดตัวโมเดล OpenLLaMA 3Bv3 ซึ่งเป็นโมเดล 3B ที่ได้รับการฝึกสำหรับโทเค็น 1T บนชุดข้อมูลเดียวกันกับโมเดล 7Bv2
เรามีความยินดีที่จะเปิดตัวโมเดล OpenLLaMA 7Bv2 ซึ่งได้รับการฝึกฝนเกี่ยวกับการผสมผสานระหว่างชุดข้อมูลเว็บที่ได้รับการปรับปรุงของ Falcon ผสมกับชุดข้อมูล starcoder และวิกิพีเดีย arxiv และหนังสือ และการแลกเปลี่ยนสแต็คจาก RedPajama
เรามีความยินดีที่จะเปิดตัว OpenLLaMA 13B เวอร์ชันโทเค็น 1T สุดท้ายของเรา เราได้อัปเดตผลการประเมินแล้ว สำหรับเวอร์ชันปัจจุบันของ OpenLLaMA โมเดลโทเค็นของเราได้รับการฝึกฝนให้รวมช่องว่างหลาย ๆ ช่องให้เป็นหนึ่งเดียวก่อนการแปลงโทเค็น คล้ายกับโทเค็น T5 ด้วยเหตุนี้ tokenizer ของเราจะไม่ทำงานกับงานสร้างโค้ด (เช่น HumanEval) เนื่องจากโค้ดเกี่ยวข้องกับพื้นที่ว่างจำนวนมาก สำหรับงานที่เกี่ยวข้องกับโค้ด โปรดใช้โมเดล v2
เรามีความยินดีที่จะเปิดตัวโทเค็น 1T เวอร์ชันสุดท้ายของ OpenLLaMA 3B และ 7B เราได้อัปเดตผลการประเมินแล้ว นอกจากนี้เรายังยินดีที่จะเปิดตัวตัวอย่างโทเค็น 600B ของรุ่น 13B ซึ่งได้รับการฝึกฝนร่วมกับ Stability AI
เรามีความยินดีที่จะเปิดตัวจุดตรวจสอบโทเค็น 700B สำหรับรุ่น OpenLLaMA 7B และจุดตรวจสอบโทเค็น 600B สำหรับรุ่น 3B เรายังอัปเดตผลการประเมินอีกด้วย เราคาดว่าการฝึกซ้อมโทเค็น 1T เต็มรูปแบบจะเสร็จสิ้นในปลายสัปดาห์นี้
หลังจากได้รับคำติชมจากชุมชน เราพบว่าโทเค็นของการปล่อยจุดตรวจสอบก่อนหน้านี้ได้รับการกำหนดค่าไม่ถูกต้อง จึงไม่รักษาบรรทัดใหม่ไว้ เพื่อแก้ไขปัญหานี้ เราได้ฝึกโทเค็นไนเซอร์ของเราใหม่ และเริ่มการฝึกโมเดลอีกครั้ง นอกจากนี้เรายังพบว่าการสูญเสียการฝึกลดลงด้วย tokenizer ใหม่นี้
เราเผยแพร่ตุ้มน้ำหนักในสองรูปแบบ: รูปแบบ EasyLM ที่จะใช้กับเฟรมเวิร์ก EasyLM ของเรา และรูปแบบ PyTorch ที่จะใช้กับไลบรารี Hugging Face Transformers ทั้งกรอบการฝึกอบรม EasyLM และตุ้มน้ำหนักจุดตรวจสอบของเราได้รับอนุญาตภายใต้ใบอนุญาต Apache 2.0
สามารถโหลดจุดตรวจสอบตัวอย่างได้โดยตรงจาก Hugging Face Hub โปรดทราบว่าขอแนะนำให้หลีกเลี่ยงการใช้โทเค็นแบบเร็ว Hugging Face ในตอนนี้ เนื่องจากเราได้สังเกตเห็นว่า โทเค็นแบบเร็วที่แปลงอัตโนมัติบางครั้งให้โทเค็นที่ไม่ถูก ต้อง ซึ่งสามารถทำได้โดยใช้คลาส LlamaTokenizer โดยตรง หรือส่งผ่านตัวเลือก use_fast=False สำหรับคลาส AutoTokenizer ดูตัวอย่างการใช้งานต่อไปนี้
