Q Bench
1.0.0
LLM แบบหลายรูปแบบทำงานอย่างไรกับคอมพิวเตอร์วิทัศน์ระดับต่ำ
หวู่หนิง 1 * , จื่อเฉิง จาง 2 * , เอ้อลี่ จาง 1 * , เฉาเฟิง เฉิน 1 , เหลียง เหลียว 1 ,
อันนัน หวัง 1 , ชุนยี่ หลี่ 2 , เหวินซิ่ว ซุน 3 , เฉียง หยาน 3 , กวงเทา ไจ้ 2 , เหวย หลิน 1 #
1 มหาวิทยาลัยเทคโนโลยีนันยาง, 2 มหาวิทยาลัยเซี่ยงไฮ้เจียวทง, 3 การวิจัย Sensetime
* ผลงานที่เท่าเทียมกัน # ผู้เขียนที่สอดคล้องกัน
สปอตไลท์ ICLR2024
กระดาษ | หน้าโครงการ | Github | ข้อมูล (LLVisionQA) | ข้อมูล (LLDescribe) |质衡 (ภาษาจีน-Q-Bench)


Q-Bench ที่นำเสนอประกอบด้วยสามขอบเขตสำหรับการมองเห็นระดับต่ำ: การรับรู้ (A1) คำอธิบาย (A2) และการประเมิน (A3)
สำหรับการรับรู้ (A1) /คำอธิบาย (A2) เรารวบรวมชุดข้อมูลการวัดประสิทธิภาพสองชุด LLVisionQA/LLDescribe
เราเปิดรับ การประเมินตามการส่งงาน ทั้งสองงาน รายละเอียดในการยื่นมีดังนี้
สำหรับการประเมิน (A3) เนื่องจากเราใช้ ชุดข้อมูลสาธารณะ เราจะจัดเตรียมโค้ดการประเมินเชิงนามธรรมสำหรับ MLLM ที่กำหนดเองเพื่อให้ทุกคนทดสอบได้
datasets API สำหรับ Q-Bench-A1 (ที่มีคำถามแบบปรนัย) เราได้แปลงเป็นชุดข้อมูลรูปแบบ HF ที่สามารถดาวน์โหลดและใช้กับ datasets API ได้โดยอัตโนมัติ โปรดดูคำแนะนำต่อไปนี้:
ชุดข้อมูลการติดตั้ง pip
จากชุดข้อมูลนำเข้า load_datasetds = load_dataset("q-future/Q-Bench-HF")print(ds["dev"][0])### {'id': 0,### 'image': <PIL .JpegImagePlugin.JpegImageFile image mode=RGB size=4160x3120>,### 'question': 'แสงของสิ่งนี้เป็นอย่างไร อาคาร?',### 'option0': 'สูง',### 'option1': 'ต่ำ',### 'option2': 'ปานกลาง',### 'option3': 'N/A', ### 'question_type': 2,### 'question_concern': 3,### 'correct_choice': 'B'} จากชุดข้อมูลนำเข้า load_datasetds = load_dataset("q-future/Q-Bench2-HF")print(ds["dev"][0])### {'id': 0,### 'image1': <PIL .Image.Image โหมดภาพ=ขนาด RGB=4032x3024>,### 'image2': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=864x1152>,### 'question': 'เมื่อเทียบกับภาพแรก ความคมชัดของภาพที่สองเป็นอย่างไรบ้าง',### 'option0': 'เบลอมากขึ้น',### 'option1': ' ชัดเจนกว่า',### 'option2': 'ประมาณเดียวกัน',### 'option3': 'N/A',### 'question_type': 2,### 'question_concern': 0,### 'correct_choice': 'B'}[8/8/2024] ส่วนงานเปรียบเทียบการมองเห็นระดับต่ำของ Q-bench+(หรือที่เรียกว่า Q-Bench2) เพิ่งได้รับการยอมรับจาก TPAMI! มาทดสอบ MLLM ของคุณด้วย Q-bench+_Dataset
[1/08/2024] Q-Bench เปิดตัวบน VLMEvalKit มาทดสอบ LMM ของคุณด้วยคำสั่งเดียวเช่น `python run.py --data Q-Bench1_VAL Q-Bench1_TEST --model InternVL2-1B --verbose'
[2024/6/17] Q-Bench , Q-Bench2 (Q-bench+) และ A-Bench ได้เข้าร่วม lmms-eval แล้ว ซึ่งทำให้ทดสอบ LMM ได้ง่ายขึ้น !!
