RWKV LM
v5
หน้าแรกของ RWKV: https://www.rwkv.com
RWKV-5/6 กระดาษ Eagle/Finch : https://arxiv.org/abs/2404.05892
RWKV ที่ยอดเยี่ยมในวิสัยทัศน์: https://github.com/Yaziwel/Awesome-RWKV-in-Vision
การสาธิต RWKV-6 3B: https://huggingface.co/spaces/BlinkDL/RWKV-Gradio-1
การสาธิต RWKV-6 7B: https://huggingface.co/spaces/BlinkDL/RWKV-Gradio-2
รหัสสาธิตโหมด RWKV-6 GPT (พร้อมความคิดเห็นและคำอธิบาย) : https://github.com/BlinkDL/RWKV-LM/blob/main/RWKV-v5/rwkv_v6_demo.py
การสาธิตโหมด RWKV-6 RNN: https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_v6_demo.py
สำหรับการอ้างอิง ให้ใช้ python 3.10+, torch 2.5+, cuda 12.5+, deepspeed ล่าสุด แต่ ให้ pytorch-lightning==1.9.5 ต่อไป
ฝึกฝน RWKV-6 : ใช้ /RWKV-v5/ และใช้ --my_testing "x060" ใน demo-training-prepare.sh และ demo-training-run.sh
ฝึกฝน RWKV-7 : ใช้ /RWKV-v5/ และใช้ --my_testing "x070" ใน demo-training-prepare.sh และ demo-training-run.sh
pip install torch --upgrade --extra-index-url https://download.pytorch.org/whl/cu121
pip install pytorch-lightning==1.9.5 deepspeed wandb ninja --upgrade
cd RWKV-v5/
./demo-training-prepare.sh
./demo-training-run.sh
(you may want to log in to wandb first)
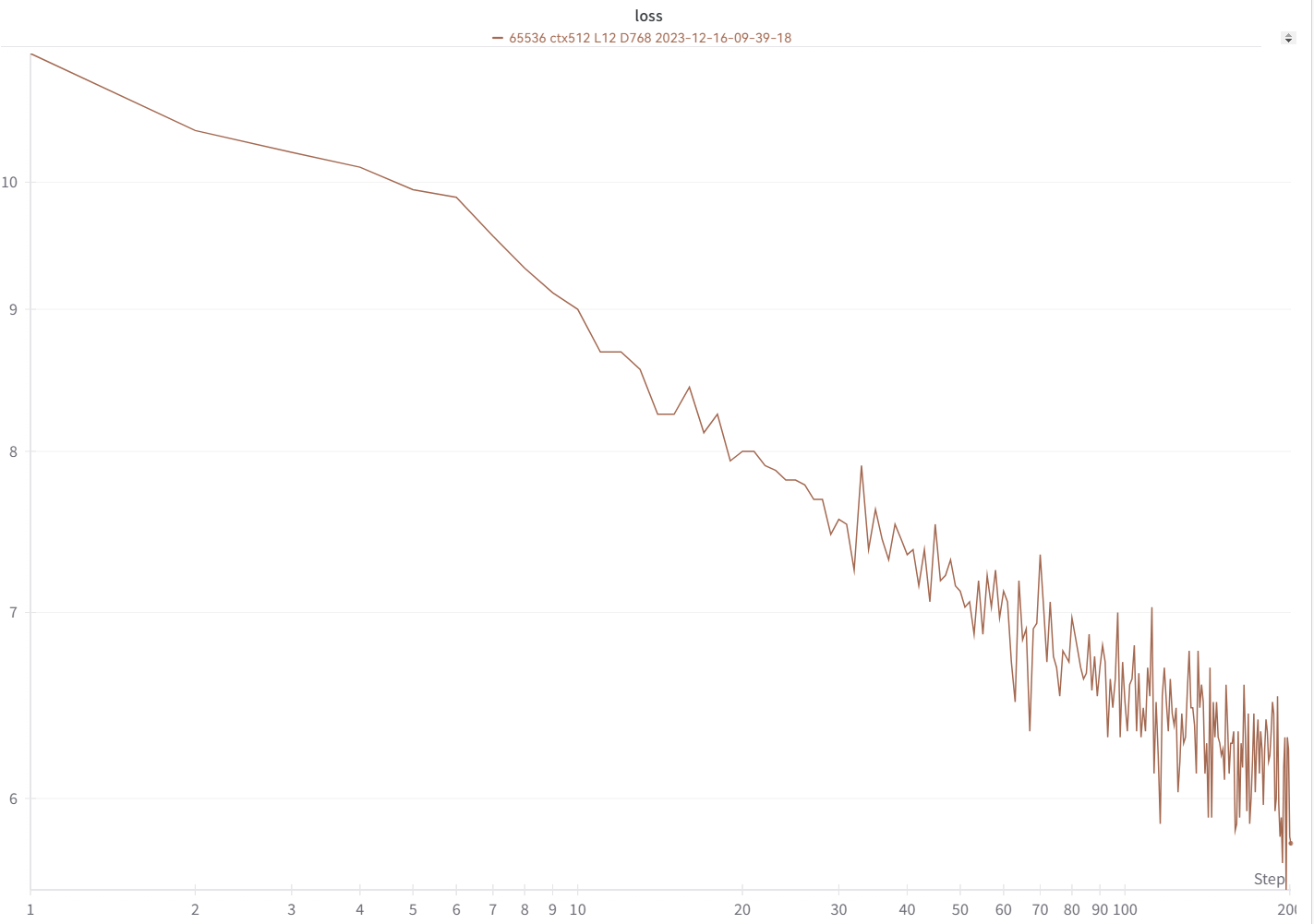
เส้นการสูญเสียของคุณควรมีลักษณะเกือบจะเหมือนกันทุกประการ โดยมีขึ้นและลงเท่ากัน (หากคุณใช้ bsz & config เดียวกัน):
คุณสามารถเรียกใช้โมเดลของคุณโดยใช้https://pypi.org/project/rwkv/ (ใช้ "rwkv_vocab_v20230424" แทน "20B_tokenizer.json")
ใช้ https://github.com/BlinkDL/RWKV-LM/blob/main/RWKV-v5/make_data.py เพื่อเตรียมข้อมูล binidx จาก jsonl และคำนวณ "--my_exit_tokens" และ "--magic_prime"
tokenizer ที่รวดเร็วกว่ามากของข้อมูลขนาดใหญ่: https://github.com/cahya-wirawan/json2bin
"ยุค" ใน train.py คือ "ยุคมินิ" (ไม่ใช่ยุคจริง เพื่อความสะดวกเท่านั้น) และโทเค็นยุคย่อย 1 อัน = 40320 * ctx_len โทเค็น
ตัวอย่างเช่น หาก binidx ของคุณมีโทเค็น 1498226207 และ ctxlen=4096 ให้ตั้งค่า "--my_exit_tokens 1498226207" (ซึ่งจะแทนที่ epoch_count) และจะเป็น 1498226207/(40320 * 4096) = 9.07 miniepochs ผู้ฝึกสอนจะออกอัตโนมัติหลังจากโทเค็น "--my_exit_tokens" ตั้งค่า "--magic_prime" เป็นไพรม์ 3n+2 ที่ใหญ่ที่สุดซึ่งเล็กกว่า datalen/ctxlen-1 (= 1498226207/4096-1 = 365776) ซึ่งก็คือ "--magic_prime 365759" ในกรณีนี้
ง่าย ๆ: เตรียม SFT jsonl => ทำซ้ำข้อมูล SFT ของคุณ 3 หรือ 4 ครั้งใน make_data.py การทำซ้ำมากขึ้นจะนำไปสู่การฟิตติ้งมากเกินไป
ขั้นสูง: ทำซ้ำข้อมูล SFT ของคุณ 3 หรือ 4 ครั้งใน jsonl ของคุณ (หมายเหตุ make_data.py จะสับเปลี่ยนรายการ jsonl ทั้งหมด) => เพิ่มข้อมูลพื้นฐานบางส่วน (เช่น slimpajama) ลงใน jsonl => และทำซ้ำเพียง 1 ครั้งใน make_data.py
แก้ไขเดือยการฝึกซ้อม : ดูส่วน "การแก้ไขเดือย RWKV-6" ในหน้านี้
การอนุมานอย่างง่ายสำหรับ RWKV-5 : https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_v5_demo.py
การอนุมานอย่างง่ายสำหรับ RWKV-6 : https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_v6_demo.py
หมายเหตุ: ใน [state = kv + w * state] ทุกอย่างจะต้องอยู่ใน fp32 เพราะ w สามารถใกล้กับ 1 ได้มาก ดังนั้นเราสามารถคง state และ w ไว้ใน fp32 และแปลง kv เป็น fp32
lm_eval: https://github.com/BlinkDL/ChatRWKV/blob/main/run_lm_eval.py
การสาธิตการแชทสำหรับนักพัฒนา: https://github.com/BlinkDL/ChatRWKV/blob/main/API_DEMO_CHAT.py
เคล็ดลับสำหรับโมเดลขนาดเล็ก/ข้อมูลขนาดเล็ก : เมื่อฉันฝึกโมเดลเพลง RWKV ฉันจะใช้มิติที่ลึกและแคบ (เช่น L29-D512) และใช้ wd และ dropout (เช่น wd=2 dropout=0.02) หมายเหตุ การออกกลางคันของ RWKV-LM นั้นมีประสิทธิภาพมาก - ใช้ 1/4 ของค่าปกติของคุณ
ใช้รูปแบบ .jsonl สำหรับข้อมูลของคุณ (ดู https://huggingface.co/BlinkDL/rwkv-5-world สำหรับรูปแบบ)