import torch
from transformers import LlamaTokenizer , LlamaForCausalLM
## v2 models
model_path = 'openlm-research/open_llama_3b_v2'
# model_path = 'openlm-research/open_llama_7b_v2'
## v1 models
# model_path = 'openlm-research/open_llama_3b'
# model_path = 'openlm-research/open_llama_7b'
# model_path = 'openlm-research/open_llama_13b'
tokenizer = LlamaTokenizer . from_pretrained ( model_path )
model = LlamaForCausalLM . from_pretrained (
model_path , torch_dtype = torch . float16 , device_map = 'auto' ,
)
prompt = 'Q: What is the largest animal? n A:'
input_ids = tokenizer ( prompt , return_tensors = "pt" ). input_ids
generation_output = model . generate (
input_ids = input_ids , max_new_tokens = 32
)
print ( tokenizer . decode ( generation_output [ 0 ]))สำหรับการใช้งานขั้นสูงเพิ่มเติม โปรดปฏิบัติตามเอกสารประกอบของ Transformers LLaMA
โมเดลสามารถประเมินได้ด้วย lm-eval-harness อย่างไรก็ตาม เนื่องจากปัญหาโทเค็นไนเซอร์ที่กล่าวมาข้างต้น เราจำเป็นต้องหลีกเลี่ยงการใช้โทเค็นไนเซอร์ที่รวดเร็วเพื่อให้ได้ผลลัพธ์ที่ถูกต้อง ซึ่งสามารถทำได้โดยการส่งผ่าน use_fast=False ไปยังส่วนนี้ของ lm-eval-harness ดังที่แสดงในตัวอย่างด้านล่าง:
tokenizer = self . AUTO_TOKENIZER_CLASS . from_pretrained (
pretrained if tokenizer is None else tokenizer ,
revision = revision + ( "/" + subfolder if subfolder is not None else "" ),
use_fast = False
)สำหรับการใช้ตุ้มน้ำหนักในกรอบงาน EasyLM ของเรา โปรดดูเอกสาร LLaMA ของ EasyLM โปรดทราบว่าโทเค็น OpenLLaMA และตุ้มน้ำหนักต่างจากรุ่น LLaMA ดั้งเดิมตรงที่การฝึกอบรมอย่างสมบูรณ์ตั้งแต่เริ่มต้น ดังนั้นจึงไม่จำเป็นต้องรับโทเค็นและตุ้มน้ำหนัก LLaMA ดั้งเดิมอีกต่อไป
