mengzi retrieval lm
1.0.0
ที่ Langboat Technology เรามุ่งเน้นที่การปรับปรุงโมเดลที่ได้รับการฝึกอบรมล่วงหน้าเพื่อให้มีน้ำหนักเบาขึ้น เพื่อตอบสนองความต้องการของอุตสาหกรรมอย่างแท้จริง วิธีการตามการดึงข้อมูล (เช่น RETRO, REALM และ RAG) มีความสำคัญอย่างยิ่งต่อการบรรลุเป้าหมายนี้
พื้นที่เก็บข้อมูลนี้เป็นการใช้งานแบบทดลองของโมเดลภาษาที่ปรับปรุงการดึงข้อมูล ปัจจุบันรองรับเฉพาะการดึงข้อมูลที่เหมาะสมบน GPT-Neo เท่านั้น
เราแยก Huggingface Transformers และ lm-evalue-harness เพื่อเพิ่มการรองรับการดึงข้อมูล ส่วนการจัดทำดัชนีถูกนำมาใช้เป็นเซิร์ฟเวอร์ HTTP เพื่อแยกการดึงข้อมูลและการฝึกอบรมที่ดีขึ้น
การใช้งานโมเดลส่วนใหญ่คัดลอกมาจาก RETRO-pytorch และ GPT-Neo เราใช้ transformers-cli เพื่อเพิ่มโมเดลใหม่ชื่อ Re_gptForCausalLM ที่ใช้ GPT-Neo จากนั้นเพิ่มส่วนที่ดึงข้อมูลเข้าไป
เราอัปโหลดโมเดลที่ติดตั้งบน EleutherAI/gpt-neo-125M โดยใช้ไลบรารีการดึงข้อมูล 200G
คุณสามารถเริ่มต้นโมเดลได้ดังนี้:
from transformers import Re_gptForCausalLM
model = Re_gptForCausalLM . from_pretrained ( 'Langboat/ReGPT-125M-200G' )และประเมินโมเดลดังนี้:
python main.py
--model retrieval
--model_args pretrained=model_path
--device 0
--tasks wikitext,lambada,winogrande,mathqa,pubmedqa
--batch_size 1เราคำนวณความคล้ายคลึงกันโดยใช้การฝังของรูปประโยคในการแสดงข้อความ คุณสามารถเริ่มต้นโมเดล Sentence-BERT ได้ดังนี้:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer ( 'all-MiniLM-L12-v2' )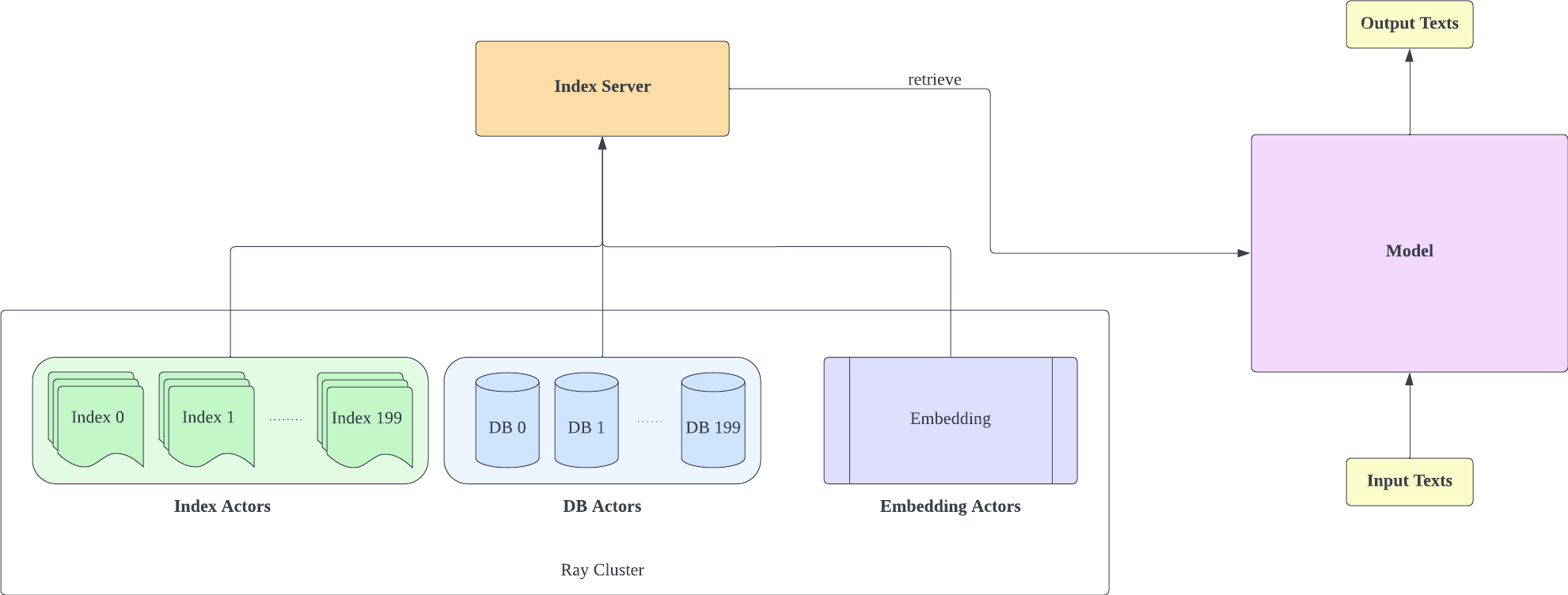
conda create -n mengzi-retrieval-fit python=3.7
conda activate mengzi-retrieval-fit
conda install pytorch torchvision torchaudio cudatoolkit=11.1 -c pytorch-lts -c nvidia
git clone https://github.com/Langboat/mengzi-retrieval-lm.git
cd mengzi-retrieval-lm
git submodule update --init --recursive
pip install -r requirement.txt
cd transformers/
pip install -e .
cd ..