ใช้ https://github.com/BlinkDL/RWKV-LM/blob/main/RWKV-v5/make_data.py เพื่อสร้างโทเค็นโดยใช้ World tokenizer ใน binidx เหมาะสำหรับการปรับแต่งโมเดล World
เปลี่ยนชื่อจุดตรวจสอบฐานในโฟลเดอร์โมเดลของคุณเป็น rwkv-init.pth และเปลี่ยนคำสั่งการฝึกอบรมเพื่อใช้ --n_layer 32 --n_embd 4096 --vocab_size 65536 --lr_init 1e-5 --lr_final 1e-5 สำหรับ 7B
0.1B = --n_layer 12 --n_embd 768 // 0.4B = --n_layer 24 --n_embd 1024 // 1.5B = --n_layer 24 --n_embd 2048 // 3B = --n_layer 32 --n_embd 2560 / / 7B = --n_layer 32 --n_embd 4096
การใช้งานที่ไม่ได้รับการเพิ่มประสิทธิภาพในปัจจุบัน ใช้ vram เดียวกันกับ SFT เต็มรูปแบบ
--train_type "states" --load_partial 1 --lr_init 1 --lr_final 0.01 --warmup_steps 10 (yes, use very high LR)
ใช้ rwkv 0.8.26+ เพื่อโหลด "time_state" ที่ผ่านการฝึกอบรมโดยอัตโนมัติ
เมื่อคุณฝึก RWKV ตั้งแต่เริ่มต้น ให้ลองเริ่มต้นของฉันเพื่อประสิทธิภาพที่ดีที่สุด ตรวจสอบ Generate_init_weight() ของ src/model.py:
emb.weight => nn.init.uniform_(a=-1e-4, b=1e-4)
(Note ln0 of block0 is the layernorm for emb.weight)
head.weight => nn.init.orthogonal_(gain=0.5*sqrt(n_vocab / n_embd))
att.receptance.weight => nn.init.orthogonal_(gain=1)
att.key.weight => nn.init.orthogonal_(gain=0.1)
att.value.weight => nn.init.orthogonal_(gain=1)
att.gate.weight => nn.init.orthogonal_(gain=0.1)
att.output.weight => zero
att.ln_x.weight (groupnorm) => ((1 + layer_id) / total_layers) ** 0.7
ffn.key.weight => nn.init.orthogonal_(gain=1)
ffn.value.weight => zero
ffn.receptance.weight => zero
- หากคุณใช้การฝังตำแหน่ง บางทีอาจเป็นการดีกว่าถ้าลบ block.0.ln0 และใช้การกำหนดค่าเริ่มต้นสำหรับ emb.weight แทนของฉัน uniform_(a=-1e-4, b=1e-4) !!!
เมื่อฝึกตั้งแต่เริ่มต้น ให้เพิ่ม "k = k * torch.clamp(w, max=0).exp()" ก่อน "RUN_CUDA_RWKV6(r, k, v, w, u)" และอย่าลืมเปลี่ยนรหัสการอนุมานของคุณด้วย . คุณจะเห็นการบรรจบกันเร็วขึ้น
ใช้ "--adam_eps 1e-18"
"--beta2 0.95" หากคุณเห็นการเพิ่มขึ้นอย่างรวดเร็ว
ใน trainer.py ให้ทำ "lr = lr * (0.01 + 0.99 * trainer.global_step / w_step)" (เดิมคือ 0.2 + 0.8) และ "--warmup_steps 20"
"--weight_decay 0.1" นำไปสู่การสูญเสียขั้นสุดท้ายที่ดีขึ้นหากคุณฝึกฝนข้อมูลจำนวนมาก ตั้งค่า lr_final เป็น 1/100 ของ lr_init เมื่อทำสิ่งนี้
RWKV คือ RNN ที่มีประสิทธิภาพ LLM ระดับ Transformer ซึ่งสามารถฝึกได้โดยตรงเหมือนกับหม้อแปลง GPT (แบบขนานได้) และปราศจากความสนใจ 100% คุณเพียงต้องการสถานะที่ซ่อนอยู่ที่ตำแหน่ง t เพื่อคำนวณสถานะที่ตำแหน่ง t+1 คุณสามารถใช้โหมด "GPT" เพื่อคำนวณสถานะที่ซ่อนอยู่สำหรับโหมด "RNN" ได้อย่างรวดเร็ว
ดังนั้นจึงเป็นการผสมผสานสิ่งที่ดีที่สุดของ RNN และ Transformer - ประสิทธิภาพที่ยอดเยี่ยม การอนุมานที่รวดเร็ว บันทึก VRAM การฝึกฝนที่รวดเร็ว ctx_len "ไม่สิ้นสุด" และการฝังประโยคอิสระ (โดยใช้สถานะที่ซ่อนอยู่สุดท้าย)
RWKV Runner GUI https://github.com/josStorer/RWKV-Runner ด้วยการติดตั้งและ API เพียงคลิกเดียว
ตุ้มน้ำหนัก RWKV ล่าสุดทั้งหมด: https://huggingface.co/BlinkDL
ตุ้มน้ำหนัก RWKV ที่เข้ากันได้กับ HF: https://huggingface.co/RWKV
แพ็คเกจ pip RWKV : https://pypi.org/project/rwkv/
os . environ [ "RWKV_JIT_ON" ] = '1'
os . environ [ "RWKV_CUDA_ON" ] = '0' # if '1' then use CUDA kernel for seq mode (much faster)
from rwkv . model import RWKV # pip install rwkv
model = RWKV ( model = '/fsx/BlinkDL/HF-MODEL/rwkv-4-pile-1b5/RWKV-4-Pile-1B5-20220903-8040' , strategy = 'cuda fp16' )
out , state = model . forward ([ 187 , 510 , 1563 , 310 , 247 ], None ) # use 20B_tokenizer.json
print ( out . detach (). cpu (). numpy ()) # get logits
