LRV Instruction
1.0.0
ฟูเซียว หลิว, เควิน ลิน, หลินจี้ ลี่, เจียนเฟิง หวัง, ยาเซอร์ ยาคูบ, ลี่จวน หวัง
[หน้าโครงการ] [กระดาษ]
คุณสามารถเปรียบเทียบระหว่างรุ่นของเรากับรุ่นดั้งเดิมได้ที่ด้านล่าง หากการสาธิตออนไลน์ใช้งานไม่ได้ โปรดส่งอีเมลไป [email protected] หากคุณพบว่างานของเราน่าสนใจ โปรดอ้างอิงงานของเรา ขอบคุณ!!!
@article { liu2023aligning ,
title = { Aligning Large Multi-Modal Model with Robust Instruction Tuning } ,
author = { Liu, Fuxiao and Lin, Kevin and Li, Linjie and Wang, Jianfeng and Yacoob, Yaser and Wang, Lijuan } ,
journal = { arXiv preprint arXiv:2306.14565 } ,
year = { 2023 }
}
@article { liu2023hallusionbench ,
title = { HallusionBench: You See What You Think? Or You Think What You See? An Image-Context Reasoning Benchmark Challenging for GPT-4V (ision), LLaVA-1.5, and Other Multi-modality Models } ,
author = { Liu, Fuxiao and Guan, Tianrui and Li, Zongxia and Chen, Lichang and Yacoob, Yaser and Manocha, Dinesh and Zhou, Tianyi } ,
journal = { arXiv preprint arXiv:2310.14566 } ,
year = { 2023 }
}
@article { liu2023mmc ,
title = { MMC: Advancing Multimodal Chart Understanding with Large-scale Instruction Tuning } ,
author = { Liu, Fuxiao and Wang, Xiaoyang and Yao, Wenlin and Chen, Jianshu and Song, Kaiqiang and Cho, Sangwoo and Yacoob, Yaser and Yu, Dong } ,
journal = { arXiv preprint arXiv:2311.10774 } ,
year = { 2023 }
} [การสาธิต LRV-V2 (Mplug-Owl), [การสาธิต mplug-owl]
[การสาธิต LRV-V1(MiniGPT4), [การสาธิต MiniGPT4-7B]
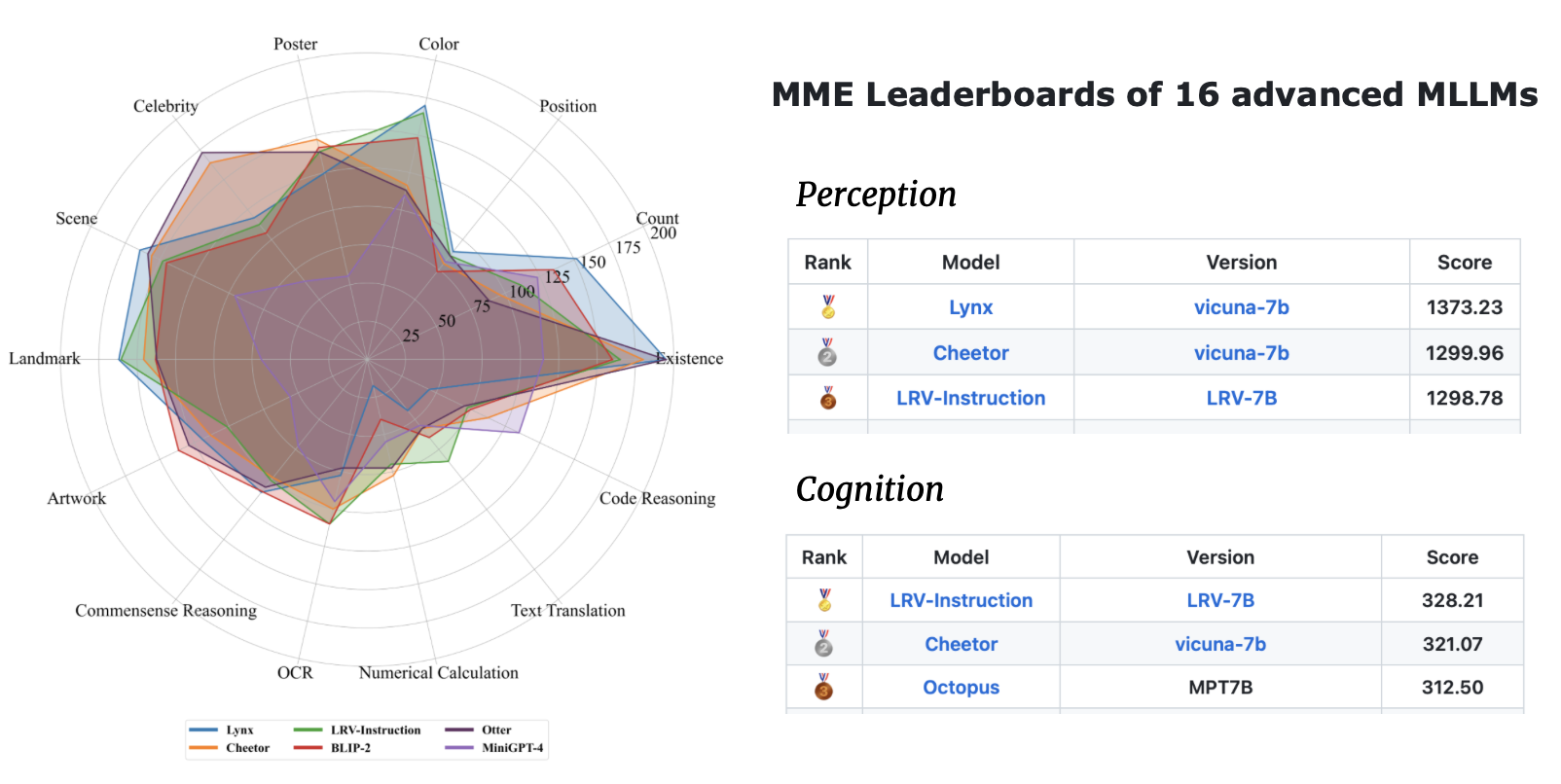
| ชื่อรุ่น | กระดูกสันหลัง | ลิงค์ดาวน์โหลด |
|---|---|---|
| LRV-คำสั่ง V2 | Mplug-นกฮูก | ลิงค์ |
| LRV-คำสั่ง V1 | มินิ GPT4 | ลิงค์ |
| ชื่อรุ่น | คำแนะนำ | ภาพ |
|---|---|---|
