LLM PuzzleTest
1.0.0
PuzzleVQA ชุดข้อมูลใหม่ของเราเผยให้เห็นความท้าทายร้ายแรงของ LLM หลายรูปแบบในการทำความเข้าใจรูปแบบนามธรรมที่เรียบง่าย กระดาษ | เว็บไซต์
เรากำลังเปิดตัว AlgoPuzzleVQA ซึ่งเป็นชุดข้อมูลที่แปลกใหม่และท้าทายสำหรับการให้เหตุผลหลายรูปแบบ! เร็วๆ นี้ เราจะปล่อยชุดข้อมูลปริศนาต่อเนื่องหลายรูปแบบเพิ่มเติม คอยติดตาม! กระดาษ | เว็บไซต์
เรารู้สึกตื่นเต้นที่จะประกาศการเปิดตัวชุดข้อมูล VQA ใหม่สองชุดที่มีศูนย์กลางอยู่ที่ปริศนา:
ประสิทธิภาพของ MLLM บนชุดข้อมูลทั้งสองยังบกพร่องอย่างเห็นได้ชัด โดยเน้นย้ำถึงความจำเป็นเร่งด่วนในการปรับปรุงอย่างมากในความสามารถในการให้เหตุผลแบบหลายรูปแบบ
โมเดลหลายรูปแบบขนาดใหญ่ขยายขีดความสามารถที่น่าประทับใจของโมเดลภาษาขนาดใหญ่โดยการบูรณาการความสามารถในการทำความเข้าใจหลายรูปแบบ อย่างไรก็ตาม ยังไม่ชัดเจนว่าพวกเขาสามารถเลียนแบบสติปัญญาทั่วไปและความสามารถในการใช้เหตุผลของมนุษย์ได้อย่างไร เนื่องจากการจดจำรูปแบบและแนวคิดที่เป็นนามธรรมเป็นกุญแจสำคัญของความฉลาดทั่วไป เราจึงขอแนะนำ PuzzleVQA ซึ่งเป็นคอลเลกชันปริศนาที่มีพื้นฐานมาจากรูปแบบนามธรรม ด้วยชุดข้อมูลนี้ เราจะประเมินแบบจำลองหลายรูปแบบขนาดใหญ่ที่มีรูปแบบนามธรรมตามแนวคิดพื้นฐาน รวมถึงสี ตัวเลข ขนาด และรูปร่าง