out , state = model . forward ([ 187 , 510 ], None )
out , state = model . forward ([ 1563 ], state ) # RNN has state (use deepcopy if you want to clone it)
out , state = model . forward ([ 310 , 247 ], state )
print ( out . detach (). cpu (). numpy ()) # same result as abovenanoRWKV : https://github.com/BlinkDL/nanoRWKV (ไม่ต้องใช้เคอร์เนล CUDA แบบกำหนดเองในการฝึก ใช้งานได้กับ GPU/CPU ใด ๆ )
ทวิตเตอร์ : https://twitter.com/BlinkDL_AI
หน้าแรก : https://www.rwkv.com
โครงการชุมชน RWKV ที่ยอดเยี่ยม :
โครงการ RWKV ทั้งหมด (300+) โครงการ: https://github.com/search?o=desc&q=rwkv&s=updated&type=Repositories
https://github.com/OpenGVLab/Vision-RWKV วิสัยทัศน์ RWKV
https://github.com/feizc/Diffusion-RWKV การแพร่กระจาย RWKV
https://github.com/cgisky1980/ai00_rwkv_server การอนุมาน WebGPU ที่เร็วที่สุด (nVidia/AMD/Intel)
https://github.com/cryscan/web-rwkv แบ็กเอนด์สำหรับ ai00_rwkv_server
https://github.com/saharNooby/rwkv.cpp การอนุมาน CPU/cuBLAS/CLBlast ที่รวดเร็ว: int4/int8/fp16/fp32
https://github.com/JL-er/RWKV-PEFT lora/pissa/Qlora/Qpissa/state การปรับแต่ง
https://github.com/RWKV/RWKV-infctx-trainer เทรนเนอร์ Infctx
https://github.com/daquexian/faster-rwkv
mlc-ai/mlc-llm#1275
https://github.com/TheRamU/Fay/blob/main/README_EN.md ผู้ช่วยดิจิทัลพร้อม RWKV
https://github.com/harrisonvanderbyl/rwkv-cpp-cuda การอนุมาน GPU ที่รวดเร็วด้วย cuda/amd/vulkan
RWKV v6 ใน 250 บรรทัด (พร้อมโทเค็นด้วย): https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_v6_demo.py
RWKV v5 ใน 250 บรรทัด (พร้อมโทเค็นด้วย): https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_v5_demo.py
RWKV v4 ใน 150 บรรทัด (โมเดล การอนุมาน การสร้างข้อความ): https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_in_150_lines.py
พิมพ์ล่วงหน้า RWKV v4 https://arxiv.org/abs/2305.13048
การแนะนำ RWKV v4 และใน 100 บรรทัดของ numpy : https://johanwind.github.io/2023/03/23/rwkv_overview.html https://johanwind.github.io/2023/03/23/rwkv_details.html
RWKV v6 มีภาพประกอบ:
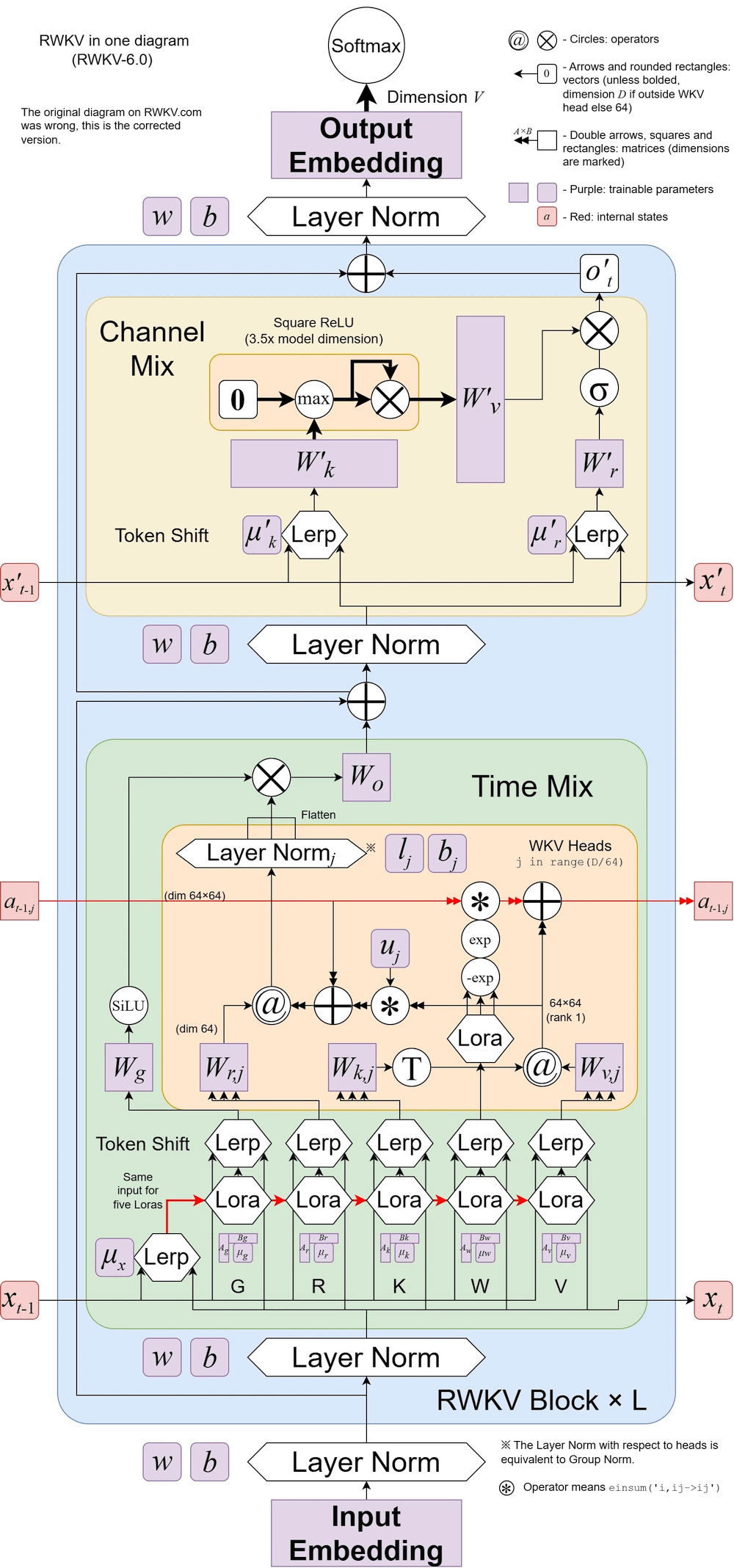
เอกสารเจ๋งๆ (Spiking Neural Network) โดยใช้ RWKV: https://github.com/ridgerchu/SpikeGPT
คุณสามารถเข้าร่วมความขัดแย้งของ RWKV https://discord.gg/bDSBUMeFpc เพื่อสร้างมันขึ้นมา ขณะนี้เรามีศักยภาพในการประมวลผล (A100 40Gs) มากมาย (ต้องขอบคุณความเสถียรและ EleutherAI) ดังนั้นหากคุณมีไอเดียที่น่าสนใจ ฉันก็สามารถดำเนินการได้

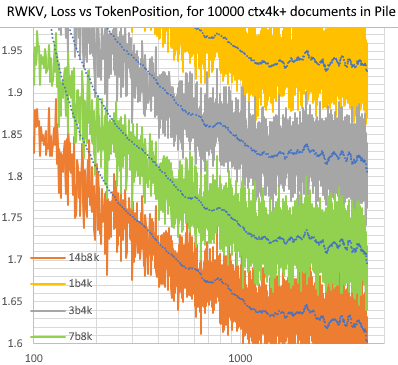
RWKV [การสูญเสียเทียบกับตำแหน่งโทเค็น] สำหรับเอกสาร 10,000 ctx4k+ ใน Pile RWKV 1B5-4k ส่วนใหญ่จะแบนหลังจาก ctx1500 แต่ 3B-4k และ 7B-4k และ 14B-4k มีความลาดชันอยู่บ้าง และพวกมันก็เริ่มดีขึ้น สิ่งนี้หักล้างมุมมองเก่าที่ RNN ไม่สามารถสร้างโมเดล ctxlens แบบยาวได้ เราสามารถคาดเดาได้ว่า RWKV 100B จะยอดเยี่ยม และ RWKV 1T น่าจะเป็นสิ่งที่คุณต้องการ :)
ChatRWKV กับ RWKV 14B ctx8192:

ฉันเชื่อว่า RNN เป็นตัวเลือกที่ดีกว่าสำหรับโมเดลพื้นฐาน เนื่องจาก: (1) เป็นมิตรกับ ASIC มากกว่า (ไม่มีแคช kv) (2) RL เป็นมิตรมากกว่า (3) เมื่อเราเขียน สมองของเราคล้ายกับ RNN มากกว่า (4) จักรวาลก็เหมือนกับ RNN เช่นกัน (เพราะท้องถิ่น) หม้อแปลงไฟฟ้าเป็นรุ่นที่ไม่ใช่ในประเทศ
RWKV-3 1.5B บน A40 (tf32) = 0.015 วินาที/โทเค็นเสมอ ทดสอบโดยใช้โค้ด pytorch แบบง่าย (ไม่มี CUDA) การใช้งาน GPU 45%, VRAM 7823M
GPT2-XL 1.3B บน A40 (tf32) = 0.032 วินาที/โทเค็น (สำหรับ ctxlen 1000) ทดสอบโดยใช้ HF, การใช้งาน GPU 45% เช่นกัน (น่าสนใจ), VRAM 9655M
ความเร็วการฝึก: (รหัสการฝึกใหม่) RWKV-4 14B BF16 ctxlen4096 = โทเค็น 114K/s บน 8x8 A100 80G (ZERO2+CP) (รหัสการฝึกอบรมเก่า) RWKV-4 1.5B BF16 ctxlen1024 = โทเค็น 106K/s บน 8xA100 40G
