FasterTransformer
v5.3 release
หมายเหตุ: การพัฒนา FasterTransformer ได้เปลี่ยนไปเป็น TensorRT-LLM แล้ว เราสนับสนุนให้นักพัฒนาทุกคนใช้ประโยชน์จาก TensorRT-LLM เพื่อรับการปรับปรุงล่าสุดเกี่ยวกับการอนุมาน LLM NVIDIA/FasterTransformer repo จะยังคงดำเนินต่อไป แต่จะไม่มีการพัฒนาเพิ่มเติม
พื้นที่เก็บข้อมูลนี้มีสคริปต์และสูตรในการรันส่วนประกอบตัวเข้ารหัสและตัวถอดรหัสที่ใช้หม้อแปลงที่ได้รับการปรับปรุงประสิทธิภาพสูงสุด และได้รับการทดสอบและบำรุงรักษาโดย NVIDIA
ใน NLP ตัวเข้ารหัสและตัวถอดรหัสเป็นองค์ประกอบที่สำคัญสองประการ โดยชั้นหม้อแปลงกลายเป็นสถาปัตยกรรมยอดนิยมสำหรับส่วนประกอบทั้งสอง FasterTransformer ใช้เลเยอร์หม้อแปลงที่ได้รับการปรับปรุงประสิทธิภาพสูงสุดสำหรับทั้งตัวเข้ารหัสและตัวถอดรหัสสำหรับการอนุมาน บน GPU Volta, Turing และ Ampere พลังการประมวลผลของ Tensor Core จะถูกใช้โดยอัตโนมัติเมื่อความแม่นยำของข้อมูลและน้ำหนักอยู่ที่ FP16
FasterTransformer สร้างขึ้นจาก CUDA, cuBLAS, cuBLASLt และ C++ เรามี API ของเฟรมเวิร์กต่อไปนี้อย่างน้อยหนึ่งรายการ: แบ็กเอนด์ TensorFlow, PyTorch และ Triton ผู้ใช้สามารถรวม FasterTransformer เข้ากับเฟรมเวิร์กเหล่านี้ได้โดยตรง สำหรับเฟรมเวิร์กที่รองรับ เรายังจัดเตรียมโค้ดตัวอย่างเพื่อสาธิตวิธีใช้งาน และแสดงประสิทธิภาพบนเฟรมเวิร์กเหล่านี้
