EasyEdit
1.0.0

กรอบงานการแก้ไขความรู้ที่ใช้งานง่ายสำหรับโมเดลภาษาขนาดใหญ่
การติดตั้ง • QuickStart • เอกสาร • กระดาษ • การสาธิต • เกณฑ์มาตรฐาน • ผู้มีส่วนร่วม • สไลด์ • วิดีโอ • นำเสนอโดย AK
23-10-2024 EasyEdit ผสานรวมวิธีการถอดรหัสที่มีข้อจำกัดตั้งแต่การแก้ไขพวงมาลัยเพื่อบรรเทาอาการประสาทหลอนใน LLM และ MLLM พร้อมข้อมูลโดยละเอียดที่มีอยู่ใน DoLa และ DeCo
26-09-2024, ?? บทความ "WISE: Rethinking the Knowledge Memory for Lifelong Model Editing of Large Language Models" ของเราได้รับการยอมรับจาก NeurIPS 2024
20-09-2024-09-20, ?? เอกสารของเรา: "กลไกความรู้ในแบบจำลองภาษาขนาดใหญ่: การสำรวจและมุมมอง" และ "การแก้ไขความรู้เชิงแนวคิดสำหรับแบบจำลองภาษาขนาดใหญ่" ได้รับการยอมรับจาก ผลการวิจัยของ EMNLP ประจำปี 2024
29-07-2024 EasyEdit ได้เพิ่มอัลกอริธึมการแก้ไขโมเดลใหม่ EMMET ซึ่งสรุป ROME ให้เป็นการตั้งค่าแบบแบตช์ ซึ่งจะช่วยให้ทำการแก้ไขเป็นชุดโดยใช้ฟังก์ชัน ROME loss ได้
วันที่ 23-07-2023 เราเผยแพร่รายงานใหม่: "กลไกความรู้ในแบบจำลองภาษาขนาดใหญ่: การสำรวจและมุมมอง" ซึ่งทบทวนวิธีการได้มา ใช้ประโยชน์ และวิวัฒนาการในแบบจำลองภาษาขนาดใหญ่ แบบสำรวจนี้อาจจัดเตรียมกลไกพื้นฐานสำหรับการจัดการ (แก้ไข) ความรู้ใน LLM ได้อย่างแม่นยำและมีประสิทธิภาพ
04-06-2024, ?? EasyEdit Paper ได้รับการยอมรับจาก ACL 2024 System Demonstration Track
03-06-2024 เราได้เผยแพร่บทความเรื่อง "WISE: การคิดใหม่เกี่ยวกับหน่วยความจำความรู้สำหรับการแก้ไขโมเดลตลอดชีวิตของโมเดลภาษาขนาดใหญ่" พร้อมด้วยการแนะนำ งานแก้ไขใหม่: การแก้ไขความรู้อย่างต่อเนื่อง และ วิธีการแก้ไขตลอดชีวิต ที่สอดคล้องกันที่เรียกว่า WISE
24-04-2024 EasyEdit ประกาศรองรับ วิธี ROME สำหรับ Llama3-8B ผู้ใช้ควรอัปเดตแพ็คเกจ Transformers เป็นเวอร์ชัน 4.40.0
29-03-2024 EasyEdit เปิดตัว การรองรับการย้อนกลับสำหรับ GRACE สำหรับคำแนะนำโดยละเอียด โปรดดูเอกสาร EasyEdit การอัปเดตในอนาคตจะค่อยๆ รวมการสนับสนุนการย้อนกลับสำหรับวิธีการอื่นๆ
22-03-2024 มีการเผยแพร่รายงานฉบับใหม่ชื่อ "แบบจำลองภาษาขนาดใหญ่ในการล้างพิษผ่านการแก้ไขความรู้" พร้อมด้วยชุดข้อมูลใหม่ชื่อ SafeEdit และ วิธีการล้างพิษ ใหม่ที่เรียกว่า DINM
