PatrickStar
v0.4.6

ดูที่ CHANGE_LOG.md
โมเดลที่ได้รับการฝึกอบรมล่วงหน้า (PTM) กำลังกลายเป็นจุดสำคัญของทั้งการวิจัย NLP และการประยุกต์ใช้ในอุตสาหกรรม อย่างไรก็ตาม การฝึกอบรม PTM ต้องใช้ทรัพยากรฮาร์ดแวร์จำนวนมหาศาล ทำให้มีเพียงคนส่วนน้อยในชุมชน AI เท่านั้นที่สามารถเข้าถึงได้ ตอนนี้ PatrickStar จะทำให้ทุกคนสามารถใช้การฝึกอบรม PTM ได้!
ข้อผิดพลาดหน่วยความจำไม่เพียงพอ (OOM) เป็นฝันร้ายของวิศวกรทุกคนในการฝึกอบรม PTM เรามักจะต้องแนะนำ GPU มากขึ้นเพื่อจัดเก็บพารามิเตอร์โมเดลเพื่อป้องกันข้อผิดพลาดดังกล่าว PatrickStar นำเสนอวิธีแก้ปัญหาที่ดีกว่าสำหรับปัญหาดังกล่าว ด้วย การฝึกแบบต่างกัน (DeepSpeed Zero Stage 3 ก็ใช้เช่นกัน) PatrickStar สามารถใช้ทั้งหน่วยความจำ CPU และ GPU ได้อย่างเต็มที่ เพื่อให้คุณสามารถใช้ GPU น้อยลงในการฝึกโมเดลขนาดใหญ่
ความคิดของแพทริคเป็นแบบนี้ ข้อมูลที่ไม่ใช่โมเดล (การเปิดใช้งานเป็นหลัก) จะแตกต่างกันไปในระหว่างการฝึก แต่โซลูชันการฝึกแบบต่างกันในปัจจุบันจะแยกข้อมูลโมเดลออกเป็น CPU และ GPU แบบคงที่ เพื่อใช้ GPU ได้ดียิ่งขึ้น PatrickStar เสนอการตั้งเวลาหน่วยความจำ แบบไดนามิก ด้วยความช่วยเหลือของโมดูลการจัดการหน่วยความจำแบบก้อน การจัดการหน่วยความจำของ PatrickStar รองรับการถ่ายโอนทุกอย่างยกเว้นส่วนการประมวลผลปัจจุบันของโมเดลไปยัง CPU เพื่อประหยัด GPU นอกจากนี้ การจัดการหน่วยความจำแบบก้อนยังมีประสิทธิภาพสำหรับการสื่อสารแบบรวมเมื่อปรับขนาดเป็น GPU หลายตัว ดูบทความและเอกสารนี้สำหรับแนวคิดเบื้องหลัง PatrickStar
ในการทดลอง Patrickstar v0.4.3 สามารถฝึกโมเดลพารามิเตอร์ 18 พันล้าน (18B) ด้วย 8xTesla V100 GPU และหน่วยความจำ GPU 240GB ในโหนดศูนย์ข้อมูล WeChat ซึ่งมีโทโพโลยีเครือข่ายเป็นแบบนี้ PatrickStar มีขนาดใหญ่เป็นสองเท่าของ DeepSpeed และประสิทธิภาพของ PatrickStar ก็ดีกว่าสำหรับรุ่นที่มีขนาดเท่ากันเช่นกัน pstar คือ PatrickStar v0.4.3 ระดับความลึกบ่งบอกถึงประสิทธิภาพของ DeepSpeed v0.4.3 โดยใช้ตัวอย่างอย่างเป็นทางการของตัวอย่าง DeepSpeed ระดับศูนย์ 3 พร้อมการเปิดการเพิ่มประสิทธิภาพการเปิดใช้งานตามค่าเริ่มต้น

นอกจากนี้เรายังประเมิน PatrickStar v0.4.3 บนโหนดเดียวของ A100 SuperPod สามารถฝึกรุ่น 68B บน 8xA100 พร้อมหน่วยความจำ CPU ขนาด 1TB ซึ่งใหญ่กว่า DeepSpeed v0.5.7 ถึง 6 เท่า นอกจากขนาดของโมเดลแล้ว PatrickStar ยังมีประสิทธิภาพมากกว่า DeepSpeed อีกด้วย สคริปต์มาตรฐานอยู่ที่นี่

ผลลัพธ์การวัดประสิทธิภาพโดยละเอียดของศูนย์ข้อมูล WeChat AI และ NVIDIA SuperPod ได้รับการโพสต์บน Google Doc นี้
ปรับขนาด PatrickStar ไปยังหลายเครื่อง (โหนด) บน SuperPod เราประสบความสำเร็จในการฝึก GPT3-175B บน 32 GPU เท่าที่เราทราบ นี่เป็นงานแรกที่ใช้ GPT3 บนคลัสเตอร์ GPU ขนาดเล็กเช่นนี้ Microsoft ใช้ 10,000 V100 เพื่อเกี่ยวข้องกับ GPT3 ตอนนี้คุณสามารถปรับแต่งหรือฝึกล่วงหน้าของคุณเองด้วย 32 A100 GPU ได้แล้ว น่าทึ่งมาก!

