DiGIT
1.0.0
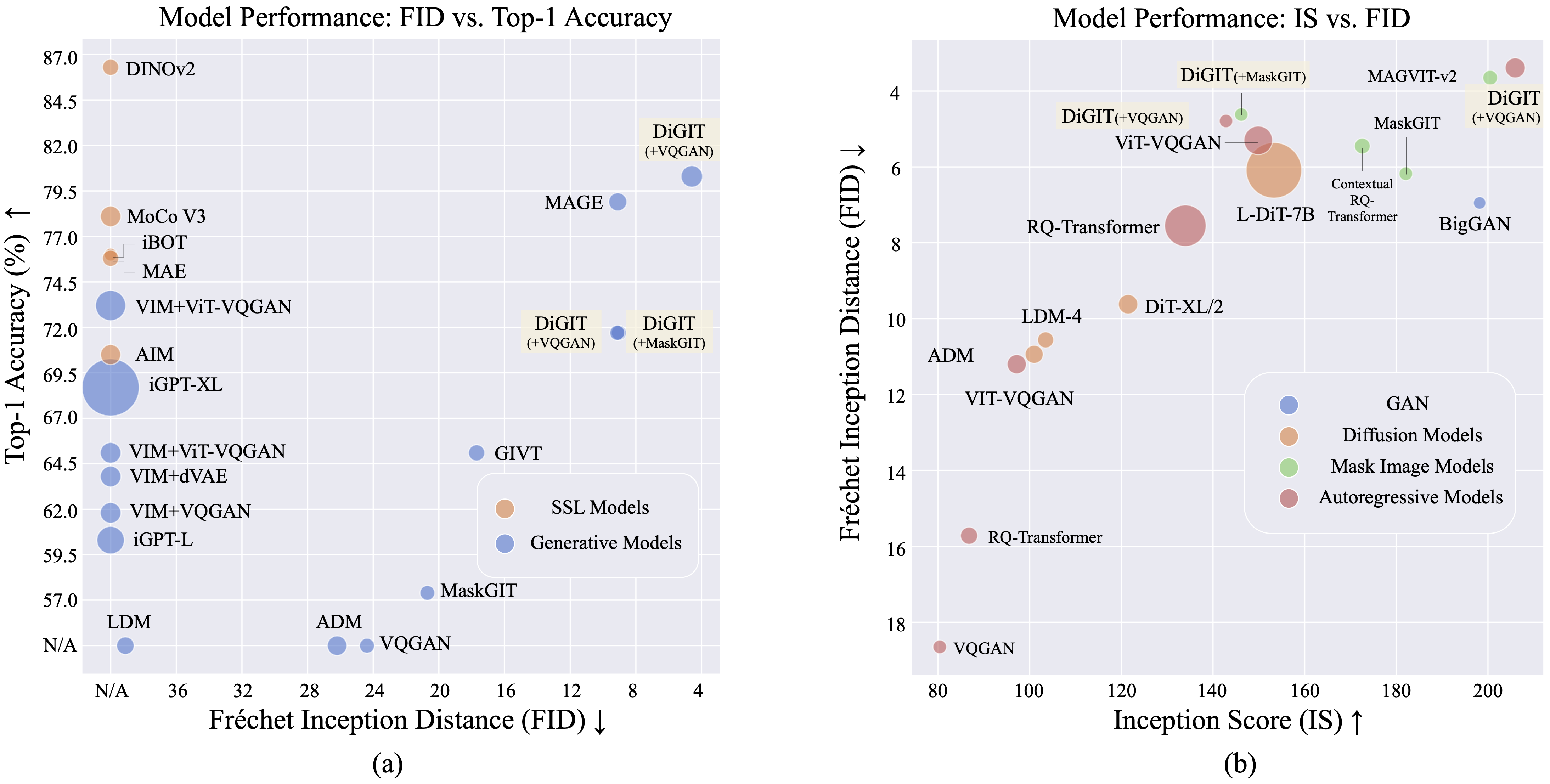
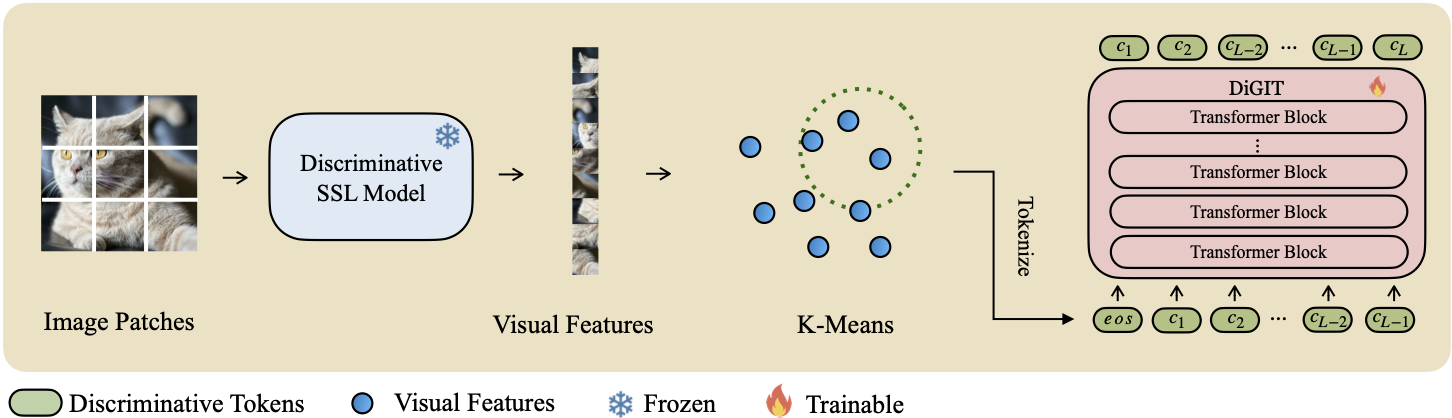
เรานำเสนอ DiGIT ซึ่งเป็นโมเดลการสร้างแบบถดถอยอัตโนมัติซึ่งดำเนินการทำนายโทเค็นถัดไปในพื้นที่แฝงเชิงนามธรรมที่ได้มาจากโมเดลการเรียนรู้แบบควบคุมตนเอง (SSL) ด้วยการใช้การจัดกลุ่ม K-Means บนสถานะที่ซ่อนอยู่ของโมเดล DINOv2 เราจึงสร้างโทเค็นไนเซอร์แยกแบบใหม่ได้อย่างมีประสิทธิภาพ วิธีการนี้ช่วยเพิ่มประสิทธิภาพการสร้างอิมเมจบนชุดข้อมูล ImageNet ได้อย่างมาก โดยได้รับคะแนน FID 4.59 สำหรับงานแบบไม่มีเงื่อนไขในคลาส และ 3.39 สำหรับงานแบบมีเงื่อนไขในคลาส นอกจากนี้ แบบจำลองยังช่วยเพิ่มความเข้าใจเกี่ยวกับภาพ โดยได้รับ ความแม่นยำของโพรบเชิงเส้นที่ 80.3
| วิธีการ | # โทเค็น | คุณสมบัติ | #พาราม | อันดับ 1 บัญชี |
|---|---|---|---|---|
| ไอจีพีที-แอล | 32 | 1536 | 1362ม | 60.3 |
| iGPT-XL | 64 | 3072 | 6801M | 68.7 |
| วิม+VQGAN | 32 | 1,024 | 650ม | 61.8 |
| VIM+dVAE | 32 | 1,024 | 650ม | 63.8 |
| VIM+ViT-VQGAN | 32 | 1,024 | 650ม | 65.1 |
| VIM+ViT-VQGAN | 32 | 2048 | 1697ม | 73.2 |
| จุดมุ่งหมาย | 16 | 1536 | 0.6B | 70.5 |
| ดิจิท (ของเรา) | 16 | 1,024 | 219ม | 71.7 |
| ดิจิท (ของเรา) | 16 | 1536 | 732ม | 80.3 |