| โมเดล | กรอบ | FP16 | INT8 (หลังทัวริง) | ความกระจัดกระจาย (หลังแอมแปร์) | เทนเซอร์ขนาน | ท่อขนาน | FP8 (หลังฮอปเปอร์) |
|---|---|---|---|---|---|---|---|
| เบิร์ต | เทนเซอร์โฟลว์ | ใช่ | ใช่ | - | - | - | - |
| เบิร์ต | ไพทอร์ช | ใช่ | ใช่ | ใช่ | ใช่ | ใช่ | - |
| เบิร์ต | แบ็กเอนด์ไทรทัน | ใช่ | - | - | ใช่ | ใช่ | - |
| เบิร์ต | ซี++ | ใช่ | ใช่ | - | - | - | ใช่ |
| XLNet | ซี++ | ใช่ | - | - | - | - | - |
| ตัวเข้ารหัส | เทนเซอร์โฟลว์ | ใช่ | ใช่ | - | - | - | - |
| ตัวเข้ารหัส | ไพทอร์ช | ใช่ | ใช่ | ใช่ | - | - | - |
| เครื่องถอดรหัส | เทนเซอร์โฟลว์ | ใช่ | - | - | - | - | - |
| เครื่องถอดรหัส | ไพทอร์ช | ใช่ | - | - | - | - | - |
| การถอดรหัส | เทนเซอร์โฟลว์ | ใช่ | - | - | - | - | - |
| การถอดรหัส | ไพทอร์ช | ใช่ | - | - | - | - | - |
| GPT | เทนเซอร์โฟลว์ | ใช่ | - | - | - | - | - |
| GPT/เลือก | ไพทอร์ช | ใช่ | - | - | ใช่ | ใช่ | ใช่ |
| GPT/เลือก | แบ็กเอนด์ไทรทัน | ใช่ | - | - | ใช่ | ใช่ | - |
| GPT-MoE | ไพทอร์ช | ใช่ | - | - | ใช่ | ใช่ | - |
| บลูม | ไพทอร์ช | ใช่ | - | - | ใช่ | ใช่ | - |
| บลูม | แบ็กเอนด์ไทรทัน | ใช่ | - | - | ใช่ | ใช่ | - |
| GPT-เจ | แบ็กเอนด์ไทรทัน | ใช่ | - | - | ใช่ | ใช่ | - |
| อดีต | ไพทอร์ช | ใช่ | - | - | - | - | - |
| T5/UL2 | ไพทอร์ช | ใช่ | - | - | ใช่ | ใช่ | - |
| T5 | เทนเซอร์โฟลว์ 2 | ใช่ | - | - | - | - | - |