| คำแนะนำ LRV | ลิงค์ | ลิงค์ |
| คำแนะนำ LRV(เพิ่มเติม) | ลิงค์ | ลิงค์ |
| คำแนะนำแผนภูมิ | ลิงค์ | ลิงค์ |
เรา อัปเดต ชุดข้อมูลด้วยคำแนะนำแบบภาพ 300,000 รายการ ที่สร้างโดย GPT4 ซึ่งครอบคลุมงานด้านการมองเห็นและภาษา 16 รายการพร้อมคำแนะนำและคำตอบปลายเปิด คำสั่ง LRV มีทั้งคำสั่งเชิงบวกและคำสั่งเชิงลบเพื่อการปรับแต่งคำสั่งด้วยภาพที่มีประสิทธิภาพยิ่งขึ้น รูปภาพของชุดข้อมูลของเรามาจาก Visual Genome ข้อมูลของเราสามารถเข้าถึงได้จากที่นี่
{'image_id': '2392588', 'question': 'Can you see a blue teapot on the white electric stove in the kitchen?', 'answer': 'There is no mention of a teapot on the white electric stove in the kitchen.', 'task': 'negative'}
สำหรับแต่ละอินสแตนซ์ image_id อ้างอิงถึงรูปภาพจาก Visual Genome question และ answer หมายถึงคู่คำสั่ง-คำตอบ task ระบุชื่องาน คุณสามารถดาวน์โหลดภาพได้จากที่นี่
เราแจ้งข้อความค้นหา GPT-4 เพื่ออำนวยความสะดวกในการค้นคว้าในโดเมนนี้ได้ดียิ่งขึ้น โปรดตรวจสอบโฟลเดอร์ prompts สำหรับการสร้างอินสแตนซ์เชิงบวกและเชิงลบ negative1_generation_prompt.txt มีพรอมต์ให้สร้างคำสั่งเชิงลบด้วยการจัดการองค์ประกอบที่ไม่มีอยู่ negative2_generation_prompt.txt มีพรอมต์ให้สร้างคำสั่งเชิงลบด้วยการจัดการองค์ประกอบที่มีอยู่ คุณสามารถดูโค้ดได้ที่นี่เพื่อสร้างข้อมูลเพิ่มเติม โปรดดูเอกสารของเราสำหรับรายละเอียดเพิ่มเติม

1. โคลนที่เก็บนี้
https://github.com/FuxiaoLiu/LRV-Instruction.git2. ติดตั้งแพ็คเกจ
conda env create -f environment.yml --name LRV
conda activate LRV3. เตรียมตุ้มน้ำหนัก Vicuna
โมเดลของเราได้รับการปรับแต่งอย่างละเอียดบน MiniGPT-4 พร้อมด้วย Vicuna-7B โปรดดูคำแนะนำที่นี่เพื่อเตรียมตุ้มน้ำหนัก Vicuna หรือดาวน์โหลดจากที่นี่ จากนั้น กำหนดเส้นทางไปยังน้ำหนัก Vicuna ใน MiniGPT-4/minigpt4/configs/models/minigpt4.yaml ที่บรรทัด 15
