CAMEL
1.0.0

เราภูมิใจที่จะแนะนำ Asclepius ซึ่งเป็นโมเดลภาษาขนาดใหญ่ทางคลินิกขั้นสูงยิ่งขึ้น เนื่องจากโมเดลนี้ได้รับการฝึกฝนเกี่ยวกับบันทึกทางคลินิกสังเคราะห์ จึงสามารถเข้าถึงได้แบบสาธารณะผ่าน Huggingface หากคุณกำลังพิจารณาใช้ CAMEL เราขอแนะนำอย่างยิ่งให้เปลี่ยนไปใช้ Asclepius แทน สำหรับข้อมูลเพิ่มเติมกรุณาเยี่ยมชมลิงค์นี้
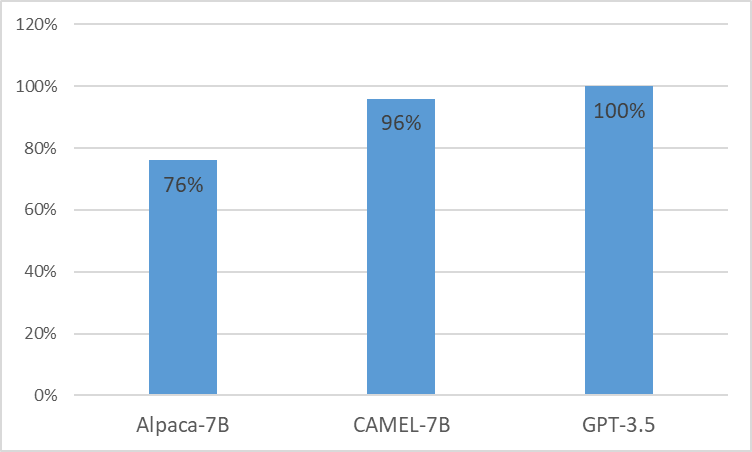
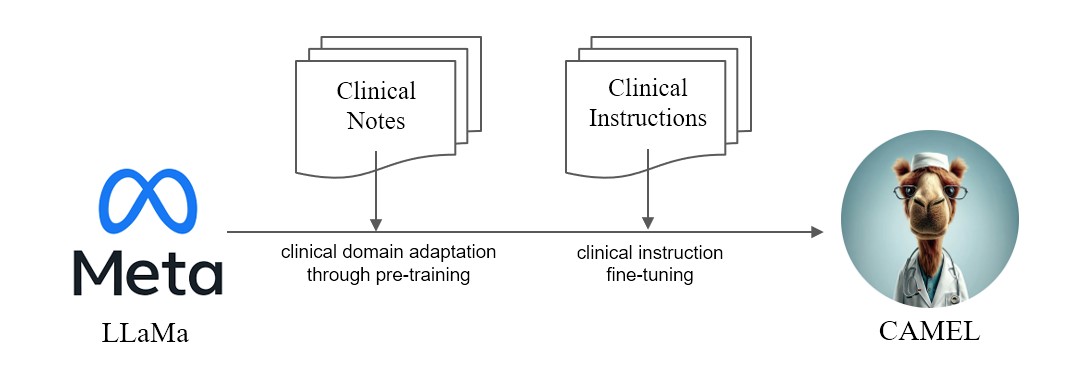
เรานำเสนอ CAMEL โมเดลดัดแปลงทางคลินิกที่ได้รับการปรับปรุงจาก LLaMA เนื่องจาก LLaMA เป็นรากฐาน CAMEL จึงได้รับการฝึกอบรมเพิ่มเติมเกี่ยวกับบันทึกทางคลินิก MIMIC-III และ MIMIC-IV และปรับปรุงคำแนะนำทางคลินิกอย่างละเอียด (รูปที่ 2) การประเมินเบื้องต้นของเราด้วยการประเมิน GPT-4 แสดงให้เห็นว่า CAMEL บรรลุคุณภาพมากกว่า 96% ของ GPT-3.5 ของ OpenAI (รูปที่ 1) ตามนโยบายการใช้ข้อมูลของแหล่งข้อมูลของเรา ทั้งชุดข้อมูลคำสั่งและแบบจำลองของเราจะถูกเผยแพร่บน PhysioNet พร้อมการเข้าถึงที่ได้รับการรับรอง เพื่ออำนวยความสะดวกในการจำลองแบบ เราจะเผยแพร่โค้ดทั้งหมด เพื่อให้สถาบันด้านการดูแลสุขภาพแต่ละแห่งสามารถจำลองแบบจำลองของเราโดยใช้บันทึกทางคลินิกของตนเองได้ สำหรับรายละเอียดเพิ่มเติม โปรดดู บล็อกโพสต์ ของเรา
เนื่องจากปัญหาใบอนุญาตของชุดข้อมูล MIMIC และ i2b2 เราจึงไม่สามารถเผยแพร่ชุดข้อมูลคำสั่งและจุดตรวจสอบได้ เราจะเผยแพร่โมเดลและข้อมูลของเราผ่านทาง physionet ภายในไม่กี่สัปดาห์
conda create -n camel python=3.9 -y
conda activate camel
conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia -y
pip install pandarallel pandas jupyter numpy datasets sentencepiece openai fire
pip install git+https://github.com/huggingface/transformers.git@871598be552c38537bc047a409b4a6840ba1c1e4
<eos>$ python pretraining_preprocess/mimiciii_preproc.py --mimiciii_note_path {MIMICIII_NOTE_PATH} --output_path {OUTPUT_PATH}$ python pretraining_preprocess/mimiciv_preproc.py --discharge_note_path {DISCHAGE_NOTE_PATH} --radiology_note_path {RADIOLOGY_NOTE_PATH} --output_path {OUTPUT_PATH}$ python pretraining_preprocess/tokenize_data.py --data_path {DATA_PATH} --save_path {SAVE_PATH} $ torchrun --nproc_per_node=8 --master_port={YOUR_PORT}
src/train.py
--model_name_or_path "decapoda-research/llama-7b-hf"
--data_path {DATA_FILE}
--bf16 True
--output_dir ./checkpoints
--num_train_epochs 1
--per_device_train_batch_size 2
--per_device_eval_batch_size 2
--gradient_accumulation_steps 8
--evaluation_strategy "no"
--save_strategy "steps"
--save_steps 1000
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0.03