ฉันกำลังทำการทดลองเกี่ยวกับภาพด้วย (ตัวอย่างเช่น: https://huggingface.co/BlinkDL/clip-guided-binary-autoencoder) และ RWKV จะสามารถทำการแพร่กระจาย txt2img ได้ :) ความคิดของฉัน: รูปภาพ 256x256 rgb -> 32x32x13 บิตแฝง - > ใช้ RWKV เพื่อคำนวณความน่าจะเป็นของการเปลี่ยนแปลงสำหรับตารางขนาด 32x32 แต่ละตาราง -> แกล้งทำเป็นว่ากริดมีความเป็นอิสระและ "กระจาย" โดยใช้ความน่าจะเป็นเหล่านี้
การฝึกที่ราบรื่น - ไม่มีการสูญเสียเดือย! (lr & bsz เปลี่ยนโทเค็นประมาณ 15G) 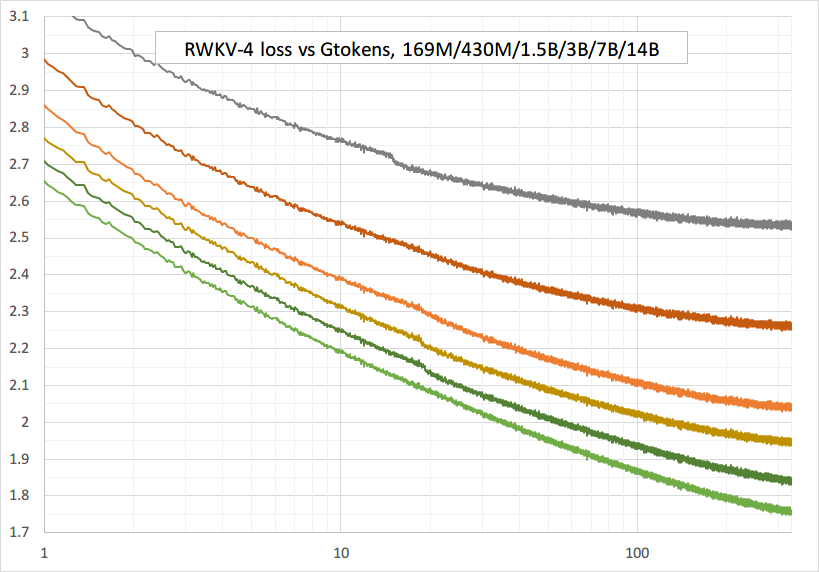
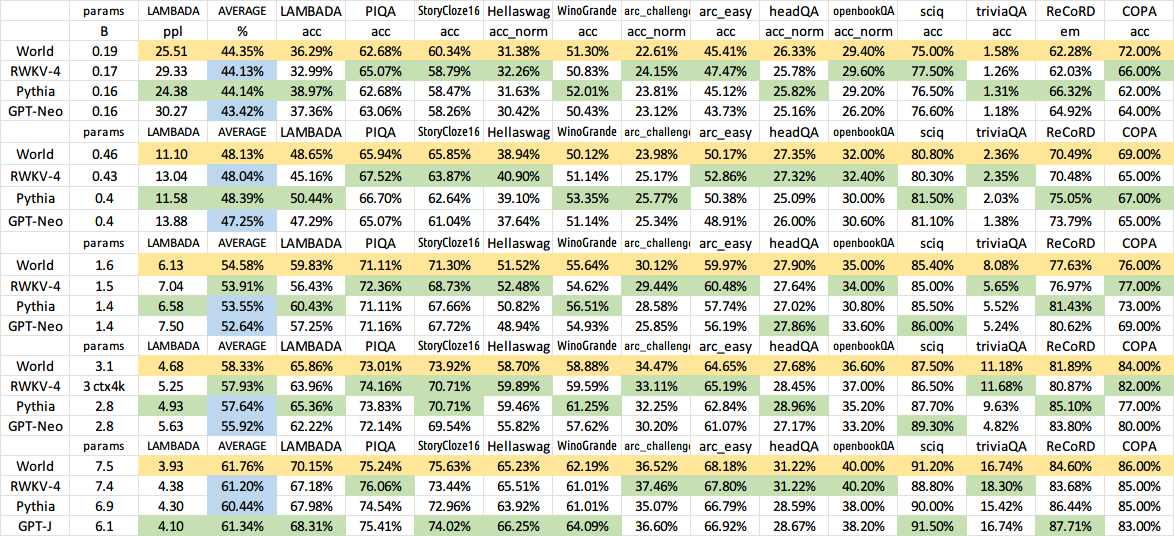
โมเดลที่ผ่านการฝึกอบรมทั้งหมดจะเป็นโอเพ่นซอร์ส การอนุมานทำได้เร็วมาก (เฉพาะการคูณเมทริกซ์-เวกเตอร์ ไม่มีการคูณเมทริกซ์-เมทริกซ์) แม้แต่บน CPU ดังนั้นคุณจึงสามารถเรียกใช้ LLM บนโทรศัพท์ของคุณได้
วิธีการทำงาน: RWKV รวบรวมข้อมูลไปยังหลายช่องทาง ซึ่งจะลดลงด้วยความเร็วที่แตกต่างกันเมื่อคุณย้ายไปยังโทเค็นถัดไป มันง่ายมากเมื่อคุณเข้าใจมัน
RWKV สามารถขนานกันได้เนื่องจากการสลายตัวของเวลาของแต่ละช่องสัญญาณไม่ขึ้นอยู่กับข้อมูล (และสามารถฝึกอบรมได้) ตัวอย่างเช่น ใน RNN ปกติ คุณสามารถปรับระยะเวลาเสื่อมของช่องสัญญาณจาก 0.8 เป็น 0.5 (ซึ่งเรียกว่า "ประตู") ในขณะที่ใน RWKV คุณเพียงแค่ย้ายข้อมูลจากช่อง W-0.8 ไปยัง W-0.5 -channel เพื่อให้บรรลุผลเช่นเดียวกัน ยิ่งไปกว่านั้น คุณสามารถปรับแต่ง RWKV ให้เป็น RNN ที่ไม่สามารถขนานกันได้ (จากนั้นคุณสามารถใช้เอาต์พุตของเลเยอร์ถัดไปของโทเค็นก่อนหน้าได้) หากคุณต้องการประสิทธิภาพพิเศษ

นี่คือสิ่งที่ต้องทำบางส่วนของฉัน มาร่วมงานกัน :)
การรวม HuggingFace (ตรวจสอบ Huggingface/transformers#17230 ) และเพิ่มประสิทธิภาพการอนุมาน CPU & iOS & Android & WASM & WebGL RWKV เป็น RNN และเป็นมิตรกับอุปกรณ์ Edge มาก มาทำให้สามารถเรียกใช้ LLM บนโทรศัพท์ของคุณกันเถอะ
ทดสอบกับงานแบบสองทิศทางและ MLM และโทเค็นรูปภาพ เสียง และวิดีโอ ฉันคิดว่า RWKV สามารถรองรับ Encoder-Decoder ได้ด้วยสิ่งนี้: สำหรับโทเค็นตัวถอดรหัสแต่ละตัว ให้ใช้ส่วนผสมที่เรียนรู้ของ [สถานะซ่อนตัวถอดรหัสก่อนหน้า] และ [สถานะซ่อนตัวสุดท้ายของตัวเข้ารหัส] ดังนั้นโทเค็นตัวถอดรหัสทั้งหมดจะสามารถเข้าถึงเอาต์พุตตัวเข้ารหัสได้
ขณะนี้กำลังฝึกอบรม RWKV-4a โดยให้ความสนใจเป็นพิเศษเพียงเล็กน้อย (เพียงไม่กี่บรรทัดเพิ่มเติมเมื่อเปรียบเทียบกับ RWKV-4) เพื่อปรับปรุงงาน Zeroshot ที่ยากลำบากบางอย่าง (เช่น LAMBADA) สำหรับโมเดลขนาดเล็ก ดู https://github.com/BlinkDL/RWKV-LM/commit/a268cd2e40351ee31c30c5f8a5d1266d35b41829
ความคิดเห็นของผู้ใช้:
จนถึงตอนนี้ ฉันเคยลองใช้โมเดลตามตัวละครในชุดข้อมูลก่อนการฝึกที่ค่อนข้างเล็ก (ข้อความประมาณ 10GB) และผลลัพธ์ก็ดีมาก - คล้ายกับโมเดลที่ใช้เวลาฝึกฝนนานกว่ามาก
พระเจ้าที่รัก rwkv นั้นเร็วมาก ฉันเปลี่ยนไปใช้แท็บอื่นหลังจากเริ่มฝึกตั้งแต่เริ่มต้น & เมื่อฉันกลับมามันก็เปล่งเสียงภาษาอังกฤษและคำเมารีที่เป็นไปได้ ฉันออกไปเอากาแฟไปอุ่นในไมโครเวฟ & เมื่อฉันกลับมา มันก็สร้างประโยคที่ถูกต้องตามหลักไวยากรณ์
ทวีตจาก Sepp Hochreiter (ขอบคุณ!): https://twitter.com/HochreiterSepp/status/1524270961314484227
คุณสามารถหาฉัน (BlinkDL) ใน EleutherAI Discord ได้เช่นกัน: https://www.eleuther.ai/get-involved/
สิ่งสำคัญ: ใช้ deepspeed==0.7.0 pytorch-lightning==1.9.5 torch==1.13.1+cu117 และ cuda 11.7.1 หรือ 11.7 (หมายเหตุ torch2 + deepspeed มีข้อบกพร่องแปลก ๆ และทำให้ประสิทธิภาพของโมเดลลดลง)
ใช้ https://github.com/BlinkDL/RWKV-LM/tree/main/RWKV-v4neo (โค้ดล่าสุด เข้ากันได้กับ v4)
นี่เป็นคำแนะนำที่ดีสำหรับการทดสอบถามตอบของ LLM ใช้งานได้กับทุกรุ่น: (พบโดยย่อ ChatGPT ppls ให้เหลือน้อยที่สุดสำหรับ RWKV 1.5B)
prompt = f' n Q & A n n Question: n { qq } n n Detailed Expert Answer: n ' # let the model generate after thisเรียกใช้โมเดล Pile RWKV-4: ดาวน์โหลดโมเดลจาก https://huggingface.co/BlinkDL ตั้งค่า TOKEN_MODE = 'pile' ใน run.py และเรียกใช้ มันเร็วแม้บน CPU (โหมดเริ่มต้น)
