lightllm
1.0.0
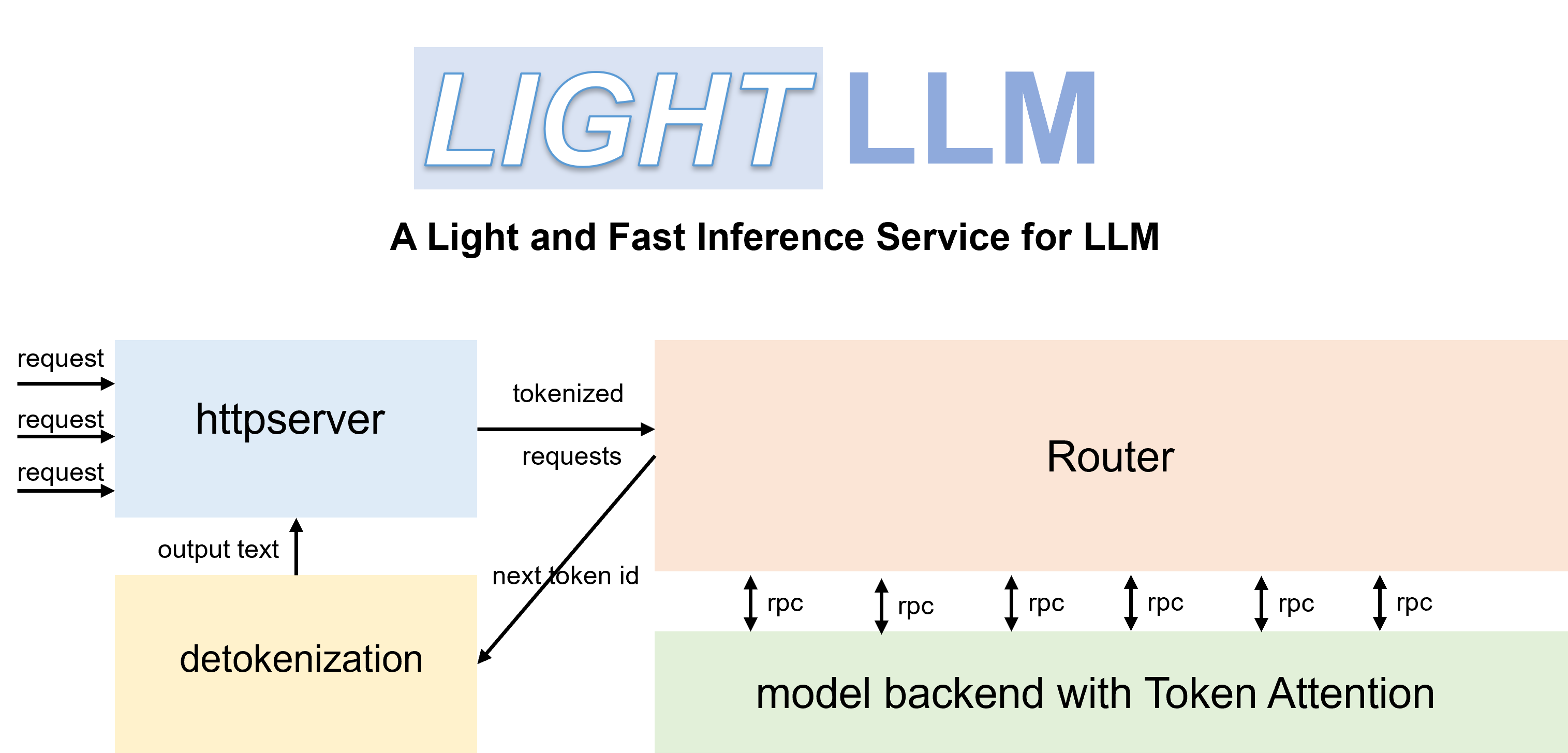
LightLLM เป็นเฟรมเวิร์กการอนุมานและการให้บริการ LLM (Large Language Model) ที่ใช้ Python โดดเด่นในด้านการออกแบบที่มีน้ำหนักเบา ความสามารถในการปรับขนาดได้ง่าย และประสิทธิภาพความเร็วสูง LightLLM ใช้ประโยชน์จากจุดแข็งของการใช้งานโอเพ่นซอร์สที่ได้รับการยอมรับเป็นอย่างดี ซึ่งรวมถึงแต่ไม่จำกัดเพียง FasterTransformer, TGI, vLLM และ FlashAttention
เอกสารภาษาอังกฤษ | 中文档
เมื่อคุณเริ่ม Qwen-7b คุณจะต้องตั้งค่าพารามิเตอร์ '--eos_id 151643 --trust_remote_code'
ChatGLM2 จำเป็นต้องตั้งค่าพารามิเตอร์ '--trust_remote_code'
InternLM จำเป็นต้องตั้งค่าพารามิเตอร์ '--trust_remote_code'
InternVL-Chat(Phi3) จำเป็นต้องตั้งค่าพารามิเตอร์ '--eos_id 32007 --trust_remote_code'
InternVL-Chat(InternLM2) จำเป็นต้องตั้งค่าพารามิเตอร์ '--eos_id 92542 --trust_remote_code'
Qwen2-VL-7b จำเป็นต้องตั้งค่าพารามิเตอร์ '--eos_id 151645 --trust_remote_code' และใช้ 'pip install git+https://github.com/huggingface/transformers' เพื่ออัปเกรดเป็นเวอร์ชันล่าสุด
Stablelm จำเป็นต้องตั้งค่าพารามิเตอร์ '--trust_remote_code'
Phi-3 รองรับเฉพาะ Mini และ Small เท่านั้น
DeepSeek-V2-Lite และ DeepSeek-V2 จำเป็นต้องตั้งค่าพารามิเตอร์ '--data_type bfloat16'
รหัสได้รับการทดสอบด้วย Pytorch>=1.3, CUDA 11.8 และ Python 3.9 หากต้องการติดตั้งการขึ้นต่อกันที่จำเป็น โปรดดู ข้อกำหนด .txt ที่ให้มา และปฏิบัติตามคำแนะนำดังกล่าว
# for cuda 11.8
pip install -r requirements.txt --extra-index-url https://download.pytorch.org/whl/cu118
# this version nccl can support torch cuda graph
pip install nvidia-nccl-cu12==2.20.5คุณสามารถใช้คอนเทนเนอร์ Docker อย่างเป็นทางการเพื่อรันโมเดลได้ง่ายขึ้น โดยทำตามขั้นตอนเหล่านี้:
ดึงคอนเทนเนอร์ออกจาก GitHub Container Registry:
docker pull ghcr.io/modeltc/lightllm:mainรันคอนเทนเนอร์ด้วยการรองรับ GPU และการแมปพอร์ต:
docker run -it --gpus all -p 8080:8080
--shm-size 1g -v your_local_path:/data/
ghcr.io/modeltc/lightllm:main /bin/bashหรือคุณสามารถสร้างคอนเทนเนอร์ด้วยตัวเอง:
docker build -t < image_name > .
docker run -it --gpus all -p 8080:8080
--shm-size 1g -v your_local_path:/data/
< image_name > /bin/bashคุณยังสามารถใช้สคริปต์ตัวช่วยเพื่อเปิดทั้งคอนเทนเนอร์และเซิร์ฟเวอร์:
python tools/quick_launch_docker.py --help หมายเหตุ: หากคุณใช้ GPU หลายตัว คุณอาจต้องเพิ่มขนาดหน่วยความจำที่ใช้ร่วมกันโดยเพิ่ม --shm-size ให้กับคำสั่ง docker run
python setup.py installรหัสได้รับการทดสอบกับ GPU หลายรุ่นรวมถึง V100, A100, A800, 4090 และ H800 หากคุณใช้โค้ดบน A100, A800 ฯลฯ เราขอแนะนำให้ใช้ triton==3.0.0
pip install triton==3.0.0 --no-depsหากคุณใช้โค้ดบน H800 หรือ V100 คุณสามารถลองใช้ไทรทันทุกคืนเพื่อให้ได้ประสิทธิภาพที่ดีขึ้น
