CareGPT
1.0.0
จีน |. อังกฤษ
วิดีโอสอน การติดตั้งและการปรับใช้ ประสบการณ์ออนไลน์

⚡คุณสมบัติ:
conda create - n llm python = 3.11
conda activate llm
python - m pip install - r requirements . txt # 转为HF格式
python - m transformers . models . llama . convert_llama_weights_to_hf
- - input_dir path_to_llama_weights - - model_size 7 B - - output_dir path_to_llama_model หากคุณใช้ชุดข้อมูลที่กำหนดเอง อย่าลืมระบุคำจำกัดความของชุดข้อมูลในไฟล์ dataset_info.json ในรูปแบบต่อไปนี้
"数据集名称" : {
"hf_hub_url" : " HuggingFace上的项目地址(若指定,则忽略下列三个参数) " ,
"script_url" : "包含数据加载脚本的本地文件夹名称(若指定,则忽略下列两个参数) " ,
"file_name" : "该目录下数据集文件的名称(若上述参数未指定,则此项必需) " ,
"file_sha1" : "数据集文件的SHA-1哈希值(可选) " ,
"columns" : {
"prompt" : "数据集代表提示词的表头名称(默认:instruction) " ,
"query" : "数据集代表请求的表头名称(默认:input) " ,
"response" : "数据集代表回答的表头名称(默认:output) " ,
"history" : "数据集代表历史对话的表头名称(默认:None) "
}
} คอลัมน์ prompt และ response ควรเป็นสตริงที่ไม่ว่างเปล่า เนื้อหาของคอลัมน์ query จะถูกต่อเข้ากับคอลัมน์ prompt เป็นอินพุตโมเดล คอลัมน์ history ควรเป็นรายการ โดยแต่ละองค์ประกอบคือสตริงทูเพิลที่แสดงถึงคำขอของผู้ใช้และการตอบกลับของโมเดลตามลำดับ
รูปแบบ .txt หนึ่งข้อมูลที่ไม่มีผู้ดูแลต่อบรรทัด
Machine learning (ML) is a field devoted to understanding and building methods that let machines "learn" – that is, methods that leverage data to improve computer performance on some set of tasks.
Machine learning algorithms build a model based on sample data, known as training data, in order to make predictions or decisions without being explicitly programmed to do so. Machine learning algorithms are used in a wide variety of applications, such as in medicine, email filtering, speech recognition, agriculture, and computer vision, where it is difficult or unfeasible to develop conventional algorithms to perform the needed tasks.[
{
"instruction" : "听起来很不错。人工智能可能在哪些方面面临挑战呢? " ,
"input" : " " ,
"output" : "人工智能面临的挑战包括数据隐私、安全和道德方面的问题,以及影响就业机会的自动化等问题。 " ,
"history" : [
[ "你好,你能帮我解答一个问题吗? " , "当然,请问有什么问题? " ],