Colab สำหรับเสาเข็ม RWKV-4 1.5B : https://colab.research.google.com/drive/1F7tZoPZaWJf1fsCmZ5tjw6sYHiFOYVWM
เรียกใช้โมเดล Pile RWKV-4 ในเบราว์เซอร์ของคุณ (และเวอร์ชัน onnx): ดูปัญหานี้ #7
การสาธิตเว็บ RWKV-4: https://josephrocca.github.io/rwkv-v4-web/demo/ (หมายเหตุ: ตอนนี้มีเพียงการสุ่มตัวอย่างโลภเท่านั้น)
สำหรับ RWKV-2 เก่า: ดูการเปิดตัวที่นี่สำหรับรุ่นพารามิเตอร์ 27M บน enwik8 พร้อม 0.72 BPC(dev) เรียกใช้ run.py ใน https://github.com/BlinkDL/RWKV-LM/tree/main/RWKV-v2-RNN คุณสามารถเรียกใช้ในเบราว์เซอร์ของคุณ: https://github.com/BlinkDL/AI-Writer/tree/main/docs/eng https://blinkdl.github.io/AI-Writer/eng/ (นี่คือการใช้ tf.js WASM โหมดเธรดเดียว)
pip ติดตั้ง deepspeed==0.7.0 // pip ติดตั้ง pytorch-lightning==1.9.5 // ไฟฉาย 1.13.1+cu117
หมายเหตุ: เพิ่มการลดน้ำหนัก (0.1 หรือ 0.01) และการออกกลางคัน (0.1 หรือ 0.01) เมื่อฝึกกับข้อมูลจำนวนเล็กน้อย ลอง x=x+dropout(att(x)) x=x+dropout(ffn(x)) x=dropout(x+att(x)) x=dropout(x+ffn(x)) เป็นต้น
การฝึกอบรม RWKV-4 ตั้งแต่เริ่มต้น: เรียกใช้ train.py ซึ่งโดยค่าเริ่มต้นจะใช้ชุดข้อมูล enwik8 (แตกไฟล์ https://data.deepai.org/enwik8.zip)
คุณจะได้ฝึกอบรมเวอร์ชัน "GPT" เนื่องจากเป็นแบบคู่ขนานและฝึกได้เร็วกว่า RWKV-4 สามารถคาดการณ์ได้ ดังนั้นการฝึกด้วย ctxLen 1024 จึงสามารถใช้ได้กับ ctxLen ที่มากกว่า 2500+ คุณสามารถปรับแต่งโมเดลด้วย ctxLen ที่ยาวขึ้นได้ และสามารถปรับให้เข้ากับ ctxLens ที่ยาวขึ้นได้อย่างรวดเร็ว
การปรับแต่งโมเดลเสาเข็ม RWKV-4 อย่างละเอียด: ใช้ 'prepare-data.py' ใน https://github.com/BlinkDL/RWKV-v2-RNN-Pile/tree/main/RWKV-v3 เพื่อโทเค็น .txt เข้าสู่รถไฟ ข้อมูล npy จากนั้นใช้ https://github.com/BlinkDL/RWKV-LM/blob/main/RWKV-v4neo/train.py เพื่อฝึกฝน
อ่านโค้ดการอนุมานใน src/model.py และลองใช้สถานะที่ซ่อนอยู่ขั้นสุดท้าย (.xx .aa .bb) เป็นประโยคที่ซื่อสัตย์ที่ฝังไว้สำหรับงานอื่น คุณควรเริ่มต้นด้วย .xx และ .aa/.bb (.aa หารด้วย .bb)
Colab สำหรับการปรับแต่งโมเดลเสาเข็ม RWKV-4: https://colab.research.google.com/github/resloved/RWKV-notebooks/blob/master/RWKV_v4_RNN_Pile_Fine_Tuning.ipynb
คลังข้อมูลขนาดใหญ่: ใช้ https://github.com/Abel2076/json2binidx_tool เพื่อแปลง .jsonl เป็น .bin และ .idx
ตัวอย่างรูปแบบ jsonl (หนึ่งบรรทัดสำหรับแต่ละเอกสาร):
{"text": "This is the first document."}
{"text": "HellonWorld"}
{"text": "1+1=2n1+2=3n2+2=4"}
สร้างโดยโค้ดดังนี้:
ss = json.dumps({"text": text}, ensure_ascii=False)
out.write(ss + "n")
การฝึกอบรม ctxlen แบบไม่มีที่สิ้นสุด (WIP): https://github.com/Blealtan/RWKV-LM-LoRA/tree/dev-infctx
พิจารณา RWKV 14B สถานะมีเวกเตอร์ 200 ตัว นั่นคือ 5 เวกเตอร์สำหรับแต่ละบล็อก: fp16 (xx), fp32 (aa), fp32 (bb), fp32 (pp), fp16 (xx)
อย่ารวมค่าเฉลี่ยเพราะเวกเตอร์ที่แตกต่างกัน (xx aa bb pp xx) ในรัฐมีความหมายและช่วงที่แตกต่างกันมาก คุณอาจจะลบ pp ออกได้
ฉันขอแนะนำให้รวบรวมสถิติเฉลี่ย + stdev ของแต่ละช่องของเวกเตอร์แต่ละตัวก่อน และทำให้สถิติทั้งหมดเป็นมาตรฐาน (หมายเหตุ: การทำให้เป็นมาตรฐานควรเป็นข้อมูลที่ไม่ขึ้นกับข้อมูลและรวบรวมจากข้อความต่างๆ) จากนั้นจึงฝึกคลาสซิเฟอร์เชิงเส้น
RWKV-5 เป็นแบบหลายหัว และที่นี่จะแสดงหัวเดียว นอกจากนี้ยังมี LayerNorm สำหรับแต่ละหัว (ดังนั้นจริงๆ แล้ว GroupNorm)
มิกซ์แบบไดนามิกและการสลายตัวแบบไดนามิก ตัวอย่าง (ทำสิ่งนี้กับทั้ง TimeMix และ ChannelMix):
TIME_MIX_EXTRA_DIM = 32
self.time_mix_k_w1 = nn.Parameter(torch.empty(args.n_embd, TIME_MIX_EXTRA_DIM).uniform_(-0.01, 0.01))
self.time_mix_k_w2 = nn.Parameter(torch.zeros(TIME_MIX_EXTRA_DIM, args.n_embd))
