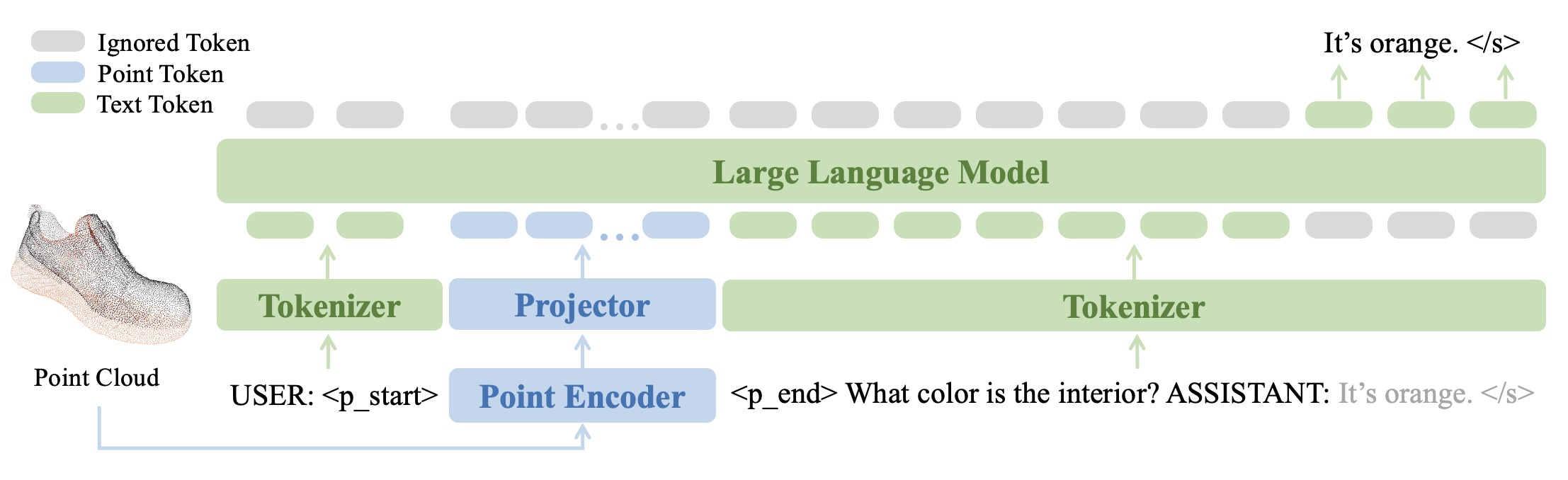
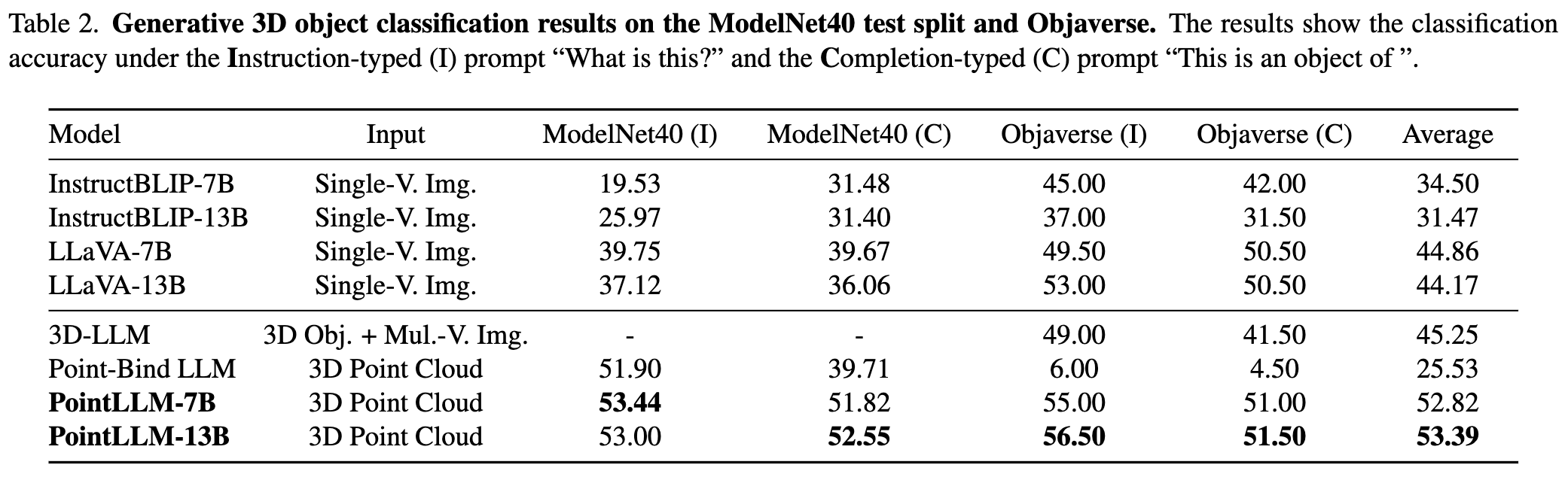
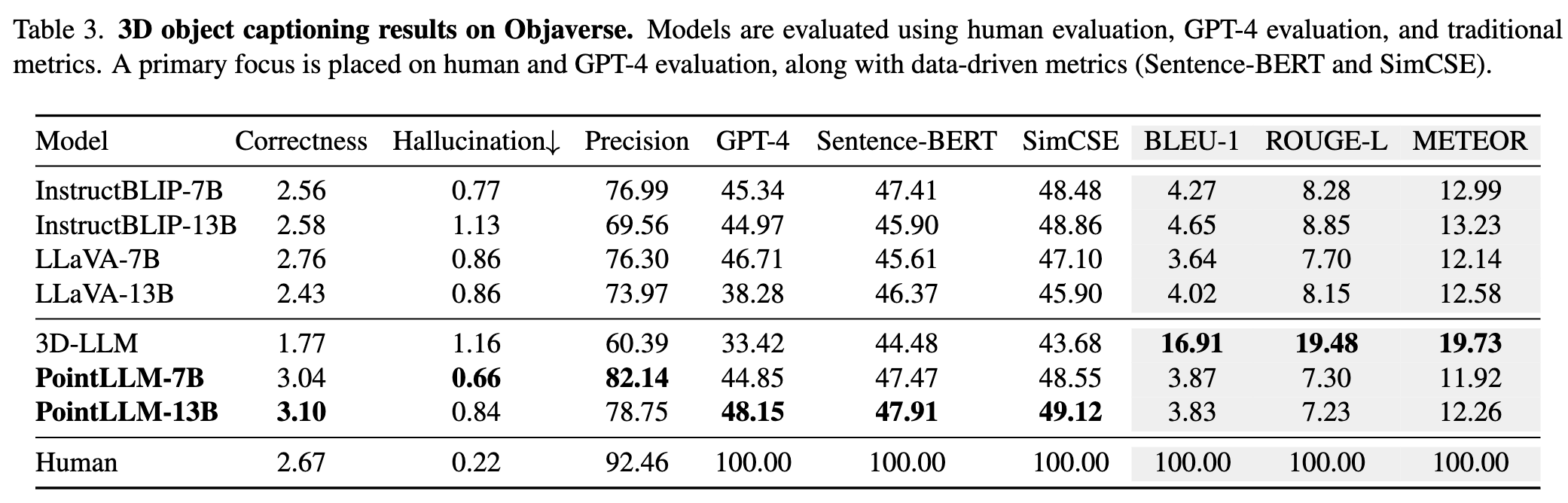
PointLLM
1.0.0
 PointLLM: เสริมศักยภาพให้กับโมเดลภาษาขนาดใหญ่เพื่อทำความเข้าใจ Point Cloud
PointLLM: เสริมศักยภาพให้กับโมเดลภาษาขนาดใหญ่เพื่อทำความเข้าใจ Point Cloud หยุนเซิน ซูเสี่ยวหลง หวังไท่ หวังอี้หลุน เฉิน เจียงเมี่ยว ผาง* ต้าฮัว หลิน
ห้องปฏิบัติการ AI ของมหาวิทยาลัยจีนแห่งฮ่องกง เซี่ยงไฮ้ มหาวิทยาลัยเจ้อเจียง

PointLLM ออนไลน์อยู่! ลองใช้ที่ http://101.230.144.196 หรือที่ OpenXLab/PointLLM
คุณสามารถพูดคุยกับ PointLLM เกี่ยวกับโมเดลของชุดข้อมูล Objaverse หรือเกี่ยวกับ point cloud ของคุณเองได้!