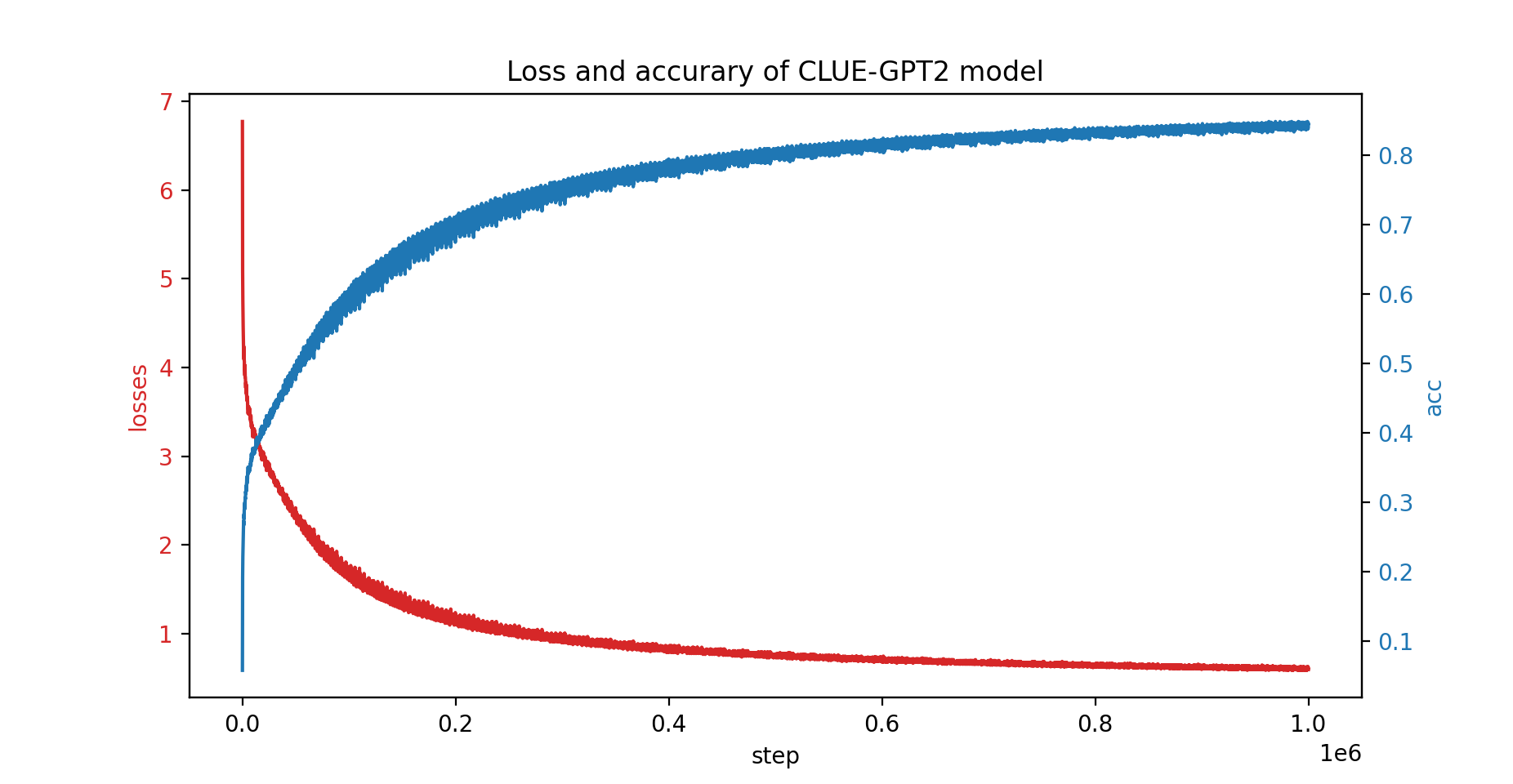
นอกจากนี้เรายังได้ฝึกโมเดล CLUE-GPT2 กับ PatrickStar อีกด้วย โดยกราฟการสูญเสียและความแม่นยำแสดงอยู่ด้านล่าง:
pip install .โปรดทราบว่า PatrickStar ต้องใช้ gcc เวอร์ชัน 7 ขึ้นไป คุณยังสามารถใช้อิมเมจ NVIDIA NGC ได้ รูปภาพต่อไปนี้ได้รับการทดสอบ:
docker pull nvcr.io/nvidia/pytorch:21.06-py3PatrickStar ทำงานบน PyTorch ทำให้ง่ายต่อการโยกย้ายโปรเจ็กต์ pytorch นี่คือตัวอย่างของ PatrickStar:
from patrickstar . runtime import initialize_engine
config = {
"optimizer" : {
"type" : "Adam" ,
"params" : {
"lr" : 0.001 ,
"betas" : ( 0.9 , 0.999 ),
"eps" : 1e-6 ,
"weight_decay" : 0 ,
"use_hybrid_adam" : True ,
},
},
"fp16" : { # loss scaler params
"enabled" : True ,
"loss_scale" : 0 ,
"initial_scale_power" : 2 ** 3 ,
"loss_scale_window" : 1000 ,
"hysteresis" : 2 ,
"min_loss_scale" : 1 ,
},
"default_chunk_size" : 64 * 1024 * 1024 ,
"release_after_init" : True ,
"use_cpu_embedding" : False ,
"client" : {
"mem_tracer" : {
"use_async_mem_monitor" : args . with_async_mem_monitor ,
}
},
}
def model_func ():
# MyModel is a derived class for torch.nn.Module
return MyModel (...)
model , optimizer = initialize_engine ( model_func = model_func , local_rank = 0 , config = config )
...
for data in dataloader :
optimizer . zero_grad ()
loss = model ( data )
model . backward ( loss )