12-03-2024 มีการเผยแพร่รายงานอีกฉบับชื่อ "การแก้ไขความรู้เชิงแนวคิดสำหรับโมเดลภาษาขนาดใหญ่" โดยแนะนำชุดข้อมูลใหม่ชื่อ ConceptEdit
01-03-2024 EasyEdit ได้เพิ่มการรองรับวิธีการใหม่ที่เรียกว่า FT-M วิธีนี้เกี่ยวข้องกับการฝึกอบรมเลเยอร์ MLP ที่เฉพาะเจาะจง โดยใช้การสูญเสียเอนโทรปีข้ามกับคำตอบเป้าหมายและปิดบังข้อความต้นฉบับ มันมีประสิทธิภาพเหนือกว่าการใช้งาน FT-L ใน ROME ขอขอบคุณผู้เขียนฉบับที่ 173 สำหรับคำแนะนำ
27-02-2024 EasyEdit ได้เพิ่มการรองรับวิธีการใหม่ที่เรียกว่า InstructEdit โดยมีรายละเอียดทางเทคนิคอยู่ในเอกสาร "InstructEdit: การแก้ไขความรู้ตามคำสั่งสำหรับโมเดลภาษาขนาดใหญ่"
Accelerateการศึกษาที่ครอบคลุมเกี่ยวกับการแก้ไขความรู้สำหรับโมเดลภาษาขนาดใหญ่ [กระดาษ] [มาตรฐาน] [รหัส]
IJCAI 2024 บทช่วยสอน Google ไดรฟ์
COLING 2024 บทช่วยสอน Google Drive
AAAI 2024 บทช่วยสอน Google ไดรฟ์
บทช่วยสอน AACL 2023 [Google Drive] [Baidu Pan]
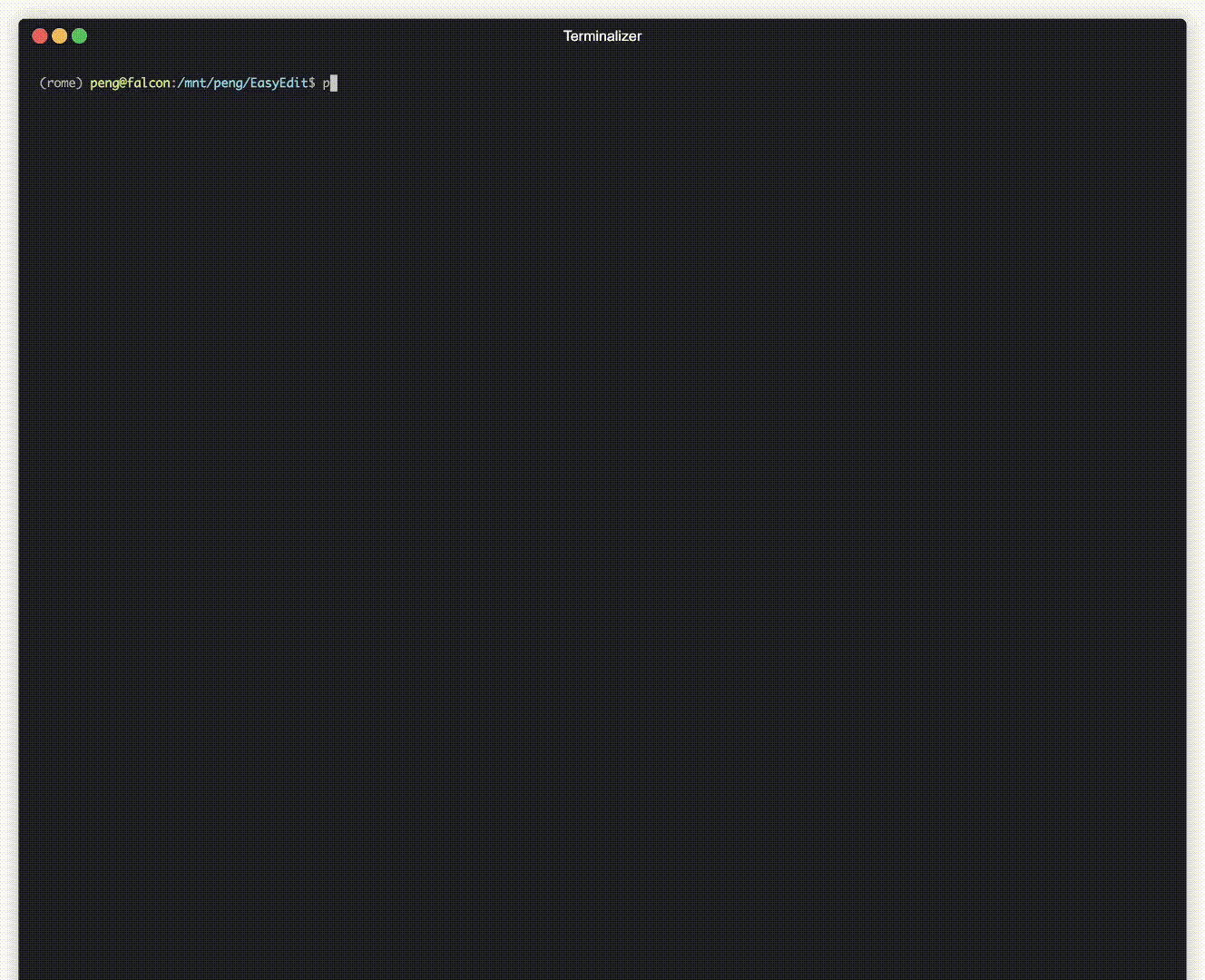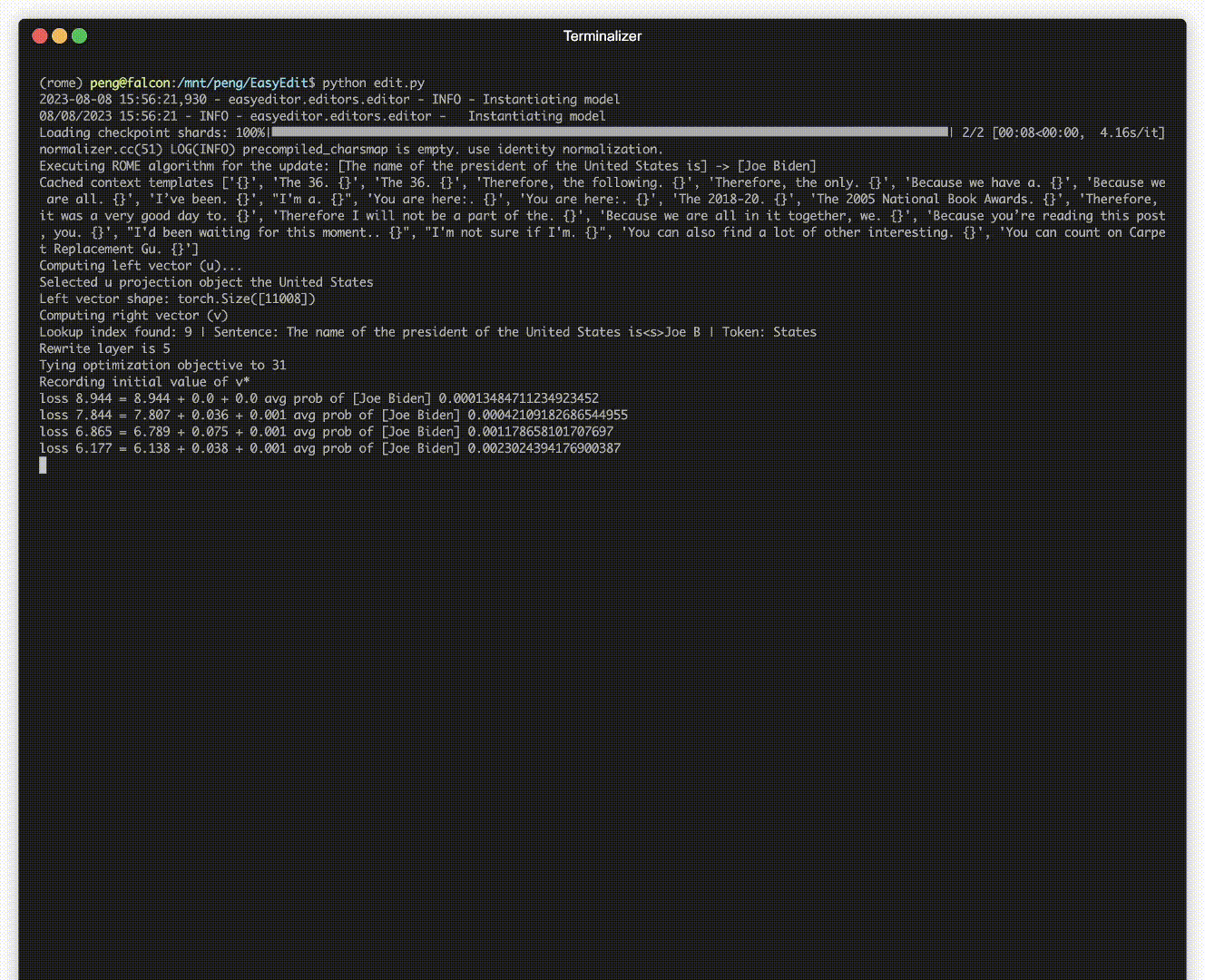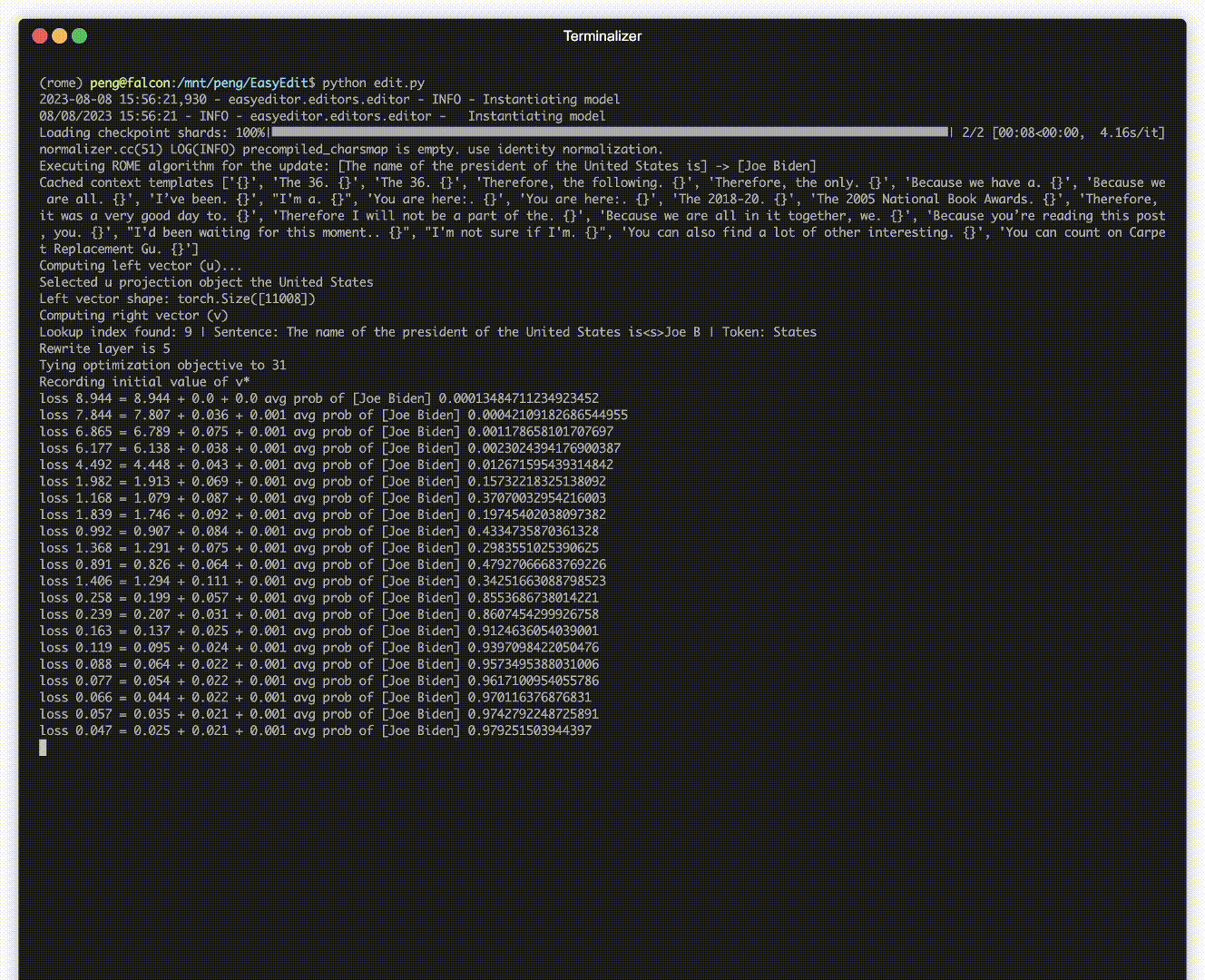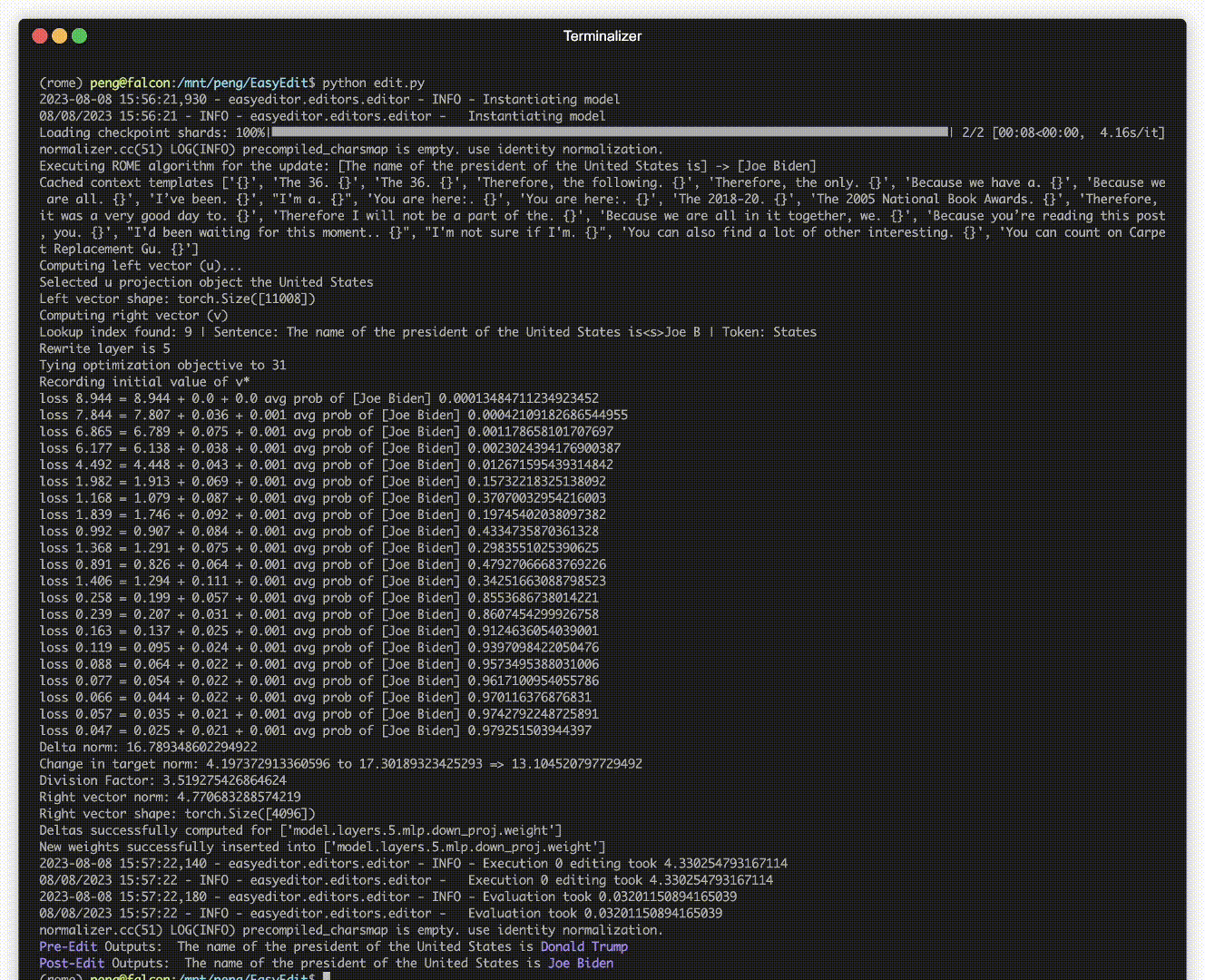
มีการสาธิตการแก้ไข ไฟล์ GIF ถูกสร้างขึ้นโดย Terminalizer
เรามีสมุดบันทึก Jupyter ที่มีประโยชน์! ช่วยให้คุณสามารถแก้ไขความรู้ของ LLM เกี่ยวกับประธานาธิบดีสหรัฐฯ เปลี่ยนจาก Biden เป็น Trump และแม้แต่กลับเป็น Biden ซึ่งรวมถึงวิธีการต่างๆ เช่น WISE, AlphaEdit, AdaLoRA และการแก้ไขตามพร้อมท์
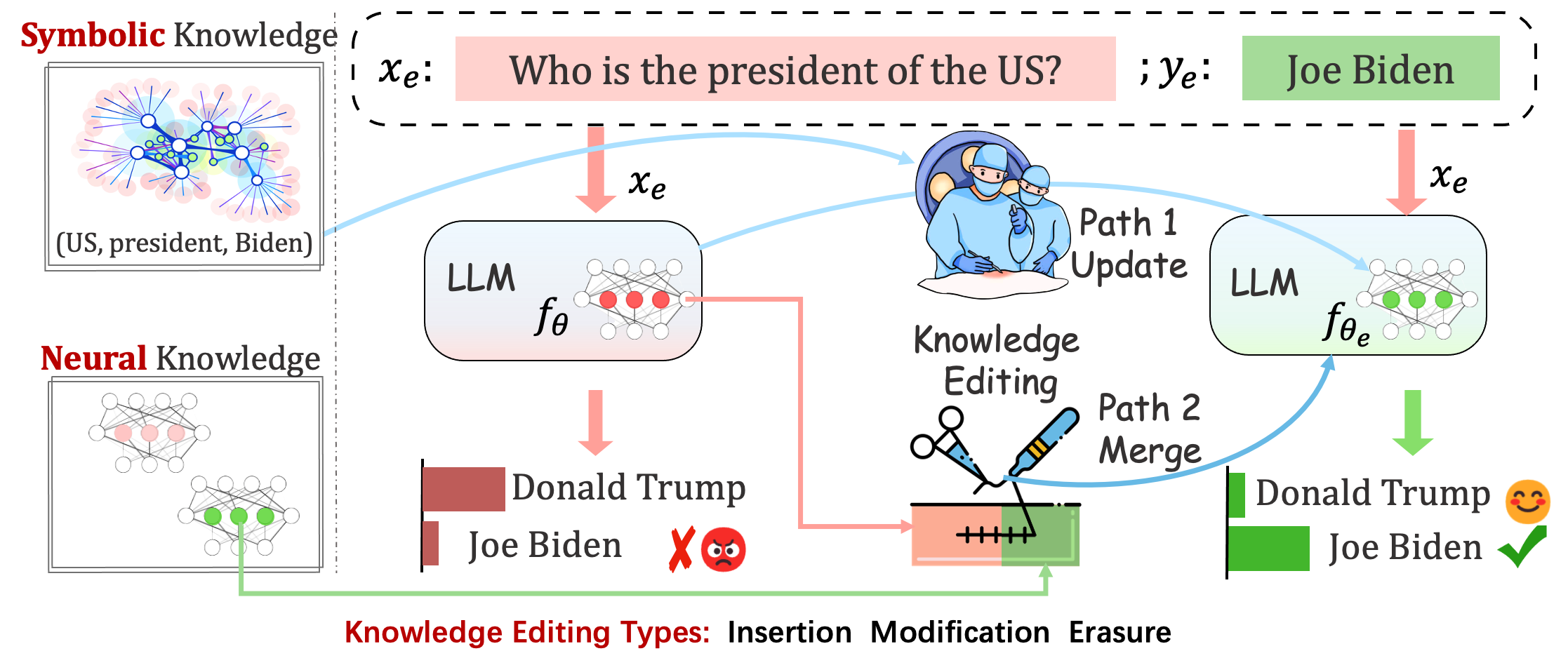
โมเดลที่ปรับใช้อาจยังคงสร้างข้อผิดพลาดที่คาดเดาไม่ได้ ตัวอย่างเช่น LLM มี อาการประสาทหลอน อย่างฉาวโฉ่ มีอคติอยู่ตลอดเวลา และ เสื่อมสลายตามความเป็นจริง ดังนั้นเราจึงควรสามารถปรับพฤติกรรมเฉพาะของแบบจำลองที่ได้รับการฝึกอบรมล่วงหน้าได้
การแก้ไขความรู้ มีวัตถุประสงค์เพื่อปรับโมเดลพื้นฐาน
การประเมินประสิทธิภาพของโมเดลหลังจากการแก้ไขครั้งเดียว แบบจำลองจะโหลดน้ำหนักเดิมใหม่ (เช่น LoRA ละทิ้งน้ำหนักของอะแดปเตอร์) หลังจากการแก้ไขครั้งเดียว คุณควรตั้งค่า sequential_edit=False
สิ่งนี้จำเป็นต้อง มีการแก้ไขตามลำดับ และการประเมินผลจะดำเนินการหลังจากใช้การอัปเดตความรู้ทั้งหมดแล้ว:
มันทำการปรับพารามิเตอร์สำหรับ sequential_edit=True : README (สำหรับรายละเอียดเพิ่มเติม)