โมเดล v1 ได้รับการฝึกฝนบนชุดข้อมูล RedPajama โมเดล v2 ได้รับการฝึกโดยใช้ส่วนผสมของชุดข้อมูลเว็บที่ได้รับการปรับปรุงของ Falcon, ชุดข้อมูล StarCoder และส่วนวิกิพีเดีย, arxiv, book และ stackexchange ของชุดข้อมูล RedPajama เราทำตามขั้นตอนการประมวลผลล่วงหน้าและไฮเปอร์พารามิเตอร์การฝึกอบรมที่เหมือนกันทุกประการกับรายงาน LLaMA ต้นฉบับ รวมถึงสถาปัตยกรรมแบบจำลอง ความยาวบริบท ขั้นตอนการฝึกอบรม กำหนดอัตราการเรียนรู้ และเครื่องมือเพิ่มประสิทธิภาพ ความแตกต่างเพียงอย่างเดียวระหว่างการตั้งค่าของเรากับการตั้งค่าดั้งเดิมคือชุดข้อมูลที่ใช้: OpenLLaMA ใช้ชุดข้อมูลแบบเปิดแทนที่จะเป็นชุดข้อมูลที่ใช้โดย LLaMA ดั้งเดิม
เราฝึกโมเดลบนคลาวด์ TPU-v4 โดยใช้ EasyLM ซึ่งเป็นไปป์ไลน์การฝึกที่ใช้ JAX ที่เราพัฒนาขึ้นเพื่อการฝึกและปรับแต่งโมเดลภาษาขนาดใหญ่อย่างละเอียด เราใช้การผสมผสานระหว่างความเท่าเทียมของข้อมูลปกติและความเท่าเทียมของข้อมูลที่แบ่งส่วนอย่างสมบูรณ์ (หรือที่รู้จักในชื่อ ZeRO ระยะที่ 3) เพื่อสร้างสมดุลปริมาณงานการฝึกอบรมและการใช้หน่วยความจำ โดยรวมแล้วเรามีทรูพุตมากกว่า 2,200 โทเค็น / วินาที / ชิป TPU-v4 สำหรับรุ่น 7B ของเรา การสูญเสียการฝึกสามารถดูได้ในรูปด้านล่าง
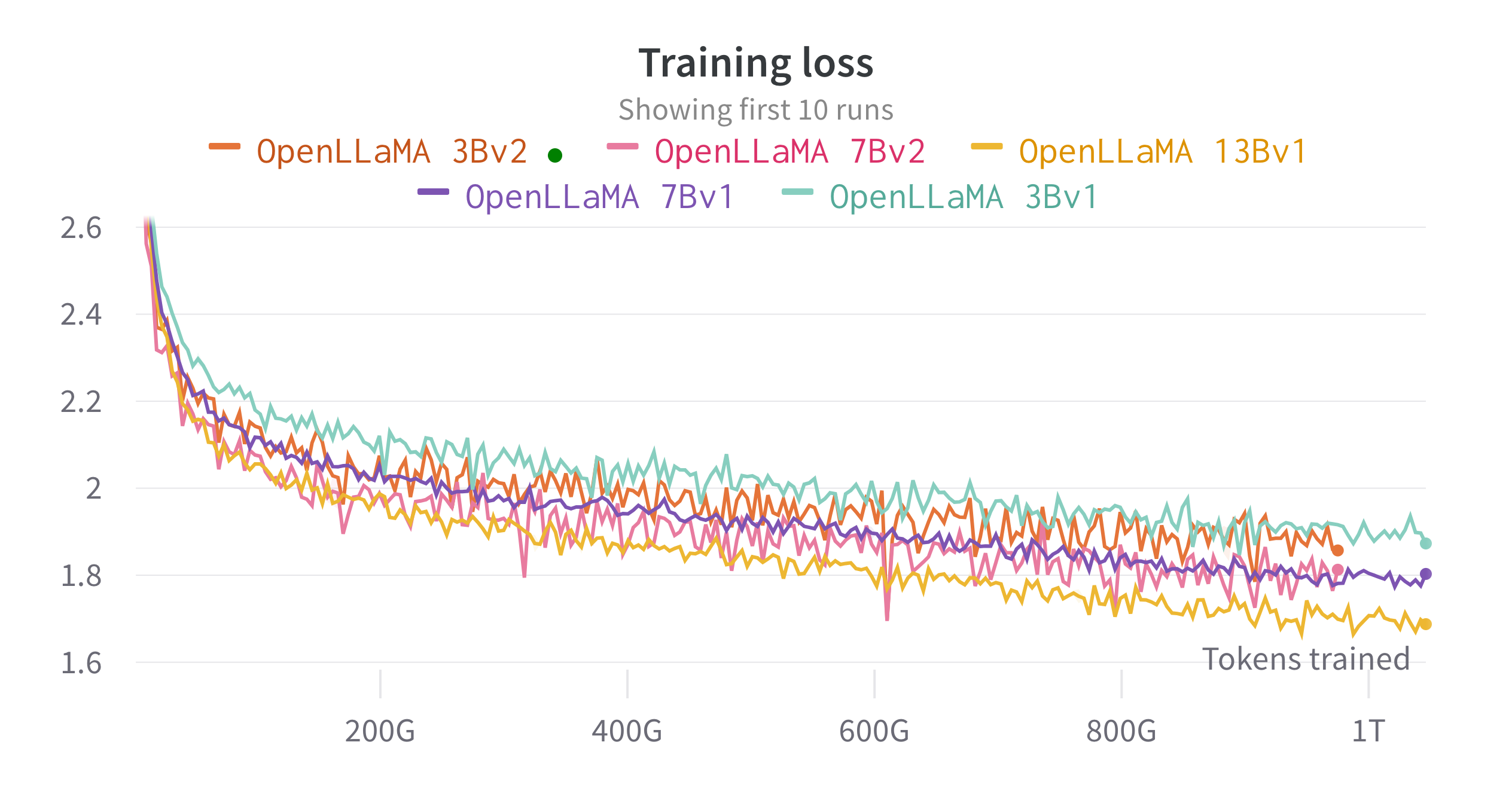
เราประเมิน OpenLLaMA ในงานที่หลากหลายโดยใช้ lm-evalue-harness ผลลัพธ์ของ LLaMA ถูกสร้างขึ้นโดยการรันแบบจำลอง LLaMA ดั้งเดิมบนตัวชี้วัดการประเมินเดียวกัน เราทราบว่าผลลัพธ์ของเราสำหรับแบบจำลอง LLaMA แตกต่างจากรายงาน LLaMA ดั้งเดิมเล็กน้อย ซึ่งเราเชื่อว่าเป็นผลมาจากโปรโตคอลการประเมินที่แตกต่างกัน มีรายงานความแตกต่างที่คล้ายกันใน lm-evalue-harness ฉบับนี้ นอกจากนี้ เรายังนำเสนอผลลัพธ์ของ GPT-J ซึ่งเป็นแบบจำลองพารามิเตอร์ 6B ที่ได้รับการฝึกบนชุดข้อมูล Pile โดย EleutherAI
โมเดล LLaMA ดั้งเดิมได้รับการฝึกอบรมสำหรับโทเค็น 1 ล้านล้านโทเค็น และ GPT-J ได้รับการฝึกอบรมสำหรับโทเค็น 500 พันล้านโทเค็น เรานำเสนอผลลัพธ์ในตารางด้านล่าง OpenLLaMA จัดแสดงประสิทธิภาพที่เทียบเคียงได้กับ LLaMA และ GPT-J ดั้งเดิมในงานส่วนใหญ่ และมีประสิทธิภาพเหนือกว่าในบางงาน
| งาน/เมตริก | GPT-J 6B | ลามา 7B | ลามา 13B | OpenLLaMA 3Bv2 | OpenLLaMA 7Bv2 | OpenLLaMA 3B | โอเพ่นLLaMA 7B | โอเพ่นLLaMA 13B |