[3/6/2024] repo Github สำหรับ A-Bench ออนไลน์อยู่ คุณต้องการทราบว่า LMM ของคุณเชี่ยวชาญในการประเมินรูปภาพที่สร้างโดย AI หรือไม่? มาทดสอบ A-Bench กันเถอะ !!
[3/1] เรากำลังเผยแพร่ Co-instruct สู่การเปรียบเทียบคุณภาพภาพแบบปลายเปิด ที่นี่ รายละเอียดเพิ่มเติมจะมาเร็ว ๆ นี้
[2/27] งานของเรา Q-Insturct ได้รับการยอมรับจาก CVPR 2024 พยายามเรียนรู้รายละเอียดเกี่ยวกับวิธีการสอน MLLM เกี่ยวกับการมองเห็นระดับต่ำ!
[2/23] ส่วนงานเปรียบเทียบการมองเห็นระดับต่ำของ Q-bench+ เปิดตัวแล้วที่ Q-bench+(ชุดข้อมูล)!
[2/10] เรากำลังเปิดตัว Q-bench+ แบบขยาย ซึ่งท้าทาย MLLM ด้วยทั้งภาพเดี่ยวและ คู่ภาพ ในการมองเห็นระดับต่ำ บอร์ดผู้นำอยู่ในสถานที่ ตรวจสอบความสามารถในการมองเห็นระดับต่ำสำหรับ MLLM ที่คุณชื่นชอบ!! รายละเอียดเพิ่มเติมในเร็ว ๆ นี้
[1/16] งานของเรา "Q-Bench: เกณฑ์มาตรฐานสำหรับแบบจำลองพื้นฐานวัตถุประสงค์ทั่วไปเกี่ยวกับการมองเห็นระดับต่ำ" ได้รับการยอมรับจาก ICLR2024 ให้เป็นการนำเสนอแบบสปอตไลท์

เราทดสอบโมเดล API แบบโคลสซอร์สสามโมเดล ได้แก่ GPT-4V-Turbo ( gpt-4-vision-preview แทนที่ผลลัพธ์ GPT-4V เวอร์ชันเก่า ที่ไม่มีอีกต่อไป), Gemini Pro ( gemini-pro-vision ) และ Qwen -VL-พลัส ( qwen-vl-plus ) ได้รับการปรับปรุงเล็กน้อยเมื่อเทียบกับเวอร์ชันเก่า GPT-4V ยังคงเหนือกว่าในบรรดา MLLM ทั้งหมดและเกือบจะเป็นประสิทธิภาพของมนุษย์ระดับจูเนียร์ Gemini Pro และ Qwen-VL-Plus ตามหลัง แต่ก็ยังดีกว่า MLLM แบบโอเพ่นซอร์สที่ดีที่สุด (โดยรวม 0.65)
อัปเดตเมื่อ [2024/7/18] เรายินดีที่จะเปิดตัวประสิทธิภาพ SOTA ใหม่ของ BlueImage-GPT (close-source)