| พิมพ์ | วิธีการ | #พาราม | #ยุค | เอฟไอดีเอ | เป็น |
|---|---|---|---|---|---|
| กัน | บิ๊กแกน | 70ม | - | 38.6 | 24.70 |
| ความแตกต่าง | แอลดีเอ็ม | 395ม | - | 39.1 | 22.83 |
| ความแตกต่าง | อดีเอ็ม | 554ม | - | 26.2 | 39.70 |
| มิม | ผู้วิเศษ | 200ม | 1600 | 11.1 | 81.17 |
| มิม | ผู้วิเศษ | 463ม | 1600 | 9.10 | 105.1 |
| มิม | MaskGIT | 227ม | 300 | 20.7 | 42.08 |
| มิม | DigiT (+MaskGIT) | 219ม | 200 | 9.04 | 75.04 |
| เออาร์ | วีคิวแกน | 214ม | 200 | 24.38 | 30.93 |
| เออาร์ | ดิจิท (+VQGAN) | 219ม | 400 | 9.13 | 73.85 |
| เออาร์ | ดิจิท (+VQGAN) | 732ม | 200 | 4.59 | 141.29 |
| พิมพ์ | วิธีการ | #พาราม | #ยุค | เอฟไอดีเอ | เป็น |
|---|---|---|---|---|---|
| กัน | บิ๊กแกน | 160ม | - | 6.95 | 198.2 |
| ความแตกต่าง | อดีเอ็ม | 554ม | - | 10.94 | 101.0 |
| ความแตกต่าง | LDM-4 | 400ม | - | 10.56 | 103.5 |
| ความแตกต่าง | DiT-XL/2 | 675ม | - | 9.62 | 121.50 |
| ความแตกต่าง | แอล-DiT-7B | 7B | - | 6.09 | 153.32 |
| มิม | CQR-ทรานส์ | 371ม | 300 | 5.45 | 172.6 |
| มิม+เออาร์ | วีเออาร์ | 310ม | 200 | 4.64 | - |
| มิม+เออาร์ | วีเออาร์ | 310ม | 200 | 3.60* | 257.5* |