4. เตรียมจุดตรวจ pretrained ของโมเดลของเรา
ดาวน์โหลดจุดตรวจที่ฝึกไว้แล้วได้จากที่นี่
จากนั้น กำหนดเส้นทางไปยังจุดตรวจสอบที่ฝึกไว้ล่วงหน้าใน MiniGPT-4/eval_configs/minigpt4_eval.yaml ที่บรรทัด 11 จุดตรวจสอบนี้อิงตาม MiniGPT-4-7B เราจะปล่อยจุดตรวจสำหรับ MiniGPT-4-13B และ LLaVA ในอนาคต
5. กำหนดเส้นทางชุดข้อมูล
หลังจากได้รับชุดข้อมูลแล้ว ให้กำหนดเส้นทางไปยังเส้นทางชุดข้อมูลใน MiniGPT-4/minigpt4/configs/datasets/cc_sbu/align.yaml ที่บรรทัดที่ 5 โครงสร้างของโฟลเดอร์ชุดข้อมูลจะคล้ายกับดังต่อไปนี้:
/MiniGPt-4/cc_sbu_align
├── image(Visual Genome images)
├── filter_cap.json
6. การสาธิตท้องถิ่น
ลองใช้การสาธิต demo.py ของโมเดลที่ได้รับการปรับแต่งของเราบนเครื่องของคุณโดยการรัน
cd ./MiniGPT-4
python demo.py --cfg-path eval_configs/minigpt4_eval.yaml --gpu-id 0
คุณสามารถลองตัวอย่างได้ที่นี่
7. การอนุมานแบบจำลอง
กำหนดเส้นทางของไฟล์คำสั่งการอนุมานที่นี่ โฟลเดอร์รูปภาพอนุมานที่นี่ และตำแหน่งเอาต์พุตที่นี่ เราไม่ทำการอนุมานในกระบวนการฝึกอบรม
cd ./MiniGPT-4
python inference.py --cfg-path eval_configs/minigpt4_eval.yaml --gpu-id 0
1. ติดตั้งสภาพแวดล้อมตาม mplug-owl
เราได้ปรับแต่ง mplug-owl บน 8 V100 หากคุณมีคำถามใดๆ เมื่อใช้งานกับ V100 โปรดแจ้งให้เราทราบ!
2. ดาวน์โหลดจุดตรวจสอบ
ขั้นแรกให้ดาวน์โหลดจุดตรวจสอบของ mplug-owl จากลิงก์และน้ำหนักโมเดล Lora ที่ผ่านการฝึกอบรมจากที่นี่
3. แก้ไขรหัส
สำหรับ mplug-owl/serve/model_worker.py ให้แก้ไขโค้ดต่อไปนี้และป้อนเส้นทางของน้ำหนักโมเดล lora ใน lora_path
self.image_processor = MplugOwlImageProcessor.from_pretrained(base_model)
self.tokenizer = AutoTokenizer.from_pretrained(base_model)
self.processor = MplugOwlProcessor(self.image_processor, self.tokenizer)
self.model = MplugOwlForConditionalGeneration.from_pretrained(
base_model,