self.time_mix_v_w1 = nn.Parameter(torch.empty(args.n_embd, TIME_MIX_EXTRA_DIM).uniform_(-0.01, 0.01))
self.time_mix_v_w2 = nn.Parameter(torch.zeros(TIME_MIX_EXTRA_DIM, args.n_embd))
self.time_mix_r_w1 = nn.Parameter(torch.empty(args.n_embd, TIME_MIX_EXTRA_DIM).uniform_(-0.01, 0.01))
self.time_mix_r_w2 = nn.Parameter(torch.zeros(TIME_MIX_EXTRA_DIM, args.n_embd))
self.time_mix_g_w1 = nn.Parameter(torch.empty(args.n_embd, TIME_MIX_EXTRA_DIM).uniform_(-0.01, 0.01))
self.time_mix_g_w2 = nn.Parameter(torch.zeros(TIME_MIX_EXTRA_DIM, args.n_embd))
...
time_mix_k = self.time_mix_k.view(1,1,-1) + (x @ self.time_mix_k_w1) @ self.time_mix_k_w2
time_mix_v = self.time_mix_v.view(1,1,-1) + (x @ self.time_mix_v_w1) @ self.time_mix_v_w2
time_mix_r = self.time_mix_r.view(1,1,-1) + (x @ self.time_mix_r_w1) @ self.time_mix_r_w2
time_mix_g = self.time_mix_g.view(1,1,-1) + (x @ self.time_mix_g_w1) @ self.time_mix_g_w2
xx = self.time_shift(x)
xk = x * time_mix_k + xx * (1 - time_mix_k)
xv = x * time_mix_v + xx * (1 - time_mix_v)
xr = x * time_mix_r + xx * (1 - time_mix_r)
xg = x * time_mix_g + xx * (1 - time_mix_g)

ใช้โหมดขนานเพื่อสร้างสถานะอย่างรวดเร็ว จากนั้นใช้ RNN เต็มรูปแบบที่ได้รับการปรับแต่งอย่างละเอียด (เลเยอร์ของโทเค็น n สามารถใช้เอาต์พุตของเลเยอร์ทั้งหมดของโทเค็น n-1) สำหรับการสร้างตามลำดับ
ตอนนี้การเสื่อมสลายของเวลามีค่าประมาณ 0.999^T (0.999 สามารถเรียนรู้ได้) เปลี่ยนเป็น (0.999^T + 0.1) โดยที่ 0.1 ก็สามารถเรียนรู้ได้เช่นกัน ส่วน 0.1 จะถูกเก็บไว้ตลอดไป หรือ A^T + B^T + C = สลายเร็ว + สลายช้า + ค่าคงที่ สามารถใช้สูตรที่แตกต่างกันได้ (เช่น K^2 แทน e^K สำหรับองค์ประกอบการสลายตัว หรือไม่มีการทำให้เป็นมาตรฐาน)
ใช้การสลายตัวด้วยค่าเชิงซ้อน (ดังนั้น หมุนแทนการสลายตัว) ในบางช่องสัญญาณ
ใส่การเข้ารหัสตำแหน่งที่สามารถฝึกได้และคาดการณ์ได้บ้างไหม?
นอกเหนือจากการหมุน 2 มิติแล้ว เรายังสามารถลองใช้กลุ่ม Lie อื่นๆ เช่น การหมุน 3 มิติ ( SO(3) ) RWKV ไม่ใช่ชาวอาเบเลี่ยน ฮ่าๆ
RWKV อาจใช้งานได้ดีบนอุปกรณ์อะนาล็อก (ค้นหาการคูณเมทริกซ์แบบแอนะล็อก-เวกเตอร์ และการคูณโฟโตนิกเมทริกซ์-เวกเตอร์) โหมด RNN นั้นเป็นมิตรกับฮาร์ดแวร์มาก (การประมวลผลในหน่วยความจำ) สามารถเป็น SNN ได้เช่นกัน (https://github.com/ridgerchu/SpikeGPT) ฉันสงสัยว่ามันจะสามารถปรับให้เหมาะสมสำหรับการคำนวณควอนตัมได้หรือไม่
สถานะซ่อนเร้นเริ่มต้นที่สามารถฝึกได้ (xx aa bb pp xx)
LR แบบเลเยอร์ (หรือแม้แต่แถว/คอลัมน์ แบบองค์ประกอบ) และทดสอบเครื่องมือเพิ่มประสิทธิภาพ Lion
self.pos_emb_x = nn.Parameter(torch.zeros((1,args.my_pos_emb,args.n_embd)))
self.pos_emb_y = nn.Parameter(torch.zeros((args.my_pos_emb,1,args.n_embd)))
...
x = x + pos_emb_x + pos_emb_y
บางทีเราสามารถปรับปรุงการท่องจำได้โดยเพียงแค่ท่องบริบทซ้ำ (ฉันเดาว่า 2 ครั้งก็เพียงพอแล้ว) ตัวอย่าง: การอ้างอิง -> การอ้างอิง (อีกครั้ง) -> คำถาม -> คำตอบ
แนวคิดก็คือเพื่อให้แน่ใจว่าแต่ละโทเค็นในคำศัพท์เข้าใจความยาวและไบต์ UTF-8 แบบดิบ
ให้ a = max(len(token)) สำหรับโทเค็นทั้งหมดในคำศัพท์ กำหนด AA : float[a][d_emb]
ให้ b = max(len_in_utf8_bytes(token)) สำหรับโทเค็นทั้งหมดในคำศัพท์ กำหนด BB : float[b][256][d_emb]
สำหรับแต่ละโทเค็น X ในคำศัพท์ ให้ [x0, x1, ..., xn] เป็นไบต์ UTF-8 แบบดิบ เราจะเพิ่มค่าพิเศษบางอย่างให้กับการฝัง EMB(X):
EMB(X) += AA[len(X)] + BB[0][x0] + BB[1][x1] + ... + BB[n][xn] (หมายเหตุ: AA BB เป็นตุ้มน้ำหนักที่เรียนรู้ได้)
ฉันมีความคิดที่จะปรับปรุงโทเค็น เราสามารถฮาร์ดโค้ดบางช่องให้มีความหมายได้ ตัวอย่าง:
ช่อง 0 = "ช่องว่าง"
ช่อง 1 = "อักษรตัวแรกเป็นตัวพิมพ์ใหญ่"
ช่อง 2 = "ใช้อักษรตัวพิมพ์ใหญ่ทั้งหมด"
ดังนั้น:
การฝัง "abc": [0, 0, 0, x0, x1, x2 , ..]