โปรดอย่าลังเลที่จะแจ้งให้เราทราบหากคุณมีข้อเสนอแนะใด ๆ! -
| บทสนทนา 1 | บทสนทนา 2 | บทสนทนา 3 | บทสนทนา 4 |
|---|---|---|---|
 |  |  |  |
โปรดดูเอกสารของเราสำหรับผลลัพธ์เพิ่มเติม
โปรดดูเอกสารของเราสำหรับผลลัพธ์เพิ่มเติม

เราทดสอบรหัสของเราภายใต้สภาพแวดล้อมต่อไปนี้:
ในการเริ่มต้น:
git clone [email protected]:OpenRobotLab/PointLLM.git
cd PointLLMconda create -n pointllm python=3.10 -y
conda activate pointllm
pip install --upgrade pip # enable PEP 660 support
pip install -e .
# * for training
pip install ninja
pip install flash-attn8192_npy ซึ่งมีไฟล์ point cloud ขนาด 660K ชื่อ {Objaverse_ID}_8192.npy แต่ละไฟล์เป็นอาร์เรย์ตัวเลขที่มีขนาด (8192, 6) โดยที่สามมิติแรกคือ xyz และสามมิติสุดท้ายคือ rgb ในช่วง [0, 1] cat Objaverse_660K_8192_npy_split_a * > Objaverse_660K_8192_npy.tar.gz
tar -xvf Objaverse_660K_8192_npy.tar.gzPointLLM ให้สร้าง data โฟลเดอร์และสร้างซอฟต์ลิงก์ไปยังไฟล์ที่ไม่มีการบีบอัดในไดเร็กทอรี cd PointLLM
mkdir data
ln -s /path/to/8192_npy data/objaverse_dataPointLLM/data ให้สร้างไดเร็กทอรีชื่อ anno_dataanno_data ไดเร็กทอรีควรมีลักษณะดังนี้: PointLLM/data/anno_data
├── PointLLM_brief_description_660K_filtered.json
├── PointLLM_brief_description_660K.json
└── PointLLM_complex_instruction_70K.jsonPointLLM_brief_description_660K_filtered.json ถูกกรองจาก PointLLM_brief_description_660K.json โดยการลบอ็อบเจ็กต์ 3000 รายการที่เราจองไว้เป็นชุดการตรวจสอบความถูกต้องออก หากคุณต้องการทำซ้ำผลลัพธ์ในรายงานของเรา คุณควรใช้ PointLLM_brief_description_660K_filtered.json สำหรับการฝึกอบรม PointLLM_complex_instruction_70K.json มีอ็อบเจ็กต์จากชุดการฝึกpointllm/data/data_generation/system_prompt_gpt4_0613.txt PointLLM_brief_description_val_200_GT.json อ้างอิงที่เราใช้สำหรับการวัดประสิทธิภาพบนชุดข้อมูล Objaverse ที่นี่ และใส่ไว้ใน PointLLM/data/anno_data นอกจากนี้เรายังจัดเตรียมรหัสออบเจ็กต์ 3000 รายการที่เรากรองระหว่างการฝึกที่นี่และ GT อ้างอิงที่เกี่ยวข้องที่นี่ ซึ่งสามารถนำไปใช้ในการประเมินบนออบเจ็กต์ 3000 ทั้งหมดได้modelnet40_data ใน PointLLM/data ดาวน์โหลดการทดสอบการแยกของ ModelNet40 point cloud modelnet40_test_8192pts_fps.dat ที่นี่ และวางไว้ใน PointLLM/data/modelnet40_dataPointLLM ให้สร้างไดเร็กทอรีชื่อ checkpointscheckpoints cd PointLLM
scripts/PointLLM_train_stage1.shscripts/PointLLM_train_stage2.shโดยปกติแล้ว คุณไม่จำเป็นต้องสนใจเนื้อหาต่อไปนี้ มีไว้เพื่อทำซ้ำผลลัพธ์ในรายงาน v1 ของเรา (PointLLM-v1.1) เท่านั้น หากคุณต้องการเปรียบเทียบกับโมเดลของเรา หรือใช้โมเดลของเราสำหรับงานดาวน์สตรีม โปรดใช้ PointLLM-v1.2 (โปรดดูเอกสาร v2 ของเรา) ซึ่งมีประสิทธิภาพที่ดีกว่า
PointLLM v1.1 และ v1.2 ใช้พอยต์เอ็นโค้ดเดอร์และโปรเจ็กเตอร์ที่ได้รับการฝึกอบรมล่วงหน้าที่แตกต่างกันเล็กน้อย หากคุณต้องการสร้าง PointLLM v1.1 ขึ้นมาใหม่ ให้แก้ไขไฟล์ config.json ในไดเร็กทอรีของ LLM เริ่มต้นและน้ำหนักตัวเข้ารหัสพอยต์ เช่น vim checkpoints/PointLLM_7B_v1.1_init/config.json
เปลี่ยนคีย์ "point_backbone_config_name" เพื่อระบุการกำหนดค่าตัวเข้ารหัสจุดอื่น:
# change from
" point_backbone_config_name " : " PointTransformer_8192point_2layer " # v1.2
# to
" point_backbone_config_name " : " PointTransformer_base_8192point " , # v1.1 แก้ไขเส้นทางจุดตรวจสอบของตัวเข้ารหัสจุดใน scripts/train_stage1.sh :
# change from
point_backbone_ckpt= $model_name_or_path /point_bert_v1.2.pt # v1.2
# to
point_backbone_ckpt= $model_name_or_path /point_bert_v1.1.pt # v1.1torch.float32 สำหรับการแชทเกี่ยวกับโมเดล 3 มิติของ Objaverse จุดตรวจโมเดลจะถูกดาวน์โหลดโดยอัตโนมัติ คุณยังสามารถดาวน์โหลดจุดตรวจโมเดลด้วยตนเองและระบุเส้นทางได้ นี่คือตัวอย่าง: cd PointLLM
PYTHONPATH= $PWD python pointllm/eval/PointLLM_chat.py --model_name RunsenXu/PointLLM_7B_v1.2 --data_name data/objaverse_data --torch_dtype float32 คุณยังสามารถแก้ไขโค้ดสำหรับการใช้ point cloud อื่นนอกเหนือจาก Objaverse ได้อย่างง่ายดาย ตราบใดที่อินพุต point cloud ของโมเดลมีขนาด (N, 6) โดยที่สามมิติแรกคือ xyz และสามมิติสุดท้ายคือ rgb ( ในช่วง [0, 1]) คุณอาจสุ่มตัวอย่างพอยต์คลาวด์ให้มี 8192 จุด เนื่องจากแบบจำลองของเราได้รับการฝึกฝนบนพอยต์คลาวด์ดังกล่าว
ตารางต่อไปนี้แสดงข้อกำหนดของ GPU สำหรับรุ่นและประเภทข้อมูลที่แตกต่างกัน เราขอแนะนำให้ใช้ torch.bfloat16 หากมี ซึ่งใช้ในการทดลองในรายงานของเรา
| แบบอย่าง | ประเภทข้อมูล | หน่วยความจำจีพียู |
|---|---|---|
| พอยต์LLM-7B | คบเพลิง.ลอย16 | 14GB |
| พอยต์LLM-7B | คบเพลิง.ลอย32 | 28GB |
| พอยต์LLM-13B | คบเพลิง.ลอย16 | 26GB |
| พอยต์LLM-13B | คบเพลิง.ลอย32 | 52GB |
cd PointLLM
PYTHONPATH= $PWD python pointllm/eval/chat_gradio.py --model_name RunsenXu/PointLLM_7B_v1.2 --data_name data/objaverse_data cd PointLLM
export PYTHONPATH= $PWD
# Open Vocabulary Classification on Objaverse
python pointllm/eval/eval_objaverse.py --model_name RunsenXu/PointLLM_7B_v1.2 --task_type classification --prompt_index 0 # or --prompt_index 1
# Object captioning on Objaverse
python pointllm/eval/eval_objaverse.py --model_name RunsenXu/PointLLM_7B_v1.2 --task_type captioning --prompt_index 2
# Close-set Zero-shot Classification on ModelNet40
python pointllm/eval/eval_modelnet_cls.py --model_name RunsenXu/PointLLM_7B_v1.2 --prompt_index 0 # or --prompt_index 1{model_name}/evaluation เป็นแบบ dict ด้วยรูปแบบต่อไปนี้: {
" prompt " : " " ,
" results " : [
{
" object_id " : " " ,
" ground_truth " : " " ,
" model_output " : " " ,
" label_name " : " " # only for classification on modelnet40
}
]
} cd PointLLM
export PYTHONPATH= $PWD
export OPENAI_API_KEY=sk- ****