| T5/UL2 | แบ็กเอนด์ไทรทัน | ใช่ | - | - | ใช่ | ใช่ | - |
| T5 | TensorRT | ใช่ | - | - | ใช่ | ใช่ | - |
| T5-MoE | ไพทอร์ช | ใช่ | - | - | ใช่ | ใช่ | - |
| หม้อแปลงสวิน | ไพทอร์ช | ใช่ | ใช่ | - | - | - | - |
| หม้อแปลงสวิน | TensorRT | ใช่ | ใช่ | - | - | - | - |
| ไวที | ไพทอร์ช | ใช่ | ใช่ | - | - | - | - |
| ไวที | TensorRT | ใช่ | ใช่ | - | - | - | - |
| GPT-นีโอเอ็กซ์ | ไพทอร์ช | ใช่ | - | - | ใช่ | ใช่ | - |
| GPT-นีโอเอ็กซ์ | แบ็กเอนด์ไทรทัน | ใช่ | - | - | ใช่ | ใช่ | - |
| บาร์ต/เอ็มบาร์ต | ไพทอร์ช | ใช่ | - | - | ใช่ | ใช่ | - |
| วีเน็ต | ซี++ | ใช่ | - | - | - | - | - |
| เดเบอร์ต้า | เทนเซอร์โฟลว์ 2 | ใช่ | - | - | กำลังดำเนินการอยู่ | กำลังดำเนินการอยู่ | - |
| เดเบอร์ต้า | ไพทอร์ช | ใช่ | - | - | กำลังดำเนินการอยู่ | กำลังดำเนินการอยู่ | - |
รายละเอียดเพิ่มเติมของรุ่นเฉพาะอยู่ใน xxx_guide.md ของ docs/ โดยที่ xxx หมายถึงชื่อรุ่น คำถามทั่วไปและคำตอบที่เกี่ยวข้องจะอยู่ใน docs/QAList.md โปรดทราบว่าโมเดลของ Encoder และ BERT มีความคล้ายคลึงกัน และเรารวมคำอธิบายไว้ใน bert_guide.md ไว้ด้วยกัน
รหัสต่อไปนี้แสดงรายการโครงสร้างไดเร็กทอรีของ FasterTransformer:
/src/fastertransformer: source code of FasterTransformer
|--/cutlass_extensions: Implementation of cutlass gemm/kernels.