|---|---|---|---|---|---|---|---|---|
| anli_r1/ตามมาตรฐาน | 0.32 | 0.35 | 0.35 | 0.33 | 0.34 | 0.33 | 0.33 | 0.33 |
| anli_r2/ตามมาตรฐาน | 0.34 | 0.34 | 0.36 | 0.36 | 0.35 | 0.32 | 0.36 | 0.33 |
| anli_r3/ตามมาตรฐาน | 0.35 | 0.37 | 0.39 | 0.38 | 0.39 | 0.35 | 0.38 | 0.40 |
| arc_challenge/ตามมาตรฐาน | 0.34 | 0.39 | 0.44 | 0.34 | 0.39 | 0.34 | 0.37 | 0.41 |
| arc_challenge/acc_norm | 0.37 | 0.41 | 0.44 | 0.36 | 0.41 | 0.37 | 0.38 | 0.44 |
| arc_easy/ตามมาตรฐาน | 0.67 | 0.68 | 0.75 | 0.68 | 0.73 | 0.69 | 0.72 | 0.75 |
| arc_easy/acc_norm | 0.62 | 0.52 | 0.59 | 0.63 | 0.70 | 0.65 | 0.68 | 0.70 |
| บูลคิว/บัญชี | 0.66 | 0.75 | 0.71 | 0.66 | 0.72 | 0.68 | 0.71 | 0.75 |
| เฮลลาสวัก/ตาม | 0.50 | 0.56 | 0.59 | 0.52 | 0.56 | 0.49 | 0.53 | 0.56 |
| เฮลลาสวัก/acc_norm | 0.66 | 0.73 | 0.76 | 0.70 | 0.75 | 0.67 | 0.72 | 0.76 |
| openbookqa/acc | 0.29 | 0.29 | 0.31 | 0.26 | 0.30 น | 0.27 | 0.30 น | 0.31 |
| openbookqa/acc_norm | 0.38 | 0.41 | 0.42 | 0.38 | 0.41 | 0.40 | 0.40 | 0.43 |
| ปิก้า/ตามมาตรฐาน | 0.75 | 0.78 | 0.79 | 0.77 | 0.79 | 0.75 | 0.76 | 0.77 |
| ปิคา/acc_norm | 0.76 | 0.78 | 0.79 | 0.78 | 0.80 | 0.76 | 0.77 | 0.79 |
| บันทึก/em | 0.88 | 0.91 | 0.92 | 0.87 | 0.89 | 0.88 | 0.89 | 0.91 |
| บันทึก/f1 | 0.89 | 0.91 | 0.92 | 0.88 | 0.89 | 0.89 | 0.90 | 0.91 |
| rte/ตามมาตรฐาน | 0.54 | 0.56 | 0.69 | 0.55 | 0.57 | 0.58 | 0.60 | 0.64 |
| truefulqa_mc/mc1 | 0.20 | 0.21 | 0.25 | 0.22 | 0.23 | 0.22 | 0.23 | 0.25 |
| ความจริงqa_mc/mc2 | 0.36 | 0.34 | 0.40 | 0.35 | 0.35 | 0.35 | 0.35 | 0.38 |
| วิค/ตามมาตรฐาน | 0.50 | 0.50 | 0.50 | 0.50 | 0.50 | 0.48 | 0.51 | 0.47 |
| วิโนแกรนด์/ตามมาตรฐาน | 0.64 | 0.68 | 0.70 | 0.63 | 0.66 | 0.62 | 0.67 | 0.70 |
| เฉลี่ย | 0.52 | 0.55 | 0.57 | 0.53 | 0.56 | 0.53 | 0.55 | 0.57 |