pip install -U --index-url https://aiinfra.pkgs.visualstudio.com/PublicPackages/_packaging/Triton-Nightly/pypi/simple/ triton-nightly --no-depsด้วยเราเตอร์ที่มีประสิทธิภาพและ TokenAttention ทำให้ LightLLM สามารถปรับใช้เป็นบริการและบรรลุประสิทธิภาพการรับส่งข้อมูลที่ล้ำสมัย
เปิดตัวเซิร์ฟเวอร์:
python -m lightllm.server.api_server --model_dir /path/llama-7B
--host 0.0.0.0
--port 8080
--tp 1
--max_total_token_num 120000 พารามิเตอร์ max_total_token_num ได้รับอิทธิพลจากหน่วยความจำ GPU ของสภาพแวดล้อมการปรับใช้ คุณยังสามารถระบุ --mem_faction เพื่อให้คำนวณโดยอัตโนมัติ
python -m lightllm.server.api_server --model_dir /path/llama-7B
--host 0.0.0.0
--port 8080
--tp 1
--mem_faction 0.9ในการเริ่มต้นการสืบค้นในเชลล์:
curl http://127.0.0.1:8080/generate
-X POST
-d ' {"inputs":"What is AI?","parameters":{"max_new_tokens":17, "frequency_penalty":1}} '
-H ' Content-Type: application/json 'หากต้องการสอบถามจาก Python:
import time
import requests
import json
url = 'http://localhost:8080/generate'
headers = { 'Content-Type' : 'application/json' }
data = {
'inputs' : 'What is AI?' ,
"parameters" : {
'do_sample' : False ,
'ignore_eos' : False ,
'max_new_tokens' : 1024 ,
}
}
response = requests . post ( url , headers = headers , data = json . dumps ( data ))
if response . status_code == 200 :
print ( response . json ())
else :
print ( 'Error:' , response . status_code , response . text )python -m lightllm.server.api_server
--host 0.0.0.0
--port 8080
--tp 1
--max_total_token_num 12000
--trust_remote_code
--enable_multimodal
--cache_capacity 1000
--model_dir /path/of/Qwen-VL or /path/of/Qwen-VL-Chatpython -m lightllm.server.api_server
--host 0.0.0.0
--port 8080
--tp 1
--max_total_token_num 12000
--trust_remote_code
--enable_multimodal
--cache_capacity 1000
--model_dir /path/of/llava-v1.5-7b or /path/of/llava-v1.5-13b import time
import requests
import json
import base64
url = 'http://localhost:8080/generate'
headers = { 'Content-Type' : 'application/json' }
uri = "/local/path/of/image" # or "/http/path/of/image"
if uri . startswith ( "http" ):
images = [{ "type" : "url" , "data" : uri }]
else :
with open ( uri , 'rb' ) as fin :
b64 = base64 . b64encode ( fin . read ()). decode ( "utf-8" )
images = [{ 'type' : "base64" , "data" : b64 }]
data = {
"inputs" : "<img></img>Generate the caption in English with grounding:" ,
"parameters" : {
"max_new_tokens" : 200 ,
# The space before <|endoftext|> is important, the server will remove the first bos_token_id, but QWen tokenizer does not has bos_token_id
"stop_sequences" : [ " <|endoftext|>" ],