# Open Vocabulary Classification on Objaverse
python pointllm/eval/evaluator.py --results_path /path/to/model_output --model_type gpt-4-0613 --eval_type open-free-form-classification --parallel --num_workers 15
# Object captioning on Objaverse
python pointllm/eval/evaluator.py --results_path /path/to/model_output --model_type gpt-4-0613 --eval_type object-captioning --parallel --num_workers 15
# Close-set Zero-shot Classification on ModelNet40
python pointllm/eval/evaluator.py --results_path /path/to/model_output --model_type gpt-3.5-turbo-0613 --eval_type modelnet-close-set-classification --parallel --num_workers 15Ctrl+C นี่จะบันทึกผลลัพธ์ชั่วคราว หากมีข้อผิดพลาดเกิดขึ้นระหว่างการประเมิน สคริปต์จะบันทึกสถานะปัจจุบันด้วย คุณสามารถดำเนินการประเมินต่อจากจุดที่ค้างไว้ได้โดยการรันคำสั่งเดิมอีกครั้ง{model_name}/evaluation เป็นคำสั่งอื่น เมตริกบางส่วนมีการอธิบายดังนี้: " average_score " : The GPT-evaluated captioning score we report in our paper.
" accuracy " : The classification accuracy we report in our paper, including random choices made by ChatGPT when model outputs are vague or ambiguous and ChatGPT outputs " INVALID " .
" clean_accuracy " : The classification accuracy after removing those " INVALID " outputs.
" total_predictions " : The number of predictions.
" correct_predictions " : The number of correct predictions.
" invalid_responses " : The number of " INVALID " outputs by ChatGPT.
# Some other statistics for calling OpenAI API
" prompt_tokens " : The total number of tokens of the prompts for ChatGPT/GPT-4.
" completion_tokens " : The total number of tokens of the completion results from ChatGPT/GPT-4.
" GPT_cost " : The API cost of the whole evaluation process, in US Dollars ?.--start_eval และระบุ --gpt_type ตัวอย่างเช่น: python pointllm/eval/eval_objaverse.py --model_name RunsenXu/PointLLM_7B_v1.2 --task_type classification --prompt_index 0 --start_eval --gpt_type gpt-4-0613python pointllm/eval/traditional_evaluator.py --results_path /path/to/model_captioning_outputยินดีต้อนรับการมีส่วนร่วมของชุมชน!? หากคุณต้องการความช่วยเหลือใด ๆ โปรดอย่าลังเลที่จะเปิดปัญหาหรือติดต่อเรา
หากคุณพบว่างานของเราและโค้ดเบสนี้มีประโยชน์ โปรดพิจารณานำแสดงโดย repo นี้ ? และอ้างอิง:
@inproceedings { xu2024pointllm ,
title = { PointLLM: Empowering Large Language Models to Understand Point Clouds } ,
author = { Xu, Runsen and Wang, Xiaolong and Wang, Tai and Chen, Yilun and Pang, Jiangmiao and Lin, Dahua } ,
booktitle = { ECCV } ,
year = { 2024 }
}
งานนี้อยู่ภายใต้สัญญาอนุญาตสากลของ Creative Commons Attribution-NonCommercial-ShareAlike 4.0
มาร่วมกันสร้าง LLM สำหรับ 3D ที่ยอดเยี่ยมกันเถอะ!