จากการทดลองของเรากับแบบจำลองหลายรูปแบบขนาดใหญ่ที่ล้ำสมัย เราพบว่าแบบจำลองเหล่านี้ไม่สามารถสรุปรูปแบบนามธรรมง่ายๆ ได้ดีนัก เป็นที่น่าสังเกตว่าแม้แต่ GPT-4V ก็ไม่สามารถไขปริศนาได้มากกว่าครึ่งหนึ่ง เพื่อวินิจฉัยความท้าทายในการใช้เหตุผลในแบบจำลองหลายรูปแบบขนาดใหญ่ เราจะแนะนำแบบจำลองต่างๆ อย่างต่อเนื่องด้วยคำอธิบายการให้เหตุผลตามความจริงภาคพื้นดินสำหรับการรับรู้ทางสายตา การใช้เหตุผลเชิงอุปนัย และการใช้เหตุผลแบบนิรนัย การวิเคราะห์อย่างเป็นระบบของเราพบว่าปัญหาคอขวดหลักของ GPT-4V คือการรับรู้ทางสายตาที่อ่อนแอกว่าและความสามารถในการให้เหตุผลเชิงอุปนัย จากงานนี้ เราหวังว่าจะให้ความกระจ่างเกี่ยวกับข้อจำกัดของแบบจำลองหลายรูปแบบขนาดใหญ่ และวิธีที่แบบจำลองเหล่านั้นสามารถจำลองกระบวนการรับรู้ของมนุษย์ได้ดีขึ้นในอนาคต
PuzzleVQA มีให้เล่นแล้วที่นี่และบน Huggingface
รูปด้านล่างแสดงคำถามตัวอย่างที่เกี่ยวข้องกับแนวคิดเรื่องสีใน PuzzleVQA และคำตอบที่ไม่ถูกต้องจาก GPT-4V โดยทั่วไปมีสามขั้นตอนที่สามารถสังเกตได้ในกระบวนการแก้ปัญหา: การรับรู้ด้วยสายตา (สีน้ำเงิน), การใช้เหตุผลเชิงอุปนัย (สีเขียว) และการให้เหตุผลแบบนิรนัย (สีแดง) ในกรณีนี้ การรับรู้ทางสายตาไม่สมบูรณ์ ทำให้เกิดข้อผิดพลาดในระหว่างการให้เหตุผลแบบนิรนัย