เราลบงาน CB และ WSC ออกจากเกณฑ์มาตรฐานของเรา เนื่องจากโมเดลของเราทำงานได้ดีอย่างน่าสงสัยในทั้งสองงาน เราตั้งสมมติฐานว่าอาจมีการปนเปื้อนของข้อมูลเกณฑ์มาตรฐานในชุดการฝึกอบรม
เราอยากจะรับข้อเสนอแนะจากชุมชน หากคุณมีคำถามใด ๆ โปรดเปิดปัญหาหรือติดต่อเรา
OpenLLaMA ได้รับการพัฒนาโดย: Xinyang Geng* และ Hao Liu* จาก Berkeley AI Research *ผลงานที่เท่าเทียมกัน
เราขอขอบคุณโปรแกรม Google TPU Research Cloud ที่มอบส่วนหนึ่งของทรัพยากรการคำนวณ เราขอขอบคุณเป็นพิเศษ Jonathan Caton จาก TPU Research Cloud ที่ช่วยเราจัดระเบียบทรัพยากรการประมวลผล Rafi Witten จากทีม Google Cloud และ James Bradbury จากทีม Google JAX ที่ช่วยเราเพิ่มประสิทธิภาพปริมาณงานการฝึกอบรมของเรา นอกจากนี้เรายังอยากจะขอบคุณ Charlie Snell, Gautier Izacard, Eric Wallace, Lianmin Zheng และชุมชนผู้ใช้ของเราสำหรับการสนทนาและข้อเสนอแนะ
โมเดล OpenLLaMA 13B v1 ได้รับการฝึกอบรมร่วมกับ Stability AI และเราขอขอบคุณ Stability AI สำหรับการจัดหาทรัพยากรการคำนวณ เราขอขอบคุณ David Ha และ Shivanshu Purohit เป็นพิเศษสำหรับการประสานงานด้านลอจิสติกส์และการให้การสนับสนุนด้านวิศวกรรม
หากคุณพบว่า OpenLLaMA มีประโยชน์ในการวิจัยหรือการใช้งานของคุณ โปรดอ้างอิงโดยใช้ BibTeX ต่อไปนี้:
@software{openlm2023openllama,
author = {Geng, Xinyang and Liu, Hao},
title = {OpenLLaMA: An Open Reproduction of LLaMA},
month = May,
year = 2023,
url = {https://github.com/openlm-research/open_llama}
}
@software{together2023redpajama,
author = {Together Computer},
title = {RedPajama-Data: An Open Source Recipe to Reproduce LLaMA training dataset},
month = April,
year = 2023,
url = {https://github.com/togethercomputer/RedPajama-Data}
}
@article{touvron2023llama,
title={Llama: Open and efficient foundation language models},
author={Touvron, Hugo and Lavril, Thibaut and Izacard, Gautier and Martinet, Xavier and Lachaux, Marie-Anne and Lacroix, Timoth{'e}e and Rozi{`e}re, Baptiste and Goyal, Naman and Hambro, Eric and Azhar, Faisal and others},
journal={arXiv preprint arXiv:2302.13971},
year={2023}
}