การรับรู้ A1-เดี่ยว
| ชื่อผู้เข้าร่วม | ใช่หรือไม่ใช่ | อะไร | ยังไง | การบิดเบือน | คนอื่น | การบิดเบือนในบริบท | อื่นๆ ในบริบท | โดยรวม |
|---|---|---|---|---|---|---|---|---|
คิวเวน-VL-พลัส ( qwen-vl-plus ) | 0.7574 | 0.7325 | 0.5733 | 0.6488 | 0.7324 | 0.6867 | 0.7056 | 0.6893 |
BlueImage-GPT ( from VIVO New Champion ) | 0.8467 | 0.8351 | 0.7469 | 0.7819 | 0.8594 | 0.7995 | 0.8240 | 0.8107 |
Gemini-Pro ( gemini-pro-vision ) | 0.7221 | 0.7300 | 0.6645 | 0.6530 | 0.7291 | 0.7082 | 0.7665 | 0.7058 |
GPT-4V-Turbo ( gpt-4-vision-preview ) | 0.7722 | 0.7839 | 0.6645 | 0.7101 | 0.7107 | 0.7936 | 0.7891 | 0.7410 |
| GPT-4V ( เวอร์ชั่นเก่า ) | 0.7792 | 0.7918 | 0.6268 | 0.7058 | 0.7303 | 0.7466 | 0.7795 | 0.7336 |
| มนุษย์-1-จูเนียร์ | 0.8248 | 0.7939 | 0.6029 | 0.7562 | 0.7208 | 0.7637 | 0.7300 | 0.7431 |
| มนุษย์-2-อาวุโส | 0.8431 | 0.8894 | 0.7202 | 0.7965 | 0.7947 | 0.8390 | 0.8707 | 0.8174 |
การรับรู้ A1-Pair
| ชื่อผู้เข้าร่วม | ใช่หรือไม่ใช่ | อะไร | ยังไง | การบิดเบือน | คนอื่น | เปรียบเทียบ | ข้อต่อ | โดยรวม |
|---|---|---|---|---|---|---|---|---|
คิวเวน-VL-พลัส ( qwen-vl-plus ) | 0.6685 | 0.5579 | 0.5991 | 0.6246 | 0.5877 | 0.6217 | 0.5920 | 0.6148 |
คิวเวน-VL-แม็กซ์ ( qwen-vl-max ) | 0.6765 | 0.6756 | 0.6535 | 0.6909 | 0.6118 | 0.6865 | 0.6129 | 0.6699 |