|--/kernels: CUDA kernels for different models/layers and operations, like addBiasResiual.
|--/layers: Implementation of layer modules, like attention layer, ffn layer.
|--/models: Implementation of different models, like BERT, GPT.
|--/tensorrt_plugin: encapluate FasterTransformer into TensorRT plugin.
|--/tf_op: custom Tensorflow OP implementation
|--/th_op: custom PyTorch OP implementation
|--/triton_backend: custom triton backend implementation
|--/utils: Contains common cuda utils, like cublasMMWrapper, memory_utils
/examples: C++, tensorflow and pytorch interface examples
|--/cpp: C++ interface examples
|--/pytorch: PyTorch OP examples
|--/tensorflow: TensorFlow OP examples
|--/tensorrt: TensorRT examples
/docs: Documents to explain the details of implementation of different models, and show the benchmark
/benchmark: Contains the scripts to run the benchmarks of different models
/tests: Unit tests
/templates: Documents to explain how to add a new model/example into FasterTransformer repo
โปรดทราบว่าหลายโฟลเดอร์มีโฟลเดอร์ย่อยจำนวนมากสำหรับแยกรุ่นต่างๆ เครื่องมือการหาปริมาณจะถูกย้ายไปที่ examples เช่น examples/tensorflow/bert/bert-quantization/ และ examples/pytorch/bert/bert-quantization-sparsity/