เป้าหมายสูงสุดคือการสร้างแบบจำลองที่แก้ไข โดยไม่ส่งผลต่อพฤติกรรมของแบบจำลองกับตัวอย่างที่ไม่เกี่ยวข้องกัน
การแก้ไขงานสำหรับ คำบรรยายภาพ และ การตอบคำถามด้วยภาพ อ่านฉัน
งานที่เสนอต้องใช้ความพยายามเบื้องต้นในการแก้ไขบุคลิกภาพของ LLM โดยการแก้ไขความคิดเห็นในหัวข้อเฉพาะ โดยที่ความคิดเห็นของแต่ละคนสามารถสะท้อนลักษณะบุคลิกภาพของตนได้ เรายึดถือทฤษฎี BIG FIVE ที่จัดตั้งขึ้นเพื่อเป็นพื้นฐานในการสร้างชุดข้อมูลของเราและประเมินการแสดงออกทางบุคลิกภาพของ LLM อ่านฉัน
การประเมิน
ตามบันทึก
อิงตามรุ่น
ในระหว่างการประเมิน Acc และ TPEI คุณสามารถดาวน์โหลดตัวแยกประเภทที่ผ่านการฝึกอบรมได้จากที่นี่
โดยทั่วไป กระบวนการแก้ไขความรู้จะส่งผลต่อการคาดการณ์สำหรับชุดอินพุตกว้างๆ ที่เกี่ยวข้องอย่างใกล้ชิด กับตัวอย่างการแก้ไข ที่เรียกว่า ขอบเขตการแก้ไข
การแก้ไขที่ประสบความสำเร็จควรปรับพฤติกรรมของโมเดลภายในขอบเขตการแก้ไขในขณะที่ยังมีอินพุตที่ไม่เกี่ยวข้องเหลืออยู่:
Reliability : อัตราความสำเร็จของการแก้ไขโดยใช้คำอธิบายการแก้ไขที่กำหนดGeneralization : อัตราความสำเร็จของการแก้ไขภายในขอบเขตการแก้ไขLocality : ไม่ว่าเอาต์พุตของแบบจำลองจะเปลี่ยนแปลงหลังจากแก้ไขอินพุตที่ไม่เกี่ยวข้องหรือไม่Portability : อัตราความสำเร็จของการแก้ไขเพื่อการให้เหตุผล/แอปพลิเคชัน (หนึ่งฮอป คำพ้องความหมาย การวางนัยทั่วไปเชิงตรรกะ)Efficiency : เวลาและการใช้หน่วยความจำ EasyEdit เป็นแพ็คเกจ Python สำหรับแก้ไข Large Language Models (LLM) เช่น GPT-J , Llama , GPT-NEO , GPT2 , T5 (รองรับโมเดลตั้งแต่ 1B ถึง 65B ) โดยมีวัตถุประสงค์เพื่อปรับเปลี่ยนพฤติกรรมของ LLM อย่างมีประสิทธิภาพภายใน เฉพาะโดเมนโดยไม่ส่งผลเสียต่อประสิทธิภาพของอินพุตอื่นๆ ออกแบบมาให้ใช้งานง่ายและง่ายต่อการขยาย
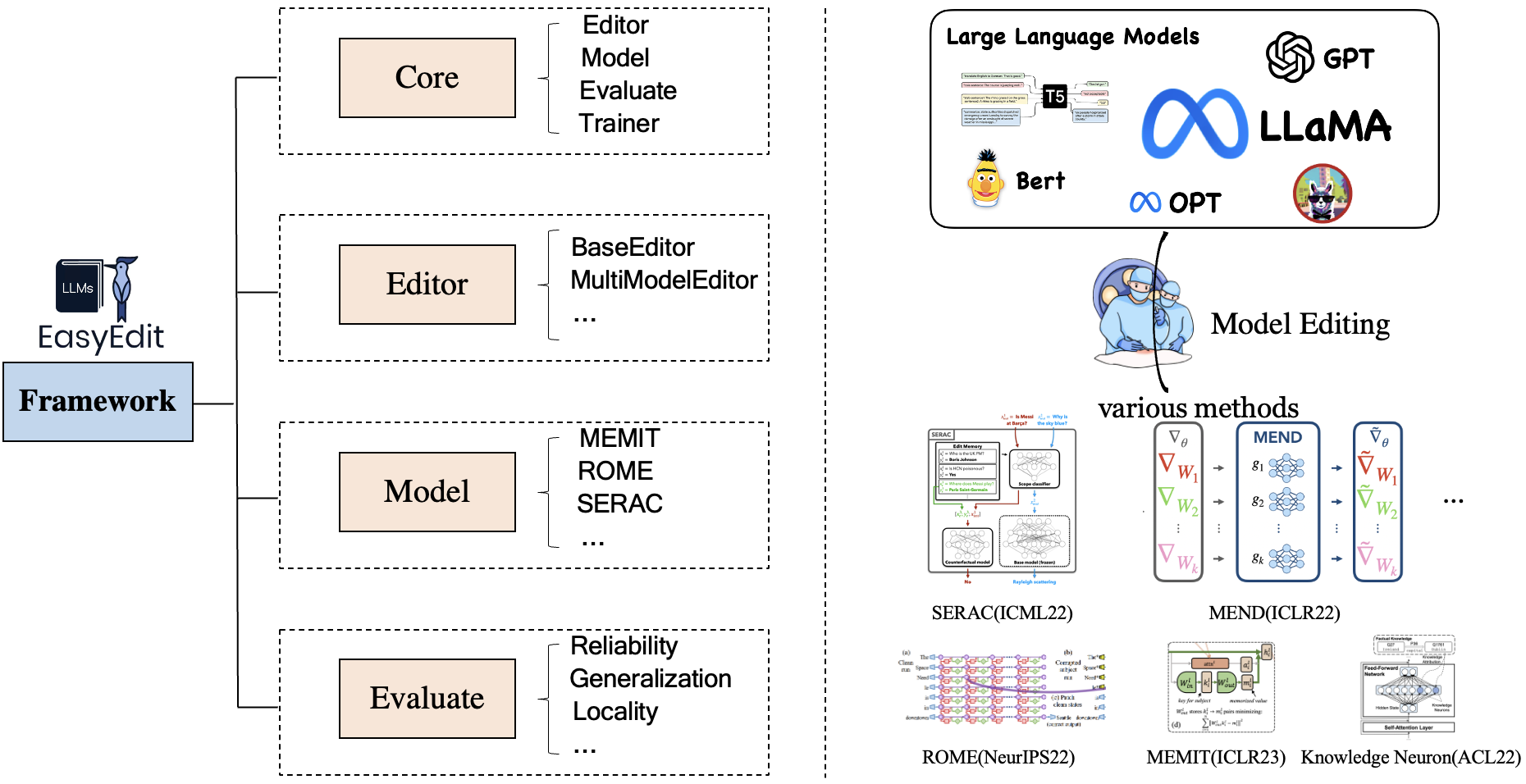
EasyEdit มีเฟรมเวิร์กแบบรวมสำหรับ Editor , Method และ Evaluate ตามลำดับซึ่งแสดงถึงสถานการณ์การแก้ไข เทคนิคการแก้ไข และวิธีการประเมิน
สถานการณ์การแก้ไขความรู้แต่ละสถานการณ์ประกอบด้วยสามองค์ประกอบ:
Editor : เช่น BaseEditor (ตัวแก้ไข ความรู้ข้อเท็จจริง และ การสร้าง ) สำหรับ LM, MultiModalEditor ( ความรู้หลายรูปแบบ )Method : เทคนิคการแก้ไขความรู้เฉพาะที่ใช้ (เช่น ROME , MEND , .. )Evaluate : ตัวชี้วัด สำหรับการประเมินประสิทธิภาพการแก้ไขความรู้Reliability Generalization Locality Portabilityเทคนิคการแก้ไขความรู้ที่ได้รับการสนับสนุนในปัจจุบันมีดังนี้:
หมายเหตุ 1: เนื่องจากชุดเครื่องมือนี้มีความเข้ากันได้อย่างจำกัด จึงไม่รองรับวิธีการแก้ไขความรู้บางอย่าง รวมถึง T-Patcher, KE, CaliNet
หมายเหตุ 2: ในทำนองเดียวกัน วิธีการ MALMEN ได้รับการรองรับเพียงบางส่วนเท่านั้นเนื่องจากเหตุผลเดียวกัน และจะมีการปรับปรุงต่อไป
คุณสามารถเลือกวิธีการแก้ไขที่แตกต่างกันได้ตามความต้องการเฉพาะของคุณ
| วิธี | T5 | GPT-2 | GPT-เจ | GPT-นีโอ | ลามะ | ไป๋ชวน | แชทGLM | ฝึกงานLM | เกว็น | มิสทรัล |
|---|---|---|---|---|---|---|---|---|---|---|
| ฟุต | ||||||||||
| อดาโลรา | ||||||||||
| ซีรัค | ||||||||||
| ไอเค | ||||||||||
| ซ่อม | ||||||||||
| เคเอ็น | ||||||||||
| โรม | ||||||||||
| r-โรม | ||||||||||
| มีมิต | ||||||||||
| เอ็มเม็ท | ||||||||||
| เกรซ | ||||||||||
| เมโล | ||||||||||
| พีเมท | ||||||||||
| สั่งสอนแก้ไข | ||||||||||
| ดินม์ | ||||||||||
| ฉลาด | ||||||||||
| อัลฟ่าแก้ไข |
❗️❗️ หากคุณตั้งใจจะใช้ Mistral โปรดอัปเดตไลบรารี่
transformersเป็นเวอร์ชัน 4.34.0 ด้วยตนเอง คุณสามารถใช้รหัสต่อไปนี้:pip install transformers==4.34.0
| งาน | คำอธิบาย | เส้นทาง |
|---|---|---|
| สั่งสอนแก้ไข | InstructEdit: การแก้ไขความรู้ตามคำสั่งสำหรับโมเดลภาษาขนาดใหญ่ | เริ่มต้นอย่างรวดเร็ว |
| ดินม์ | การล้างพิษโมเดลภาษาขนาดใหญ่ด้วยการแก้ไขความรู้ | เริ่มต้นอย่างรวดเร็ว |
| ฉลาด | WISE: การคิดใหม่เกี่ยวกับหน่วยความจำความรู้สำหรับการแก้ไขโมเดลตลอดชีวิตของโมเดลภาษาขนาดใหญ่ | เริ่มต้นอย่างรวดเร็ว |
| แนวคิดแก้ไข | การแก้ไขความรู้เชิงแนวคิดสำหรับโมเดลภาษาขนาดใหญ่ | เริ่มต้นอย่างรวดเร็ว |
| MMแก้ไข | เราสามารถแก้ไขโมเดลภาษาขนาดใหญ่หลายรูปแบบได้หรือไม่ | เริ่มต้นอย่างรวดเร็ว |
| บุคลิกภาพแก้ไข | การแก้ไขบุคลิกภาพสำหรับโมเดลภาษาขนาดใหญ่ | เริ่มต้นอย่างรวดเร็ว |
| พร้อมท์ | วิธีการแก้ไขความรู้ตาม PROMPT | เริ่มต้นอย่างรวดเร็ว |
เกณฑ์มาตรฐาน: KnowEdit [กอดใบหน้า] [WiseModel] [ModelScope]