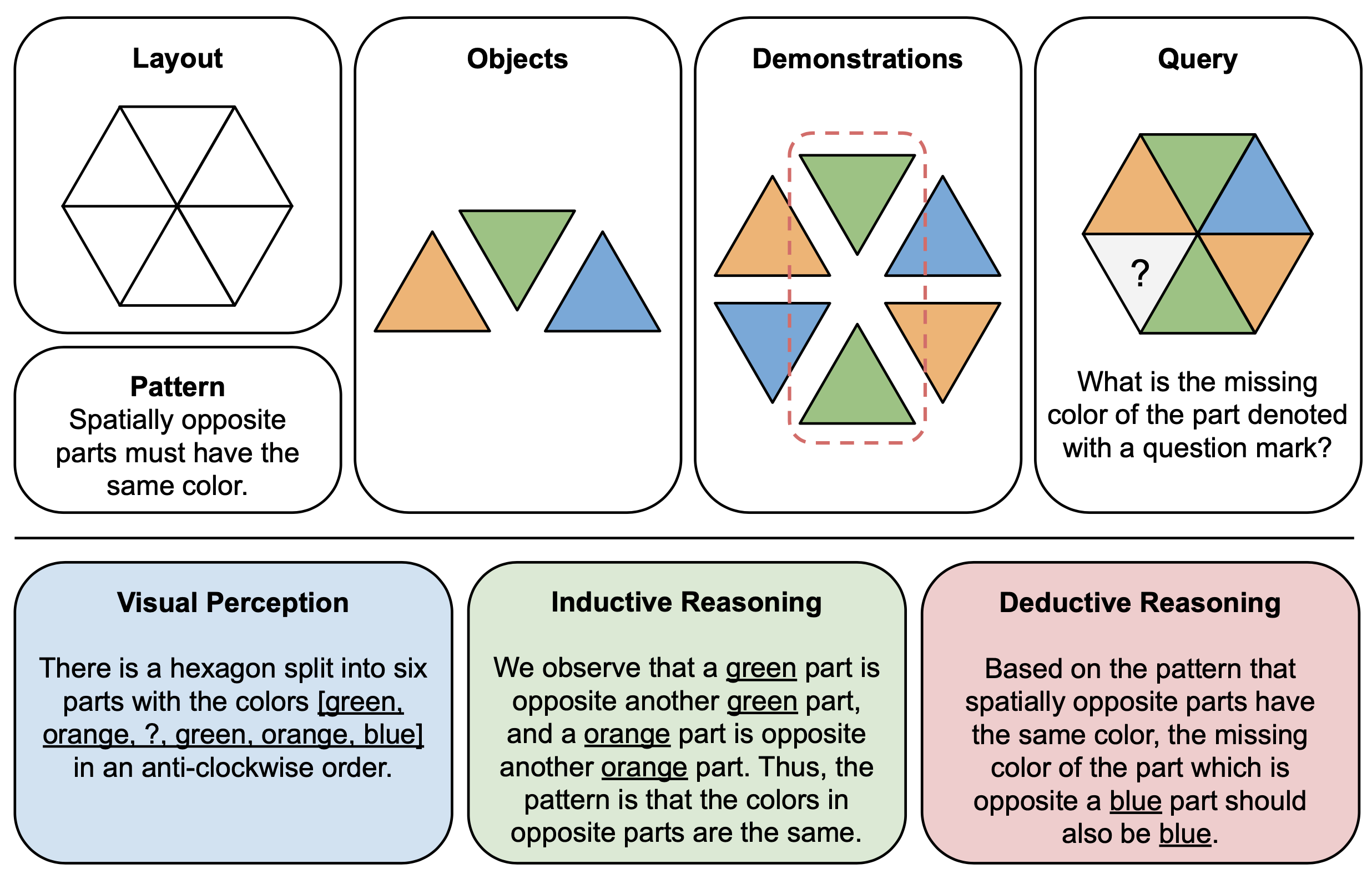
รูปด้านล่างแสดงตัวอย่างภาพประกอบของส่วนประกอบ (บน) และคำอธิบายเหตุผล (ล่าง) สำหรับปริศนาเชิงนามธรรมใน PuzzleVQA ในการสร้างแต่ละตัวอย่างปริศนา ขั้นแรกเราจะกำหนดเค้าโครงและรูปแบบของเทมเพลตหลายรูปแบบ และเติมเทมเพลตด้วยวัตถุที่เหมาะสมซึ่งแสดงให้เห็นรูปแบบที่ซ่อนอยู่ สำหรับการตีความได้ เรายังสร้างคำอธิบายการใช้เหตุผลตามความเป็นจริงเพื่อตีความปริศนาและอธิบายขั้นตอนการแก้ปัญหาทั่วไป
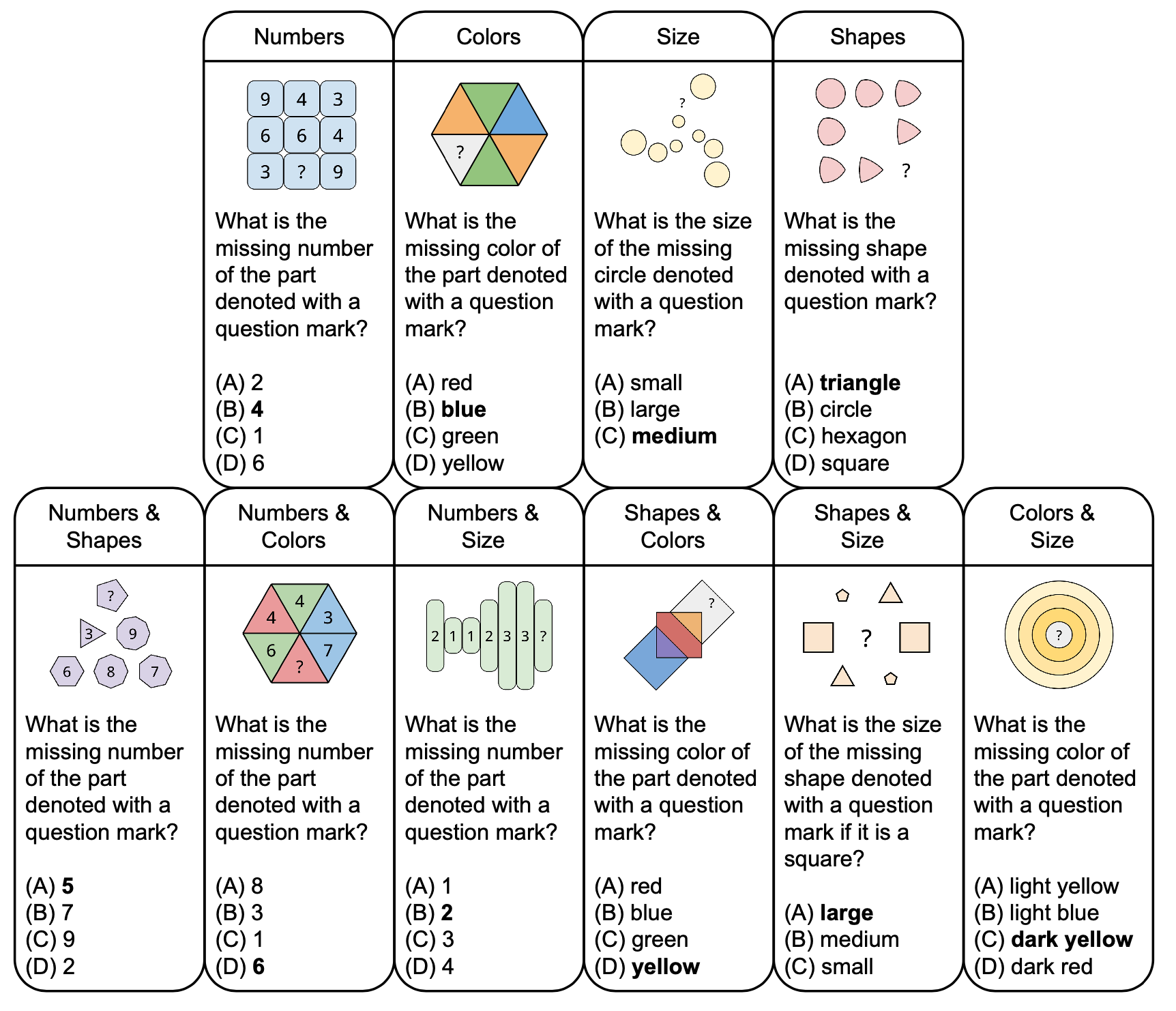
รูปด้านล่างแสดงอนุกรมวิธานของปริศนาเชิงนามธรรมใน PuzzleVQA พร้อมคำถามตัวอย่าง โดยอิงตามแนวคิดพื้นฐาน เช่น สีและขนาด เพื่อเพิ่มความหลากหลาย เราได้ออกแบบปริศนาทั้งแบบแนวคิดเดียวและสองแนวคิด
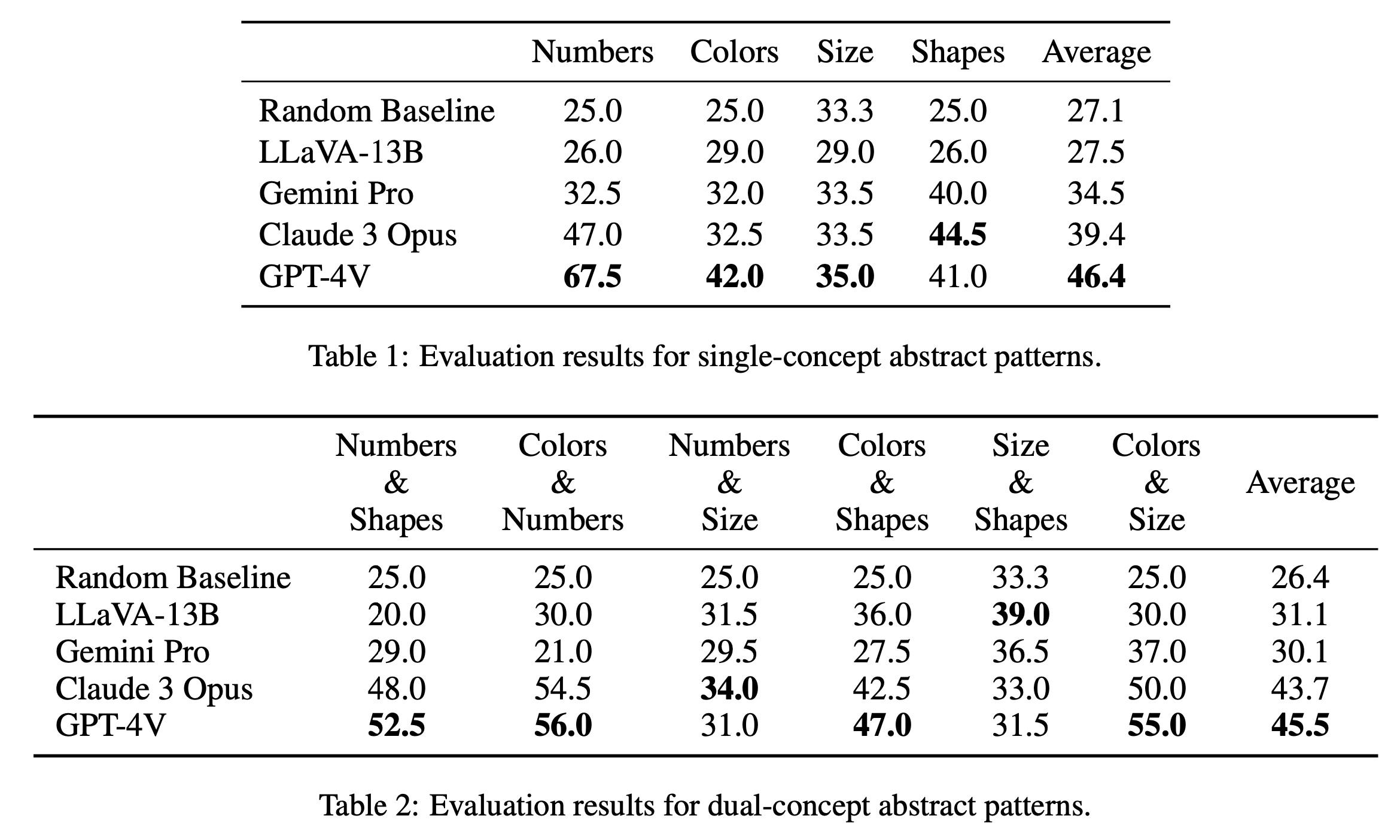
เรารายงานผลการประเมินหลักเกี่ยวกับปริศนาแนวคิดเดียวและสองแนวคิดในตารางที่ 1 และตารางที่ 2 ตามลำดับ ผลการประเมินสำหรับปริศนาแนวคิดเดียว ดังแสดงในตารางที่ 1 เผยให้เห็นความแตกต่างที่โดดเด่นในด้านประสิทธิภาพระหว่างโมเดลโอเพ่นซอร์สและโอเพ่นซอร์ส GPT-4V โดดเด่นด้วยคะแนนเฉลี่ยสูงสุดที่ 46.4 ซึ่งแสดงให้เห็นถึงการใช้เหตุผลรูปแบบนามธรรมที่เหนือกว่าสำหรับปริศนาที่มีแนวคิดเดียว เช่น ตัวเลข สี และขนาด โดยเฉพาะอย่างยิ่งในหมวดหมู่ "ตัวเลข" ด้วยคะแนน 67.5 ซึ่งเหนือกว่ารุ่นอื่นๆ มาก ซึ่งอาจเนื่องมาจากความได้เปรียบในงานการให้เหตุผลทางคณิตศาสตร์ (Yang et al., 2023) Claude 3 Opus ตามมาด้วยคะแนนเฉลี่ยโดยรวม 39.4 แสดงให้เห็นความแข็งแกร่งในหมวด "รูปร่าง" ด้วยคะแนนสูงสุด 44.5 รุ่นอื่นๆ รวมถึง Gemini Pro และ LLaVA-13B ตามหลังด้วยค่าเฉลี่ย 34.5 และ 27.5 ตามลำดับ ซึ่งมีประสิทธิภาพใกล้เคียงกับเกณฑ์พื้นฐานแบบสุ่มในหลายประเภท
ในการประเมินปริศนาสองแนวคิด ดังแสดงในตารางที่ 2 GPT-4V มีความโดดเด่นอีกครั้งด้วยคะแนนเฉลี่ยสูงสุดที่ 45.5 โดยมีประสิทธิภาพดีเป็นพิเศษในหมวดหมู่ต่างๆ เช่น "สีและตัวเลข" และ "สีและขนาด" ด้วยคะแนน 56.0 และ 55.0 ตามลำดับ Claude 3 Opus ตามมาติดๆ ด้วยคะแนนเฉลี่ย 43.7 แสดงให้เห็นผลงานที่แข็งแกร่งใน " Numbers & Size" ด้วยคะแนนสูงสุดที่ 34.0 สิ่งที่น่าสนใจคือ LLaVA-13B แม้จะมีค่าเฉลี่ยโดยรวมต่ำกว่าที่ 31.1 แต่ก็ได้คะแนนสูงสุดในหมวด "ขนาดและรูปร่าง" ที่ 39.0 ในทางกลับกัน Gemini Pro มีประสิทธิภาพที่สมดุลมากกว่าในหมวดหมู่ต่างๆ แต่มีค่าเฉลี่ยโดยรวมที่ต่ำกว่าเล็กน้อยที่ 30.1 โดยรวมแล้ว เราพบว่าแบบจำลองมีประสิทธิภาพโดยเฉลี่ยที่คล้ายคลึงกันสำหรับรูปแบบแนวคิดเดียวและสองแนวคิด ซึ่งแสดงให้เห็นว่าโมเดลเหล่านี้สามารถเชื่อมโยงแนวคิดหลายอย่าง เช่น สีและตัวเลขเข้าด้วยกันได้