},
"multimodal_params" : {
"images" : images ,
}
}
response = requests . post ( url , headers = headers , data = json . dumps ( data ))
if response . status_code == 200 :
print ( response . json ())
else :
print ( 'Error:' , response . status_code , response . text ) import json
import requests
import base64
def run_once ( query , uris ):
images = []
for uri in uris :
if uri . startswith ( "http" ):
images . append ({ "type" : "url" , "data" : uri })
else :
with open ( uri , 'rb' ) as fin :
b64 = base64 . b64encode ( fin . read ()). decode ( "utf-8" )
images . append ({ 'type' : "base64" , "data" : b64 })
data = {
"inputs" : query ,
"parameters" : {
"max_new_tokens" : 200 ,
# The space before <|endoftext|> is important, the server will remove the first bos_token_id, but QWen tokenizer does not has bos_token_id
"stop_sequences" : [ " <|endoftext|>" , " <|im_start|>" , " <|im_end|>" ],
},
"multimodal_params" : {
"images" : images ,
}
}
# url = "http://127.0.0.1:8080/generate_stream"
url = "http://127.0.0.1:8080/generate"
headers = { 'Content-Type' : 'application/json' }
response = requests . post ( url , headers = headers , data = json . dumps ( data ))
if response . status_code == 200 :
print ( " + result: ({})" . format ( response . json ()))
else :
print ( ' + error: {}, {}' . format ( response . status_code , response . text ))
"""
multi-img, multi-round:
<|im_start|>system
You are a helpful assistant.<|im_end|>
<|im_start|>user
<img></img>
<img></img>
上面两张图片分别是哪两个城市?请对它们进行对比。<|im_end|>
<|im_start|>assistant
根据提供的信息,两张图片分别是重庆和北京。<|im_end|>
<|im_start|>user
这两座城市分别在什么地方?<|im_end|>
<|im_start|>assistant
"""
run_once (
uris = [
"assets/mm_tutorial/Chongqing.jpeg" ,
"assets/mm_tutorial/Beijing.jpeg" ,
],
query = "<|im_start|>system n You are a helpful assistant.<|im_end|> n <|im_start|>user n <img></img> n <img></img> n上面两张图片分别是哪两个城市?请对它们进行对比。<|im_end|> n <|im_start|>assistant n根据提供的信息,两张图片分别是重庆和北京。<|im_end|> n <|im_start|>user n这两座城市分别在什么地方?<|im_end|> n <|im_start|>assistant n "
) import time
import requests
import json
import base64
url = 'http://localhost:8080/generate'
headers = { 'Content-Type' : 'application/json' }
uri = "/local/path/of/image" # or "/http/path/of/image"
if uri . startswith ( "http" ):
images = [{ "type" : "url" , "data" : uri }]
else :
with open ( uri , 'rb' ) as fin :
b64 = base64 . b64encode ( fin . read ()). decode ( "utf-8" )
images = [{ 'type' : "base64" , "data" : b64 }]
data = {