❗️❗️ โปรดทราบว่า KnowEdit ถูกสร้างขึ้นโดย การจัดระเบียบใหม่และขยาย ชุดข้อมูลที่มีอยู่ รวมถึง WikiBio , ZsRE , WikiData Counterfact , WikiData ล่าสุด , Convsent , Sanitation เพื่อทำการประเมินที่ครอบคลุมสำหรับการแก้ไขความรู้ ขอขอบคุณเป็นพิเศษสำหรับผู้สร้างและผู้ดูแลชุดข้อมูลเหล่านั้น
โปรดทราบว่า Counterfact และ WikiData Counterfact ไม่ใช่ชุดข้อมูลเดียวกัน
| งาน | การแทรกความรู้ | การปรับเปลี่ยนความรู้ | การลบล้างความรู้ | |||
|---|---|---|---|---|---|---|
| ชุดข้อมูล | วิกิ ล่าสุด | ZsRE | วิกิไบโอ | การโต้แย้งของ WikiData | คอนเนตทิคัต | สุขาภิบาล |
| พิมพ์ | ข้อเท็จจริง | การตอบคำถาม | อาการประสาทหลอน | ต่อต้าน | ความรู้สึก | ข้อมูลที่ไม่ต้องการ |
| # รถไฟ | 570 | 10,000 | 592 | 1,455 | 14,390 | 80 |
| # ทดสอบ | 1,266 | 1301 | 1,392 | 885 | 800 | 80 |
เรามี สคริปต์โดยละเอียด เพื่อให้ผู้ใช้ใช้ KnowEdit ได้อย่างง่ายดาย โปรดดูตัวอย่าง
knowedit
├── WikiBio
│ ├── wikibio-test-all.json
│ └── wikibio-train-all.json
├── ZsRE
│ └── ZsRE-test-all.json
├── wiki_counterfact
│ ├── test_cf.json
│ └── train_cf.json
├── convsent
│ ├── blender_test.json
│ ├── blender_train.json
│ └── blender_val.json
├── convsent
│ ├── trivia_qa_test.json
│ └── trivia_qa_train.json
└── wiki_recent
├── recent_test.json
└── recent_train.json
| ชุดข้อมูล | กอดใบหน้า | ปรีชาญาณโมเดล | โมเดลสโคป | คำอธิบาย |
|---|---|---|---|---|
| Cทราบแก้ไข | [กอดใบหน้า] | [ปรีชาโมเดล] | [โมเดลสโคป] | ชุดข้อมูลสำหรับแก้ไขความรู้ภาษาจีน |
CNowEdit เป็นชุดข้อมูลภาษาจีนคุณภาพสูงสำหรับการแก้ไขความรู้ซึ่งมีลักษณะเฉพาะอย่างมากด้วยภาษาจีน โดยข้อมูลทั้งหมดมาจากฐานความรู้ภาษาจีน ได้รับการออกแบบอย่างพิถีพิถันเพื่อให้เข้าใจความแตกต่างและความท้าทายที่มีอยู่ในความเข้าใจภาษาจีนโดย LLM ในปัจจุบันอย่างลึกซึ้งยิ่งขึ้น ซึ่งเป็นทรัพยากรที่มีประสิทธิภาพสำหรับการปรับปรุงความรู้เฉพาะด้านภาษาจีนภายใน LLM
คำอธิบายฟิลด์สำหรับข้อมูลใน CNowEdit มีดังนี้:
"prompt" : query inputed to the model ( str )
"target_old" : the incorrect response previously generated by the model ( str )
"target_new" : the accurate answer of the prompt ( str )
