xcodec
1.0.0
ตัวแปลงสัญญาณความหมายและเสียงแบบรวมสำหรับโมเดลภาษาเสียง
หัวข้อ : Codec ไม่สำคัญ: การสำรวจข้อบกพร่องด้านความหมายของ Codec สำหรับโมเดลภาษาเสียง
ผู้แต่ง : เจิ้น เย่, เป่ยเหวิน ซุน, เจียเหอ เล่ย, หงจาน หลิน, ซู ตัน, เจ้อฉี ไต, ชิวเฉียงกง, เจียนอี้ เฉิน, เจียห่าว แพน, ฉีเฟิง หลิว, ยี่ กั๋ว*, เหว่ย เสว่*
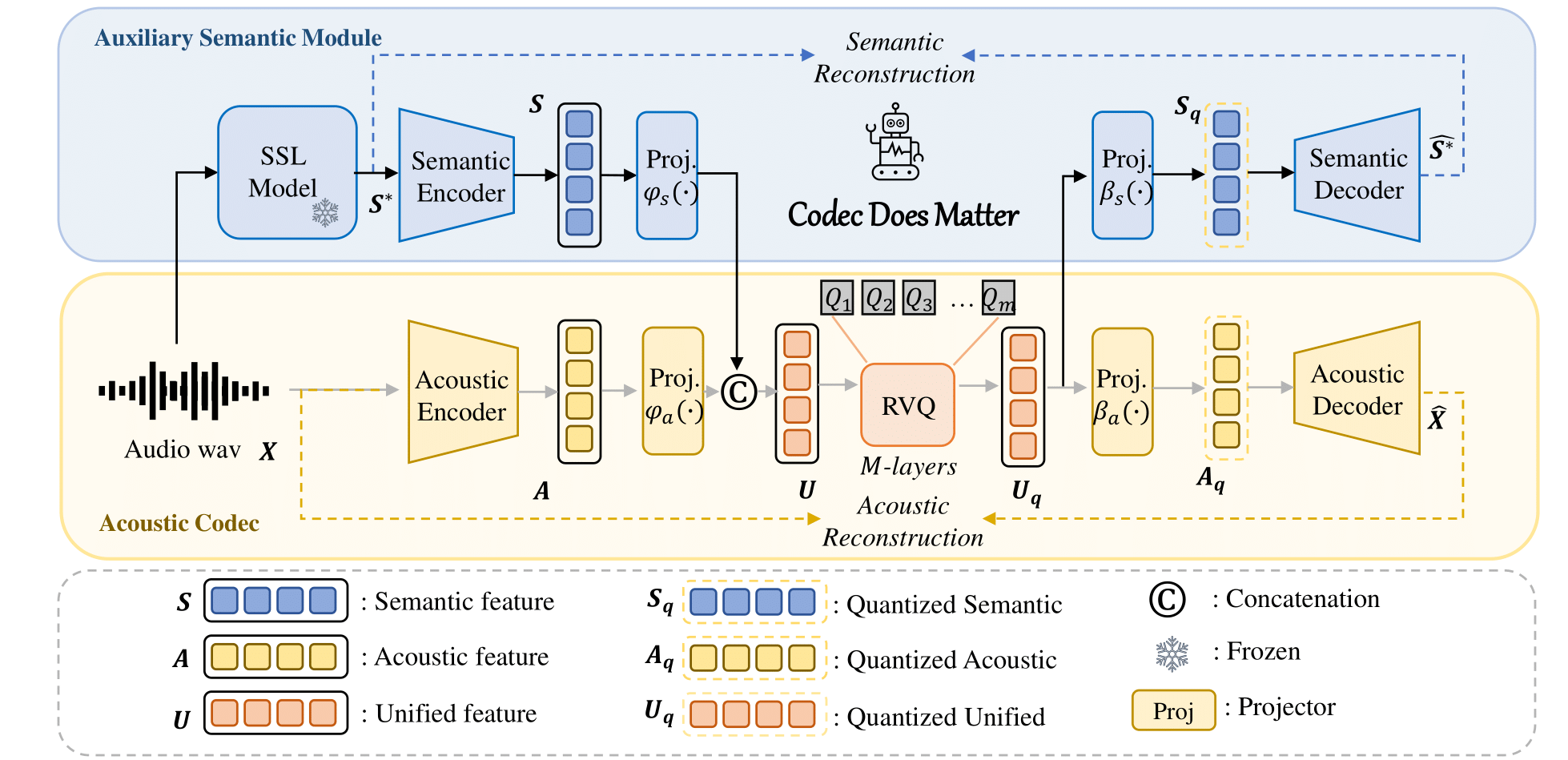
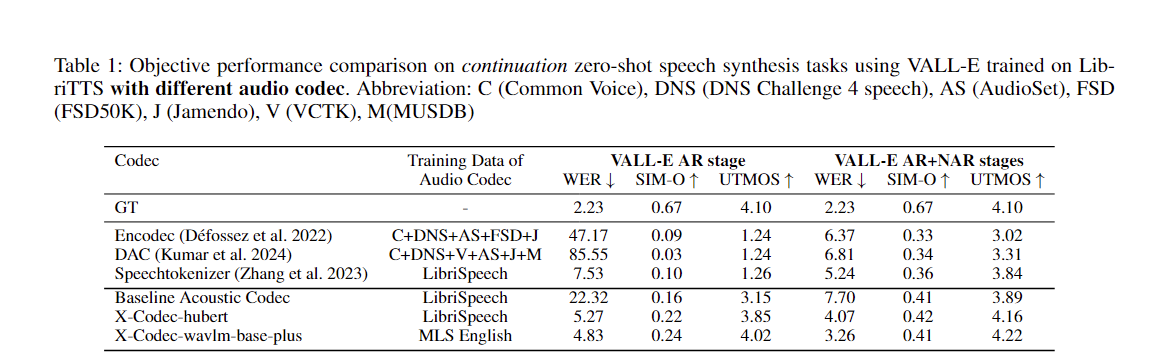
คุณสามารถใช้แนวทางของเราเพื่อปรับปรุงตัวแปลงสัญญาณอะคูสติกที่มีอยู่ได้อย่างง่ายดาย:
ตัวอย่างเช่น
class Codec ():
def __init__ ( self ):
# Acoustic codec components
self . encoder = Encoder (...) # Acoustic encoder
self . decoder = Decoder (...) # Acoustic decoder
self . quantizer = RVQ (...) # Residual Vector Quantizer (RVQ)
# Adding the semantic module
self . semantic_model = AutoModel . from_pretrained (...) # e.g., Hubert, WavLM
# Adding Projector
self . fc_prior = nn . Linear (...)