BlueImage-GPT ( from VIVO New Champion ) | 0.8843 | 0.8033 | 0.7958 | 0.8464 | 0.8062 | 0.8462 | 0.7955 | 0.8348 |
Gemini-Pro ( gemini-pro-vision ) | 0.6578 | 0.5661 | 0.5674 | 0.6042 | 0.6055 | 0.6046 | 0.6044 | 0.6046 |
GPT-4V ( gpt-4-vision ) | 0.7975 | 0.6949 | 0.8442 | 0.7732 | 0.7993 | 0.8100 | 0.6800 | 0.7807 |
| มนุษย์ระดับจูเนียร์ | 0.7811 | 0.7704 | 0.8233 | 0.7817 | 0.7722 | 0.8026 | 0.7639 | 0.8012 |
| มนุษย์ระดับสูง | 0.8300 | 0.8481 | 0.8985 | 0.8313 | 0.9078 | 0.8655 | 0.8225 | 0.8548 |
นอกจากนี้ เรายังได้ประเมินโมเดลโอเพ่นซอร์สใหม่หลายโมเดลเมื่อเร็วๆ นี้ และจะเผยแพร่ผลลัพธ์เร็วๆ นี้
ขณะนี้เรามีสองวิธีในการดาวน์โหลดชุดข้อมูล (LLVisionQA&LLDescribe)
ผ่าน GitHub Release: โปรดดูรายละเอียดการเปิดตัวของเรา
ผ่านชุดข้อมูล Huggingface: โปรดดูบันทึกการเผยแพร่ข้อมูลเพื่อดาวน์โหลดภาพ
ขอแนะนำอย่างยิ่งให้แปลงโมเดลของคุณเป็นรูปแบบ Huggingface เพื่อทดสอบข้อมูลเหล่านี้ได้อย่างราบรื่น ดูสคริปต์ตัวอย่างสำหรับ IDEFICS-9B-Instruct ของ Huggingface เป็นตัวอย่าง และแก้ไขสคริปต์สำหรับโมเดลที่คุณกำหนดเองเพื่อทดสอบกับโมเดลของคุณ
กรุณาส่งอีเมลไป [email protected] เพื่อส่งผลการเรียนของคุณในรูปแบบ json
คุณยังสามารถส่งโมเดลของคุณ (อาจเป็น Huggingface AutoModel หรือ ModelScope AutoModel) มาให้เรา ควบคู่ไปกับสคริปต์การประเมินผลที่คุณกำหนดเอง สคริปต์แบบกำหนดเองของคุณสามารถแก้ไขได้จากสคริปต์เทมเพลตที่ใช้ได้กับ LLaVA-v1.5 (สำหรับ A1/A2) และที่นี่ (สำหรับการประเมินคุณภาพของภาพ)