การฝัง " abc": [1, 0, 0, x0, x1, x2, ..]
การฝัง " Abc": [1, 1, 0, x0, x1, x2, ..]
การฝัง "ABC": [0, 0, 1, x0, x1, x2, ...]
-
ดังนั้นพวกเขาจะแบ่งปันการฝังส่วนใหญ่ และเราสามารถคำนวณความน่าจะเป็นเอาท์พุตของรูปแบบ "abc" ทุกรูปแบบได้อย่างรวดเร็ว
หมายเหตุ: วิธีการข้างต้นสมมุติว่า p(" xyz") / p("xyz") เหมือนกันสำหรับ "xyz" ใดๆ ซึ่งอาจผิดได้
ดีกว่า: กำหนด emb_space emb_capitalize_first emb_capitalize_all ให้เป็นฟังก์ชันของ emb
อาจจะดีที่สุด: ให้ 'abc' ' abc' ฯลฯ แบ่งปัน 90% สุดท้ายของการฝัง
ในขณะนี้ โทเค็นไนเซอร์ทั้งหมดของเราใช้รายการมากเกินไปเพื่อแสดงรูปแบบทั้งหมดของ 'abc' ' abc' ' Abc' เป็นต้น ยิ่งไปกว่านั้น โมเดลไม่สามารถค้นพบได้ว่าสิ่งเหล่านี้คล้ายกันจริง ๆ หากรูปแบบเหล่านี้บางรูปแบบหาได้ยากในชุดข้อมูล วิธีการที่นี่สามารถปรับปรุงสิ่งนี้ได้ ฉันวางแผนที่จะทดสอบสิ่งนี้ใน RWKV เวอร์ชันใหม่
ตัวอย่าง (ถามตอบรอบเดียว):
สร้างสถานะสุดท้ายของเอกสารวิกิทั้งหมด
สำหรับผู้ใช้ Q ให้ค้นหาเอกสารวิกิที่ดีที่สุด และใช้สถานะสุดท้ายเป็นสถานะเริ่มต้น
ฝึกฝนโมเดลเพื่อสร้างสถานะเริ่มต้นที่เหมาะสมที่สุดสำหรับผู้ใช้ Q โดยตรง
อย่างไรก็ตาม อาจยุ่งยากกว่านี้เล็กน้อยสำหรับการถามตอบแบบหลายรอบ :)
RWKV ได้รับแรงบันดาลใจจาก AFT ของ Apple (https://arxiv.org/abs/2105.14103)
นอกจากนี้มันยังใช้ลูกเล่นของฉันหลายอย่าง เช่น:
SmallInitEmb: https://github.com/BlinkDL/SmallInitEmb (ใช้ได้กับหม้อแปลงทั้งหมด) ซึ่งช่วยคุณภาพการฝังและทำให้ Post-LN เสถียร (ซึ่งเป็นสิ่งที่ฉันใช้)
Token-shift: https://github.com/BlinkDL/RWKV-LM#token-shift-time-shift-mixing (ใช้ได้กับหม้อแปลงทั้งหมด) มีประโยชน์อย่างยิ่งสำหรับโมเดลระดับถ่าน
Head-QK: https://github.com/BlinkDL/RWKV-LM#the-head-qk-trick-learning-to-copy-and-avoid-tokens (ใช้ได้กับหม้อแปลงทั้งหมด) หมายเหตุ: มีประโยชน์ แต่ฉันปิดการใช้งานในโมเดล Pile เพื่อให้เป็น RNN 100%
R-gate พิเศษใน FFN (ใช้ได้กับหม้อแปลงทุกตัว) ฉันยังใช้ reluSquared จาก Primer ด้วย
การเริ่มต้นที่ดีขึ้น: ฉันเริ่มต้นเมทริกซ์ส่วนใหญ่เป็นศูนย์ (ดู RWKV_Init ใน https://github.com/BlinkDL/RWKV-LM/blob/main/RWKV-v2-RNN/src/model.py)
คุณสามารถถ่ายโอนพารามิเตอร์บางตัวจากรุ่นเล็กไปเป็นรุ่นใหญ่ได้ (หมายเหตุ: ฉันก็จัดเรียง & ปรับให้เรียบด้วย) เพื่อการลู่เข้าที่รวดเร็วและดีขึ้น (ดู https://www.reddit.com/r/MachineLearning/comments/umq908/r_rwkvv2rnn_a_parallelizable_rnn_with /)
เคอร์เนล CUDA ของฉัน: https://github.com/BlinkDL/RWKV-CUDA เพื่อเร่งความเร็วการฝึกอบรม

ปัจจัย abcd ทำงานร่วมกันเพื่อสร้างเส้นโค้งตามเวลา: [X, 1, W, W^2, W^3, ...]
เขียนสูตรสำหรับ "โทเค็นที่ตำแหน่ง 2" และ "โทเค็นที่ตำแหน่ง 3" แล้วคุณจะได้แนวคิด:
kv / k เป็นกลไกของหน่วยความจำ โทเค็นที่มีค่า k สูงสามารถจดจำได้เป็นระยะเวลานาน หาก W ใกล้ถึง 1 ในช่องสัญญาณ
R-gate มีความสำคัญต่อประสิทธิภาพ k = ความแรงของข้อมูลของโทเค็นนี้ (ที่จะส่งต่อไปยังโทเค็นในอนาคต) r = จะใช้ข้อมูลกับโทเค็นนี้หรือไม่
ใช้ปัจจัย TimeMix ที่แตกต่างกันที่สามารถฝึกได้สำหรับ R / K / V ในเลเยอร์ SA และ FF ตัวอย่าง:
xx = self . time_shift ( x )
xk = x * self . time_mix_k + xx * ( 1 - self . time_mix_k )
xv = x * self . time_mix_v + xx * ( 1 - self . time_mix_v )
xr = x * self . time_mix_r + xx * ( 1 - self . time_mix_r )ใช้ preLN แทน postLN (การบรรจบกันที่เสถียรและเร็วขึ้น):
if self . layer_id == 0 :
x = self . ln0 ( x )
x = x + self . att ( self . ln1 ( x ))
x = x + self . ffn ( self . ln2 ( x ))โครงสร้างหลักของโหมด RWKV-3 GPT นั้นคล้ายคลึงกับโครงสร้างของ preLN GPT ทั่วไป
ข้อแตกต่างเพียงอย่างเดียวคือ LN เพิ่มเติมหลังจากการฝัง โปรดทราบว่าคุณสามารถดูดซับ LN นี้ลงในการฝังได้หลังจากเสร็จสิ้นการฝึก
x = self . emb ( idx ) # input: idx = token indices
x = self . ln_emb ( x ) # extra LN after embedding
x = x + self . att_0 ( self . ln_att_0 ( x )) # preLN
x = x + self . ffn_0 ( self . ln_ffn_0 ( x ))
...