[ "我想了解人工智能的未来发展方向,你有什么想法吗? " , "人工智能在未来的发展方向可能包括更强大的机器学习算法,更先进的自然语言处理技术,以及更加智能的机器人。 " ]
]
}
][
{
"instruction" : "听起来很不错。人工智能可能在哪些方面面临挑战呢? " ,
"input" : " " ,
"output" : "人工智能面临的挑战包括数据隐私、安全和道德方面的问题,以及影响就业机会的自动化等问题。 " ,
"history" : []
}
][
{
"instruction" : "生成三个与“道歉”意思相同的动词" ,
"input" : " " ,
"output" : [
"承认,表示遗憾,弥补。 " ,
"道歉"
]
}
] ตรวจสอบว่าการ์ดแสดงผลของคุณเชื่อมต่อกับ NVLINK หรือไม่ เฉพาะการเชื่อมต่อ NVLINK เท่านั้นที่คุณสามารถใช้ accelerate สำหรับการฝึกเร่งความเร็วแบบขนานได้อย่างมีประสิทธิภาพ
nvidia-smi topo -m
accelerate config # configure the environment
accelerate launch src / train_bash . py # arguments (same as above) # LLaMA-2
accelerate launch src / train_bash . py
- - stage sft
- - model_name_or_path . / Llama - 2 - 7 b - chat - hf
- - do_train
- - dataset mm
- - finetuning_type lora
- - quantization_bit 4
- - overwrite_cache
- - output_dir output
- - per_device_train_batch_size 8
- - gradient_accumulation_steps 4
- - lr_scheduler_type cosine
- - logging_steps 10
- - save_steps 1000
- - learning_rate 5e-5
- - num_train_epochs 2.0
- - plot_loss
- - fp16
- - template llama2
- - lora_target q_proj , v_proj
# LLaMA
accelerate launch src / train_bash . py
- - stage sft
- - model_name_or_path . / Llama - 7 b - hf
- - do_train
- - dataset mm , hm
- - finetuning_type lora
- - overwrite_cache
- - output_dir output - 1
- - per_device_train_batch_size 4
- - gradient_accumulation_steps 4
- - lr_scheduler_type cosine
- - logging_steps 10
- - save_steps 2000
- - learning_rate 5e-5
- - num_train_epochs 2.0
- - plot_loss
- - fp16
- - template default
- - lora_target q_proj , v_proj # LLaMA-2, DPO
accelerate launch src / train_bash . py
- - stage dpo
- - model_name_or_path . / Llama - 2 - 7 b - chat - hf
- - do_train
- - dataset rlhf
- - template llama2
- - finetuning_type lora
- - quantization_bit 4
- - lora_target q_proj , v_proj
- - resume_lora_training False
- - checkpoint_dir . / output - 2
- - output_dir output - dpo
- - per_device_train_batch_size 2
