SWE bench
1.0.0

- ภาษาญี่ปุ่น | อังกฤษ | 中文简体 | 中文繁體 |
รหัสและข้อมูลสำหรับรายงาน ICLR 2024 ของเรา SWE-bench: โมเดลภาษาสามารถแก้ไขปัญหา GitHub ในโลกแห่งความเป็นจริงได้หรือไม่
โปรดดูเว็บไซต์ของเราสำหรับกระดานผู้นำสาธารณะและบันทึกการเปลี่ยนแปลงสำหรับข้อมูลเกี่ยวกับการอัปเดตล่าสุดในเกณฑ์มาตรฐาน SWE-bench
SWE-bench เป็นเกณฑ์มาตรฐานสำหรับการประเมินโมเดลภาษาขนาดใหญ่เกี่ยวกับปัญหาซอฟต์แวร์ในโลกแห่งความเป็นจริงที่รวบรวมจาก GitHub ด้วย โค้ดเบส และ ปัญหา โมเดลภาษาได้รับมอบหมายให้สร้าง แพตช์ ที่แก้ไขปัญหาที่อธิบายไว้
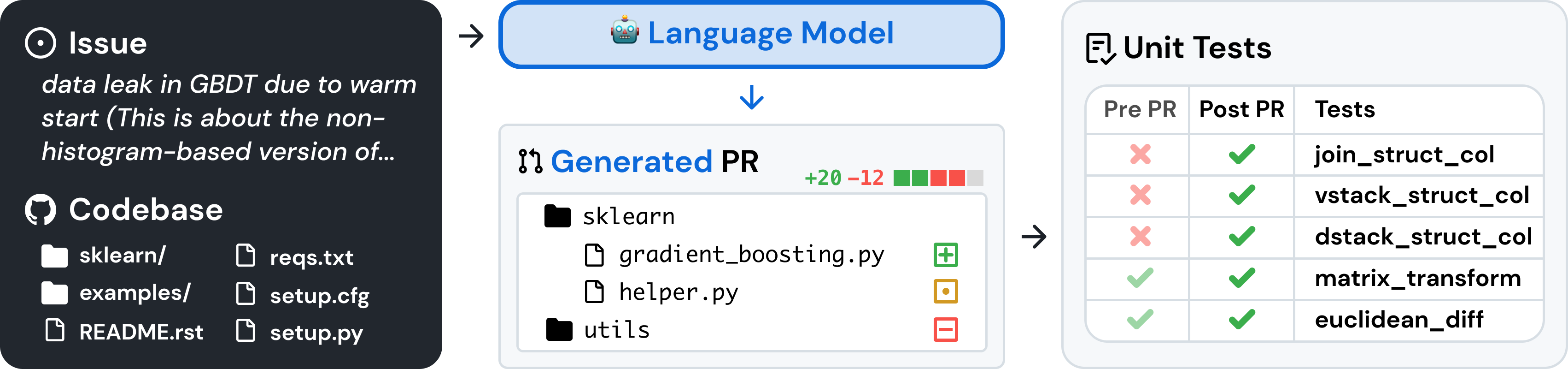
หากต้องการเข้าถึง SWE-bench ให้คัดลอกและเรียกใช้โค้ดต่อไปนี้:
from datasets import load_dataset
swebench = load_dataset ( 'princeton-nlp/SWE-bench' , split = 'test' )SWE-bench ใช้ Docker สำหรับการประเมินที่ทำซ้ำได้ ทำตามคำแนะนำในคู่มือการตั้งค่า Docker เพื่อติดตั้ง Docker บนเครื่องของคุณ หากคุณตั้งค่าบน Linux เราขอแนะนำให้ดูขั้นตอนหลังการติดตั้งด้วย
สุดท้าย หากต้องการสร้าง SWE-bench จากแหล่งที่มา ให้ทำตามขั้นตอนเหล่านี้:
git clone [email protected]:princeton-nlp/SWE-bench.git
cd SWE-bench
pip install -e .ทดสอบการติดตั้งของคุณโดยการรัน:
python -m swebench.harness.run_evaluation
--predictions_path gold
--max_workers 1
--instance_ids sympy__sympy-20590
--run_id validate-goldคำเตือน
การรันการประเมินอย่างรวดเร็วบน SWE-bench อาจต้องใช้ทรัพยากรจำนวนมาก เราขอแนะนำให้รันชุดประเมินผลบนเครื่อง x86_64 ที่มีพื้นที่เก็บข้อมูลฟรีอย่างน้อย 120GB, RAM ขนาด 16GB และคอร์ CPU 8 ตัว คุณอาจต้องทดลองใช้อาร์กิวเมนต์ --max_workers เพื่อค้นหาจำนวนพนักงานที่เหมาะสมที่สุดสำหรับเครื่องของคุณ แต่เราแนะนำให้ใช้น้อยกว่า min(0.75 * os.cpu_count(), 24)
หากใช้งานกับเดสก์ท็อปนักเทียบท่า ตรวจสอบให้แน่ใจว่าได้เพิ่มพื้นที่ดิสก์เสมือนของคุณให้มี ~120 GB ว่าง และตั้งค่า max_workers ให้สอดคล้องกับข้างต้นสำหรับ CPU ที่พร้อมใช้งานสำหรับนักเทียบท่า
การสนับสนุนสำหรับเครื่อง arm64 อยู่ระหว่างการทดลอง
ประเมินการทำนายแบบจำลองบน SWE-bench Lite โดยใช้สายรัดการประเมินด้วยคำสั่งต่อไปนี้:
python -m swebench.harness.run_evaluation
--dataset_name princeton-nlp/SWE-bench_Lite
--predictions_path < path_to_predictions >
--max_workers < num_workers >
--run_id < run_id >
# use --predictions_path 'gold' to verify the gold patches
# use --run_id to name the evaluation run คำสั่งนี้จะสร้างบันทึกการสร้างนักเทียบท่า ( logs/build_images ) และบันทึกการประเมิน ( logs/run_evaluation ) ในไดเร็กทอรีปัจจุบัน
ผลการประเมินขั้นสุดท้ายจะถูกจัดเก็บไว้ในไดเร็กทอรี evaluation_results
หากต้องการดูรายการข้อโต้แย้งทั้งหมดสำหรับชุดประเมินผล ให้รัน:
python -m swebench.harness.run_evaluation --helpนอกจากนี้ SWE-Bench repo ยังช่วยให้คุณ:
| ชุดข้อมูล | โมเดล |
|---|---|
| - SWE-ม้านั่ง | - SWE-ลามะ 13b |
| - การสืบค้น "ออราเคิล" | - SWE-ลามะ 13b (PEFT) |
| - BM25 รีไรท์ 13K | - SWE-ลามะ 7b |
| - BM25 ดึงคืน 27K | - SWE-ลามะ 7b (PEFT) |
| - BM25 ดึงคืน 40K | |
| - BM25 การเรียกค้น 50K (โทเค็นลามะ) |
นอกจากนี้เรายังได้เขียนบล็อกโพสต์ต่อไปนี้เกี่ยวกับวิธีใช้ส่วนต่างๆ ของ SWE-bench หากคุณต้องการดูโพสต์เกี่ยวกับหัวข้อใดหัวข้อหนึ่ง โปรดแจ้งให้เราทราบผ่านทางปัญหา
เรายินดีรับฟังความคิดเห็นจากชุมชนการวิจัย NLP, Machine Learning และ Software Engineering ในวงกว้าง และเรายินดีรับความช่วยเหลือ ดึงคำขอ หรือปัญหาใดๆ ในการดำเนินการดังกล่าว โปรดยื่นคำขอดึงข้อมูลหรือฉบับใหม่ และกรอกเทมเพลตที่เกี่ยวข้องตามลำดับ เราจะติดตามผลเร็วๆ นี้อย่างแน่นอน!
ผู้ติดต่อ: Carlos E. Jimenez และ John Yang (อีเมล: [email protected], [email protected])
หากคุณพบว่างานของเรามีประโยชน์ โปรดใช้ข้อมูลอ้างอิงต่อไปนี้
@inproceedings{
jimenez2024swebench,
title={{SWE}-bench: Can Language Models Resolve Real-world Github Issues?},
author={Carlos E Jimenez and John Yang and Alexander Wettig and Shunyu Yao and Kexin Pei and Ofir Press and Karthik R Narasimhan},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024},
url={https://openreview.net/forum?id=VTF8yNQM66}
}
เอ็มไอที. ตรวจสอบ LICENSE.md