optimizer . step () เราใช้รูปแบบ config เดียวกันกับการกำหนดค่า DeepSpeed JSON ซึ่งส่วนใหญ่ประกอบด้วยพารามิเตอร์ของเครื่องมือเพิ่มประสิทธิภาพ ตัวปรับขนาดการสูญเสีย และการกำหนดค่าเฉพาะของ PatrickStar บางส่วน
สำหรับคำอธิบายโดยละเอียดของตัวอย่างข้างต้น โปรดอ่านคำแนะนำที่นี่
สำหรับตัวอย่างเพิ่มเติม โปรดตรวจสอบที่นี่
สคริปต์วัดประสิทธิภาพการเริ่มต้นอย่างรวดเร็วอยู่ที่นี่ มันถูกดำเนินการด้วยข้อมูลที่สร้างขึ้นแบบสุ่ม จึงไม่จำเป็นต้องเตรียมข้อมูลจริง นอกจากนี้ยังสาธิตเทคนิคการปรับให้เหมาะสมทั้งหมดสำหรับ patrickstar สำหรับเคล็ดลับการปรับให้เหมาะสมเพิ่มเติมที่ใช้เกณฑ์มาตรฐาน โปรดดูตัวเลือกการปรับให้เหมาะสม
สิทธิ์การใช้งาน BSD 3 ข้อ
@article{fang2021patrickstar,
title={PatrickStar: Parallel Training of Pre-trained Models via a Chunk-based Memory Management},
author={Fang, Jiarui and Yu, Yang and Zhu, Zilin and Li, Shenggui and You, Yang and Zhou, Jie},
journal={arXiv preprint arXiv:2108.05818},
year={2021}
}
@article{fang2022parallel,
title={Parallel Training of Pre-Trained Models via Chunk-Based Dynamic Memory Management},
author={Fang, Jiarui and Zhu, Zilin and Li, Shenggui and Su, Hui and Yu, Yang and Zhou, Jie and You, Yang},
journal={IEEE Transactions on Parallel and Distributed Systems},
volume={34},
number={1},
pages={304--315},
year={2022},
publisher={IEEE}
}
{jiaruifang, zilinzhu, josephyu}@tencent.com
ขับเคลื่อนโดยทีม WeChat AI, Tencent NLP Oteam