FasterTransformer มีตัวแปรสภาพแวดล้อมที่สะดวกสำหรับการดีบักและการทดสอบ
FT_LOG_LEVEL : สภาพแวดล้อมนี้ควบคุมระดับบันทึกของข้อความแก้ไขข้อบกพร่อง รายละเอียดเพิ่มเติมอยู่ใน src/fastertransformer/utils/logger.h โปรดทราบว่าโปรแกรมจะพิมพ์ข้อความจำนวนมากเมื่อระดับต่ำกว่า DEBUG และโปรแกรมจะทำงานช้ามากFT_NVTX : หากตั้งค่าเป็น ON เช่น FT_NVTX=ON ./bin/gpt_example โปรแกรมจะแทรกแท็ก tha ของ nvtx เพื่อช่วยในการสร้างโปรไฟล์โปรแกรมFT_DEBUG_LEVEL : หากตั้งค่าเป็น DEBUG โปรแกรมจะรัน cudaDeviceSynchronize() หลังจากทุกเคอร์เนล มิฉะนั้น เคอร์เนลจะถูกดำเนินการแบบอะซิงโครนัสตามค่าเริ่มต้น การค้นหาจุดข้อผิดพลาดระหว่างการดีบักจะเป็นประโยชน์ แต่แฟล็กนี้ส่งผลต่อประสิทธิภาพของโปรแกรมอย่างมาก ดังนั้นจึงควรใช้สำหรับการดีบักเท่านั้น การตั้งค่าฮาร์ดแวร์:
เพื่อรันการวัดประสิทธิภาพต่อไปนี้ เราจำเป็นต้องติดตั้งเครื่องมือคำนวณยูนิกซ์ "bc" ภายใน
apt-get install bc ผลลัพธ์ FP16 ของ TensorFlow ได้มาจากการดำเนินการ benchmarks/bert/tf_benchmark.sh
ผลลัพธ์ INT8 ของ TensorFlow ได้มาจากการรัน benchmarks/bert/tf_int8_benchmark.sh
ผลลัพธ์ FP16 ของ PyTorch ได้มาจากการรัน benchmarks/bert/pyt_benchmark.sh
ผลลัพธ์ INT8 ของ PyTorch ได้มาจากการรัน benchmarks/bert/pyt_int8_benchmark.sh
มีการวางเกณฑ์มาตรฐานเพิ่มเติมใน docs/bert_guide.md