--lr_scheduler_type "cosine"
--logging_steps 1
--fsdp "full_shard auto_wrap"
--fsdp_transformer_layer_cls_to_wrap 'LlamaDecoderLayer'
--tf32 True
--model_max_length 2048
--gradient_checkpointing True
หมายเหตุ: หากต้องการสร้างคำแนะนำ คุณควรใช้ Azure Openai API ที่ได้รับการรับรอง
การสร้างคำสั่ง
OPENAI_API_KEYOPENAI_API_BASEOPENAI_DEPLOYMENT_NAME$ python instructino/preprocess_note.py$ python instruction/de_id_gen.py --input {PREPROCESSED_NOTES} --output {OUTPUT_FILE_1} --mode inst$ python instruction/de_id_postprocess.py --input {OUTPUT_FILE_1} --output {OUTPUT_FILE_2}$ python instruction/de_id_gen.py --input {OUTPUT__FILE_2} --output {inst_output/OUTPUT_FILE_deid} --mode ans$ python instruction/instructtion_gen.py --input {PREPROCESSED_NOTES} --output {inst_output/OUTPUT_FILE} --source {mimiciii, mimiciv, i2b2}$ python instruction/merge_data.py --data_path {inst_output} --output {OUTPUT_FILE_FINAL}เรียกใช้คำสั่ง Finetuning
nproc_per_node และ gradient accumulate step ให้พอดีกับฮาร์ดแวร์ของคุณ (ขนาดแบตช์ทั่วโลก = 128) $ torchrun --nproc_per_node=8 --master_port={YOUR_PORT}
src/instruction_ft.py
--model_name_or_path "decapoda-research/llama-7b-hf"
--data_path {OUTPUT_FILE_FINAL}
--bf16 True
--output_dir ./checkpoints
--num_train_epochs 3
--per_device_train_batch_size 2
--per_device_eval_batch_size 2
--gradient_accumulation_steps 8
--evaluation_strategy "no"
--save_strategy "epoch"
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0.03
--lr_scheduler_type "cosine"
--logging_steps 1
--fsdp "full_shard auto_wrap"
--fsdp_transformer_layer_cls_to_wrap 'LlamaDecoderLayer'
--tf32 True
--model_max_length 2048
--gradient_checkpointing True
--ddp_timeout 18000
เรียกใช้โมเดลบน MTSamples
CUDA_VISIBLE_DEVICES=0 python src/evaluate.py
--model_name {MODEL_PATH}
--data_path eval/mtsamples_instructions.json
--output_path {OUTPUT_PATH}
mtsamples_results.json ในโฟลเดอร์ evalเรียกใช้ GPT-4 เพื่อการประเมินผล
python eval/gpt4_evaluate.py --input {INPUT_PATH} --output {OUTPUT_PATH}
@misc{CAMEL,
title = {CAMEL : Clinically Adapted Model Enhanced from LLaMA},
author = {Sunjun Kweon and Junu Kim and Seongsu Bae and Eunbyeol Cho and Sujeong Im and Jiyoun Kim and Gyubok Lee and JongHak Moon and JeongWoo Oh and Edward Choi},
month = {May},
year = {2023}
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/starmpcc/CAMEL}},
}