python -c " from sentence_transformers import SentenceTransformer; model = SentenceTransformer('all-MiniLM-L12-v2') " การใช้ IVF1024PQ48 เป็นโรงงานดัชนี faiss เราได้อัปโหลดดัชนีและฐานข้อมูลไปยังฮับโมเดล Huggingface ซึ่งสามารถดาวน์โหลดได้โดยใช้คำสั่งต่อไปนี้
ใน download_index_db.py คุณสามารถระบุจำนวนดัชนีและฐานข้อมูลที่คุณต้องการดาวน์โหลด
python -u download_index_db.py --num 200คุณสามารถดาวน์โหลดโมเดลที่ติดตั้งด้วยตนเองได้จากที่นี่: https://huggingface.co/Langboat/ReGPT-125M-200G
เซิร์ฟเวอร์ดัชนีจะขึ้นอยู่กับ FastAPI และ Ray ด้วย Ray's Actor งานที่เน้นการประมวลผลจะถูกห่อหุ้มแบบอะซิงโครนัส ช่วยให้เราสามารถใช้ทรัพยากร CPU และ GPU ได้อย่างมีประสิทธิภาพด้วยอินสแตนซ์เซิร์ฟเวอร์ FastAPI เพียงอินสแตนซ์เดียว คุณสามารถเริ่มต้นเซิร์ฟเวอร์ดัชนีได้ดังนี้:
cd index-server/
ray start --head
python -u api.py
--config config_IVF1024PQ48.json
--db_path ../db/models—Langboat—Pile-DB/snapshots/fd35bcce75db5c1b7385a28018029f7465b4e966
- โปรดทราบว่าจำนวนส่วนแบ่งข้อมูลการกำหนดค่า IVF1024PQ48.json จะต้องตรงกับจำนวนดัชนีที่ดาวน์โหลด คุณสามารถดูหมายเลขดัชนีที่ดาวน์โหลดในปัจจุบันได้ภายใต้ db_path
- การกำหนดค่านี้ได้รับการทดสอบบน A100-40G แล้ว ดังนั้นหากคุณมี GPU อื่น เราขอแนะนำให้ปรับให้เข้ากับฮาร์ดแวร์ของคุณ
- หลังจากปรับใช้เซิร์ฟเวอร์ดัชนีแล้ว คุณต้องแก้ไข request_server ใน lm-evalue-harness/config.json และ train/config.json
- คุณสามารถลด encoder_actor_count ใน config_IVF1024PQ48.json เพื่อลดทรัพยากรหน่วยความจำที่จำเป็น
· db_path:ตำแหน่งดาวน์โหลดฐานข้อมูลจาก Huggingface "../db/models—Langboat—Pile-DB/snapshots/fd35bcce75db5c1b7385a28018029f7465b4e966" เป็นตัวอย่าง
คำสั่งนี้จะดาวน์โหลดฐานข้อมูลและข้อมูลดัชนีจาก Huggingface
เปลี่ยนโฟลเดอร์ดัชนีในไฟล์การกำหนดค่า (config IVF1024PQ48) ให้ชี้ไปที่เส้นทางของโฟลเดอร์ดัชนี และส่งสแน็ปช็อตของโฟลเดอร์ฐานข้อมูลเป็นเส้นทาง db ไปยังสคริปต์ api.py