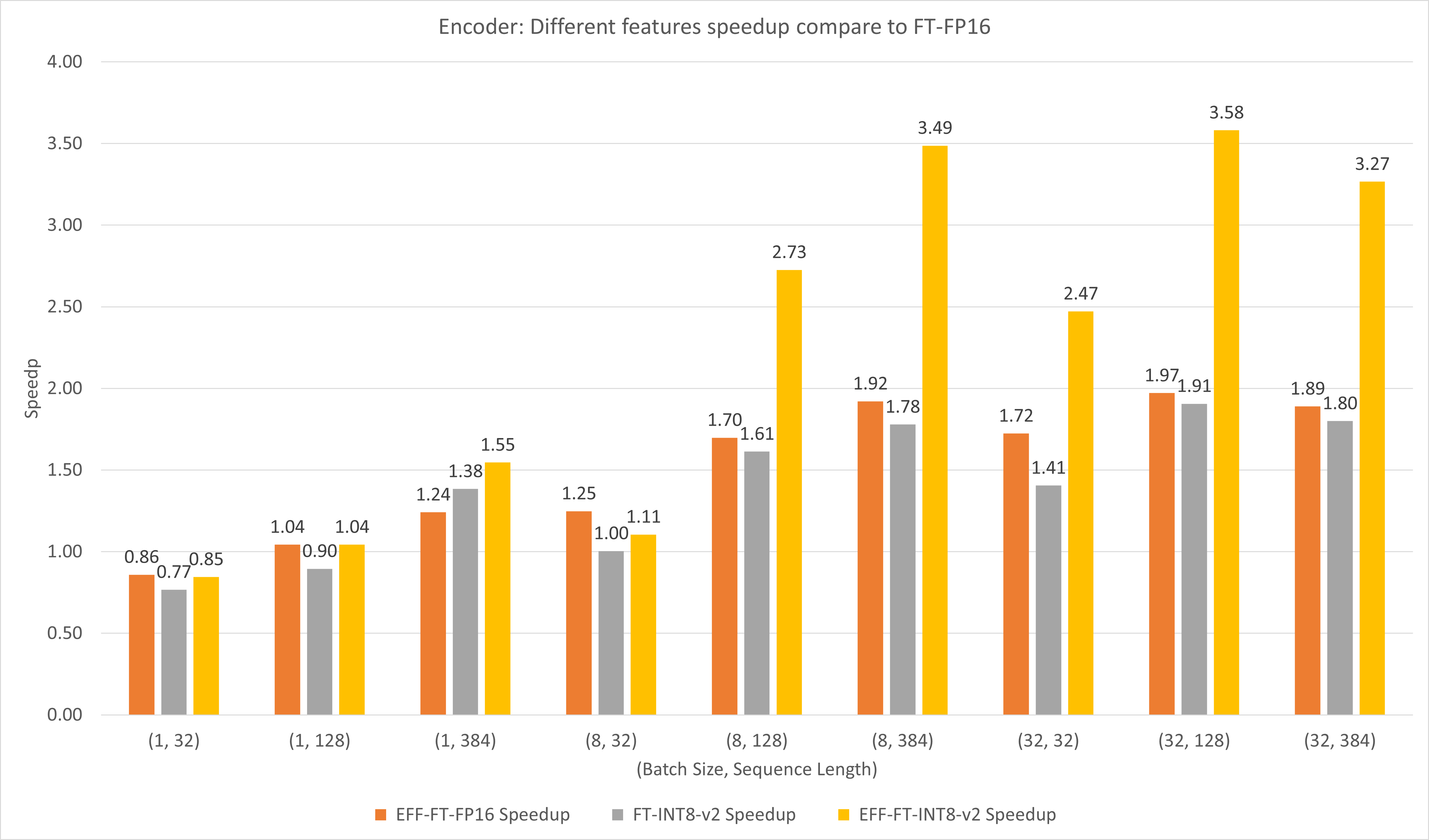
รูปต่อไปนี้เปรียบเทียบประสิทธิภาพของฟีเจอร์ต่างๆ ของ FasterTransformer และ FasterTransformer ภายใต้ FP16 บน T4
สำหรับขนาดแบทช์ขนาดใหญ่และความยาวลำดับ ทั้ง EFF-FT และ FT-INT8-v2 จะให้ความเร็วเพิ่มขึ้นประมาณ 2 เท่า การใช้ FasterTransformer และ int8v2 ที่มีประสิทธิภาพพร้อมกันสามารถเร่งความเร็วได้ประมาณ 3.5 เท่า เมื่อเทียบกับ FasterTransformer FP16 สำหรับเคสขนาดใหญ่
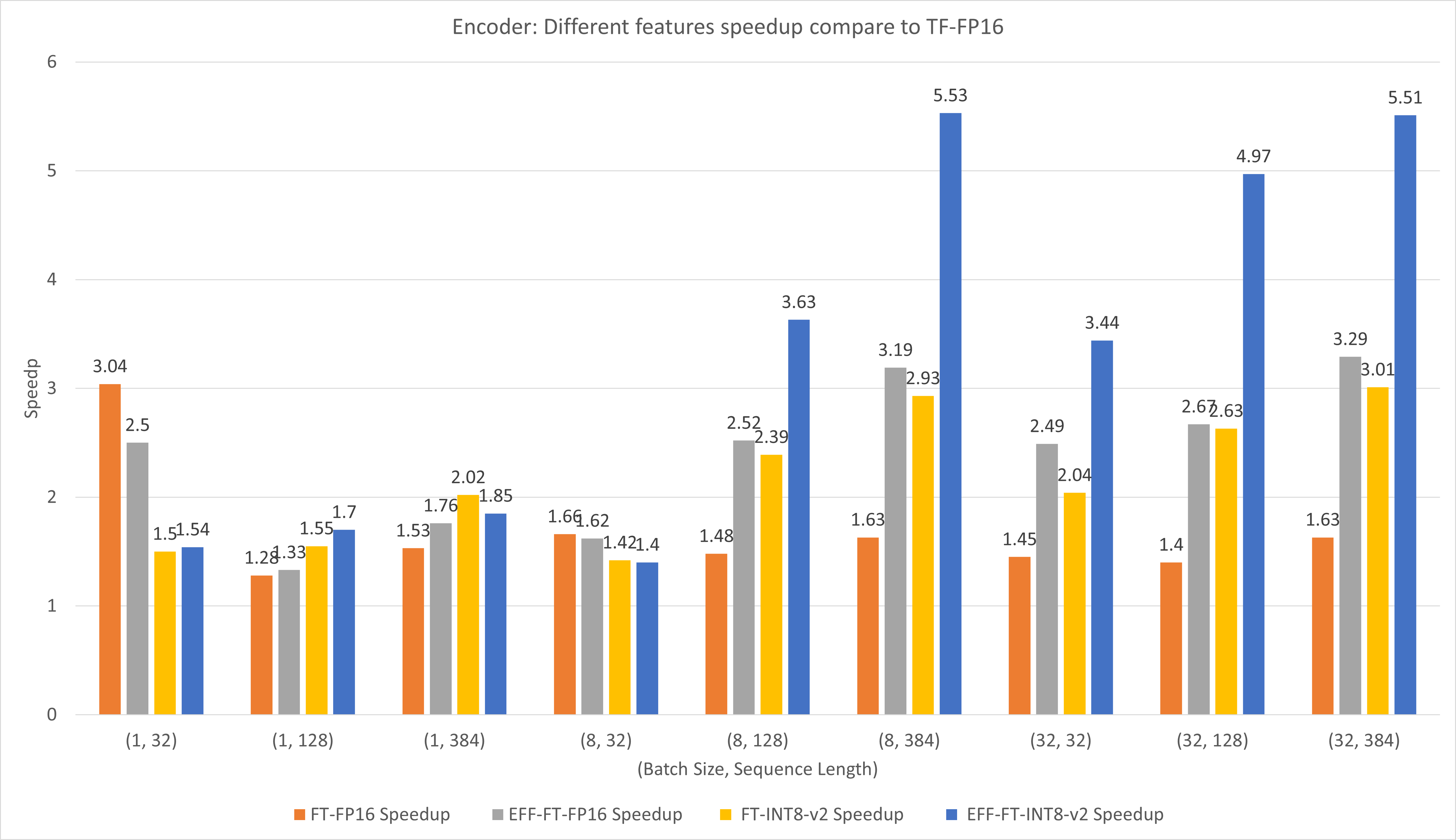
รูปต่อไปนี้เปรียบเทียบประสิทธิภาพของฟีเจอร์ต่างๆ ของ FasterTransformer และ TensorFlow XLA ภายใต้ FP16 บน T4
สำหรับขนาดแบตช์ขนาดเล็กและความยาวของลำดับ การใช้ FasterTransformer สามารถเพิ่มความเร็วได้ประมาณ 3 เท่า
สำหรับขนาดแบทช์ขนาดใหญ่และความยาวลำดับ การใช้ Effective FasterTransformer พร้อมการหาปริมาณ INT8-v2 จะทำให้เร่งความเร็วได้ประมาณ 5 เท่า
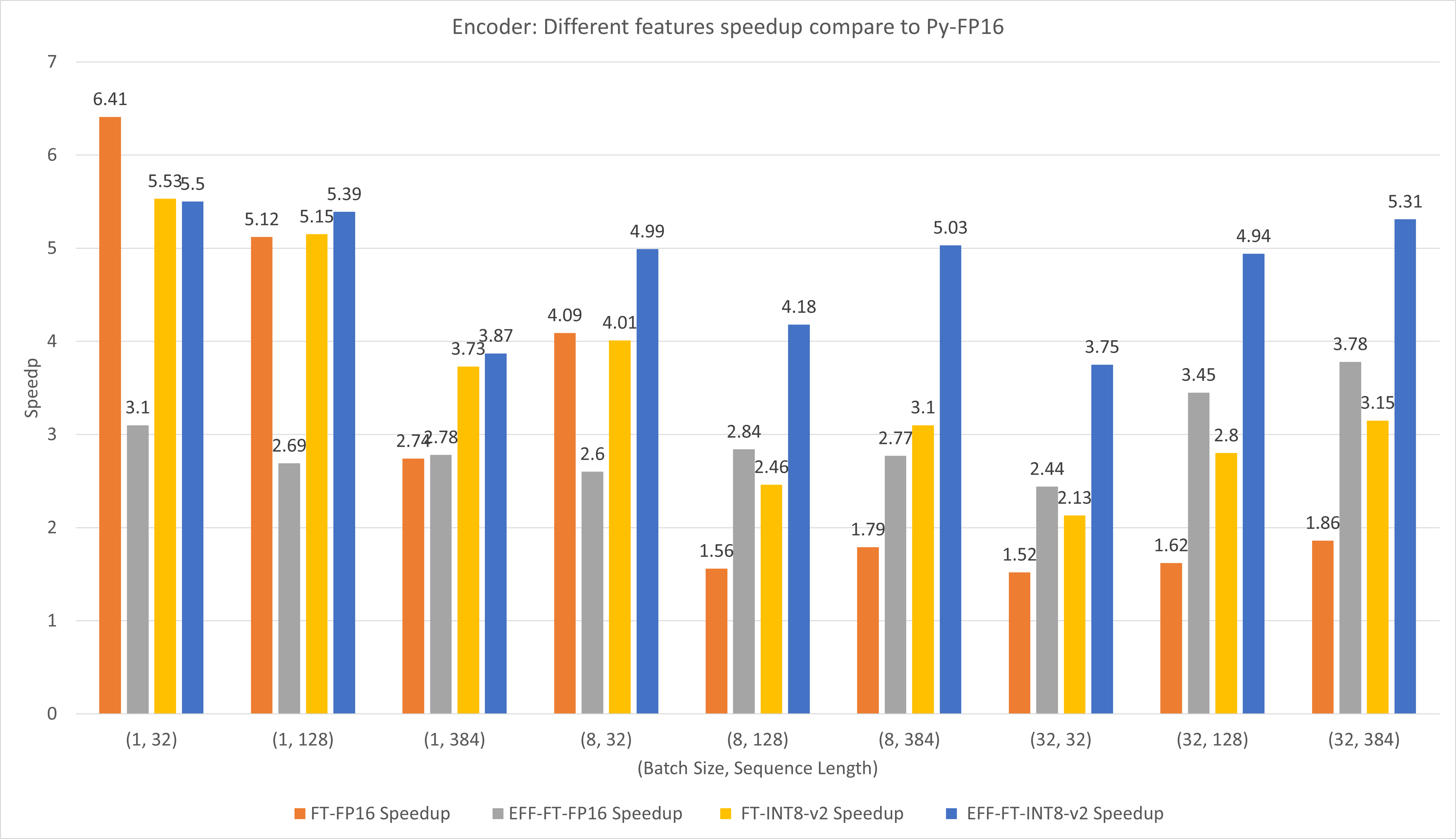
รูปต่อไปนี้เปรียบเทียบประสิทธิภาพของฟีเจอร์ต่างๆ ของ FasterTransformer และ PyTorch TorchScript ภายใต้ FP16 บน T4
สำหรับขนาดแบตช์ขนาดเล็กและความยาวของลำดับ การใช้ FasterTransformer CustomExt สามารถทำให้เร่งความเร็วได้ประมาณ 4x ~ 6x
สำหรับขนาดแบทช์ขนาดใหญ่และความยาวของลำดับ การใช้ Effective FasterTransformer พร้อมการหาปริมาณ INT8-v2 จะทำให้เร่งความเร็วได้ประมาณ 5 เท่า