- - gradient_accumulation_steps 4
- - lr_scheduler_type cosine
- - logging_steps 10
- - save_steps 1000
- - learning_rate 1e-5
- - num_train_epochs 1.0
- - plot_loss
- - fp16 # LLaMA-2
python src / web_demo . py
- - model_name_or_path . / Llama - 2 - 7 b - chat - hf
- - checkpoint_dir output
- - finetuning_type lora
- - template llama2
# LLaMA
python src / web_demo . py
- - model_name_or_path . / Llama - 7 b - hf
- - checkpoint_dir output - 1
- - finetuning_type lora
- - template default
# DPO
python src / web_demo . py
- - model_name_or_path . / Llama - 2 - 7 b - chat - hf
- - checkpoint_dir output - dpo
- - finetuning_type lora
- - template llama2 # LLaMA-2
python src / api_demo . py
- - model_name_or_path . / Llama - 2 - 7 b - chat - hf
- - checkpoint_dir output
- - finetuning_type lora
- - template llama2
# LLaMA
python src / api_demo . py
- - model_name_or_path . / Llama - 7 b - hf
- - checkpoint_dir output - 1
- - finetuning_type lora
- - template default
# DPO
python src / api_demo . py
- - model_name_or_path . / Llama - 2 - 7 b - chat - hf
- - checkpoint_dir output - dpo
- - finetuning_type lora
- - template llama2ทดสอบ API:
curl - X 'POST'
'http://127.0.0.1:8888/v1/chat/completions'
- H 'accept: application/json'
- H 'Content-Type: application/json'
- d ' {
"model" : "string",
"messages": [
{
"role" : "user",
"content": "你好"
}
],
" temperature ": 0 ,
"top_p" : 0 ,
"max_new_tokens" : 0 ,
"stream" : false
}' # LLaMA-2
python src / cli_demo . py
- - model_name_or_path . / Llama - 2 - 7 b - chat - hf
- - checkpoint_dir output
- - finetuning_type lora
- - template llama2
# LLaMA
python src / cli_demo . py
- - model_name_or_path . / Llama - 7 b - hf
- - checkpoint_dir output - 1
- - finetuning_type lora
- - template default
# DPO
python src / cli_demo . py
- - model_name_or_path . / Llama - 2 - 7 b - chat - hf
- - checkpoint_dir output - dpo
- - finetuning_type lora
- - template llama2 # LLaMA-2
CUDA_VISIBLE_DEVICES = 0 python src / train_bash . py