กรุณาส่งอีเมลไป [email protected] เพื่อส่งแบบจำลองของคุณ หากคุณอยู่ นอก จีนแผ่นดินใหญ่ กรุณาส่งอีเมลไป [email protected] เพื่อส่งแบบจำลองของคุณ หากคุณอยู่ ใน จีนแผ่นดินใหญ่
สแน็ปช็อตสำหรับชุดข้อมูลการวัดประสิทธิภาพ LLVisionQA สำหรับความสามารถในการรับรู้ MLLM ระดับต่ำมีดังต่อไปนี้ ดูกระดานผู้นำที่นี่
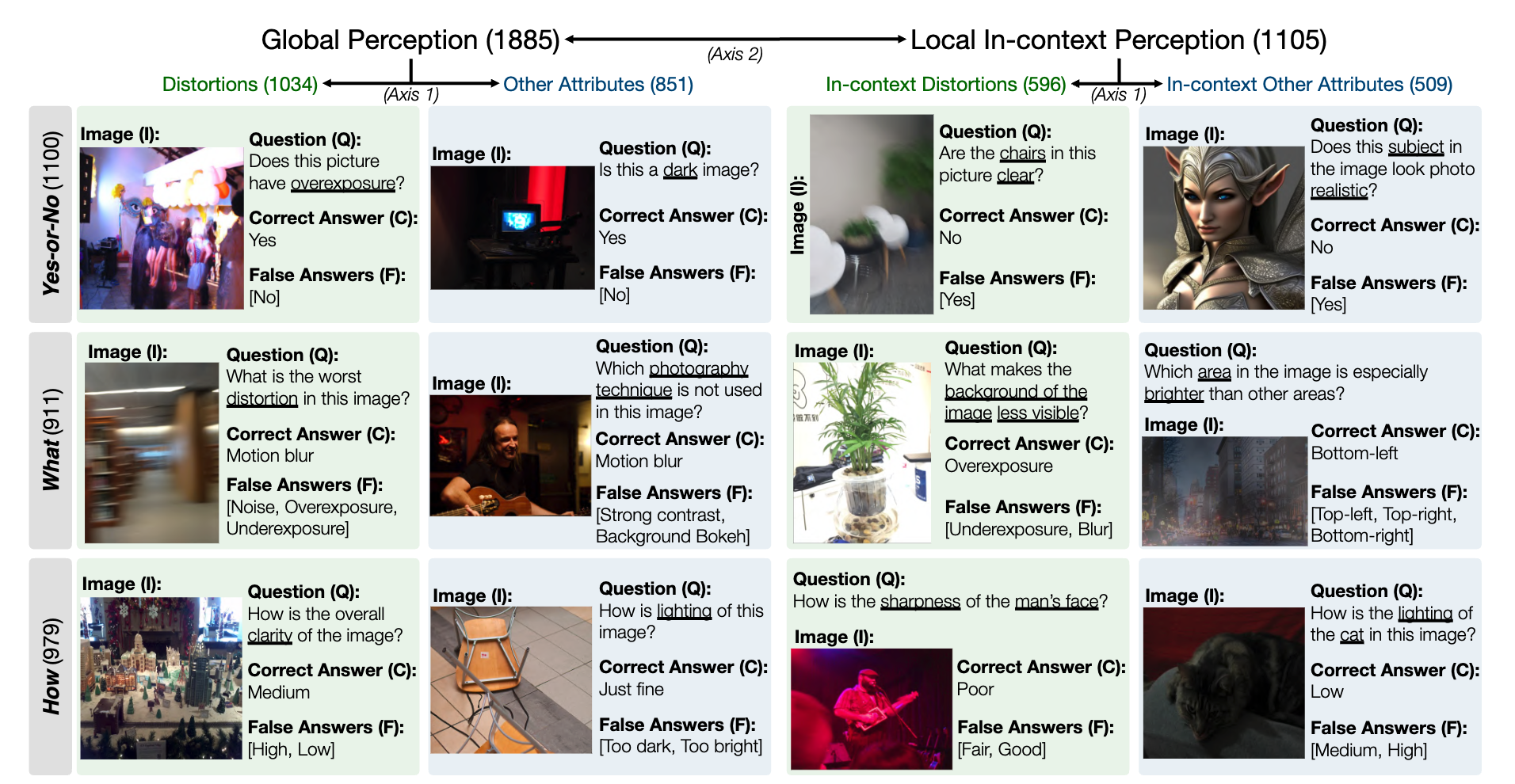
เราวัดความแม่นยำของคำตอบของ MLLM (มาพร้อมกับคำถามและตัวเลือกทั้งหมด) เป็นตัวชี้วัดที่นี่
สแน็ปช็อตสำหรับชุดข้อมูลเบนช์มาร์ก LLDescribe สำหรับความสามารถในการอธิบายระดับต่ำของ MLLM มีดังต่อไปนี้ ดูกระดานผู้นำที่นี่

เราวัด ความสมบูรณ์ ความแม่นยำ และ ความเกี่ยวข้อง ของคำอธิบาย MLLM เป็นตัวชี้วัดที่นี่
ความสามารถที่น่าตื่นเต้นที่ MLLM สามารถทำนายคะแนนเชิงปริมาณสำหรับ IQA ได้!
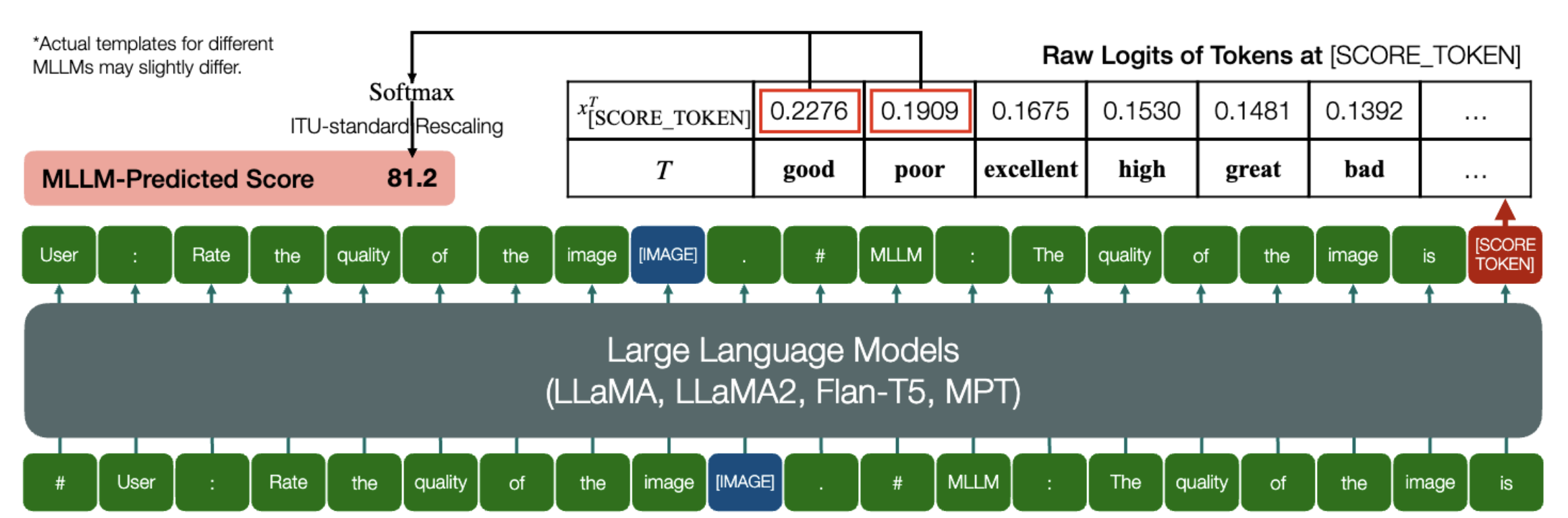
ในทำนองเดียวกันข้างต้น ตราบใดที่โมเดล (ขึ้นอยู่กับโมเดลภาษาเชิงสาเหตุ) มีสองวิธีต่อไปนี้: embed_image_and_text (เพื่ออนุญาตอินพุตหลายรูปแบบ) และ forward (สำหรับบันทึกการคำนวณ) การประเมินคุณภาพของรูปภาพ (IQA) ด้วยโมเดล สามารถทำได้ดังนี้:
จาก PIL นำเข้า Imagefrom my_mllm_model นำเข้า Model, Tokenizer, embed_image_and_textmodel, tokenizer = Model(), Tokenizer()prompt = "##User: ให้คะแนนคุณภาพของ image.n"
"##Assistant: คุณภาพของรูปภาพคือ" ### บรรทัดนี้สามารถแก้ไขได้ตามพฤติกรรมเริ่มต้นของ MLLM.good_idx, Poor_idx = tokenizer(["good",poor"]).tolist()image = Image open("image_for_iqa.jpg")input_embeds = embed_image_and_text(รูปภาพ, พรอมต์)output_logits = model(input_embeds=input_embeds).logits[0,-1]q_pred = (output_logits[[good_idx, Poor_idx]] / 100).softmax(0)[0]*โปรดทราบว่าคุณสามารถแก้ไขบรรทัดที่สองตามรูปแบบเริ่มต้นของโมเดลของคุณ ได้ เช่น สำหรับ Shikra นั้น "##Assistant: The quality of the image is" จะถูกแก้ไขเป็น "##Assistant: The answer is" ไม่เป็นไรหาก MLLM ของคุณจะตอบว่า "ตกลง ฉันอยากช่วย! คุณภาพของภาพคือ" ก่อน เพียงแทนที่สิ่งนี้ลงในบรรทัดที่ 2 ของพรอมต์
นอกจากนี้เรายังจัดให้มีการนำ IDEFICs ไปใช้กับ IQA อย่างเต็มรูปแบบอีกด้วย ดูตัวอย่างวิธีรัน IQA ด้วย MLLM นี้ MLLM อื่นๆ สามารถแก้ไขได้ในลักษณะเดียวกันเพื่อใช้ใน IQA
เราได้เตรียมคะแนนความคิดเห็นของมนุษย์ (MOS) ในรูปแบบ JSON สำหรับฐานข้อมูล IQA ทั้งเจ็ดตามที่ได้รับการประเมินในเกณฑ์มาตรฐานของเรา
โปรดดูฐานข้อมูล IQA_databases สำหรับรายละเอียด
ย้ายไปที่กระดานผู้นำ กรุณาคลิกเพื่อดูรายละเอียด
โปรดติดต่อผู้เขียนคนแรกของบทความนี้เพื่อสอบถาม
หวู่หนิง [email protected] , @teowu
จือเฉิง จาง, [email protected] , @zzc-1998
เอ้อลี่ จาง, [email protected] , @ZhangErliCarl
หากคุณพบว่างานของเราน่าสนใจ โปรดอ้างอิงบทความของเรา:
@inproceedings{wu2024qbench,author = {Wu, Haoning และ Zhang, Zicheng และ Zhang, Erli และ Chen, Chaofeng และ Liao, Liang และ Wang, Annan และ Li, Chunyi และ Sun, Wenxiu และ Yan, Qiong และ Zhai, Guangtao และ Lin, Weisi},title = {Q-Bench: เกณฑ์มาตรฐานสำหรับแบบจำลองพื้นฐานสำหรับวัตถุประสงค์ทั่วไปในการมองเห็นระดับต่ำ},booktitle = {ICLR},ปี = {2024}} 