"inputs" : "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions. USER: <image> n Please explain the picture. ASSISTANT:" ,
"parameters" : {
"max_new_tokens" : 200 ,
},
"multimodal_params" : {
"images" : images ,
}
}
response = requests . post ( url , headers = headers , data = json . dumps ( data ))
if response . status_code == 200 :
print ( response . json ())
else :
print ( 'Error:' , response . status_code , response . text )พารามิเตอร์ lanuch เพิ่มเติม:
--enable_multimodal,--cache_capacity, ใหญ่กว่า--cache_capacityต้องใช้shm-sizeที่ใหญ่กว่า
Support
--tp > 1เมื่อtp > 1โมเดลภาพจะทำงานบน gpu 0
แท็กรูปภาพพิเศษสำหรับ Qwen-VL คือ
<img></img>(<image>สำหรับ Llava) ความยาวของdata["multimodal_params"]["images"]ควรเท่ากับจำนวนแท็ก จำนวน สามารถเป็น 0, 1, 2, ...
รูปแบบภาพอินพุต: รายการสำหรับ dict เช่น
{'type': 'url'/'base64', 'data': xxx}
เราเปรียบเทียบประสิทธิภาพการบริการของ LightLLM และ vLLM==0.1.2 บน LLaMA-7B โดยใช้ A800 พร้อมหน่วยความจำ GPU 80G
ในการเริ่มต้นให้เตรียมข้อมูลดังต่อไปนี้:
wget https://huggingface.co/datasets/anon8231489123/ShareGPT_Vicuna_unfiltered/resolve/main/ShareGPT_V3_unfiltered_cleaned_split.jsonเปิดบริการ:
python -m lightllm.server.api_server --model_dir /path/llama-7b --tp 1 --max_total_token_num 121060 --tokenizer_mode autoการประเมิน:
cd test
python benchmark_serving.py --tokenizer /path/llama-7b --dataset /path/ShareGPT_V3_unfiltered_cleaned_split.json --num-prompts 2000 --request-rate 200ผลการเปรียบเทียบประสิทธิภาพแสดงไว้ด้านล่าง:
| วีแอลแอลเอ็ม | ไลท์LLM |
|---|---|
| เวลารวม: 361.79 วิ ปริมาณงาน: 5.53 คำขอ/วินาที | เวลารวม: 188.85 วิ ปริมาณงาน: 10.59 คำขอ/วินาที |
สำหรับการดีบัก เรามีสคริปต์การทดสอบประสิทธิภาพแบบคงที่สำหรับรุ่นต่างๆ ตัวอย่างเช่น คุณสามารถประเมินประสิทธิภาพการอนุมานของแบบจำลอง LLaMA ได้
cd test/model
python test_llama.pypip install protobuf==3.20.0error : PTX .version 7.4 does not support .target sm_89bash tools/resolve_ptx_version python -m lightllm.server.api_server ... หากคุณมีโครงการที่ควรรวมเข้าด้วยกัน โปรดติดต่อทางอีเมลหรือสร้างคำขอดึง
เมื่อคุณติดตั้ง lightllm และ lazyllm แล้ว คุณสามารถใช้โค้ดต่อไปนี้เพื่อสร้างแชทบอตของคุณเอง:
from lazyllm import TrainableModule , deploy , WebModule
# Model will be download automatically if you have an internet connection
m = TrainableModule ( 'internlm2-chat-7b' ). deploy_method ( deploy . lightllm )
WebModule ( m ). start (). wait ()เอกสาร: https://lazyllm.readthedocs.io/
สำหรับข้อมูลเพิ่มเติมและการสนทนา เข้าร่วมเซิร์ฟเวอร์ความไม่ลงรอยกันของเรา
พื้นที่เก็บข้อมูลนี้เผยแพร่ภายใต้ลิขสิทธิ์ Apache-2.0
เราเรียนรู้มากมายจากโครงการต่อไปนี้เมื่อพัฒนา LightLLM