"portability_prompt" : new prompts related to the target knowledge ( list or None )
"portability_answer" : accurate answers corresponding to the portability_prompt ( list or None )
"locality_prompt" : new prompts unrelated to the target knowledge ( list or None )
"locality_answer" : accurate answers corresponding to the locality_prompt ( list or None )
"rephrase" : alternative ways to phrase the original prompt ( list ) CknowEdit
├── Chinese Literary Knowledge
│ ├── Ancient Poetry
│ ├── Proverbs
│ └── Idioms
├── Chinese Linguistic Knowledge
│ ├── Phonetic Notation
│ └── Classical Chinese
├── Chinese Geographical Knowledge
└── Ruozhiba
| ชุดข้อมูล | Google ไดรฟ์ | BaiduNetDisk | คำอธิบาย |
|---|---|---|---|
| ซีเอสอาร์ อี พลัส | [กูเกิลไดรฟ์] | [ไป่ตู้เน็ตดิสก์] | ชุดข้อมูลการตอบคำถามโดยใช้ถ้อยคำคำถามใหม่ |
| ต่อต้าน บวก | [กูเกิลไดรฟ์] | [ไป่ตู้เน็ตดิสก์] | ชุดข้อมูล Counterfact โดยใช้การแทนที่เอนทิตี |
เราจัดเตรียมชุดข้อมูล zsre และ counterfact เพื่อตรวจสอบประสิทธิภาพของการแก้ไขความรู้ คุณสามารถดาวน์โหลดได้ที่นี่ [Google ไดรฟ์], [BaiduNetDisk]
editing-data
├── counterfact
│ ├── counterfact-edit.json
│ ├── counterfact-train.json
│ └── counterfact-val.json
├── locality
│ ├── Commonsense Task
│ │ ├── piqa_valid-labels.lst
│ │ └── piqa_valid.jsonl
│ ├── Distracting Neighbor
│ │ └── counterfact_distracting_neighbor.json
│ └── Other Attribution
│ └── counterfact_other_attribution.json
├── portability
│ ├── Inverse Relation
│ │ └── zsre_inverse_relation.json
│ ├── One Hop
│ │ ├── counterfact_portability_gpt4.json
│ │ └── zsre_mend_eval_portability_gpt4.json
│ └── Subject Replace
│ ├── counterfact_subject_replace.json
│ └── zsre_subject_replace.json
└── zsre
├── zsre_mend_eval.json
├── zsre_mend_train_10000.json
└── zsre_mend_train.json
spouse| ชุดข้อมูล | Google ไดรฟ์ | ชุดข้อมูล HuggingFace | คำอธิบาย |
|---|---|---|---|
| แนวคิดแก้ไข | [กูเกิลไดรฟ์] | [ชุดข้อมูล HuggingFace] | ชุดข้อมูลสำหรับการแก้ไขความรู้เชิงแนวคิด |
data