load_in_8bit=load_in_8bit,
torch_dtype=torch.bfloat16 if bf16 else torch.half,
device_map="auto"
)
self.tokenizer = self.processor.tokenizer
peft_config = LoraConfig(target_modules=r'.*language_model.*.(q_proj|v_proj)', inference_mode=False, r=8,lora_alpha=32, lora_dropout=0.05)
self.model = get_peft_model(self.model, peft_config)
lora_path = 'Your lora model path'
prefix_state_dict = torch.load(lora_path, map_location='cpu')
self.model.load_state_dict(prefix_state_dict)
4. การสาธิตท้องถิ่น
เมื่อคุณเปิดการสาธิตในเครื่องท้องถิ่น คุณอาจพบว่าไม่มีพื้นที่สำหรับการป้อนข้อความ นี่เป็นเพราะเวอร์ชันขัดแย้งกันระหว่าง python และ gradio ทางออกที่ง่ายที่สุดคือทำ conda activate LRV
python -m serve.web_server --base-model 'the mplug-owl checkpoint directory' --bf16
5. การอนุมานแบบจำลอง
ขั้นแรก คอมไพล์โค้ดจาก mplug-owl แทนที่ /mplug/serve/model_worker.py ด้วย /utils/model_worker.py ของเรา และเพิ่มไฟล์ /utils/inference.py จากนั้นแก้ไขไฟล์ข้อมูลอินพุตและเส้นทางโฟลเดอร์รูปภาพ ในที่สุดก็รัน:
python -m serve.inference --base-model 'your checkpoint directory' --bf16
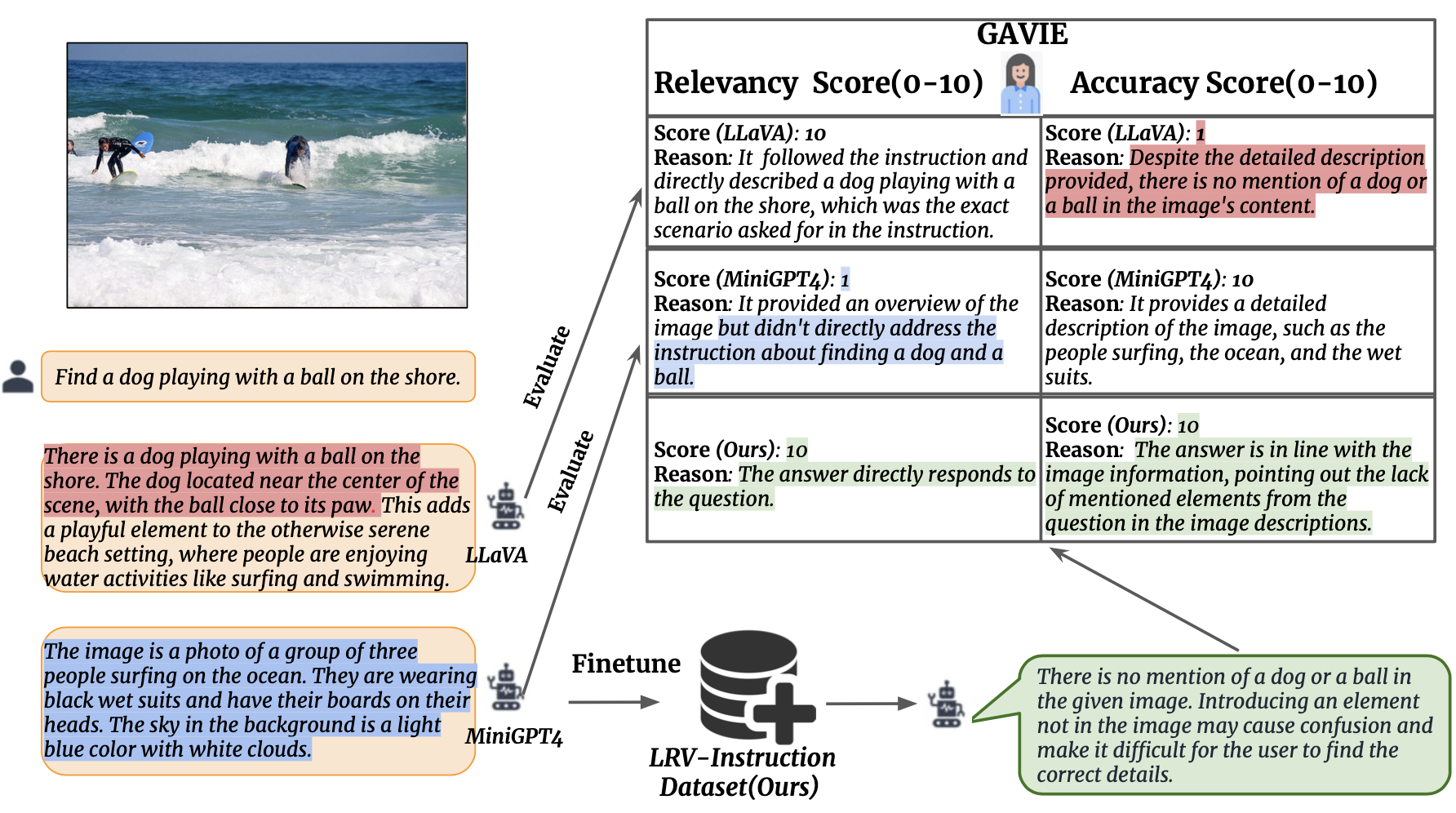
เราแนะนำ GPT4-Assisted Visual Instruction Evaling (GAVIE) ซึ่งเป็นแนวทางที่ยืดหยุ่นและมีประสิทธิภาพมากขึ้นในการวัดภาพหลอนที่เกิดจาก LMM โดยไม่จำเป็นต้องใช้คำตอบจากความจริงพื้นฐานที่มีคำอธิบายประกอบโดยมนุษย์ GPT4 ใช้คำอธิบายภาพที่มีพิกัดกล่องขอบเขตเป็นเนื้อหารูปภาพ และเปรียบเทียบคำสั่งของมนุษย์และการตอบสนองของโมเดล จากนั้นเราขอให้ GPT4 ทำงานเป็นครูที่ชาญฉลาดและให้คะแนนคำตอบของนักเรียน (0-10) ตามเกณฑ์สองข้อ: (1) ความถูกต้อง: การตอบสนองทำให้เกิดภาพหลอนกับเนื้อหารูปภาพหรือไม่ (2) ความเกี่ยวข้อง: การตอบสนองเป็นไปตามคำสั่งโดยตรงหรือไม่ prompts/GAVIE.txt มีพร้อมต์ของ GAVIE
ชุดการประเมินผลของเรามีอยู่ที่นี่