@misc{chia2024puzzlevqa,
title={PuzzleVQA: Diagnosing Multimodal Reasoning Challenges of Language Models with Abstract Visual Patterns},
author={Yew Ken Chia and Vernon Toh Yan Han and Deepanway Ghosal and Lidong Bing and Soujanya Poria},
year={2024},
eprint={2403.13315},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
เราขอแนะนำภารกิจใหม่ของการไขปริศนาต่อเนื่องหลายรูปแบบ โดยมีกรอบบริบทของการตอบคำถามด้วยภาพ เรานำเสนอชุดข้อมูลใหม่ AlgoPuzzleVQA ที่ออกแบบมาเพื่อท้าทายและประเมินความสามารถของโมเดลภาษาหลายรูปแบบในการแก้ปริศนาอัลกอริทึมที่จำเป็นต้องมีทั้งความเข้าใจด้วยภาพ ความเข้าใจภาษา และการใช้เหตุผลอัลกอริทึมที่ซับซ้อน เราสร้างปริศนาเพื่อรวบรวมหัวข้อทางคณิตศาสตร์และอัลกอริทึมที่หลากหลาย เช่น ตรรกะบูลีน การรวมกัน ทฤษฎีกราฟ การเพิ่มประสิทธิภาพ การค้นหา ฯลฯ โดยมีจุดมุ่งหมายเพื่อประเมินช่องว่างระหว่างการตีความข้อมูลด้วยภาพและทักษะการแก้ปัญหาด้วยอัลกอริทึม ชุดข้อมูลถูกสร้างขึ้นโดยอัตโนมัติจากโค้ดที่เขียนโดยมนุษย์ ปริศนาทั้งหมดของเรามีคำตอบที่แน่นอนซึ่งสามารถพบได้จากอัลกอริธึมโดยไม่ต้องคำนวณโดยมนุษย์ที่น่าเบื่อ ช่วยให้มั่นใจได้ว่าชุดข้อมูลของเราสามารถขยายขนาดได้ตามใจชอบในแง่ของความซับซ้อนของเหตุผลและขนาดชุดข้อมูล การตรวจสอบของเราเผยให้เห็นว่าโมเดลภาษาขนาดใหญ่ (LLM) เช่น GPT4V และ Gemini มีประสิทธิภาพที่จำกัดในงานไขปริศนา เราพบว่าประสิทธิภาพของพวกเขาแทบจะสุ่มเสี่ยงในการตั้งค่าการตอบคำถามแบบหลายตัวเลือกสำหรับปริศนาจำนวนมาก การค้นพบนี้เน้นย้ำถึงความท้าทายในการบูรณาการความรู้ด้านภาพ ภาษา และอัลกอริทึม เพื่อแก้ไขปัญหาการใช้เหตุผลที่ซับซ้อน
PuzzleVQA มีให้เล่นแล้วที่นี่และบน Huggingface
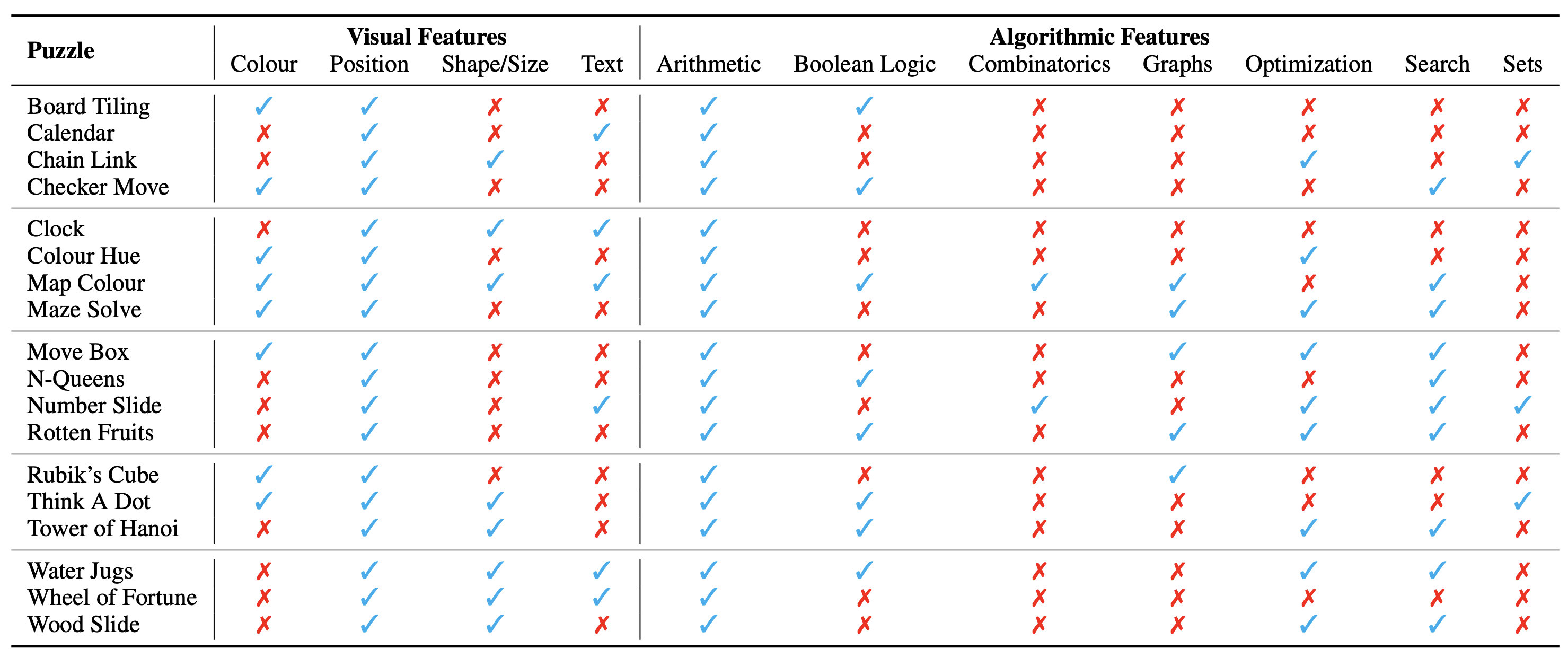
โครงร่างของปริศนา/ปัญหาจะแสดงเป็นรูปภาพ ซึ่งประกอบขึ้นเป็นบริบทที่มองเห็นได้ เราระบุลักษณะพื้นฐานต่อไปนี้ของบริบทภาพที่มีอิทธิพลต่อธรรมชาติของปริศนา:

นอกจากนี้เรายังระบุแนวคิดอัลกอริทึมที่จำเป็นสำหรับการไขปริศนา เช่น การตอบคำถามสำหรับตัวอย่างปริศนา มีดังนี้:

หมวดหมู่อัลกอริทึมไม่แยกจากกัน เนื่องจากเราจำเป็นต้องใช้สองหมวดหมู่ขึ้นไปเพื่อหาคำตอบสำหรับปริศนาส่วนใหญ่
ชุดข้อมูลมีอยู่ที่นี่ในรูปแบบเหล่านี้ เราสร้างปริศนาที่แตกต่างกันทั้งหมด 18 ปริศนาซึ่งครอบคลุมหัวข้ออัลกอริธึมและคณิตศาสตร์ต่างๆ ปริศนาเหล่านี้จำนวนมากได้รับความนิยมในสถานที่พักผ่อนหย่อนใจหรือเชิงวิชาการต่างๆ