หยุดเซิร์ฟเวอร์ดัชนีด้วยคำสั่งต่อไปนี้
ray stop
- โปรดทราบว่าคุณต้องเปิดใช้งานเซิร์ฟเวอร์ดัชนีไว้ในระหว่างการฝึก การประเมิน และการอนุมาน
ใช้ train/train.py เพื่อดำเนินการฝึกอบรม train/config.json สามารถปรับเปลี่ยนเพื่อเปลี่ยนพารามิเตอร์การฝึกได้
คุณสามารถเริ่มต้นการฝึกอบรมได้ดังนี้:
cd train
python -u train.py
- เนื่องจากเซิร์ฟเวอร์ดัชนีจำเป็นต้องใช้ทรัพยากรหน่วยความจำ คุณจึงปรับใช้เซิร์ฟเวอร์ดัชนีและการฝึกโมเดลบน GPU ที่แตกต่างกันได้ดีขึ้น
ใช้ train/inference.py เป็นการอนุมานเพื่อพิจารณาการสูญเสียข้อความและความฉงนสนเท่ห์
cd train
python -u inference.py
--model_path Langboat/ReGPT-125M-200G
--file_name data/test_data.json
- ขณะนี้ test_data.json และ train_data.json ในโฟลเดอร์ data เป็นรูปแบบไฟล์ที่รองรับ คุณสามารถแก้ไขข้อมูลของคุณเป็นรูปแบบนี้ได้
ใช้ lm-evalue-harness เป็นวิธีการประเมิน
เราตั้งค่า seq_len ของ lm-evalue-harness เป็น 1,025 เป็นการตั้งค่าเริ่มต้นสำหรับการเปรียบเทียบโมเดล เนื่องจาก seq_len ของการฝึกโมเดลของเราคือ 1,025
cd lm-evaluation-harness
python setup.py installpython main.py
--model retrieval
--model_args pretrained=Langboat/ReGPT-125M-200G
--device 0
--tasks wikitext
--batch_size 1· model_path:เส้นทางโมเดลที่เหมาะสม
python main.py
--model gpt2
--model_args pretrained=EleutherAI/gpt-neo-125M
--device 0
--tasks wikitext
--batch_size 1ผลการประเมินมีดังนี้
| แบบอย่าง | ข้อความวิกิ word_perplexity |
|---|---|
| EleutherAI/gpt-neo-125M | 35.8774 |
| เรือท้องแบน/ReGPT-125M-200G | 22.115 |
| EleutherAI/gpt-neo-1.3B | 17.6979 |
| เรือท้องแบน/ReGPT-125M-400G | 14.1327 |
@software { mengzi-retrieval-lm-library ,
title = { {Mengzi-Retrieval-LM} } ,
author = { Wang, Yulong and Bo, Lin } ,
url = { https://github.com/Langboat/mengzi-retrieval-lm } ,
month = { 9 } ,
year = { 2022 } ,
version = { 0.0.1 } ,
}