| มิม+เออาร์ | วีเออาร์ | 600ม | 250 | 2.95* | 306.1* |
| มิม | แม็กวิท-v2 | 307ม | 1,080 | 3.65 | 200.5 |
| เออาร์ | VQVAE-2 | 13.5B | - | 31.11 | 45 |
| เออาร์ | RQ-ทรานส์ | 480ม | - | 15.72 | 86.8 |
| เออาร์ | RQ-ทรานส์ | 3.8B | - | 7.55 | 134.0 |
| เออาร์ | ViTVQGAN | 650ม | 360 | 11.20 | 97.2 |
| เออาร์ | ViTVQGAN | 1.7B | 360 | 5.3 | 149.9 |
| มิม | MaskGIT | 227ม | 300 | 6.18 | 182.1 |
| มิม | DigiT (+MaskGIT) | 219ม | 200 | 4.62 | 146.19 |
| เออาร์ | วีคิวแกน | 227ม | 300 | 18.65 | 80.4 |
| เออาร์ | ดิจิท (+VQGAN) | 219ม | 400 | 4.79 | 142.87 |
| เออาร์ | ดิจิท (+VQGAN) | 732ม | 200 | 3.39 | 205.96 |
*: VAR ได้รับการฝึกอบรมโดยมีคำแนะนำที่ไม่ต้องใช้ตัวแยกประเภท ในขณะที่รุ่นอื่นๆ ทั้งหมดไม่ได้รับการฝึกอบรม
คุณสามารถดาวน์โหลดไฟล์ K-Means npy และจุดตรวจสอบโมเดลได้จาก:
| แบบอย่าง | ลิงค์ |
|---|---|
| ตุ้มน้ำหนัก HF? | กอดหน้า |
สำหรับรุ่นพื้นฐาน เราใช้ DINOv2-base และ DINOv2-large สำหรับรุ่นขนาดใหญ่ VQGAN ที่เราใช้นั้นเหมือนกับ MAGE
DiGIT
└── data/
├── ILSVRC2012
├── dinov2_base_short_224_l3
├── km_8k.npy
├── dinov2_large_short_224_l3
├── km_16k.npy
└── outputs/
├── base_8k_stage1
├── ...