- - stage sft
- - model_name_or_path . / Llama - 2 - 7 b - chat - hf
- - do_predict
- - dataset mm
- - template llama2
- - finetuning_type lora
- - checkpoint_dir output
- - output_dir predict_output
- - per_device_eval_batch_size 8
- - max_samples 100
- - predict_with_generate
# LLaMA
CUDA_VISIBLE_DEVICES = 0 python src / train_bash . py
- - stage sft
- - model_name_or_path . / Llama - 7 b - hf
- - do_predict
- - dataset mm
- - template default
- - finetuning_type lora
- - checkpoint_dir output - 1
- - output_dir predict_output
- - per_device_eval_batch_size 8
- - max_samples 100
- - predict_with_generate # LLaMA-2
CUDA_VISIBLE_DEVICES = 0 python src / train_bash . py
- - stage sft
- - model_name_or_path . / Llama - 2 - 7 b - chat - hf
- - do_eval
- - dataset mm
- - template llama2
- - finetuning_type lora
- - checkpoint_dir output
- - output_dir eval_output
- - per_device_eval_batch_size 8
- - max_samples 100
- - predict_with_generate
# LLaMA
CUDA_VISIBLE_DEVICES = 0 python src / train_bash . py
- - stage sft
- - model_name_or_path . / Llama - 7 b - hf
- - do_eval
- - dataset mm
- - template default
- - finetuning_type lora
- - checkpoint_dir output - 1
- - output_dir eval_output
- - per_device_eval_batch_size 8
- - max_samples 100
- - predict_with_generate สำหรับการประเมินแบบ 4/8 บิต ขอแนะนำให้ใช้ --per_device_eval_batch_size=1 และ --max_target_length 128
# LLaMA-2
python src / export_model . py
- - model_name_or_path . / Llama - 2 - 7 b - chat - hf
- - template llama2
- - finetuning_type lora
- - checkpoint_dir output - 1
- - output_dir output_export
# LLaMA
python src / export_model . py
- - model_name_or_path . / Llama - 7 b - hf
- - template default
- - finetuning_type lora
- - checkpoint_dir output
- - output_dir output_export % cd Gradio
python app . py 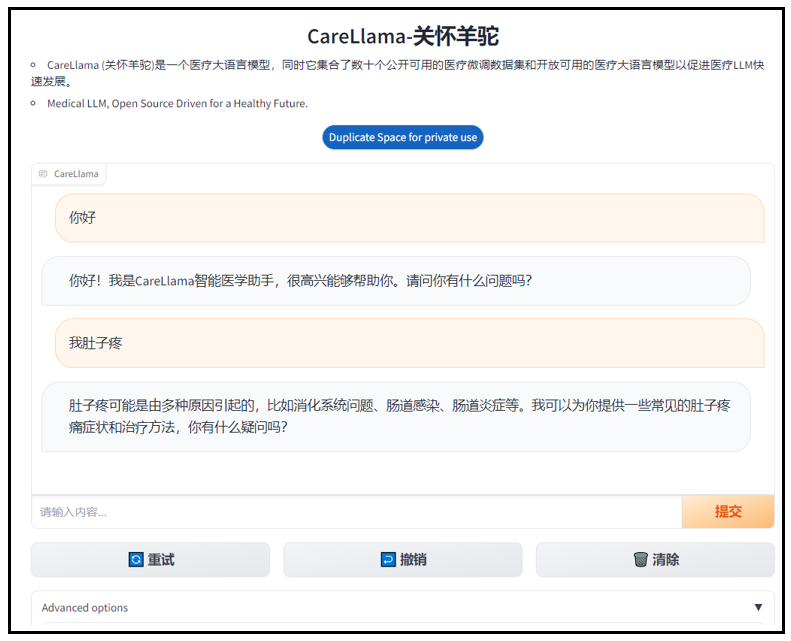
# LLaMA-2
python src / api_demo . py
- - model_name_or_path . / Llama - 2 - 7 b - chat - hf
- - checkpoint_dir output
- - finetuning_type lora