ผลลัพธ์ของ TensorFlow ได้มาจากการรัน benchmarks/decoding/tf_decoding_beamsearch_benchmark.sh และ benchmarks/decoding/tf_decoding_sampling_benchmark.sh
ผลลัพธ์ของ PyTorch ได้มาจากการรัน benchmarks/decoding/pyt_decoding_beamsearch_benchmark.sh
ในการทดลองถอดรหัส เราได้อัปเดตพารามิเตอร์ต่อไปนี้:
มีการวางเกณฑ์มาตรฐานเพิ่มเติมใน docs/decoder_guide.md
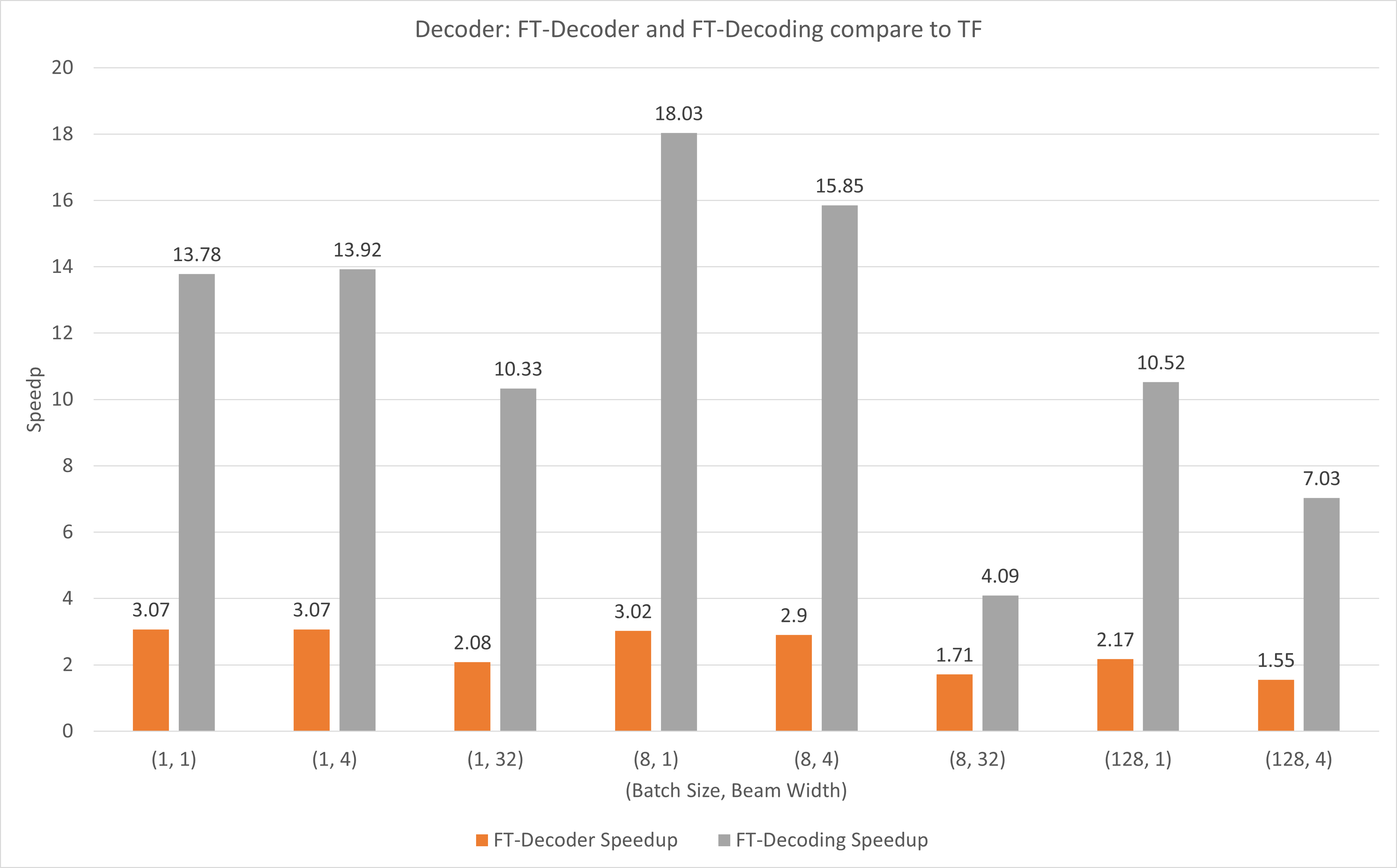
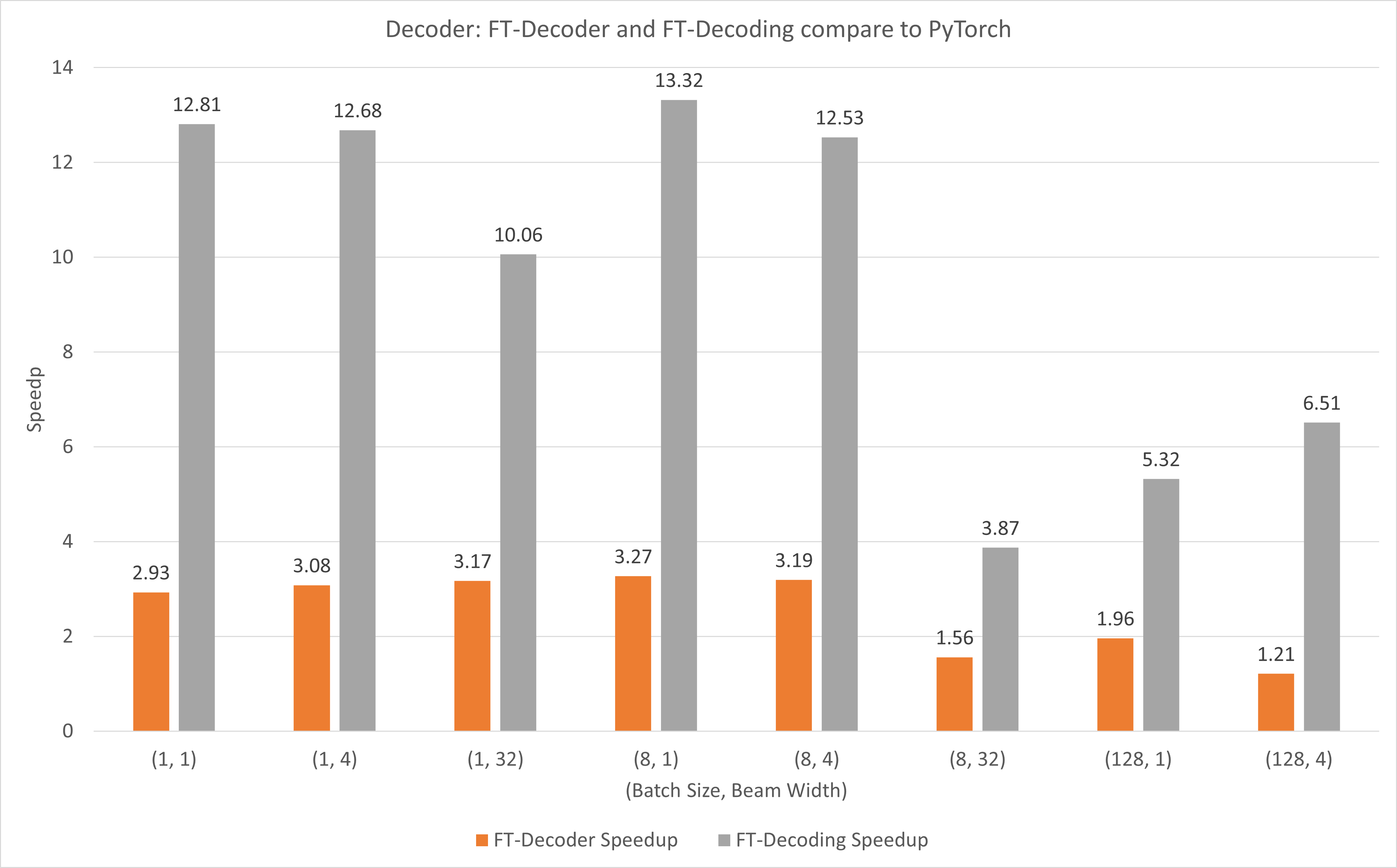
รูปต่อไปนี้แสดงการเร่งความเร็วของ FT-Decoder op และ FT-Decoding op เมื่อเปรียบเทียบกับ TensorFlow ภายใต้ FP16 พร้อม T4 ที่นี่ เราใช้ทรูพุตของการแปลชุดทดสอบเพื่อป้องกันไม่ให้โทเค็นทั้งหมดของแต่ละวิธีอาจแตกต่างกัน เมื่อเปรียบเทียบกับ TensorFlow แล้ว FT-Decoder ให้ความเร็วเพิ่มขึ้น 1.5x ~ 3x; ในขณะที่การถอดรหัส FT ให้การเร่งความเร็ว 4x ~ 18x
รูปต่อไปนี้แสดงการเร่งความเร็วของ FT-Decoder op และ FT-Decoding op เมื่อเปรียบเทียบกับ PyTorch ภายใต้ FP16 พร้อม T4 ที่นี่ เราใช้ทรูพุตของการแปลชุดทดสอบเพื่อป้องกันไม่ให้โทเค็นทั้งหมดของแต่ละวิธีอาจแตกต่างกัน เมื่อเทียบกับ PyTorch แล้ว FT-Decoder ให้ความเร็วเพิ่มขึ้น 1.2x ~ 3x; ในขณะที่การถอดรหัส FT ให้การเร่งความเร็ว 3.8x ~ 13x
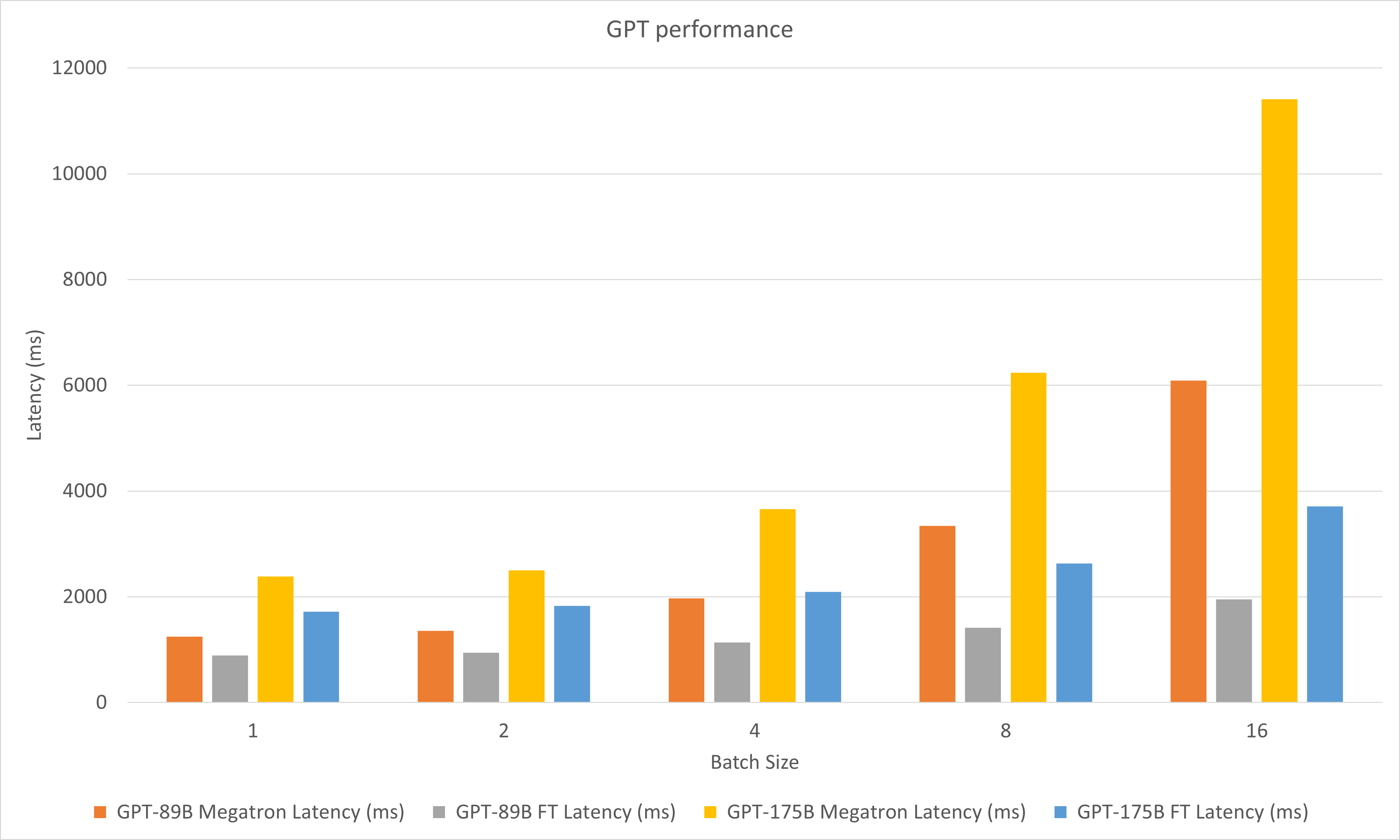
รูปต่อไปนี้เปรียบเทียบประสิทธิภาพของ Megatron และ FasterTransformer ภายใต้ FP16 บน A100