└── models/
├── vqgan_jax_strongaug.ckpt
├── dinov2_vitb14_reg4_pretrain.pth
├── dinov2_vitl14_reg4_pretrain.pth
git clone https://github.com/DAMO-NLP-SG/DiGIT.git
cd DiGITfairseq ผ่าน pip install fairseq ดาวน์โหลดชุดข้อมูล ImageNet และวางลงในชุดข้อมูลของคุณ dir $PATH_TO_YOUR_WORKSPACE/dataset/ILSVRC2012
แยกคุณสมบัติ SSL และบันทึกเป็นไฟล์ .npy ใช้อัลกอริธึม K-Means พร้อม fais เพื่อคำนวณเซนทรอยด์ คุณยังสามารถใช้เซนทรอยด์ที่ผ่านการฝึกอบรมมาแล้วบน Huggingface ได้
bash preprocess/run.shขั้นตอนที่ 1
ฝึกฝนโมเดล GPT ด้วยโทเค็นไนเซอร์ที่เลือกปฏิบัติ คุณสามารถค้นหาสคริปต์การฝึกอบรมได้ใน scripts/train_stage1_ar.sh และไฮเปอร์พารามิเตอร์อยู่ใน config/stage1/dino_base.yaml สำหรับการกำหนดค่าการสร้างแบบมีเงื่อนไขของคลาส โปรดดูที่ scripts/train_stage1_classcond.sh
ขั้นตอนที่ 2
ฝึกฝนตัวถอดรหัสพิกเซล (ทั้งรุ่น AR หรือรุ่น NAR) โดยกำหนดเงื่อนไขบนโทเค็นที่เลือกปฏิบัติ คุณสามารถค้นหาสคริปต์การฝึกอบรมแบบ autoregressive ได้ใน scripts/train_stage2_ar.sh และสคริปต์การฝึกอบรม NAR ใน scripts/train_stage2_nar.sh
โฟลเดอร์ชื่อ outputs/EXP_NAME/checkpoints จะถูกสร้างขึ้นเพื่อบันทึกจุดตรวจสอบ ไฟล์บันทึกของ TensorBoard จะถูกบันทึกไว้ที่ outputs/EXP_NAME/tb บันทึกจะถูกบันทึกไว้ใน outputs/EXP_NAME/train.log
คุณสามารถตรวจสอบกระบวนการฝึกอบรมได้โดยใช้ tensorboard --logdir=outputs/EXP_NAME/tb
สุ่มตัวอย่างโทเค็นการเลือกปฏิบัติครั้งแรกด้วย scripts/infer_stage1_ar.sh สำหรับขนาดโมเดลพื้นฐาน เราแนะนำให้ตั้งค่า topk=200 และสำหรับขนาดโมเดลขนาดใหญ่ ให้ใช้ topk=400
จากนั้นรัน scripts/infer_stage2_ar.sh เพื่อสุ่มตัวอย่างโทเค็น VQ โดยอิงตามโทเค็นที่เลือกปฏิบัติที่สุ่มตัวอย่างไว้ก่อนหน้านี้
โทเค็นที่สร้างขึ้นและรูปภาพที่สังเคราะห์จะถูกจัดเก็บไว้ในไดเร็กทอรีชื่อ outputs/EXP_NAME/results
เตรียมชุดการตรวจสอบ ImageNet สำหรับการประเมิน FID:
python prepare_imgnet_val.py --data_path $PATH_TO_YOUR_WORKSPACE /dataset/ILSVRC2012 --output_dir imagenet-val ติดตั้งเครื่องมือประเมินผลโดยการรัน pip install torch-fidelity
ดำเนินการคำสั่งต่อไปนี้เพื่อประเมิน FID:
python fairseq_user/eval_fid.py --results-path $IMG_SAVE_DIR --subset $GEN_SUBSETbash scripts/train_stage1_linearprobe.shโครงการนี้ได้รับอนุญาตภายใต้ใบอนุญาต MIT - ดูรายละเอียดในไฟล์ใบอนุญาต
หากคุณพบว่าโครงการของเรามีประโยชน์ หวังว่าคุณจะติดดาว repo ของเราและอ้างอิงงานของเราดังต่อไปนี้
@misc { zhu2024stabilize ,
title = { Stabilize the Latent Space for Image Autoregressive Modeling: A Unified Perspective } ,
author = { Yongxin Zhu and Bocheng Li and Hang Zhang and Xin Li and Linli Xu and Lidong Bing } ,
year = { 2024 } ,
eprint = { 2410.12490 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
}