└──concept_data.json
├──final_gpt2_inter.json
├──final_gpt2_intra.json
├──final_gptj_inter.json
├──final_gptj_intra.json
├──final_llama2chat_inter.json
├──final_llama2chat_intra.json
├──final_mistral_inter.json
└──final_mistral_intra.json
ตัวชี้วัดการประเมินเฉพาะแนวคิด
Instance Change : จับความซับซ้อนของการเปลี่ยนแปลงระดับอินสแตนซ์เหล่านี้Concept Consistency : ความคล้ายคลึงทางความหมายของคำจำกัดความแนวคิดที่สร้างขึ้น | ชุดข้อมูล | Google ไดรฟ์ | BaiduNetDisk | คำอธิบาย |
|---|---|---|---|
| อี-ไอซี | [กูเกิลไดรฟ์] | [ไป่ตู้เน็ตดิสก์] | ชุดข้อมูลสำหรับการแก้ไข คำบรรยายภาพ |
| E-VQA | [กูเกิลไดรฟ์] | [ไป่ตู้เน็ตดิสก์] | ชุดข้อมูลสำหรับแก้ไข การตอบคำถามด้วยภาพ |
editing-data
├── caption
│ ├── caption_train_edit.json
│ └── caption_eval_edit.json
├── locality
│ ├── NQ dataset
│ │ ├── train.json
│ │ └── validation.json
├── multimodal_locality
│ ├── OK-VQA dataset
│ │ ├── okvqa_loc.json
└── vqa
├── vqa_train.json
└── vqa_eval.json
| ชุดข้อมูล | ชุดข้อมูล HuggingFace | คำอธิบาย |
|---|---|---|
| ปลอดภัยแก้ไข | [ชุดข้อมูล HuggingFace] | ชุดข้อมูลสำหรับการล้างพิษ LLM |
data
└──SafeEdit_train.json
└──SafeEdit_val.json
└──SafeEdit_test.json
การล้างพิษตัวชี้วัดการประเมินเฉพาะ
Defense Duccess (DS) : อัตราความสำเร็จในการล้างพิษของ LLM ที่แก้ไขแล้วสำหรับอินพุตของฝ่ายตรงข้าม (พร้อมท์การโจมตี + คำถามที่เป็นอันตราย) ซึ่งใช้ในการแก้ไข LLMDefense Generalization (DG) : อัตราความสำเร็จในการล้างพิษของ LLM ที่แก้ไขแล้วสำหรับอินพุตที่เป็นอันตรายนอกโดเมนGeneral Performance : ผลข้างเคียงจากการปฏิบัติงานที่ไม่เกี่ยวข้อง | วิธี | คำอธิบาย | GPT-2 | ลามะ |
|---|---|---|---|
| ไอเค | แก้ไขการเรียนรู้ในบริบท (ICL) | [Colab-gpt2] | [โคแล็บ-ลามะ] |
| โรม | ค้นหาแล้วแก้ไขเซลล์ประสาท | [Colab-gpt2] | [โคแล็บ-ลามะ] |
| มีมิต | ค้นหาแล้วแก้ไขเซลล์ประสาท | [Colab-gpt2] | [โคแล็บ-ลามะ] |
หมายเหตุ: โปรดใช้ Python 3.9+ สำหรับ EasyEdit ในการเริ่มต้น เพียงติดตั้ง conda และรัน:
git clone https://github.com/zjunlp/EasyEdit.git
conda create -n EasyEdit python=3.9.7
...