self . fc_post1 = nn . Linear (...)
self . fc_post2 = nn . Linear (...)
def forward ( self , x , bw ):
# Encode the input acoustically and semantically
e_acoustic = self . encoder ( x )
e_semantic = self . semantic_model ( x )
# Combine acoustic and semantic features
combined_features = torch . cat ([ e_acoustic , e_semantic ])
# Apply prior transformation
transformed_features = self . fc_prior ( combined_features )
# Quantize the unified semantic and acoustic features
quantized , codes , bandwidth , commit_loss = self . quantizer ( transformed_features , bw )
# Post-process the quantized features
quantized_semantic = self . fc_post1 ( quantized )
quantized_acoustic = self . fc_post2 ( quantized )
# Decode the quantized acoustic features
output = self . decoder ( quantized_acoustic )
def semantic_loss ( self , semantic , quantized_semantic ):
return F . mse_loss ( semantic , quantized_semantic ) สำหรับรายละเอียดเพิ่มเติม โปรดดูรหัสของเรา
- ลิงก์ไปยังฮับโมเดล Huggingface
| ชื่อรุ่น | กอดหน้า | การกำหนดค่า | โมเดลความหมาย | โดเมน | ข้อมูลการฝึกอบรม |
|---|---|---|---|---|---|
| xcodec_hubert_librispeech | - | - | - ฐานฮิวเบิร์ต | คำพูด | บรรณารักษ์ |
| xcodec_wavlm_mls (ไม่ได้กล่าวถึงในกระดาษ) | - | - | - Wavlm-ฐานบวก | คำพูด | ภาษาอังกฤษเอ็มแอลเอส |
| xcodec_wavlm_more_data (ไม่ได้กล่าวถึงในกระดาษ) | - | - | - Wavlm-ฐานบวก | คำพูด | MLS ภาษาอังกฤษ + ข้อมูลภายใน |
| xcodec_hubert_general_audio | - | - | ?ฮูเบิร์ต-ฐาน-เสียงทั่วไป | เครื่องเสียงทั่วไป | ข้อมูลภายใน 200,000 ชั่วโมง |
| xcodec_hubert_general_audio_more_data (ไม่ได้กล่าวถึงในกระดาษ) | - | - | ?ฮูเบิร์ต-ฐาน-เสียงทั่วไป | เครื่องเสียงทั่วไป | ข้อมูลที่สมดุลมากขึ้น |
หากต้องการเรียกใช้การอนุมาน ขั้นแรกให้ดาวน์โหลดโมเดลและกำหนดค่าจากการกอดใบหน้า
python inference.pyเตรียมไฟล์ training_file และ validation_file ใน config. ไฟล์ควรแสดงรายการเส้นทางไปยังไฟล์เสียงของคุณ:
/path/to/your/xxx.wav
/path/to/your/yyy.wav
...แล้ว:
torchrun --nnodes=1 --nproc-per-node=8 main_launch_vqdp.pyฉันขอขอบคุณผู้เขียน Uniaudio และ DAC เป็นพิเศษ เนื่องจากฐานโค้ดของเรายืมมาจาก Uniaudio และ DAC เป็นหลัก
หากคุณพบว่า repo นี้มีประโยชน์ โปรดพิจารณาการอ้างอิงในรูปแบบต่อไปนี้:
@article { ye2024codecdoesmatterexploring ,
title = { Codec Does Matter: Exploring the Semantic Shortcoming of Codec for Audio Language Model } ,
author = { Zhen Ye and Peiwen Sun and Jiahe Lei and Hongzhan Lin and Xu Tan and Zheqi Dai and Qiuqiang Kong and Jianyi Chen and Jiahao Pan and Qifeng Liu and Yike Guo and Wei Xue } ,
journal = { arXiv preprint arXiv:2408.17175 } ,
year = { 2024 } ,
}