x = x + self . att_n ( self . ln_att_n ( x ))
x = x + self . ffn_n ( self . ln_ffn_n ( x ))
x = self . ln_head ( x ) # final LN before projection
x = self . head ( x ) # output: x = logitsสิ่งสำคัญคือต้องเริ่มต้น emb เป็นค่าเล็กๆ เช่น nn.init.uniform_(a=-1e-4, b=1e-4) เพื่อใช้เคล็ดลับของฉัน https://github.com/BlinkDL/SmallInitEmb
สำหรับ 1.5B RWKV-3 ฉันใช้เครื่องมือเพิ่มประสิทธิภาพ Adam (ไม่มี wd ไม่มี dropout) บน 8 * A100 40G
battSz = 32 * 896, ctxLen = 896 ฉันใช้ tf32 ดังนั้น battSz จึงเล็กไปหน่อย
สำหรับโทเค็น 15B แรก LR ได้รับการแก้ไขที่ 3e-4 และ beta=(0.9, 0.99)
จากนั้นฉันตั้งค่า beta=(0.9, 0.999) และทำการสลายตัวแบบเอ็กซ์โปเนนเชียลของ LR ถึง 1e-5 ที่โทเค็น 332B
RWKV-3 ไม่มีความสนใจใดๆ ตามปกติ แต่เราจะเรียกบล็อกนี้ว่า ATT ต่อไป
B , T , C = x . size () # x = (Batch,Time,Channel)
# Mix x with the previous timestep to produce xk, xv, xr
xx = self . time_shift ( x ) # self.time_shift = nn.ZeroPad2d((0,0,1,-1))
xk = x * self . time_mix_k + xx * ( 1 - self . time_mix_k )
xv = x * self . time_mix_v + xx * ( 1 - self . time_mix_v )
xr = x * self . time_mix_r + xx * ( 1 - self . time_mix_r )
# Use xk, xv, xr to produce k, v, r
k = self . key ( xk ). transpose ( - 1 , - 2 )
v = self . value ( xv ). transpose ( - 1 , - 2 )
r = self . receptance ( xr )
k = torch . clamp ( k , max = 60 ) # clamp k to avoid overflow
k = torch . exp ( k )
kv = k * v
# Compute the W-curve = [e^(-n * e^time_decay), e^(-(n-1) * e^time_decay), ..., 1, e^(time_first)]
self . time_w = torch . cat ([ torch . exp ( self . time_decay ) * self . time_curve . to ( x . device ), self . time_first ], dim = - 1 )
w = torch . exp ( self . time_w )
# Use W to mix kv and k respectively. Add K_EPS to wk to avoid divide-by-zero
if RUN_DEVICE == 'cuda' :
wkv = TimeX . apply ( w , kv , B , C , T , 0 )
wk = TimeX . apply ( w , k , B , C , T , K_EPS )
else :
w = w [:, - T :]. unsqueeze ( 1 )
wkv = F . conv1d ( nn . ZeroPad2d (( T - 1 , 0 , 0 , 0 ))( kv ), w , groups = C )
wk = F . conv1d ( nn . ZeroPad2d (( T - 1 , 0 , 0 , 0 ))( k ), w , groups = C ) + K_EPS
# The RWKV formula
rwkv = torch . sigmoid ( r ) * ( wkv / wk ). transpose ( - 1 , - 2 )
rwkv = self . output ( rwkv ) # final output projectionself.key, self.receptance, self.output เมทริกซ์ทั้งหมดถูกกำหนดให้เป็นศูนย์
เวกเตอร์ time_mix, time_decay, time_first จะถูกถ่ายโอนจากโมเดลที่ผ่านการฝึกอบรมที่มีขนาดเล็กกว่า (หมายเหตุ: ฉันก็จัดเรียงและทำให้พวกมันเรียบเช่นกัน)
บล็อก FFN มีสามเทคนิคเมื่อเปรียบเทียบกับ GPT ปกติ:
เคล็ดลับ time_mix ของฉัน
sqReLU จากกระดาษรองพื้น
ประตูรับพิเศษ (คล้ายกับประตูรับในบล็อก ATT)
# Mix x with the previous timestep to produce xk, xr
xx = self . time_shift ( x )
xk = x * self . time_mix_k + xx * ( 1 - self . time_mix_k )
xr = x * self . time_mix_r + xx * ( 1 - self . time_mix_r )
# The usual FFN operation
k = self . key ( xk )
k = torch . square ( torch . relu ( k )) # from the Primer paper
kv = self . value ( k )
# Apply an extra receptance-gate to kv
rkv = torch . sigmoid ( self . receptance ( xr )) * kv
return rkvself.value และเมทริกซ์ self.receptance ทั้งหมดถูกเตรียมใช้งานให้เป็นศูนย์

ให้ F[t] เป็นสถานะของระบบที่ t
ให้ x[t] เป็นอินพุตภายนอกใหม่ที่ t
ใน GPT การทำนาย F[t+1] จะต้องพิจารณา F[0], F[1], .. F[t] ดังนั้นจึงต้องใช้ O(T^2) เพื่อสร้างลำดับความยาว T
สูตรอย่างง่าย สำหรับ GPT:
มีความสามารถมากในทางทฤษฎี แต่นั่น ไม่ได้หมายความว่าเราจะสามารถใช้ความสามารถของมันอย่างเต็มที่กับเครื่องมือเพิ่มประสิทธิภาพตามปกติ ฉันสงสัยว่าแนวการสูญเสียนั้นยากเกินไปสำหรับวิธีการปัจจุบันของเรา
เปรียบเทียบกับ สูตรอย่างง่าย สำหรับ RWKV (โหมดคู่ขนาน มีลักษณะคล้ายกับ AFT ของ Apple):
R, K, V เป็นเมทริกซ์ที่ฝึกได้ และ W เป็นเวกเตอร์ที่ฝึกได้ (ปัจจัยการสลายตัวของเวลาสำหรับแต่ละช่องสัญญาณ)
ใน GPT การมีส่วนร่วมของ F[i] ถึง F[t+1] จะถ่วงน้ำหนักด้วย
ใน RWKV-2 การมีส่วนร่วมของ F[i] ถึง F[t+1] จะถ่วงน้ำหนักด้วย
ประเด็นสำคัญมาถึงแล้ว: เราสามารถเขียนมันใหม่เป็น RNN (สูตรเรียกซ้ำ) บันทึก:
ดังนั้นจึงง่ายที่จะตรวจสอบ:
โดยที่ A[t] และ B[t] เป็นตัวเศษและส่วนของขั้นตอนที่แล้ว ตามลำดับ
ฉันเชื่อว่า RWKV มีประสิทธิภาพเพราะ W เหมือนกับการใช้เมทริกซ์แนวทแยงซ้ำๆ หมายเหตุ (P^{-1} DP)^n = P^{-1} D^n P ดังนั้นจึงคล้ายกับการใช้เมทริกซ์แบบทแยงมุมทั่วไปซ้ำๆ
ยิ่งไปกว่านั้น ยังสามารถเปลี่ยนเป็น ODE ต่อเนื่องได้ (คล้ายกับ State Space Models เล็กน้อย) ฉันจะเขียนเกี่ยวกับเรื่องนี้ในภายหลัง
ฉันมีแนวคิดสำหรับ [ข้อความ --> ภาพ RGB 32x32] โดยใช้ LM (หม้อแปลง, RWKV ฯลฯ ) จะทดสอบเร็วๆ นี้
ประการแรก การสูญเสีย LM (แทนที่จะเป็นการสูญเสีย L2) ดังนั้นภาพจะไม่เบลอ
ประการที่สอง การหาปริมาณสี ตัวอย่างเช่น อนุญาตเพียง 8 ระดับสำหรับ R/G/B ดังนั้นขนาดคำศัพท์ของรูปภาพคือ 8x8x8 = 512 (สำหรับแต่ละพิกเซล) แทนที่จะเป็น 2^24 ดังนั้น รูปภาพ RGB ขนาด 32x32 = ลำดับ len1024 ของ vocab512 (โทเค็นรูปภาพ) ซึ่งเป็นอินพุตทั่วไปสำหรับ LM ทั่วไป (ต่อมาเราสามารถใช้แบบจำลองการแพร่กระจายเพื่อเพิ่มตัวอย่างและสร้างภาพ RGB888 เราอาจใช้ LM สำหรับสิ่งนี้ได้เช่นกัน)
ประการที่สาม การฝังตำแหน่ง 2 มิติที่โมเดลเข้าใจได้ง่าย ตัวอย่างเช่น เพิ่มพิกัด X & Y ยอดนิยมหนึ่งรายการลงในช่อง 64(=32+32) แรก สมมติว่าพิกเซลอยู่ที่ x=8, y=20 เราจะบวก 1 เข้ากับช่อง 8 และช่อง 52 (=32+20) ยิ่งกว่านั้นเราอาจสามารถเพิ่มพิกัด X & Y แบบลอย (ทำให้เป็นช่วง 0~1) ให้กับอีก 2 ช่องสัญญาณได้ และตำแหน่งอื่นๆ เป็นระยะๆ การเข้ารหัสอาจช่วยได้เช่นกัน (จะทดสอบ)
ในที่สุด RandRound เมื่อ