pip install -r requirements.txtผลลัพธ์ของเราทั้งหมดขึ้นอยู่กับการกำหนดค่าเริ่มต้น
| ลามะ-2-7B | chatglm2 | gpt-j-6b | GPT-XL | |
|---|---|---|---|---|
| ฟุต | 60GB | 58GB | 55GB | 7GB |
| ซีรัค | 42GB | 32GB | 31GB | 10GB |
| ไอเค | 52GB | 38GB | 38GB | 10GB |
| ซ่อม | 46GB | 37GB | 37GB | 13GB |
| เคเอ็น | 42GB | 39GB | 40GB | 12GB |
| โรม | 31GB | 29GB | 27GB | 10GB |
| มีมิต | 33GB | 31GB | 31GB | 11GB |
| อดาโลรา | 29GB | 24GB | 25GB | 8GB |
| เกรซ | 27GB | 23GB | 6GB | |
| ฉลาด | 34GB | 27GB | 7GB |
แก้ไขโมเดลภาษาขนาดใหญ่ (LLM) ประมาณ 5 วินาที
ตัวอย่างต่อไปนี้แสดงวิธีการแก้ไขด้วย EasyEdit สามารถดูตัวอย่างและบทช่วยสอนเพิ่มเติมได้จากตัวอย่าง
BaseEditorเป็นคลาสสำหรับการแก้ไขความรู้ Modality ภาษา คุณสามารถเลือกวิธีการแก้ไขที่เหมาะสมได้ตามความต้องการเฉพาะของคุณ
ด้วยความเป็นโมดูลและความยืดหยุ่นของ EasyEdit คุณจึงสามารถใช้เพื่อแก้ไขโมเดลได้อย่างง่ายดาย
ขั้นตอนที่ 1: กำหนด PLM ให้เป็นออบเจ็กต์ที่จะแก้ไข เลือก PLM ที่จะแก้ไข EasyEdit รองรับโมเดลบางส่วน (จนถึงขณะนี้ T5 , GPTJ , GPT-NEO , LlaMA ) ที่สามารถเรียกดูได้บน HuggingFace ไดเร็กทอรีไฟล์การกำหนดค่าที่เกี่ยวข้องคือ hparams/YUOR_METHOD/YOUR_MODEL.YAML เช่น hparams/MEND/gpt2-xl.yaml ให้ตั้ง model_name ที่เกี่ยวข้องเพื่อเลือกออบเจ็กต์สำหรับการแก้ไขความรู้
model_name : gpt2-xl
model_class : GPT2LMHeadModel
tokenizer_class : GPT2Tokenizer
tokenizer_name : gpt2-xl
model_parallel : false # true for multi-GPU editingขั้นตอนที่ 2: เลือกวิธีการแก้ไขความรู้ที่เหมาะสม
## In this case, we use MEND method, so you should import `MENDHyperParams`
from easyeditor import MENDHyperParams
## Loading config from hparams/MEMIT/gpt2-xl.yaml
hparams = MENDHyperParams . from_hparams ( './hparams/MEND/gpt2-xl' )ขั้นตอนที่ 3: ระบุคำอธิบายการแก้ไขและเป้าหมายการแก้ไข
## edit descriptor: prompt that you want to edit
prompts = [
'What university did Watts Humphrey attend?' ,
'Which family does Ramalinaceae belong to' ,
'What role does Denny Herzig play in football?'
]
## You can set `ground_truth` to None !!!(or set to original output)
ground_truth = [ 'Illinois Institute of Technology' , 'Lecanorales' , 'defender' ]
## edit target: expected output
target_new = [ 'University of Michigan' , 'Lamiinae' , 'winger' ] ขั้นตอนที่ 4: รวมพวกมันเข้าใน BaseEditor EasyEdit มอบวิธีที่ง่ายและเป็นหนึ่งเดียวในการเริ่ม Editor เช่น Huggingface: from_hparams
## Construct Language Model Editor
editor = BaseEditor . from_hparams ( hparams )ขั้นตอนที่ 5: ให้ข้อมูลสำหรับการประเมิน โปรดทราบว่าข้อมูลสำหรับการพกพาและท้องถิ่นนั้นเป็น ทางเลือก (ตั้งค่าเป็นไม่มีสำหรับการประเมินอัตราความสำเร็จในการแก้ไขขั้นพื้นฐานเท่านั้น) รูปแบบข้อมูลสำหรับทั้งสองแบบคือ dict สำหรับแต่ละมิติการวัด คุณต้องระบุข้อความแจ้งที่เกี่ยวข้องและความจริงภาคพื้นดินที่สอดคล้องกัน นี่คือตัวอย่างข้อมูล:
locality_inputs = {
'neighborhood' :{
'prompt' : [ 'Joseph Fischhof, the' , 'Larry Bird is a professional' , 'In Forssa, they understand' ],
'ground_truth' : [ 'piano' , 'basketball' , 'Finnish' ]
},
'distracting' : {
'prompt' : [ 'Ray Charles, the violin Hauschka plays the instrument' , 'Grant Hill is a professional soccer Magic Johnson is a professional' , 'The law in Ikaalinen declares the language Swedish In Loviisa, the language spoken is' ],
'ground_truth' : [ 'piano' , 'basketball' , 'Finnish' ]
}
}ในตัวอย่างข้างต้น เราประเมินประสิทธิภาพของวิธีการแก้ไขเกี่ยวกับ "พื้นที่ใกล้เคียง" และ "สิ่งที่รบกวนสมาธิ"
ขั้นตอนที่ 6: แก้ไขและประเมินผล เสร็จแล้ว! เราสามารถดำเนินการแก้ไขและประเมินผลโมเดลของคุณเพื่อแก้ไขได้ ฟังก์ชัน edit จะส่งคืนชุดเมตริกที่เกี่ยวข้องกับกระบวนการแก้ไขตลอดจนน้ำหนักโมเดลที่แก้ไข [ sequential_edit=True สำหรับการแก้ไขอย่างต่อเนื่อง]
metrics , edited_model , _ = editor . edit (
prompts = prompts ,
ground_truth = ground_truth ,
target_new = target_new ,
locality_inputs = locality_inputs ,
sequential_edit = False # True: start continuous editing ✈️
)
## metrics: edit success, rephrase success, locality e.g.
## edited_model: post-edit modelความยาวอินพุตสูงสุดสำหรับ EasyEdit คือ 512 หากเกินความยาวนี้ คุณจะพบข้อผิดพลาด "ข้อผิดพลาด CUDA: ทริกเกอร์การยืนยันฝั่งอุปกรณ์" คุณสามารถแก้ไขความยาวสูงสุดได้ในไฟล์ต่อไปนี้:LINK
ขั้นตอนที่ 7: ย้อนกลับ ในการแก้ไขตามลำดับ หากคุณไม่พอใจกับผลลัพธ์ของการแก้ไขอย่างใดอย่างหนึ่ง และคุณไม่ต้องการสูญเสียการแก้ไขก่อนหน้านี้ คุณสามารถใช้คุณสมบัติย้อนกลับเพื่อเลิกทำการแก้ไขก่อนหน้าของคุณได้ ปัจจุบันเรารองรับเฉพาะวิธี GRACE เท่านั้น สิ่งที่คุณต้องทำคือโค้ดเพียงบรรทัดเดียว โดยใช้ edit_key เพื่อคืนค่าการแก้ไขของคุณ
editor.rolllback('edit_key')
ใน EasyEdit เราตั้งค่าเริ่มต้นให้ใช้ target_new เป็น edit_key
เราระบุเมตริกส่งคืนเป็นรูปแบบ dict รวมถึงการประเมินการทำนายโมเดลก่อนและหลังการแก้ไข สำหรับการแก้ไขแต่ละครั้ง จะมีเมตริกต่อไปนี้:
rewrite_acc rephrase_acc locality portablility 