ในการทดลองถอดรหัส เราได้อัปเดตพารามิเตอร์ต่อไปนี้:
พฤษภาคม 2023
มกราคม 2023
ธันวาคม 2022
พ.ย. 2022
ต.ค. 2022
ก.ย. 2022
ส.ค. 2022
กรกฎาคม 2022
มิถุนายน 2565
พฤษภาคม 2022
เมษายน 2022
มีนาคม 2565
stop_ids และ ban_bad_ids ใน GPT-Jstart_id และ end_id ใน GPT-J, GPT, T5 และการถอดรหัสกุมภาพันธ์ 2022
ธันวาคม 2021
พฤศจิกายน 2021
สิงหาคม 2021
layer_para เป็น pipeline_parasize_per_head 96, 160, 192, 224, 256 สำหรับรุ่น GPTมิถุนายน 2021
เมษายน 2021
ธ.ค. 2020
พ.ย. 2020
ก.ย. 2020
ส.ค. 2020
มิถุนายน 2020
พฤษภาคม 2020
translate_sample.pyเมษายน 2020
decoding_opennmt.h เป็น decoding_beamsearch.hdecoding_sampling.hbert_transformer_op.h , bert_transformer_op.cu.cc เข้ากับ bert_transformer_op.ccdecoder.h , decoder.cu.cc เข้ากับ decoder.ccdecoding_beamsearch.h , decoding_beamsearch.cu.cc เข้ากับ decoding_beamsearch.ccbleu_score.py ลงใน utils โปรดทราบว่าคะแนน BLEU ต้องใช้ python3มีนาคม 2020
translate_sample.py เพื่อสาธิตวิธีการแปลประโยคโดยการกู้คืนโมเดล OpenNMT-tf ที่ฝึกไว้ล่วงหน้ากุมภาพันธ์ 2020
กรกฎาคม 2019
import torch ก่อน หากทำเช่นนี้ อาจเป็นเพราะ C++ ABI ที่เข้ากันไม่ได้ คุณอาจต้องตรวจสอบว่า PyTorch ที่ใช้ในระหว่างการคอมไพล์และดำเนินการเหมือนกัน หรือคุณต้องตรวจสอบว่าการคอมไพล์ PyTorch ของคุณเป็นอย่างไร หรือเวอร์ชันของ GCC ของคุณ ฯลฯ