- - template llama2
# LLaMA
python src / api_demo . py
- - model_name_or_path . / Llama - 7 b - hf
- - checkpoint_dir output - 1
- - finetuning_type lora
- - template default设置แก้ไข接口地址เป็น: http://127.0.0.1:8000/ (นั่นคือ ที่อยู่อินเทอร์เฟซ API ของคุณ) จากนั้นคุณจึงจะสามารถใช้งานได้ 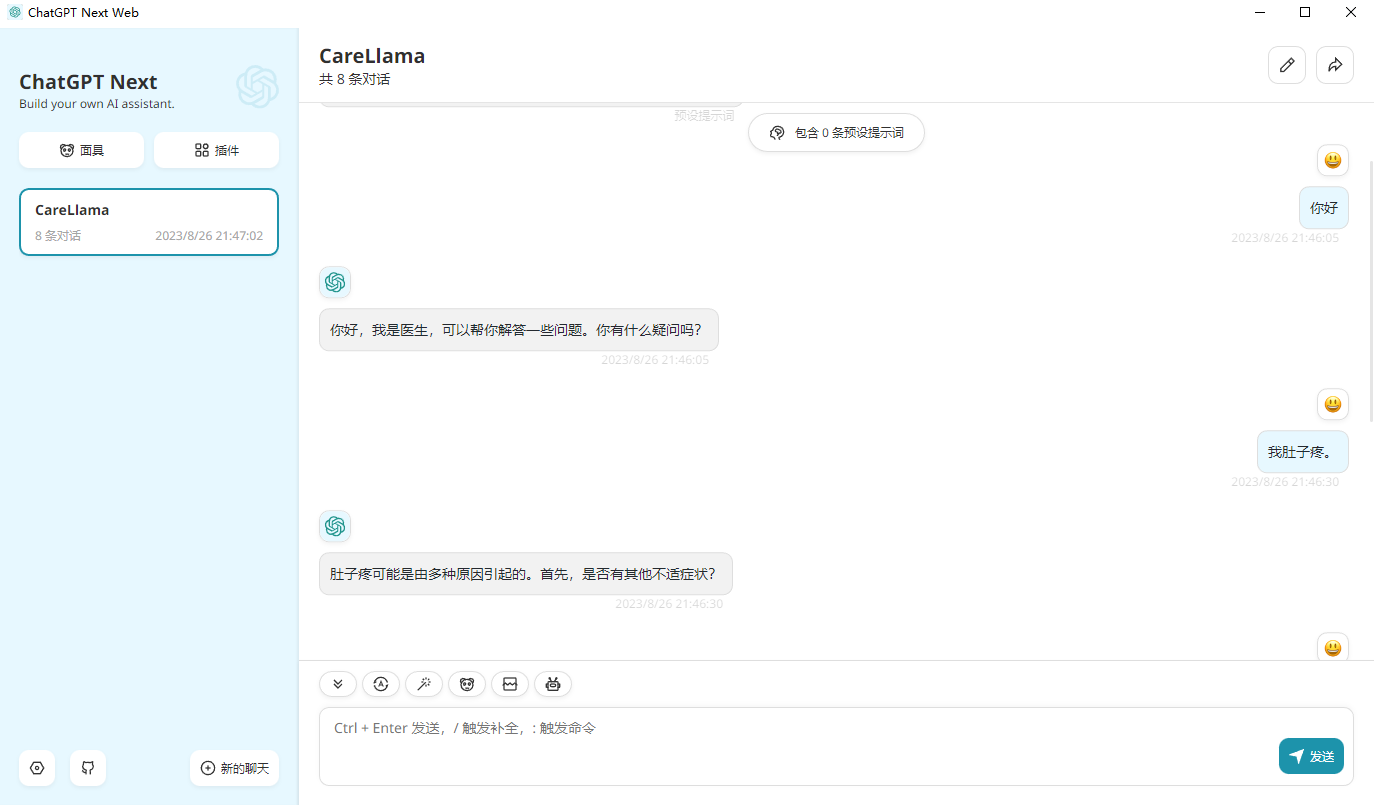
PubMed Central และ PubMed Abstracts ข้อความอันทรงคุณค่าเหล่านี้ได้เสริมสร้างระบบความรู้ทางการแพทย์ของโมเดล BLOOMZ อย่างมาก ดังนั้นโครงการโอเพ่นซอร์สจำนวนมากจึงให้ความสำคัญกับ BLOOMZ เป็นโมเดลพื้นฐานสำหรับการปรับแต่งทางการแพทย์质量> 数量คือความจริง เช่น: Less is More! ส่งมอบให้กับ Qingyuan&& Caspian | ใช้ข้อมูล 200 ชิ้นเพื่อปรับแต่งโมเดลอย่างละเอียด มินิจีพีที-4 ! ข้อมูล SFT ขนาดใหญ่พิเศษจะทำให้ LLM งานดาวน์สตรีมอ่อนแอลง หรือสูญเสีย ICL, CoT และความสามารถอื่นๆ大规模预训练+小规模监督微调=超强的LLM模型英文10B以下选择Mistral-7B中文, 10B以下选择Yi-6B 10B และ 10B以上选择Qwen-14B和Yi-34B ; สำคัญ
ยินดีให้ทุกคนเพิ่มประสบการณ์ใหม่ๆ ให้กับ ISSUE!
ระเบียบวิธี 11~13 มาจากแบบจำลองภาษาขนาดใหญ่กว่า 13 พันล้านแบบ การเปลี่ยนแปลงน้ำหนักเพียงครั้งเดียวจะทำให้ความสามารถทางภาษาหายไปโดยสิ้นเชิง! งานวิจัยล่าสุดจากห้องปฏิบัติการประมวลผลภาษาธรรมชาติของมหาวิทยาลัยฟู่ตัน
14วิธีการจากความสามารถในโมเดลภาษาขนาดใหญ่ได้รับผลกระทบจากองค์ประกอบข้อมูลที่มีการปรับแต่งอย่างละเอียดภายใต้การดูแลอย่างไร
วิธีการ 17~25 มาจาก LLM Optimization: Layer-wise Optimal Rank Adaptation (LORA) การตีความเวอร์ชันภาษาจีน
| เวที | รู้เบื้องต้นเกี่ยวกับน้ำหนัก | ดาวน์โหลดที่อยู่ | คุณสมบัติ | โมเดลพื้นฐาน | วิธีการปรับแบบละเอียด | ชุดข้อมูล |
|---|---|---|---|---|---|---|
| ?การกำกับดูแลและการปรับแต่ง | ข้อมูลบทสนทนาแบบหลายเลี้ยวได้รับการฝึกอบรมตาม LLaMA2-7b-Chat | CareLlama2-7b-แชท-sft-หลาย、?CareLlama2-7b-หลาย | ทักษะการสนทนาหลายรอบที่ยอดเยี่ยม | LLaMA2-7b-แชท | คิวลอรา | มม |
| กำกับดูแลการปรับจูน | ข้อมูลการสนทนาระหว่างแพทย์และผู้ป่วยที่สมบูรณ์และมีประสิทธิภาพได้รับการฝึกอบรมบน LLaMA2-7b-Chat | CareLlama2-7b-แชท-sft-med | ความสามารถในการวินิจฉัยโรคของผู้ป่วยที่ดีเยี่ยม | LLaMA2-7b-แชท | คิวลอรา | อืม |
| กำกับดูแล |