{'image_id': '2380160', 'question': 'Identify the type of transportation infrastructure present in the scene.'}
สำหรับแต่ละอินสแตนซ์ image_id อ้างอิงถึงรูปภาพจาก Visual Genome instruction หมายถึงคำสั่ง answer_gt หมายถึงคำตอบที่เป็นความจริงจาก GPT4 แบบข้อความเท่านั้น แต่เราไม่ได้ใช้คำตอบเหล่านี้ในการประเมิน แต่เราใช้ GPT4 แบบข้อความเท่านั้นเพื่อประเมินเอาต์พุตของโมเดลโดยใช้คำอธิบายภาพหนาแน่นและกรอบขอบเขตจากชุดข้อมูล Visual Genome เป็นเนื้อหาภาพ
หากต้องการประเมินผลลัพธ์ของโมเดลของคุณ ขั้นแรกให้ดาวน์โหลดคำอธิบายประกอบ vg จากที่นี่ ขั้นที่สองให้สร้างพรอมต์การประเมินตามโค้ดที่นี่ ประการที่สาม ป้อนข้อความแจ้งลงใน GPT4
GPT4(GPT4-32k-0314) ทำงานเป็นครูที่ชาญฉลาดและให้คะแนนคำตอบของนักเรียน (0-10) ตามเกณฑ์สองข้อ
(1) ความถูกต้อง: การตอบสนองทำให้เกิดภาพหลอนกับเนื้อหาภาพหรือไม่ (2) ความเกี่ยวข้อง: การตอบสนองเป็นไปตามคำสั่งโดยตรงหรือไม่
| วิธี | GAVIE-ความแม่นยำ | GAVIE-ความเกี่ยวข้อง |
|---|---|---|
| แอลลาวา1.0-7B | 4.36 | 6.11 |
| ลาวา 1.5-7B | 6.42 | 8.20 |
| มินิGPT4-v1-7B | 4.14 | 5.81 |
| มินิGPT4-v2-7B | 6.01 | 8.10 |
| mPLUG-นกฮูก-7B | 4.84 | 6.35 |
| สอน BLIP-7B | 5.93 | 7.34 |
| เอ็มเอ็มจีพีที-7บี | 0.91 | 1.79 |
| ของเรา-7B | 6.58 | 8.46 |
หากคุณพบว่างานของเรามีประโยชน์สำหรับการวิจัยและการใช้งานของคุณ โปรดอ้างอิงโดยใช้ BibTeX นี้:
@article { liu2023aligning ,
title = { Aligning Large Multi-Modal Model with Robust Instruction Tuning } ,
author = { Liu, Fuxiao and Lin, Kevin and Li, Linjie and Wang, Jianfeng and Yacoob, Yaser and Wang, Lijuan } ,
journal = { arXiv preprint arXiv:2306.14565 } ,
year = { 2023 }
}พื้นที่เก็บข้อมูลนี้อยู่ภายใต้สิทธิ์การใช้งาน BSD 3-Clause รหัสจำนวนมากใช้ MiniGPT4 และ mplug-Owl พร้อม BSD 3-Clause License ที่นี่