โดยรวมแล้ว เรามี 1,800 อินสแตนซ์จาก 18 ปริศนาที่แตกต่างกัน กรณีเหล่านี้คล้ายคลึงกับ กรณีทดสอบ ต่างๆ ของปริศนา กล่าวคือ มีอินพุตที่แตกต่างกัน สถานะเริ่มต้นและเป้าหมาย ฯลฯ การแก้ปัญหากรณีทั้งหมดได้อย่างน่าเชื่อถือจะต้องค้นหาอัลกอริธึมที่แน่นอนเพื่อใช้แล้วนำไปใช้อย่างถูกต้อง ซึ่งคล้ายกับวิธีที่เราตรวจสอบความถูกต้องของโปรแกรมคอมพิวเตอร์ที่มีจุดมุ่งหมายเพื่อแก้ไขงานเฉพาะผ่านกรณีทดสอบที่หลากหลาย
ขณะนี้เราถือว่าชุดข้อมูลทั้งหมดเป็นเกณฑ์มาตรฐาน สำหรับการประเมินเท่านั้น ตัวอย่างรายละเอียดของปริศนาทั้งหมดแสดงไว้ที่นี่
คำแนะนำในการสร้างชุดข้อมูลสามารถดูได้ที่นี่ จำนวนอินสแตนซ์และความยากของปริศนาสามารถปรับขนาดได้ตามขนาดหรือระดับที่ต้องการ
การจัดหมวดหมู่ภววิทยาของปริศนามีดังนี้:
การตั้งค่าการทดลองและสคริปต์สามารถพบได้ในไดเร็กทอรี AlgoPuzzleVQA
โปรดพิจารณาอ้างอิงบทความต่อไปนี้หากคุณพบว่างานของเรามีประโยชน์:
@article { ghosal2024algopuzzlevqa ,
title = { Are Language Models Puzzle Prodigies? Algorithmic Puzzles Unveil Serious Challenges in Multimodal Reasoning } ,
author = { Ghosal, Deepanway and Han, Vernon Toh Yan and Chia, Yew Ken and and Poria, Soujanya } ,
journal = { arXiv preprint arXiv:2403.03864 } ,
year = { 2024 }
}

